Overview of the first elastic data warehouse Snowflake Elastic Data Warehouse
In our company, we regularly test and analyze new and interesting technologies in the field of storage and management of big data. In April, representatives of Snowflake Computing contacted us and offered to try their product Snowflake Elastic Data Warehouse - a cloud-based data warehouse. They are working to create an elastic system that could easily expand as needed - with an increase in data volume, workload, and other troubles.
Usually DBMS work in conditions when the amount of available resources is limited by the available equipment. To add resources, you need to add or replace servers. In the cloud, resources are available at the moment when they are needed, and they can be returned if they are no longer needed. The architecture of Snowflake allows you to take full advantage of the cloud: data storage can instantly expand and contract without interrupting your running requests.
There are other data warehouses that work in the clouds, the most famous is Amazon Redshift. But for their expansion it is still necessary to add servers, albeit virtual ones. What entails the redistribution of data, which means in one way or another downtime. About the compression of such storage is not at all, no one wants to once again shift all the data from place to place.
Snowflake provides the client with an elastic data warehouse as a service (Data Warehouse as a Service). This is a high-performance column DBMS that supports standard SQL and meets the requirements of ACID. The data is accessed via the Snowflake Web UI, the Snowflake Client command-line interface, as well as ODBC and JDBC.
')
We conducted a full cycle of testing Snowflake, which includes testing the performance of data loading, test SQL queries, system scaling, as well as basic operating scenarios.
But before proceeding to the test results, it is worthwhile to dwell on the architecture in more detail.
Snowflake uses Amazon Web Services as its platform. A DBMS consists of three components: a data storage level (Database Storage), a data processing level (Processing), and cloud services (Cloud Services).
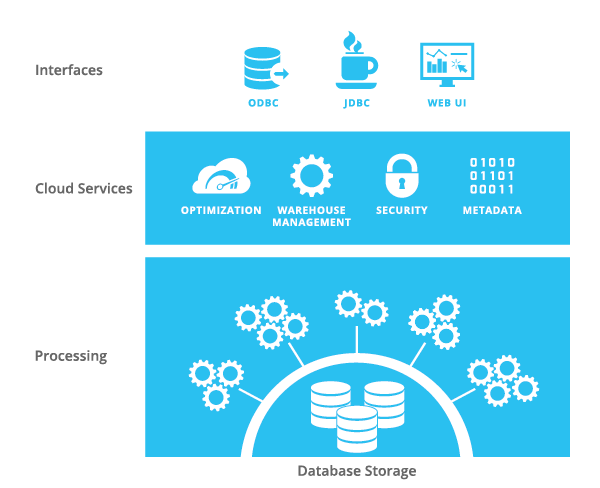
The data storage level is responsible for the safe, secure and resilient data storage. These wonderful properties are not provided by Snowflake itself, but by S3. Data is stored in S3, customers do not have direct access to them. To load data into Snowflake, special S3 buckets (staging area) are created, where you need to add files, from which you can then load data using Snowflake SQL. To create a staging area and copy files to it, you can use standard Amazon Web Services services or special Snowflake SQL functions. You can connect existing S3 buckets as Staging area, then files can be downloaded without prior copying. When loading, data is compressed (gzip) and converted to column format. Snowflake indexes are not provided.
The distribution of data (data distribution) is carried out automatically based on statistics on the use of data. There is no paring.
Data access is carried out through the data processing level - this is a set of virtual servers that can access S3 files. “Virtual Clusters” can consist of 1 (X-Small), 2 (Small), 4 (Medium), 8 (Large) or 16 (X-Large) virtual servers (EC2). All servers in a virtual cluster are the same and equivalent, the client does not have direct access to them. From a client’s point of view, a virtual cluster is a single unit. EC2 servers can be of two types: Standard and Enterprise. At the time of testing, EC2 with 16Gb RAM, 160Gb SSD, 8 cores were used as Standard. Enterprise - 2 times more. Snowflake has an agreement with Amazon, they receive new instances within 5 minutes. Those. expanding a virtual cluster or creating a new one takes 1-5 minutes. Since EC2 does not store any data, their loss is not at all critical. If a failure occurs, EC2 is simply recreated.
SSD virtual servers are used as a cluster cache. When executing a query, the data from S3 will go to the cluster cache, and all subsequent queries will use this cache. When data is available in the cache, queries are executed up to 10 times faster.
You can create multiple virtual clusters that will simultaneously access the same data. This allows you to better distribute the load. For example, you can use different virtual clusters to access different tables - in this case, the data of different tables will be cached by different clusters, which will actually increase the database cache.
Data management uses cloud services Snowflake. Using Snowflake UI, the client creates databases and tables, users, and roles. Metadata is used at the data processing level to determine whether you have the necessary access rights, to compile queries, etc. How and where metadata is stored, Snowflake does not explain.
For each virtual cluster, you need to select a database with which it will work. Before executing the request, the user must specify which cluster needs to be executed. You can set a default cluster.
You can start the cluster on a schedule, you can automatically when you receive a request, you can automatically stop if no requests were received within a certain time. You can also increase or decrease the number of servers in a running cluster.
As a result, the client receives an elastic storage, which is in no way limited in size. No installation, configuration, and maintenance procedures are required — Snowflake provides all of this. You just need to go to the site, create tables, download data, and run the query.
Snowflake has several interesting features. For example, it is possible to restore a recently deleted object: a table, a schema, and even a database.
Another feature allows you to see the results of a recently executed query. For re-viewing the data is available within 24 hours only to the user who executed the request. To view the saved results do not need a virtual cluster, because Snowflake stores them with metadata.
Snowflake is very proud of the ability to process partially structured data, such as JSON or Avro. Data is loaded as is, without any transformation and without a specific scheme. Then you can refer to them in SQL, indicating certain "fields" of the record. As part of testing, we did not check the speed of such calls, but usually in such cases, performance is sacrificed for convenience. For example, in Vertica, this functionality works much slower than querying regular tables.
The cost of service consists of payment for the amount of data in S3 and hourly payment for used virtual servers. Those. if the client has 2 virtual clusters of 4 servers each, and they worked 9 hours and 3 minutes, then you will have to pay for 2 * 4 * 10 = 80 service hours. It is important that virtual servers are paid only for the time. This allows you to significantly save if the load is uneven throughout the day or the system is used only sporadically.
Our test dataset consisted of one large table (just over 1 billion rows) and several small (from 100 to 100 thousand rows) - a simple star-type diagram. Data downloaded from text files in CSV format. Snowflake advises downloading data in small chunks, one file on the CPU core - so the resources will be used most efficiently. To do this, you need to split the file into pieces before it got to the Staging area. Faster to copy data from one table to another. When data is changed, the table is locked exclusively (reading is possible, all DML requests are queued).
Then we proceeded to simple queries. Here we were pleased with Snowflake, requests for two or three tables with filters, both for large and small, were performed fairly quickly.
It can be seen that the table scan is performed 10 or more times faster if the data has been cached. You can also see that Snowflake scales well, i.e. An increase in the number of servers in a cluster gives an almost linear increase in performance.
To analyze the results obtained, a reference is always needed. In our case, these are the results of conducting the same test on a Vertica cluster of 5 servers. All five servers are the same: 2xE5-2630, 32GB RAM, 8x1000GB R10 SATA.
Thus, with enough cache, the Snowflake Medium cluster of 4 EC2 can easily compete with the Vertica cluster of 5 servers. Moreover, on scans Snowflake is quite far ahead of Vertica, but with the complexity of requests it begins to lag behind. Unfortunately, it is not clear to what extent you can count on the cache. Monitoring is not available, it is also impossible to see usage statistics. All you can see is how much data you had to read to fulfill a particular request, but you don’t see where the data was read from the cache or from S3. It should also be borne in mind that when the table data changes, the cache is invalid. However, synthetic test data should never be used to predict actual performance.
In the next step, we tried to reproduce the data loading procedure that we use in Vertica. First, the data from the file is loaded into a very wide table (about 200 fields), and then aggregated with varying degrees of detail and passed on to other tables. This is where problems began to arise. Queries with a large number of tables or columns could be compiled for several minutes. If there was not enough memory to execute the request, no messages were output, instead, an incorrect result was simply returned. Often the error messages were not informative, it was especially difficult to diagnose the format mismatch at boot. We stopped the tests because it became clear that Snowflake is not yet ready to perform our tasks.
Testing lasted about a month. During this time, specialists from Snowflake gave us support, helped with advice, even fixed a couple of bugs. The technology is interesting, the ability to change the amount of resources on the fly looks very attractive.
Cloud storage may be a good option if the project is new and there is not much data yet. Especially if the fate of the project is unknown, and do not want to invest in infrastructure for storing and processing data. But it’s still too early to plan the transfer of all data and systems to the cloud.
Usually DBMS work in conditions when the amount of available resources is limited by the available equipment. To add resources, you need to add or replace servers. In the cloud, resources are available at the moment when they are needed, and they can be returned if they are no longer needed. The architecture of Snowflake allows you to take full advantage of the cloud: data storage can instantly expand and contract without interrupting your running requests.
There are other data warehouses that work in the clouds, the most famous is Amazon Redshift. But for their expansion it is still necessary to add servers, albeit virtual ones. What entails the redistribution of data, which means in one way or another downtime. About the compression of such storage is not at all, no one wants to once again shift all the data from place to place.
Snowflake provides the client with an elastic data warehouse as a service (Data Warehouse as a Service). This is a high-performance column DBMS that supports standard SQL and meets the requirements of ACID. The data is accessed via the Snowflake Web UI, the Snowflake Client command-line interface, as well as ODBC and JDBC.
')
We conducted a full cycle of testing Snowflake, which includes testing the performance of data loading, test SQL queries, system scaling, as well as basic operating scenarios.
But before proceeding to the test results, it is worthwhile to dwell on the architecture in more detail.
Architecture
Snowflake uses Amazon Web Services as its platform. A DBMS consists of three components: a data storage level (Database Storage), a data processing level (Processing), and cloud services (Cloud Services).
The data storage level is responsible for the safe, secure and resilient data storage. These wonderful properties are not provided by Snowflake itself, but by S3. Data is stored in S3, customers do not have direct access to them. To load data into Snowflake, special S3 buckets (staging area) are created, where you need to add files, from which you can then load data using Snowflake SQL. To create a staging area and copy files to it, you can use standard Amazon Web Services services or special Snowflake SQL functions. You can connect existing S3 buckets as Staging area, then files can be downloaded without prior copying. When loading, data is compressed (gzip) and converted to column format. Snowflake indexes are not provided.
The distribution of data (data distribution) is carried out automatically based on statistics on the use of data. There is no paring.
Data access is carried out through the data processing level - this is a set of virtual servers that can access S3 files. “Virtual Clusters” can consist of 1 (X-Small), 2 (Small), 4 (Medium), 8 (Large) or 16 (X-Large) virtual servers (EC2). All servers in a virtual cluster are the same and equivalent, the client does not have direct access to them. From a client’s point of view, a virtual cluster is a single unit. EC2 servers can be of two types: Standard and Enterprise. At the time of testing, EC2 with 16Gb RAM, 160Gb SSD, 8 cores were used as Standard. Enterprise - 2 times more. Snowflake has an agreement with Amazon, they receive new instances within 5 minutes. Those. expanding a virtual cluster or creating a new one takes 1-5 minutes. Since EC2 does not store any data, their loss is not at all critical. If a failure occurs, EC2 is simply recreated.
SSD virtual servers are used as a cluster cache. When executing a query, the data from S3 will go to the cluster cache, and all subsequent queries will use this cache. When data is available in the cache, queries are executed up to 10 times faster.
You can create multiple virtual clusters that will simultaneously access the same data. This allows you to better distribute the load. For example, you can use different virtual clusters to access different tables - in this case, the data of different tables will be cached by different clusters, which will actually increase the database cache.
Data management uses cloud services Snowflake. Using Snowflake UI, the client creates databases and tables, users, and roles. Metadata is used at the data processing level to determine whether you have the necessary access rights, to compile queries, etc. How and where metadata is stored, Snowflake does not explain.
For each virtual cluster, you need to select a database with which it will work. Before executing the request, the user must specify which cluster needs to be executed. You can set a default cluster.
You can start the cluster on a schedule, you can automatically when you receive a request, you can automatically stop if no requests were received within a certain time. You can also increase or decrease the number of servers in a running cluster.
As a result, the client receives an elastic storage, which is in no way limited in size. No installation, configuration, and maintenance procedures are required — Snowflake provides all of this. You just need to go to the site, create tables, download data, and run the query.
Special features
Snowflake has several interesting features. For example, it is possible to restore a recently deleted object: a table, a schema, and even a database.
Another feature allows you to see the results of a recently executed query. For re-viewing the data is available within 24 hours only to the user who executed the request. To view the saved results do not need a virtual cluster, because Snowflake stores them with metadata.
Snowflake is very proud of the ability to process partially structured data, such as JSON or Avro. Data is loaded as is, without any transformation and without a specific scheme. Then you can refer to them in SQL, indicating certain "fields" of the record. As part of testing, we did not check the speed of such calls, but usually in such cases, performance is sacrificed for convenience. For example, in Vertica, this functionality works much slower than querying regular tables.
Price
The cost of service consists of payment for the amount of data in S3 and hourly payment for used virtual servers. Those. if the client has 2 virtual clusters of 4 servers each, and they worked 9 hours and 3 minutes, then you will have to pay for 2 * 4 * 10 = 80 service hours. It is important that virtual servers are paid only for the time. This allows you to significantly save if the load is uneven throughout the day or the system is used only sporadically.
Testing
Our test dataset consisted of one large table (just over 1 billion rows) and several small (from 100 to 100 thousand rows) - a simple star-type diagram. Data downloaded from text files in CSV format. Snowflake advises downloading data in small chunks, one file on the CPU core - so the resources will be used most efficiently. To do this, you need to split the file into pieces before it got to the Staging area. Faster to copy data from one table to another. When data is changed, the table is locked exclusively (reading is possible, all DML requests are queued).
Load time of 1 billion lines, from a text file and from a table
| Cluster size | Insert from file | Time |
|---|---|---|
| Medium (4 EC2) | 1 file 8 GB copy into table1 from @ ~ / file / file.txt.gz file_format = 'csv' | 42m 49.663s |
| Medium (4 EC2) | 11 files of 750 MB copy into table1 from @ ~ / file / file_format = 'csv' | 3m 45.272s |
| Small (2 EC2) | 11 files of 750 MB copy into table1 from @ ~ / file / file_format = 'csv' | 4m 33.432s |
| Copy from another table | ||
| Medium (4 EC2) | insert into table2 select * from table1 | 1m 30.713s |
| Small (2 EC2) | insert into table2 select * from table1 | 2m 42.358s |
Then we proceeded to simple queries. Here we were pleased with Snowflake, requests for two or three tables with filters, both for large and small, were performed fairly quickly.
For example, select count (*), sum (float1) from table
| Cluster size | Size table | First run (S3) | Restart (cache) |
|---|---|---|---|
| Small (2 EC2) | 1 billion lines, 24.4 GB | 22.48 seconds | 1.91 seconds |
| Small (2 EC2) | 5 billion lines | 109 seconds | 7.34 seconds |
| Medium (4 EC2) | 1 billion lines, 24.4 GB | 10.67 seconds | 1.2 seconds |
| Medium (4 EC2) | 5 billion lines | 3.65 seconds |
It can be seen that the table scan is performed 10 or more times faster if the data has been cached. You can also see that Snowflake scales well, i.e. An increase in the number of servers in a cluster gives an almost linear increase in performance.
To analyze the results obtained, a reference is always needed. In our case, these are the results of conducting the same test on a Vertica cluster of 5 servers. All five servers are the same: 2xE5-2630, 32GB RAM, 8x1000GB R10 SATA.
Compare test runtime between Snowflake and Vertica
| Snowflake (first) | Snowflake (second) | Vertica | |
|---|---|---|---|
| Cluster size | Medium (4 EC2) | Medium (4 EC2) | cluster of 5 servers |
| Size of table (rows) | 1 billion | 1 billion | 1 billion |
| select count (*) from table1 | 0.2 | 0.27 | 0.69 |
| select count (*), sum (float1) from table1 | 10.6 | 1.33 | 2.89 |
| select count (*), sum (float1) from table1 where country_key = 1 | 5.8 | 1.41 | 3.63 |
| select count (*), sum (float1) from table1 a, country c where c.country_code = 'US' and a.country_key = c.country_key | 2.3 | 1.70 | 2.14 |
| select count (*), sum (float1) from table1 a, country c where c.country_code = 'ZA' and a.country_key = c.country_key; | 2.1 | 1.51 | 1.94 |
| select count (*), sum (float1), c.country_code from table1 a, country c where a.country_key = 1 and a.country_key = c.country_key group by c.country_code | 2.3 | 1.99 | 2.17 |
| select count (*), sum (float1), c.country_code from table1 a, country c where a.country_key> -1 and a.country_key <100000 and a.country_key = c.country_key group by c.country_code; | 4.4 | 4.17 | 3.26 |
| select count (*), sum (float1), c.country_code from table1 a, country c where c.country_code in ('US', 'GB') and a.country_key = c.country_key group by c.country_code; | 2.3 | 2.22 | 2.42 |
| select count (*), sum (float1), c.country_code from table1 a, country c where c.country_code in ('US', 'GB') and a.country_key = c.country_key and a.time_key <45000 group by c.country_code; | 3.8 | 1.47 | 1.03 |
| select count (*), sum (float1), c.country_code from table1 a, country c, time t where c.country_code in ('US', 'GB') and a.country_key = c.country_key and t.date> = '2013-03-01' and t.date <'2013-04-01' and t.time_key = a.time_key group by c.country_code; | 3.3 | 1.97 | 1.23 |
| select count (*), sum (float1), c.country_code, r.revision_name from table1 a, country c, time t, revision r where c.country_code in ('US', 'GB') and a.country_key = c.country_key and t.date> = '2013-03-01' and t.date <'2013-04-01' and t.time_key = a.time_key and r.revision_key = a.revision_key group by c.country_code, r.revision_name ; | 4.4 | 2.66 | 1.49 |
| Total test time, seconds | 41.5 | 20.69 | 22.89 |
Thus, with enough cache, the Snowflake Medium cluster of 4 EC2 can easily compete with the Vertica cluster of 5 servers. Moreover, on scans Snowflake is quite far ahead of Vertica, but with the complexity of requests it begins to lag behind. Unfortunately, it is not clear to what extent you can count on the cache. Monitoring is not available, it is also impossible to see usage statistics. All you can see is how much data you had to read to fulfill a particular request, but you don’t see where the data was read from the cache or from S3. It should also be borne in mind that when the table data changes, the cache is invalid. However, synthetic test data should never be used to predict actual performance.
In the next step, we tried to reproduce the data loading procedure that we use in Vertica. First, the data from the file is loaded into a very wide table (about 200 fields), and then aggregated with varying degrees of detail and passed on to other tables. This is where problems began to arise. Queries with a large number of tables or columns could be compiled for several minutes. If there was not enough memory to execute the request, no messages were output, instead, an incorrect result was simply returned. Often the error messages were not informative, it was especially difficult to diagnose the format mismatch at boot. We stopped the tests because it became clear that Snowflake is not yet ready to perform our tasks.
Conclusion
Testing lasted about a month. During this time, specialists from Snowflake gave us support, helped with advice, even fixed a couple of bugs. The technology is interesting, the ability to change the amount of resources on the fly looks very attractive.
Cloud storage may be a good option if the project is new and there is not much data yet. Especially if the fate of the project is unknown, and do not want to invest in infrastructure for storing and processing data. But it’s still too early to plan the transfer of all data and systems to the cloud.
Source: https://habr.com/ru/post/270167/
All Articles