Pitfalls of backup in hybrid storage systems

Of course, ways to protect data from loss are determined both by the amount of information and the device itself, on which they are stored. And the one and the other is constantly evolving.
Therefore, there have long been controversies between supporters of the traditional approach to backups and those who are looking for new ways to protect data, more convenient in terms of the architecture of the storage systems used. Now this dispute has escalated as the variety of storage system types has sharply increased lately. The use of some of them requires a change in approaches to the usual tasks of operation and accessibility, including backup, which I want to talk about here.
The traditional approach is not even to save a backup to tape. We are talking about having a backup in a storage system designed specifically for backup. Whether it is a disk SRK, or tape - no difference. This traditional approach implies that there is a productive system that stores the most up-to-date production data, and there is a system where copies of this data are regularly stored. In particular, EMC offers Data Domain for this storage.
')
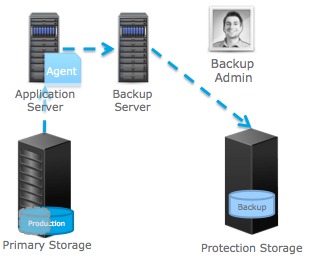
The scheme of the traditional backup.
A backup server is also typically used to centrally manage this process. He also carries out and information recovery, if the original data were damaged or lost. In this segment, the Networker software product has proven itself well. This is a time-tested data protection tool that satisfies a host of regulatory laws. And due to the presence of software clients for applications, Networker integrates perfectly with them, for which many deservedly love.
In contrast to the traditional approach, replication of data is put by means of storage systems. In this case, the productive data was replicated (mirrored) to the same, and preferably to another storage system. To create a set of recovery points, snapshots are regularly created from this mirror, which can be up to several hundred. Due to its convenience, this approach has gradually gained popularity over the past years. Most often he was chosen:
- NetApp systems administrators, in which snapshots are deeply embedded in the architecture,
- those who didn’t pay much attention to regulatory legislation about alienable carriers,
- and those who did not care about the perfect integration with applications.
In general, the struggle between these two approaches was going on, but without any particular intensity. In my opinion, the reason is that these two worlds overlap a little. My thoughts on this topic, by the way, are here: http://denserov.com/2013/01/30/bu-vs-rep/ .
I believe that the world of backup began to change fundamentally when new types of storage systems appeared, which began to gain weight quickly.
In the context of a changing approach to backups, I see three basic new types of storage.
- Hybrid storage systems using two- and three-level storage (SSD / SAS / NL-SAS). Systems such as VNX, VMAX and their analogues.
- Ultra-scalable massive scale-out Isilon, ScaleIO, Elastic Cloud Storage and their analogues.
- Systems with deduplication of productive data. For example, XtremIO. In some cases - VNX.
Perhaps many have long noticed that these three types of storage systems need a special approach to backup. Below, I present backup considerations for hybrid systems, as for the most common ones, and in future publications I’ll review the remaining two types.
Backup
Currently, these are the most common storage systems in the corporate segment. The architectures of most of them were the result of the development of traditional storage systems, which, as a rule, were combined with the traditional backup tools (EMC Networker and its analogs). Traditional storage systems mutated into hybrid ones, and the approach to backup remained largely the same. What is the problem with backups in these systems, if everything is traditional there?

A typical hybrid storage system contains fast, medium and slow media.
Someone has already guessed that the problem lies in the lowest level of storage, where the “coldest” data “slides”. For economy, this level is sometimes made up of a very small number of large-capacity disks (NL-SAS, 7200 rpm, from 1 to 6 TB).
Never, never, never use NL-SAS drives larger than 2TB for automatic multi-level storage in hybrid systems! Resist the temptation. And that's why.
It would be a mistake to assume that if you designed the system for capacity and performance, then with backup everything will settle down somehow by itself.
When designing three-tier systems, you need to remember that from the lower level, data also sometimes needs to be quickly raised for various tasks - from backup to reporting.
With sad regularity, we have to deal with the design of hybrid storage systems for databases of hundreds of TB. Sometimes they even make MS SQL databases of this size, adding electronic documents into the database. At the same time, no one considers how long the backup will take, and multi-level storage with the lower level on 6TB drives is prescribed in the TZ. Sometimes even 5400 rpm to be cheaper.
Consider a small hybrid system with not the worst set of disks:
- 16 200GB SSD drives in RAID 5 (7 + 1)
- 32 600GB 15000 rpm drives in RAID 1
- 8 2000GB 7200 rpm disks in RAID6 (6 + 2)
Decimal capacity (including RAID):
- SSD - 2800 GB
- SAS 15,000 rpm - 9600 GB
- NL-SAS 7200 rpm - 24,000 GB
TOTAL 36,400 GB.
Crude performance:
- SSD 16 * 3500 = 80000 IOPS
- SAS 15000 rpm 32 * 180 = 5760 IOPS
- NL-SAS 7200 rpm 8 * 80 = 640 IOPS
TOTAL 86,400 IOPS.
The volume and performance of such a system on just 56 disks turned out to be impressive. Now all this can fit in a disk shelf for 60 disks. In the worst case - 4 shelves with 15 discs.
A similar “flat” system, without the use of “Auto-Tiering” technologies, would consist of 480 disks of 15,000 rpm, would consume many times more electricity and would take many times more space. The economic gain of the “hybrid” approach is obvious.
We here admit, of course, that the design of this system for the workload profile was chosen to be correct, and the hot and cold data “sprawled” on it correctly (although the solution to this fascinating task is the subject of a separate and very interesting article).
Now I would like to consider exactly how the backup of such a “successfully designed” hybrid system will occur. Suppose traditional backup is used. Those. full backup on Friday night, and then a series of incremental ones. And so every week.
We calculate in the zero approximation how long a full backup of 36 TB from the hybrid system takes in the absence of productive load.

The calculation was made based on the assumption that there are no other bottlenecks in the backup process, and neither the storage controllers nor the target backup system prevent the disks from transmitting data for the backup.
From the illustration we see that the lower storage level “ate” 94% of the backup time and took 7 days. This is unacceptable. In fact, this is a consequence of the use of multi-level storage. The speed of the application is determined by the speed of the top level and its volume. And the speed of backup (and recovery!) Is the speed of the lower level and its volume. Does this mean that hybrid systems are poorly adapted to real life? Someone will say yes. But already very significant benefits come from their use in terms of storage efficiency. Therefore, you just need to rethink the rules of their operation and follow common sense.
I see the following solutions (or a combination of them) for hybrid systems:
The first. Discard full backups of large amounts of data. Go to synthetic full backups, distribute backups in time. Those. reduce the amount of data transmitted in a given time interval. The advantage of this option is the conditional cheapness.
The big drawback is the time to full recovery. It does not matter here whether the synthetic backup was or not. We'll have to fill the data completely even on the lower level. This will add to the daily data loss also about a week of inactivity.
The second. Try to make the lower level not so slow. After all, it is possible to compose it from disks of 1 TB, which, at a price per GB, are approximately in the same price category as 2 TB. It is possible to lay additional spindles in the lower storage level precisely in order to ensure an acceptable backup time. This need to think in advance. Those. increase both the speed of "return" of data for backup and plan the speed of potential recovery.
It is slightly more expensive than the first option, but it can be several times faster. The first and second options can be freely combined.
Third . Avoid 100% utilization of third-level storage for multi-level volumes. After all, it can be filled with “combat” data not by 100%, but by 15-20%, and the remaining 80% are allocated, for example, to archived data, which can be backed up less often. This is the fundamental difference between archival and operational data. For some, it may still sound strange, but the archive and backup are fundamentally different things. An archive is a long-term storage of immutable data that is moved there from the operational storage. A backup is a regularly created copy of operational data for possible recovery. In other words, the archive is the move operation, and the backup is the copy. You can read more about archiving on the EMC website .

Combination archive and backup.
Fourth. If all of the above does not allow to drastically improve the situation, then, perhaps, it is worth reconsidering a principled approach to backup. For a long time there are backup systems with data deduplication at the source, for example, Avamar or Vmware Data Protection Advanced. This technology effectively reduces the amount of data transferred between the client and the backup server. Another alternative is continuous data replication with snapshots to another storage system. For example, using RecoverPoint.
As you can see, when designing hybrid storage systems, you need to consider the backup context. Even when storage and backup are different projects.
Recovery
Imagine now that we have a system with automated multi-level storage and we successfully make backups from it. In addition, in the design process we take into account the speed of recovery, and with this, too, there are no serious questions.
The application runs on a hybrid storage system, the performance is sufficient. However, we recall that in modern environments most of the load falls on only a small amount of data.
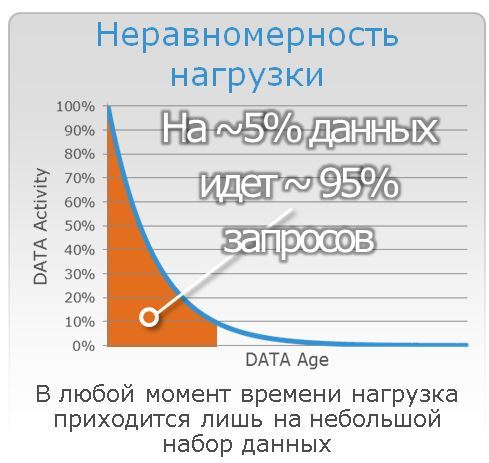
The question arises: how fast will the application work after a successful recovery from a backup made half a day ago? No one guarantees that when recovering from IBS, data blocks will necessarily expand on the carriers in exact accordance with their “temperature” before the failure. If we take into account that the hottest data is not in the storage cache, but in the RAM of the database servers and applications that, when recovering data from a backup, also have to warm up all their memory from scratch, the load on the disk system will also be higher than usual. The situation is not pleasant.
Since hybrid storage systems have in some places become almost standard approach to solving storage problems, the question of potential recovery after a failure, I think, has arisen and will arise more than once before administrators during operation.
If people encounter backup every day, it comes to full-scale recovery, I think, a hundred times less. Therefore, when in practice one encounters the scenario considered here, this turns out to be an unpleasant, but quite predictable event. Perhaps you should foresee and take it into account?
But since the design of backups is still about copying / restoring data, rather than guaranteed performance after recovery, this topic most often remains somewhere on the border of the attention of architects. And it is not clear from what budget to finance this project. Backup or storage? Perhaps that is why I still have not met with clear and clear recommendations on this matter when planning the architecture. Apparently, many believe that when recovering, the main thing is to recover. And further - these are minor nuances.
It should be noted here that there are cases when successful recovery of data from a backup did not allow a successful launch of the application. Hundreds and thousands of users literally "burst into" the "cold" storage system, successfully dumping it, entering the application server into a coma, and sometimes even damaging the data. Similar situations occur even on conventional storage systems, not to mention hybrid.

Therefore, we must remember that recovery from a full backup is a last resort. And if we resort to it, then we should not expect an instant release of applications at full capacity. In addition, in most cases, you still have to resolve organizational issues related to rolling back data for a while. But this does not remove the issue of technical support from the agenda.
Solution to the problem
What can I advise to solve this problem, characteristic of all disk systems, including hybrid ones?
First : consider the possibility of heating the storage system. Some hybrid storage algorithms use Flash as a cache expansion , and can respond to application needs in minutes, while others need at least three days to restore data from slow disks to fast disks after restoring from backup. So, if the hybrid system does not respond very quickly, then it is important not to overdo it with slow disks. They can significantly limit the ability of the system to "warm up" under load.
Second : backing up to an external IBS is always a last resort, Plan B, when nothing else worked ( see in another article ). Therefore, in order to minimize the uncertainty in application performance after data recovery, I would use online recovery tools that allow you to recover data more “pointwise”, “block by block”.
We are talking about replication at the storage level (clones, snapshots), and replication at the application level (Data Guard, etc.). This approach minimizes not only recovery time and data loss, but also saves the nerves of administrators in terms of more predictable performance after recovery. That is, it is best to combine backup to external devices with data replication, knowing what they are for.
Third : if the first two positions are taken into account, but you want more, then you can use two hybrid systems operating in a synchronous, crash-resistant cluster pair, which provides not only the storage of identical data instances, but also completely identical placement of these data at the storage levels. Even if one of the storage systems is completely disabled, data loss or application shutdown will not occur, and after restoring a failed system, the cluster can synchronize data and its layering on both systems.
In general, I share the opinion that a good backup should be integrated not only with the application level, but also with the productive storage system, and be able to both back up and restore individual data blocks similar to snapshots. And it seems that about this trend is currently observed in the backup market.
In these arguments, I deliberately adhered only to the protection and restoration of hybrid storage systems. The issue of flash systems will be discussed in one of the following articles. Stay tuned!
Denis Serov
Source: https://habr.com/ru/post/269933/
All Articles