PostgreSQL Evangelist Memo: Replicants vs. Replication

In the continuation of the series of publications, “The PostgreSQL Evangelist Memo ...” ( 1 , 2 ), the expensive edition again contacts, this time with the promised review of replication mechanisms in PostgreSQL and MySQL. The main reason for writing was the frequent criticism of MySQL replication. As is often the case, a typical criticism is a strong mixture of truth, half-truths, and evangelism . All this is repeatedly replicated by different people without special attempts to understand what was heard. And since this is a fairly extensive topic, I decided to make the analysis in a separate publication.
So, within the framework of cultural exchange and in anticipation of HighLoad ++, where there will certainly be as usual a lot of criticism of MySQL, consider the mechanisms of replication. For a start, some boring basic things for those who haven't.
Types of replication
Replication is logical and physical. Physical is a description of changes at the level of data files (simplified: write such bytes on such a displacement on such a page). Logical, on the other hand, describes changes at a higher level without reference to a specific representation of data on disk, and variants are possible here. You can describe changes in terms of the rows of the tables, for example, the
UPDATE can be reflected as a sequence of pairs (old values, new values) for each modified row. In MySQL, this type is called row-based replication. And you can simply write the text of all SQL queries that modify the data. This type in MySQL is called statement-based replication.')
Physical replication is often called binary (especially in the PostgreSQL community), which is not true. The data format of both logical and physical replication can be either text (that is, human-readable) or binary (requiring processing for human reading). In practice, all formats in both MySQL and PostgreSQL are binary. Obviously, in the case of statement-based replication in MySQL, query texts can be read with the naked eye, but all the service information will still be in binary form. Therefore, the log used in replication is called binary regardless of the replication format.
Features of logical replication:
- independence of data storage format: master and slave can have different representations of data on disk, different processor architectures, different table structures (provided that the schemes are compatible), different configurations and location of data files, different storage engines (for MySQL), different server versions, and in general, the master and the slave can be different DBMS (and such solutions for "cross-platform" replication exist). These properties are used frequently, especially in large-scale projects. For example, in rolling schema upgrade.
- readability: you can read data from every node in replication without any restrictions. With physical replication, this is not so easy (see below)
- multi-source capability : merging changes from different masters on the same slave. Example of use: data aggregation from several shards for building statistics and reports. The same Wikipedia uses multi-source for exactly this purpose.
- multi-master feature: for any topology, you can have more than one server available for recording, if necessary
- partial replication: the ability to replicate only individual tables or schemas
- compactness: the amount of data transmitted over the network is less. In some cases, much less.
Features of physical replication:
- easier to configure and use: By itself, the task of byte-based mirroring of one server to another is much simpler than logical replication with its numerous usage scenarios and topologies. Hence, the famous “set up and forget” in all the MySQL vs PostgreSQL holivors.
- low resource consumption: Logical replication requires additional resources, because the logical description of changes still needs to be “translated” into physical, i.e. understand what exactly and where to burn
- the requirement of 100% node identity: physical replication is possible only between exactly identical servers, up to the processor architecture, paths to the tablespace files, etc. This can often be a problem for large-scale replication clusters, since a change in these factors entails a complete stop of the cluster.
- no entry on the slave: derived from the preceding paragraph. Even a temporary table cannot be created.
- reading from the slave is problematic: reading from the slave is possible, but not without problems. See “Physical Replication in PostgreSQL” below.
- limited topologies: no multi-source and multi-master impossible. At best, cascading replication.
- no partial replication: everything follows from the same requirement of 100% data file identity
- large overheads: all changes to the data files need to be transferred (operation with indexes, vacuum and other internal accounting). So the load on the network is higher than with logical replication. But everything as usual depends on the number / type of indexes, load and other factors.
And still replication can be synchronous, asynchronous and semi-synchronous, regardless of format. But this fact has little relevance to the things discussed here, so we leave it behind the brackets.
Physical replication in MySQL
It does not exist as such, at least built into the server itself. There are architectural reasons for this, but this does not mean that it is impossible in principle. Oracle could implement physical replication for InnoDB with relatively little effort, and that would cover the needs of most users. A more complex approach would require creating some API, implementing which alternative engines could support physical replication, but I do not think it will ever happen.
But in some cases, physical replication can be implemented by external means, for example using DRBD or hardware solutions . The pros and cons of this approach have been discussed repeatedly and in detail.
In the context of comparison with PostgreSQL, it should be noted that the use of DRBD and similar solutions for the physical replication of MySQL is most similar to warm standby in PostgreSQL. But the amount of data transmitted over the network in DRBD will be higher, because DRBD operates at the block device level, which means that not only REDO log records (transaction log) are replicated, but also file system meta-information updates to the data files and updates.
Logical replication in MySQL
This topic is the most disturbing. And most of the criticism is based on the report “Asynchronous replication of MySQL without censorship or why PostgreSQL will conquer the world” by Oleg Tsarev zabivator , as well as the accompanying article on Habré.
 I would not single out one specific report if I were not referred to in approximately every tenth comment to previous articles. Therefore, we have to answer, but I would like to emphasize that there are no perfect reports (I personally get bad reports), and all criticism is directed not at the speaker, but at technical inaccuracies in the report. I would be glad if this helps to improve its future versions.
I would not single out one specific report if I were not referred to in approximately every tenth comment to previous articles. Therefore, we have to answer, but I would like to emphasize that there are no perfect reports (I personally get bad reports), and all criticism is directed not at the speaker, but at technical inaccuracies in the report. I would be glad if this helps to improve its future versions.In general, the report contains quite a lot of technically inaccurate or simply incorrect statements, some of which I addressed in the first part of the evangelist's memo . But I do not want to drown in the details, so I will analyze the main points.
So, in MySQL, logical replication is represented by two subtypes: statement-based and row-based.
Statement-based is the most naive way to organize replication (“let's just send SQL commands to the slave!”), Which is why it appeared first in MySQL and it was a long time ago. It even works as long as the SQL commands are strictly deterministic, i.e. result in the same changes regardless of runtime, context, triggers, etc. Tons of articles have been written about this; I will not dwell here in detail.
In my opinion, statement-based replication is a MyISAM style hack and “legacy”. Surely someone somewhere else finds her application, but if possible avoid it .
 Interestingly, Oleg also talks about the use of statement-based replication in his report. The reason - row-based replication would generate terabytes of information per day. What is generally logical, but how is this consistent with the statement “PostgreSQL conquers the world” if there is no asynchronous statement-based replication in PostgreSQL at all? That is, PostgreSQL would generate terabytes of updates per day, a disk or a network would be expected to become a disk or a network, and with the conquest of the world would have to wait .
Interestingly, Oleg also talks about the use of statement-based replication in his report. The reason - row-based replication would generate terabytes of information per day. What is generally logical, but how is this consistent with the statement “PostgreSQL conquers the world” if there is no asynchronous statement-based replication in PostgreSQL at all? That is, PostgreSQL would generate terabytes of updates per day, a disk or a network would be expected to become a disk or a network, and with the conquest of the world would have to wait .Oleg notes that logical replication is usually CPU-bound, that is, rests on the processor, and physical replication is usually I / O-bound, that is, rests on the network / disk. I’m not quite sure about this statement: CPU-bound load in one hand turns into an elegant I / O bound as soon as the active data set stops being stored in memory (typical situation for the same Facebook, for example). And along with this, most of the difference between logical and physical replication is leveled. But in general, I agree: logical replication requires relatively more resources (and this is its main drawback), and physical is less (and this is practically its only advantage).
There can be many reasons to “slow down” replication: it’s not only single streaming or processor deficiency, it can be a network, a disk, inefficient requests, inadequate configuration. The main damage from the report is that it “rows all one size fits all”, explaining all the problems with a certain “architectural error of MySQL”, and leaving the impression that there are no solutions to these problems. That is why he was gladly adopted by the evangelists of all stripes . In fact, I am sure that 1) most of the problems have a solution and 2) all these problems exist in the implementations of logical replication for PostgreSQL, perhaps even more severely (see “Logical Replication for PostgreSQL”).
 From Oleg's report it is very difficult to understand what actually became a problem in his tests: there is no attempt to analyze, there are no metrics, neither at the OS level, nor at the server level. For comparison: the publication of engineers from Booking.com on the same topic, but with detailed analysis and without the "evangelical" conclusions. I especially recommend to read the section Under the Hood . That's the way to do and show benchmarks. In Oleg's report, 3 slides are set aside for benchmarks.
From Oleg's report it is very difficult to understand what actually became a problem in his tests: there is no attempt to analyze, there are no metrics, neither at the OS level, nor at the server level. For comparison: the publication of engineers from Booking.com on the same topic, but with detailed analysis and without the "evangelical" conclusions. I especially recommend to read the section Under the Hood . That's the way to do and show benchmarks. In Oleg's report, 3 slides are set aside for benchmarks.I just briefly list possible problems and their solutions. I foresee a lot of comments in the spirit of "and everything works fine in the elephant and without any shamanism!" I will answer them once and I will not do it again: physical replication is easier to set up than logical replication, but not everyone is happy with its capabilities. There are more logical possibilities, but there are also disadvantages. Here are ways to minimize flaws for MySQL.
If we rest against the disk
Often, weak machines are allocated to the slave for reasons of "well, this is not the main server, this old wash will come down." In the old basin is usually a weak disk, in which everything rests.
If the disk is a bottleneck during replication, and it is not possible to use something more powerful, you need to reduce the disk load.
First, it is possible to regulate the amount of information that master writes to the binary log, and therefore is sent over the network and written / read on the slave. Settings worth watching:
binlog_rows_query_log_events , binlog_row_image .Secondly, you can disable the binary log on the slave. It is needed only if the slave itself is a master (in a multi-master topology or as an intermediate master in cascade replication). Some keep the binary log enabled in order to speed up the slave switch to master mode in case of failover. But if there is a problem with disk performance, it can and should be disabled.
Thirdly, you can weaken the durability settings on the slave. A slave is, by definition, irrelevant (due to asynchronous) and not a single copy of the data, which means that if it falls it can be recreated either from a backup, or from a master, or from another slave. Therefore, there is no point in keeping the strict settings of durability, keywords:
sync_binlog , innodb_flush_log_at_trx_commit , innodb_doublewrite .Finally, the InnoDB general setting for intensive recording has not been canceled. Keywords:
innodb_max_dirty_pages_pct , innodb_stats_persistent , innodb_adaptive_flushing , innodb_flush_neighbors , innodb_write_io_threads , in the innodb_io_capacity innodb_adaptive_flushing , innodb_flush_neighbors , innodb_write_io_threads , innodb_io_capacity , innodb_purge_threads , innodb_log_file_size , innodb_log_buffer_size , innodb_stats_persistent , innodb_adaptive_flushing , innodb_flush_neighbors , innodb_write_io_threads , innodb_io_capacity , innodb_purge_threads , innodb_log_file_size , innodb_log_buffer_size , innodb_stats_persistent , innodb_adaptive_flushing , innodb_flush_neighbors , innodb_write_io_threads , innodb_io_capacity , innodb_purge_threads , innodb_log_file_size , innodb_log_buffer_size .If nothing helps, you can look towards the TokuDB engine, which is, firstly, optimized for intensive writing, especially if the data does not fit in memory, and secondly, it provides the ability to organize read-free replication . This can solve the problem in both IO-bound and CPU-bound loads.
If we run into the processor
With a fairly intensive recording on the master and no other bottlenecks on the slave (network, disk), you can rest against the processor. This is where parallel replication comes to the rescue, it’s a multi-threaded slave (MTS).
At 5.6, MTS was made in a very limited form: only updates to different databases were performed in parallel (schemes in PostgreSQL terminology). But surely there is a non-empty multitude of users in the world for whom this is quite enough (hello, hosters!).
In 5.7, MTS was extended to perform arbitrary updates in parallel. In early pre-release versions 5.7, concurrency was limited by the number of simultaneously committed transactions within a group commit. This limited parallelism, especially for systems with fast disks, which most likely led to insufficiently effective results for those who tested these early versions. It is quite normal for them to have earlier versions so that interested users can test and scold. But not all users guess to make a report of this with the conclusion “PostgreSQL will conquer the world.”
Nevertheless, here are the results of the same sysbench tests that Oleg used for the report, but already on the GA release 5.7. What we see in the bottom line:
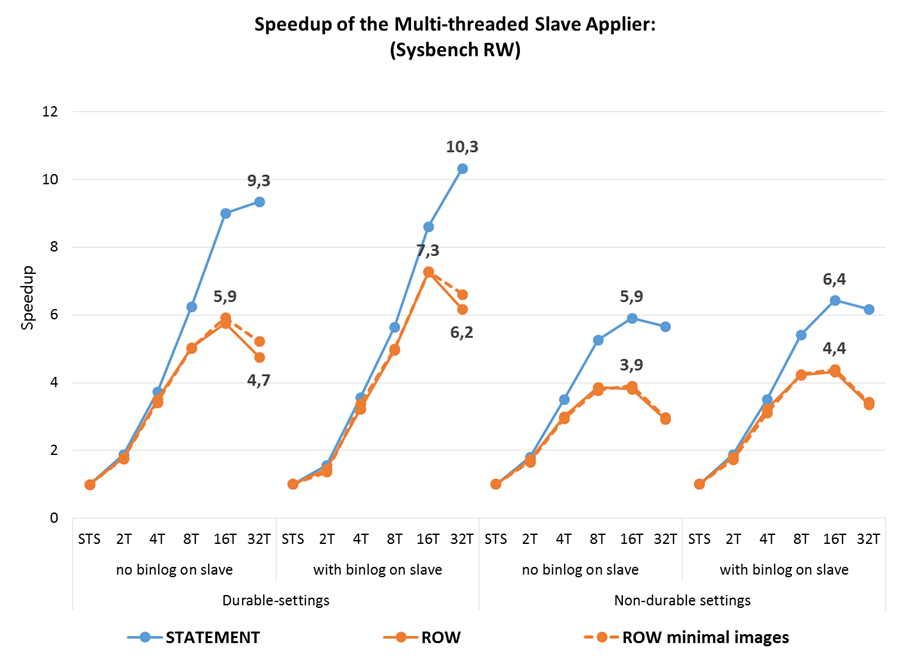
- MTS on the slave achieves a 10-fold increase in performance compared to single-threaded replication
- using
slave_parallel_workers=4already results in more than 3.5 times the throughput of the slave - Row-based replication performance is almost always better than statement-based. But MTS has a greater effect on statement-based, which somewhat equalizes both formats in terms of performance on OLTP loads.
Another important conclusion from Booking.com testing is: the smaller the transaction size, the more parallelism can be achieved. Before group commit in 5.6, developers tried to make transactions as much as possible, often unnecessarily from an application point of view. Starting from 5.6, this is not necessary, and for parallel replication in 5.7 it is better to revise transactions and break them into smaller ones where possible.
In addition, you can adjust the
binlog_group_commit_sync_delay and binlog_group_commit_sync_no_delay_count on the wizard, which can lead to additional parallelism on the slave, even in the case of long transactions.On this topic with replication in MySQL and a popular report, I think it is closed, go to PostgreSQL.
Physical replication in PostgreSQL
In addition to all the advantages and disadvantages of physical replication listed above, the implementation in PostgreSQL has another significant drawback: replication compatibility is not guaranteed between major releases of PostgreSQL, since WAL compatibility is not guaranteed. This is really a serious drawback for loaded projects and large clusters: you need to stop the wizard, upgrade, then complete re-creation of the slaves. For comparison: problems with replication from old versions to new ones occur in MySQL, but they are fixed and in most cases it works, no one refuses compatibility. This is what is used when updating large-scale clusters - the advantages of “flawed” logical replication.
PostgreSQL provides the ability to read data from a slave (the so-called Hot Standby), but this is not nearly as easy as with logical replication. From the Hot Standby documentation , we found out that:
SELECT ... FOR SHARE | UPDATESELECT ... FOR SHARE | UPDATEnot supported because it requires modification of data files.- 2PC commands are not supported for the same reasons.
- explicit indication of “read write” transaction status (
BEGIN READ WRITE, etc.), LISTEN, UNLISTEN, NOTIFY, sequence updates are not supported. Which is generally explicable, but this means that some applications will have to be rewritten during migration to Hot Standby, even if they do not modify any data. - Even read-only requests can cause conflicts with DDL and vacuum operations on the wizard (hello to “aggressive” vacuum settings!) In this case, requests can either delay replication or be forcibly interrupted and there are configuration parameters that control this behavior.
- the slave can be configured to provide “feedback” to the master (the
hot_standby_feedbackparameter). What is good, but the overhead costs of this mechanism in loaded systems are interesting.
In addition, I found a wonderful warning in the same documentation:
- "Operations on hash indexes are not presently WAL-logged, so do not replay these indexes" - uh, but this is generally how? And with physical backups, what?
There are some features with failover that may seem strange to the MySQL user, such as the inability to return to the old master after failover without re-creating it. I quote the documentation:
Once there is a single server in operation. This is known as a degenerate state. Stay down and stay down. If it comes to a third time, it may be new.
There is one more specific feature of physical replication in PostgreSQL. As I wrote above, the overhead for traffic for physical replication is generally higher than in logical. But in the case of PostgeSQL, in WAL, full images of the pages updated after checkpoint (
full_page_writes ) are recorded (and therefore transmitted over the network). I can easily imagine the load, where this behavior can be a disaster. Here, for sure, several people will rush to explain the meaning of full_page_writes to me. I know, just in InnoDB this is implemented somewhat differently, not through a transactional log.Updated 09/28/2016: The same problems with replication, but with English words in the article by Uber engineers on the reasons for switching from PostgreSQL to MySQL: eng.uber.com/mysql-migration
Updated 10/30/2017: A curious problem that arose from the fact that replication in PostgreSQL is physical: thebuild.com/blog/2017/10/27/streaming-replication-stopped-one-more-thing-to-check
Otherwise, physical replication in PostgreSQL is probably a really reliable and easy-to-configure mechanism for those to whom physical replication is generally suitable.
But users of PostgreSQL are also people and nothing human is alien to them. Someone sometimes wants multi-source. And someone really likes multi-master or partial replication. Perhaps that is why there is ...
Logical replication in PostgreSQL
I tried to understand the state of logical replication in PostgreSQL and something was despondent . There is no built-in, there are a lot of third-party solutions ( who said “confusion”? ): Slony-I (by the way, where is Slony-II?), Bucardo, Londiste, BDR, pgpool 1/2, Logical Decoding, and that's not counting the dead or proprietary projects.
Everyone has their own problems - some look familiar ( for them replication in MySQL is often criticized ), some look strange to the MySQL user. Some kind of total disaster with DDL replication that is not supported even in Logical Decoding (I wonder why?).
BDR requires a patched version of PostgreSQL ( who says fork? ).
I have some doubts about performance. I'm sure that someone in the comments will begin to explain that replication on triggers and scripts in Perl / Python is fast , but I will believe in it only when I see comparative load tests with MySQL on the same hardware.
Logical decoding looks interesting. But:
- This is not replication per se, but a constructor / framework / API for creating third-party logical replication solutions.
- Using Logical Decoding requires recording additional information in WAL (required to install
wal_level=logical). Hello to the critics of the binary log in MySQL! - Some of the third-party solutions have already moved to Logical Decoding, and some have not.
- , row-based MySQL, : , GTID ( failover/switchover ?), .
- SQL Logical Decoding Poll , Push . , Push , - ?
- , . , ?
REPLICA IDENTITY.binlog_row_imageMySQL. MySQL , , . PostgreSQL?- , « PostgreSQL »? . .
As I said, I do not pretend to anything in terms of knowledge of PostgreSQL. If any of this is wrong, or inaccurate - let me know in the comments and I will correct it. It would also be interesting to get answers to questions that I had on the go.
But my overall impression is that logical replication in PostgreSQL is in its early stages of development. In MySQL, logical replication has been around for a long time; all of its pros, cons, and pitfalls are well known, studied, discussed, and shown in various reports . In addition, it has changed a lot in recent years.
Conclusion
Since this publication contains some criticism of PostgreSQL, I predict another explosion of comments in the style: “but my friend and I worked on a muscle and everything was bad, but now we are working on an elephant and life has improved” . I believe. No seriously. But I do not urge anyone to go somewhere or even change anything at all.
The article pursues two goals:
1) the answer to the not completely correct criticism of MySQL and
2) an attempt to systematize the numerous differences between MySQL and PostgreSQL. Such comparisons require tremendous work, but this is what is often expected of me in the comments.
In the next post I’m going to continue the comparison, this time in the light of performance.
Source: https://habr.com/ru/post/269889/
All Articles