Configuring a bunch of Apache Zeppelin + Oracle
I have long been looking for a handy tool to perform ad hoc SQL queries in an Oracle database, with the ability to quickly build various types of graphs on the received data. Anything that can facilitate the rapid creation of reports, as they say on the fly. Recently I came across a tool like Apache Zeppelin . A short overview of the possibilities in the documentation on the website and the demo video showed that this thing is quite interesting and it makes sense to more closely examine it and configure access from Apache Zeppelin to the Oracle DBMS.

The explosive growth of the Big Data industry, Machine Learing, has required new tools and approaches for working with large data sets. There are such ecosystems and Big Data software products like Hadoop , Spark , Storm , Elasticsearch , etc ... Dozens of different machine learning frameworks with predefined algorithms. Leading universities in the world create many free courses on machine learning and working with Big Data.
There are also tools that solve data visualization problems. I would like to highlight two tools: this is an ecosystem of the programming language R , created for statistical data processing and work with graphics. And Weka is a set of visualization tools and algorithms for data mining and solving forecasting problems. By the way, the development of both tools / programming languages started in 1993 and both from New Zealand :). And of course, this is a set of other visualization tools that almost every team offering the final product already does by itself using popular frameworks for data visualization: D3.js , JfreeChart , HighCharts.js and others.
')
Separately, I would like to highlight the direction of interactive shells for working with big data and machine learning. The most famous and popular tool is the product of the Python community — IPython . Judging by the number of references (I myself did not work closely with it), it is the de facto standard among machine learning specialists. Since 2014, the creator of IPython has launched a new project, Jupyter Notebook , the goal of which is to create an interactive shell that is completely independent of the programming language. Also, DataBricks and Beaker companies are actively working in this direction, which develop the direction of interactive shell tools for Data Scientist with a focus on clouds . In addition to Jupyter Notebook , there are other similar tools, such as Spark Notebook .
So, Apache Zeppelin is one of the representatives of the direction of interactive shells for working with Big Data and machine learning.
Work on the creation of Zeppelin was started in the depths of the South Korean software company NFLabs in 2012-2013 (for more details, see the creation history from the system developer here ).
Initially, the goal was to create a user interface for a variety of SQL over Hadoop systems, such as Hive, Presto, and Shark etc. Then it became clear that there is a need to create a more powerful tool for Data Scientist for collaboration on large projects that are not limited only to SQL. Therefore, the built-in integration with the Apache Spark framework and the ability to work together in a Notebook via WEB was implemented.
System requirements and instructions for installing Apache Zeppelin are available on the project page on GitHub or on the project website.
You can configure the Apache Zeppelin environment using Vagrant on your client machine:
1. github.com/arjones/vagrant-spark-zeppelin
2. github.com/felixcheung/vagrant-projects
or Docker:
hub.docker.com/r/internavenue/centos-zeppelin/~/dockerfile
In my work, I used Vagrant + manual compilation from source codes. You can choose any of the proposed methods.
We download the JDBC driver from Oracle (for example, ojdbc7.jar) by reference (registration on the site is required) and post the driver in the CLASSPATH paths. In the case of Apache Zeppelin, we post the driver file in the root directory (/ usr / zeppelin). For Apache Spark, in SPARK_HOME / lib (theoretically, the jdbc driver can be loaded dynamically using the Dependency loader , but I could not get the visibility of classes in the SparkContext).
To work with ojdbc7.jar, you may need to configure the Timezone when the application starts. If you get an error like when trying to access the data: ORA-01882: timezone region not found., Then in the Apache configuration file /usr/zeppelin/conf/zeppelin-env.sh you will need to add the value of your server timezone. For example: ZEPPELIN_JAVA_OPTS -Duser.timezone = UTC
The first attempt to access Oracle was made from the Apache Spark environment. Since Spark 1.3, it is recommended to work with the database through the Spark SQL data source API . Specify the database access url, table / dataset and jdbc driver for connecting to the database. Check which fields are available for selection, and load the data set as a table into memory in the SQLContext environment using the registerTempTable () procedure, after which you can query the data source.
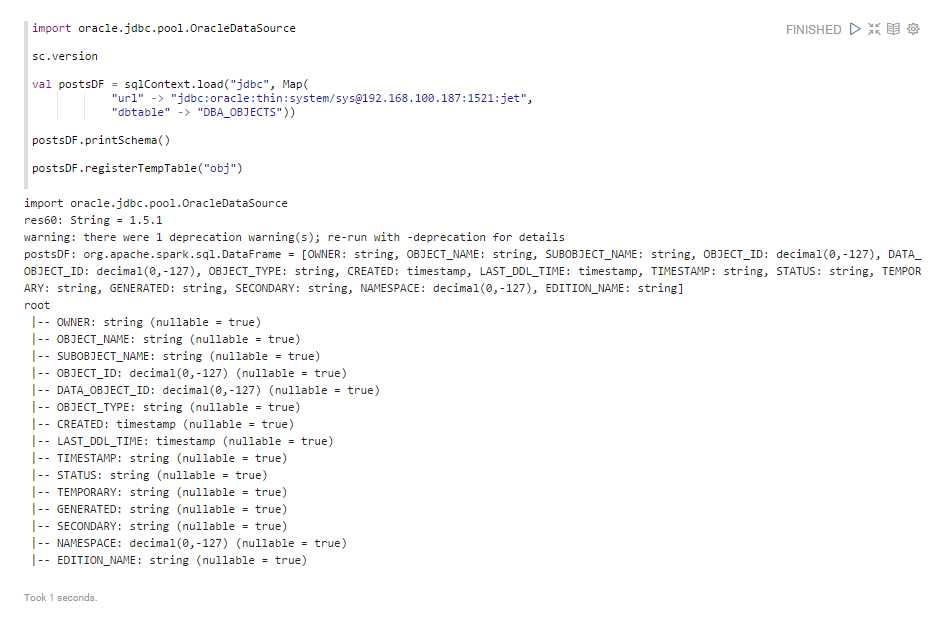
Now everything is ready for the query on the OBJ table
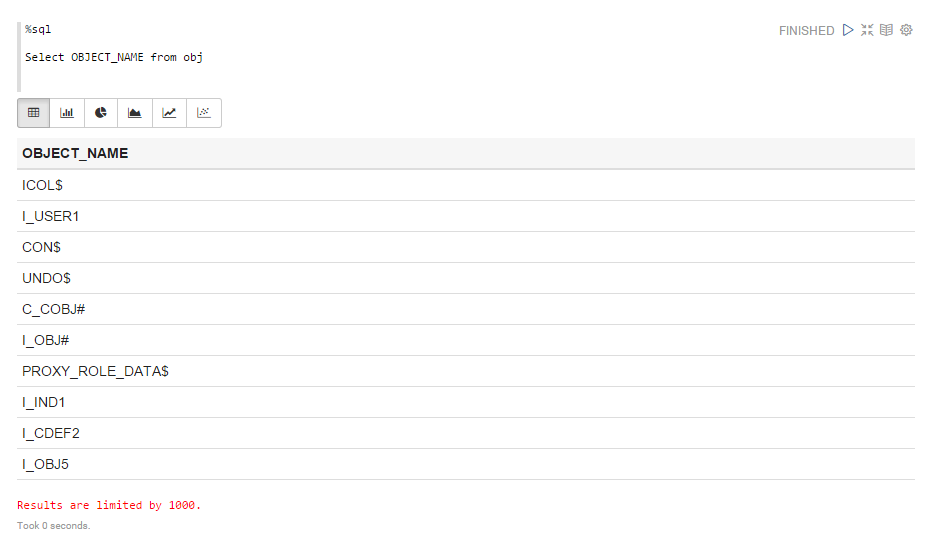
Unfortunately, full access to Oracle data in Apache Spark does not work. When trying to select data with data type NUMBER, we get the following error:

This problem is known and described in the Apache Spark JIRA project: Spark sql jdbc fails for Oracle NUMBER type columns
While there is no solution, respectively, fully, directly, working with Oracle DBMS data in Apache Spark is not easy. As a workaround, in Oracle DBMS, you can create views in which to do NUMBER to VARCHAR2 conversion and use them to work from Apache Spark. But these are additional difficulties with administration, issuance of rights, etc.
Let's try to get access to Oracle DBMS directly, not through Spark. The developers came up with a system of extensions for this purpose - called Interpreters. There is no separate plugin for Oracle DB yet. But we will try to use ready for Postgresql - after all it is JDBC . Make the necessary changes in the Zeppelin interface on the Interpreters tab for psql:
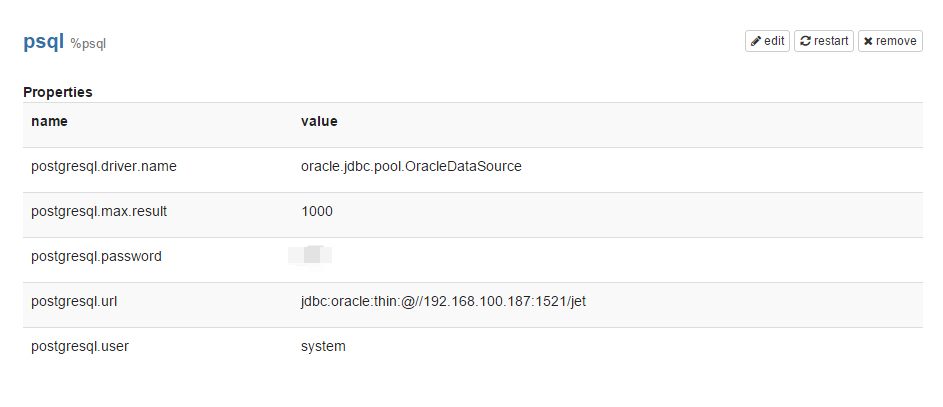
And we try to perform a test query:

Let's try to visualize data from the history of active sessions:
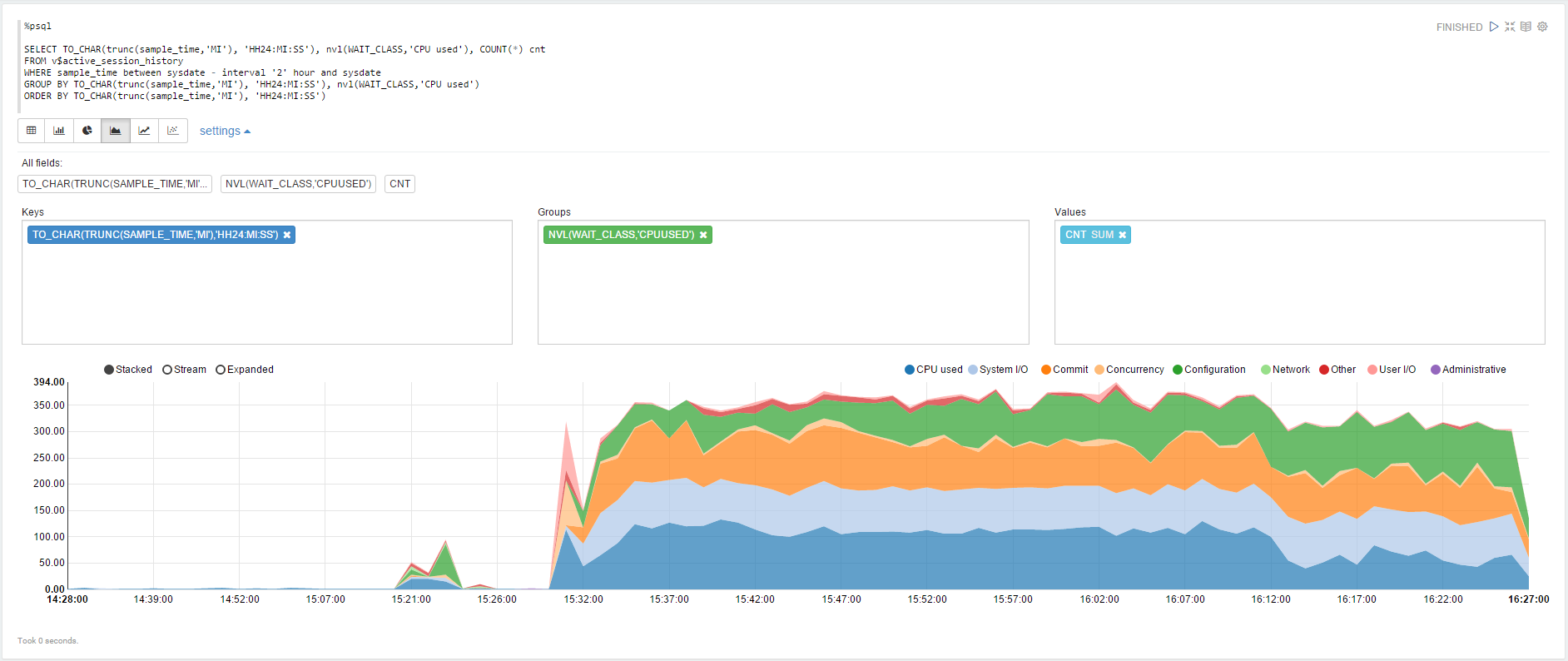
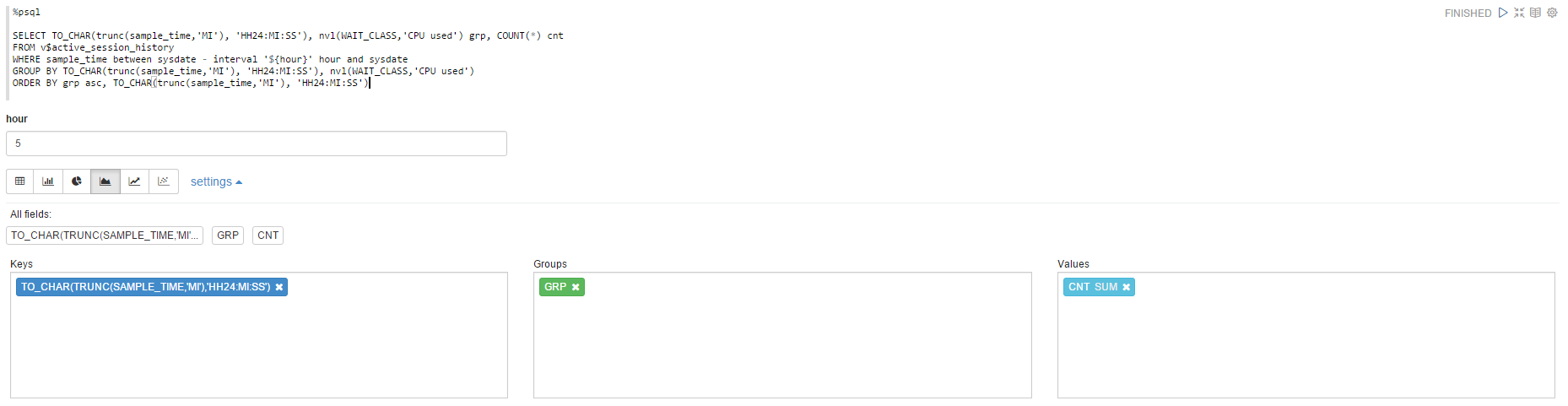
The same, but using the dynamic form to change the range of the data to be selected:
You can also try dynamically updated pages, for example, account tweet statistics: Capture Tweets from the Twitter by Gustavo Arjones
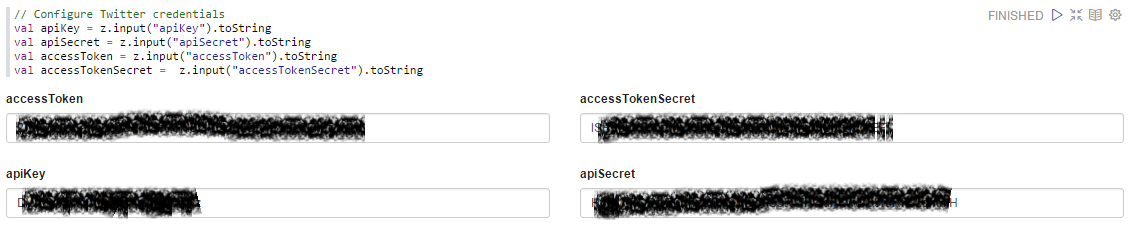
Specify the application settings for accessing your feed:
The code itself, which creates magic:

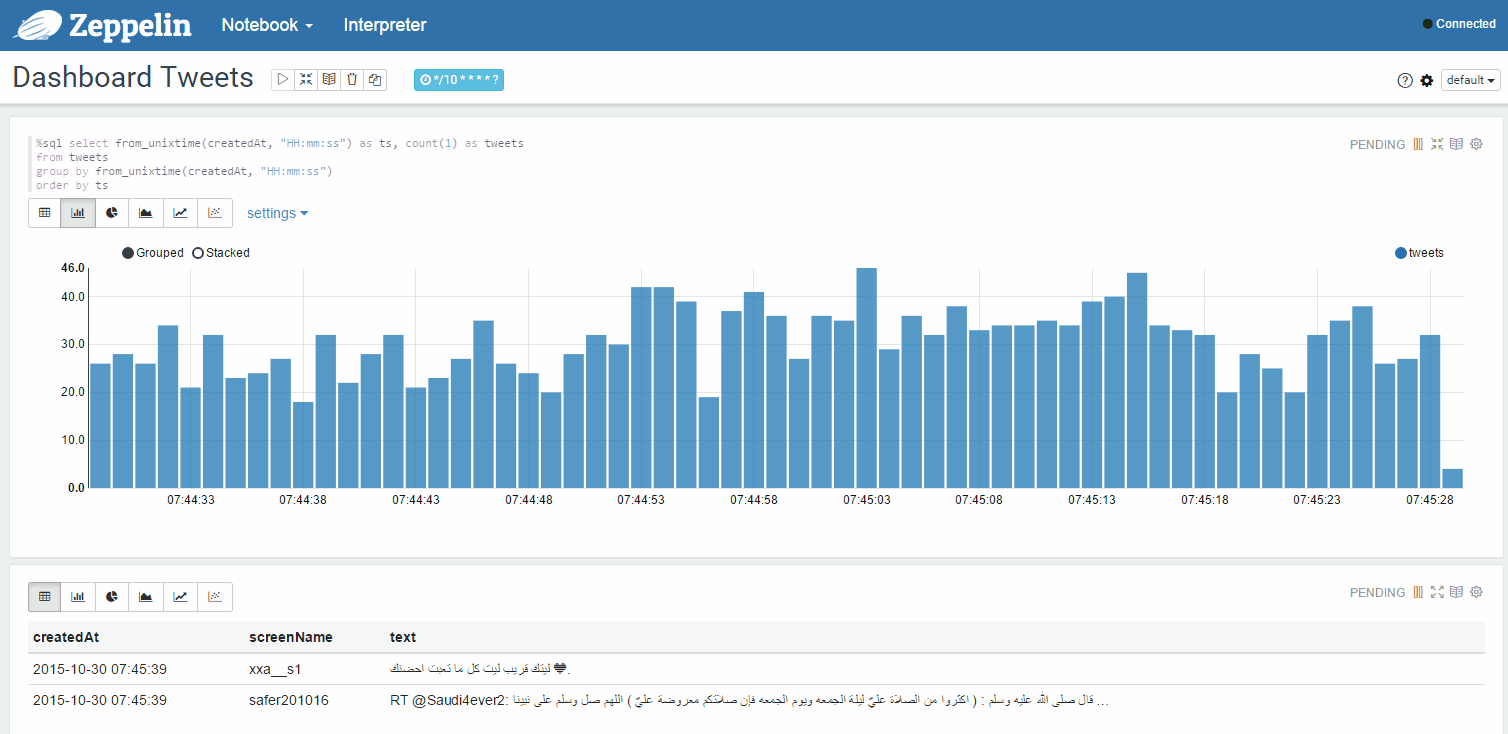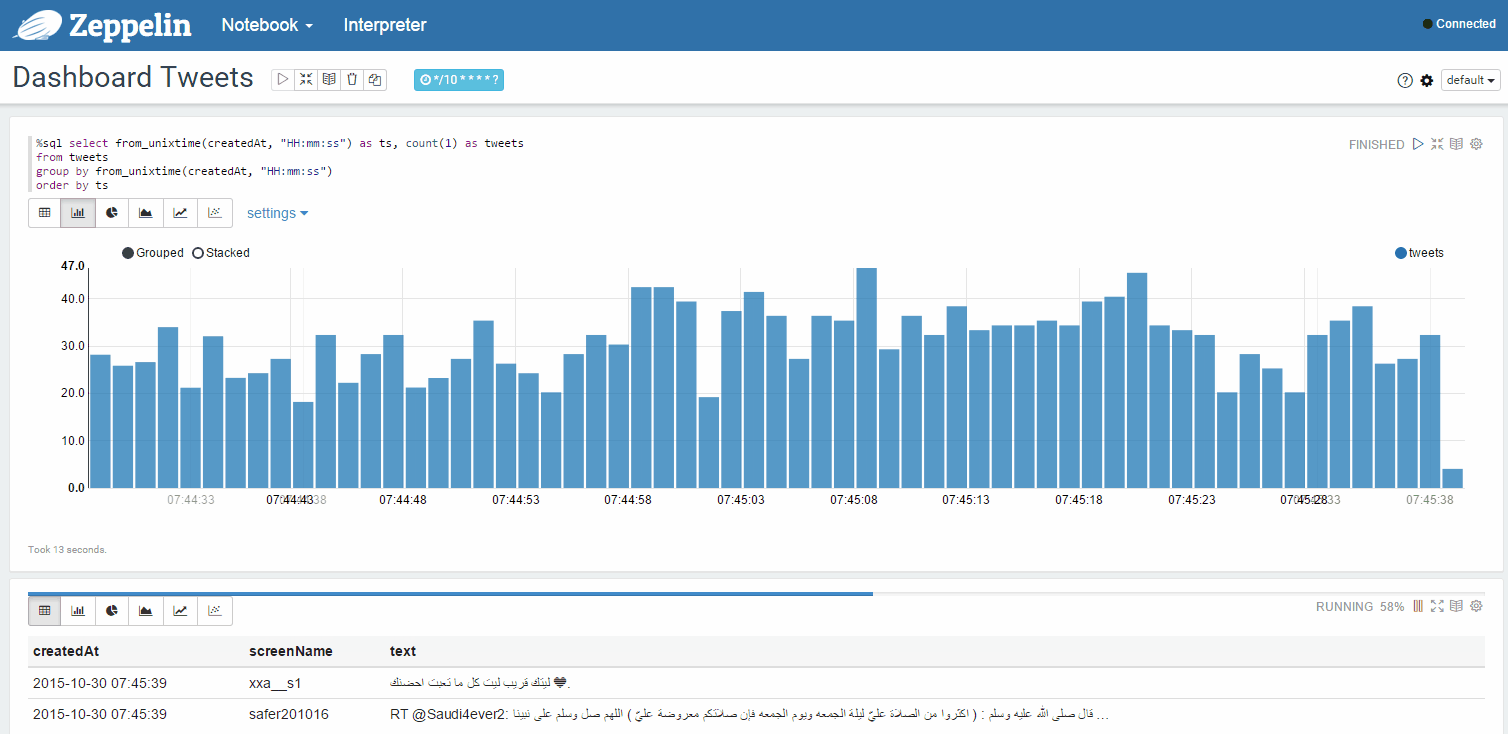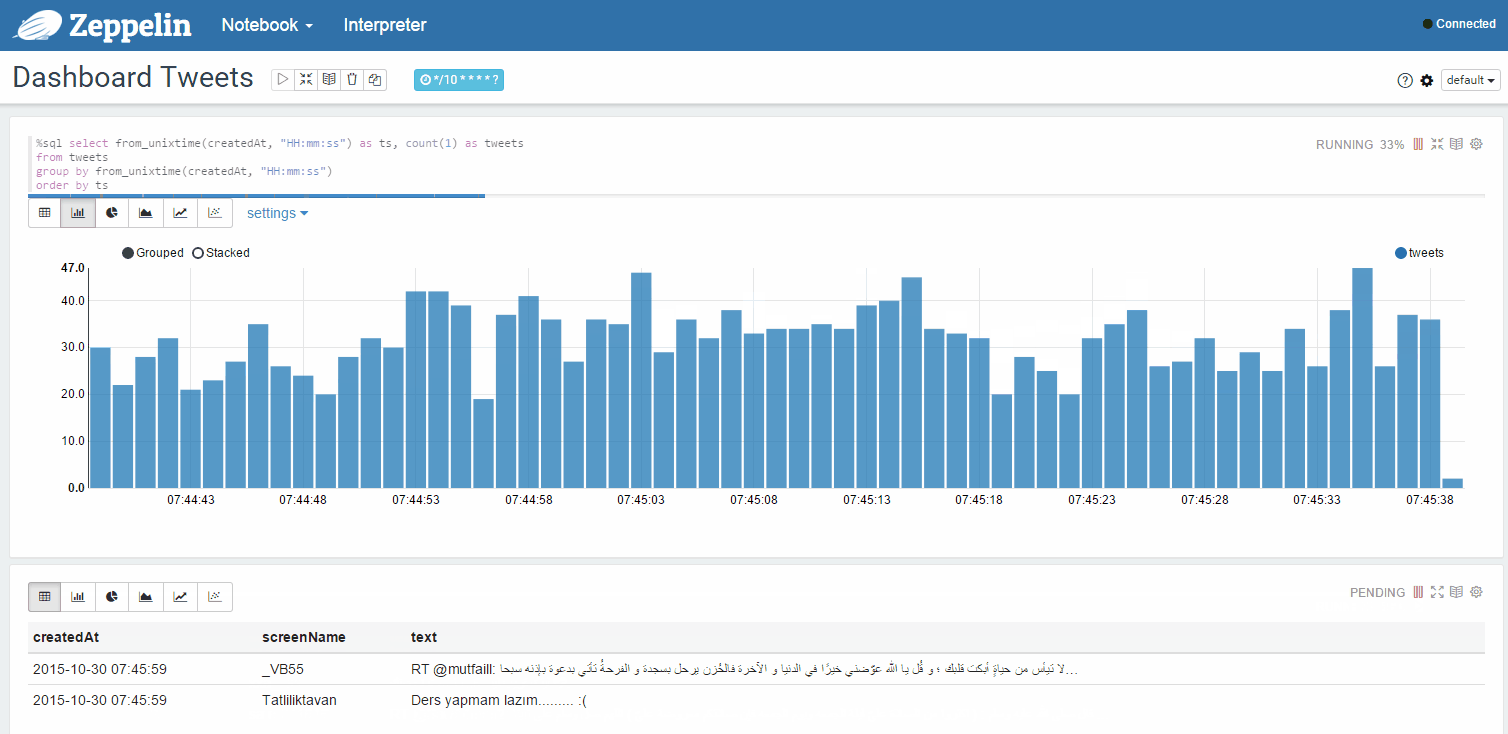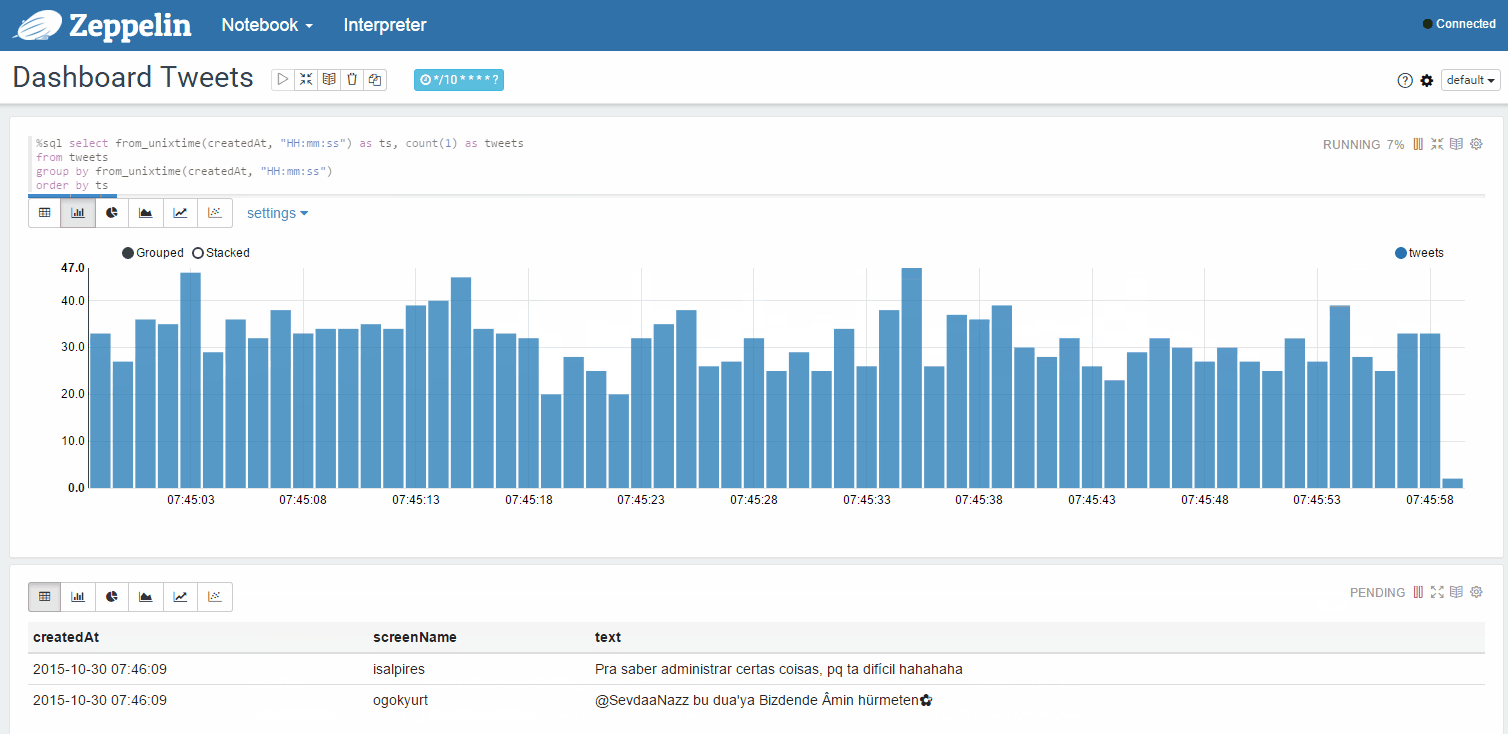
Dynamically updated statistics of tweets from your feed in a separate window:
- Report generator for ad hoc requests;
- Creation of flexible customizable environments for simple monitoring systems and monitoring of key indicators of IT systems.
- While the developer community is underdeveloped. The number of code written in Apache Zeppelin compared to Jupiter Notebook ;
- A set of types of graphs is still small, competitors will be richer;
- There are small bugs, which are few, but they do not interfere fully, without the hassle, to use the basic functionality. "It just works."
Apache Zeppelin is an interactive shell for querying Big Data, working with Machine Learning, subsequent visualization of results, and team development.
In connection with the growth of data volumes, new tasks in the search for new knowledge require for researchers a convenient tool (environment) for their work. The niche of interactive shells is currently one of the promising areas: June 12, 2015, 8 New Big Data Projects To Watch, author: Alex Woodie . We are witnessing an interesting trend - this is the emergence of hybrid software systems that allow simplifying the tasks of preparing and analyzing big data, visualization and collaboration for Data Scientist. A convenient visualization interface provided by Apache Zeppelin will also be useful to the administrator and database developers.
Judging by the activity of developers on the transfer of code to the open access under the wing of the Apache Foundation as part of the Apache Incubator program , the creation of a specialized ZeppelinHub portal for laying out prepared Notebooks, the development team is planning active product development and access to a wider audience.
Thanks for attention!
Prologue
The explosive growth of the Big Data industry, Machine Learing, has required new tools and approaches for working with large data sets. There are such ecosystems and Big Data software products like Hadoop , Spark , Storm , Elasticsearch , etc ... Dozens of different machine learning frameworks with predefined algorithms. Leading universities in the world create many free courses on machine learning and working with Big Data.
There are also tools that solve data visualization problems. I would like to highlight two tools: this is an ecosystem of the programming language R , created for statistical data processing and work with graphics. And Weka is a set of visualization tools and algorithms for data mining and solving forecasting problems. By the way, the development of both tools / programming languages started in 1993 and both from New Zealand :). And of course, this is a set of other visualization tools that almost every team offering the final product already does by itself using popular frameworks for data visualization: D3.js , JfreeChart , HighCharts.js and others.
')
Separately, I would like to highlight the direction of interactive shells for working with big data and machine learning. The most famous and popular tool is the product of the Python community — IPython . Judging by the number of references (I myself did not work closely with it), it is the de facto standard among machine learning specialists. Since 2014, the creator of IPython has launched a new project, Jupyter Notebook , the goal of which is to create an interactive shell that is completely independent of the programming language. Also, DataBricks and Beaker companies are actively working in this direction, which develop the direction of interactive shell tools for Data Scientist with a focus on clouds . In addition to Jupyter Notebook , there are other similar tools, such as Spark Notebook .
So, Apache Zeppelin is one of the representatives of the direction of interactive shells for working with Big Data and machine learning.
Work on the creation of Zeppelin was started in the depths of the South Korean software company NFLabs in 2012-2013 (for more details, see the creation history from the system developer here ).
Initially, the goal was to create a user interface for a variety of SQL over Hadoop systems, such as Hive, Presto, and Shark etc. Then it became clear that there is a need to create a more powerful tool for Data Scientist for collaboration on large projects that are not limited only to SQL. Therefore, the built-in integration with the Apache Spark framework and the ability to work together in a Notebook via WEB was implemented.
Apache Zeppelin features:
- WEB access to an interactive console, SQL data access, Scala, Java, etc .;
- the concept of storing the results of analysis and visualization in the form of a notebook (Notebook);
- data visualization using various types of graphs;
- opportunities to create pivot tables (Pivot);
- Dynamic setting of query parameters in special forms (Dynamic Form);
- the ability to connect other execution environments, SQL backend using the Interpreter API;
Install Apache Zeppelin
System requirements and instructions for installing Apache Zeppelin are available on the project page on GitHub or on the project website.
You can configure the Apache Zeppelin environment using Vagrant on your client machine:
1. github.com/arjones/vagrant-spark-zeppelin
2. github.com/felixcheung/vagrant-projects
or Docker:
hub.docker.com/r/internavenue/centos-zeppelin/~/dockerfile
In my work, I used Vagrant + manual compilation from source codes. You can choose any of the proposed methods.
Configuring Apache Zeppelin + Oracle Bundle
We download the JDBC driver from Oracle (for example, ojdbc7.jar) by reference (registration on the site is required) and post the driver in the CLASSPATH paths. In the case of Apache Zeppelin, we post the driver file in the root directory (/ usr / zeppelin). For Apache Spark, in SPARK_HOME / lib (theoretically, the jdbc driver can be loaded dynamically using the Dependency loader , but I could not get the visibility of classes in the SparkContext).
To work with ojdbc7.jar, you may need to configure the Timezone when the application starts. If you get an error like when trying to access the data: ORA-01882: timezone region not found., Then in the Apache configuration file /usr/zeppelin/conf/zeppelin-env.sh you will need to add the value of your server timezone. For example: ZEPPELIN_JAVA_OPTS -Duser.timezone = UTC
Attempt number 1
The first attempt to access Oracle was made from the Apache Spark environment. Since Spark 1.3, it is recommended to work with the database through the Spark SQL data source API . Specify the database access url, table / dataset and jdbc driver for connecting to the database. Check which fields are available for selection, and load the data set as a table into memory in the SQLContext environment using the registerTempTable () procedure, after which you can query the data source.
Now everything is ready for the query on the OBJ table
Unfortunately, full access to Oracle data in Apache Spark does not work. When trying to select data with data type NUMBER, we get the following error:
This problem is known and described in the Apache Spark JIRA project: Spark sql jdbc fails for Oracle NUMBER type columns
While there is no solution, respectively, fully, directly, working with Oracle DBMS data in Apache Spark is not easy. As a workaround, in Oracle DBMS, you can create views in which to do NUMBER to VARCHAR2 conversion and use them to work from Apache Spark. But these are additional difficulties with administration, issuance of rights, etc.
Attempt number 2
Let's try to get access to Oracle DBMS directly, not through Spark. The developers came up with a system of extensions for this purpose - called Interpreters. There is no separate plugin for Oracle DB yet. But we will try to use ready for Postgresql - after all it is JDBC . Make the necessary changes in the Zeppelin interface on the Interpreters tab for psql:
And we try to perform a test query:
Let's try to visualize data from the history of active sessions:
The same, but using the dynamic form to change the range of the data to be selected:
You can also try dynamically updated pages, for example, account tweet statistics: Capture Tweets from the Twitter by Gustavo Arjones
Specify the application settings for accessing your feed:
The code itself, which creates magic:
Dynamically updated statistics of tweets from your feed in a separate window:
Possible uses (optional):
- Report generator for ad hoc requests;
- Creation of flexible customizable environments for simple monitoring systems and monitoring of key indicators of IT systems.
Disadvantages:
- While the developer community is underdeveloped. The number of code written in Apache Zeppelin compared to Jupiter Notebook ;
- A set of types of graphs is still small, competitors will be richer;
- There are small bugs, which are few, but they do not interfere fully, without the hassle, to use the basic functionality. "It just works."
Apache Zeppelin is an interactive shell for querying Big Data, working with Machine Learning, subsequent visualization of results, and team development.
In connection with the growth of data volumes, new tasks in the search for new knowledge require for researchers a convenient tool (environment) for their work. The niche of interactive shells is currently one of the promising areas: June 12, 2015, 8 New Big Data Projects To Watch, author: Alex Woodie . We are witnessing an interesting trend - this is the emergence of hybrid software systems that allow simplifying the tasks of preparing and analyzing big data, visualization and collaboration for Data Scientist. A convenient visualization interface provided by Apache Zeppelin will also be useful to the administrator and database developers.
Judging by the activity of developers on the transfer of code to the open access under the wing of the Apache Foundation as part of the Apache Incubator program , the creation of a specialized ZeppelinHub portal for laying out prepared Notebooks, the development team is planning active product development and access to a wider audience.
Used software:
Thanks for attention!
Source: https://habr.com/ru/post/269769/
All Articles