How can you make a fault-tolerant storage system of data from domestic servers

Cluster nodes: Etegro domestic server (2 AMD Opteron 6320, 16 GB RAM, 4 HDD)
Data storage systems used now in practice in Russia are conventionally divided into three categories:
- Very expensive high-end storage systems;
- Midrange arrays (tearing, HDD, hybrid solutions);
- And economical clusters based on SSD arrays and HDD arrays from “everyday” disks, often assembled by hand.
And not the fact that the latest solutions are slower or less reliable than the Highland. Just use a completely different approach, which is not always suitable for the same bank, for example. But it’s great for almost all mid-sized businesses or cloud solutions. The general meaning is that we take a lot of cheap “domestic” hardware and connect them to a fault-tolerant configuration, compensating for the problems with the correct virtualization software. An example is domestic RAIDIX, the creation of Petersburg colleagues.
And so EMC came to this market, known for its damn expensive and reliable hardware with software that allows you to easily raise a VMware farm, a virtual storage system, and any application on the same x86 servers. And the story began with the servers of Russian production.
Russian servers
The original idea was to take our domestic iron and pick up on it the pieces of infrastructure that are missing for import substitution. For example, the same hotbed of virtual machines, VDI servers, butt storage systems and application servers.
')
The Russian server is such a miracle piece of hardware, which is 100% assembled in Russia and is 100% Russian by all standards. In practice, they carry individual parts from China and other countries, buy domestic wires and assemble them in the territory of the Russian Federation.
It turns out not so bad. You can work, although the reliability is lower than the same HP. But this is offset by the price of iron. Then we come to a situation in which not the most stable hardware should be compensated by a good control software. At this stage, we began experimenting with EMC ScaleIO.
The experiment turned out to be good, during the experiments it turned out that iron is not very important. That is - you can replace the proven, from well-known brands. It turns out a little more expensive, but less problems with the service.
As a result, the concept has changed: now we are simply talking about the benefits of ScaleIO on various hardware, including (and above all) from the lower price segment.
But to the point: test results
Here is the principle of operation of ScaleIO (http://habrahabr.ru/company/croc/blog/248891/) - we take servers, stuff them to capacity with disks (for example, the same SSD pieces that were intended to replace the HDD at one time) and we combine all this into a cluster:

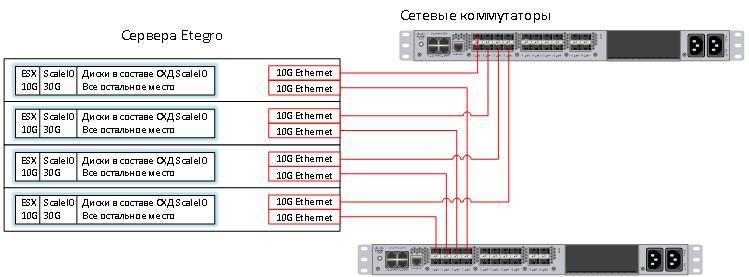
The configuration we tested in the lab this time is the integration of EMC ScaleIO and VMware. Colleagues from Etegro kindly lent us 4 servers with 2 AMD Opteron processors (tm) Processor 6320 and 16 GB of RAM in each. Each had 4 discs. Not the most capacious configuration, I would prefer servers on 25 2.5-inch disks, but I have to work with what I have and not with what I want.
Here are the servers in the rack:

I divided the entire volume of disks in the server into 3 parts:
- 10 Gb for ESX. That is quite enough.
- 30 GB for internal use ScaleIO, but more on that later.
- The rest of the place will be given through ScaleIO.
The first thing to do is install VMware. ESX we will put on the network, so faster. The task is not new, but a virtual machine with a PXE server has long taken a well-deserved place in my laptop.

As you can see, there is a lot of test equipment in our lab. On the right, there are 4 more racks and 12 more on the first floor. We can assemble almost any stand at the request of the customer.
The technology of Software Defined Storage is such that each node can request a sufficiently large amount of information from other nodes. This fact means that the bandwidth and response time of the BackEnd network is very important in such solutions. 10G Ethernet is well suited for this task, and the Nexus switches are already in this rack.
Here is a diagram of the resulting solution:
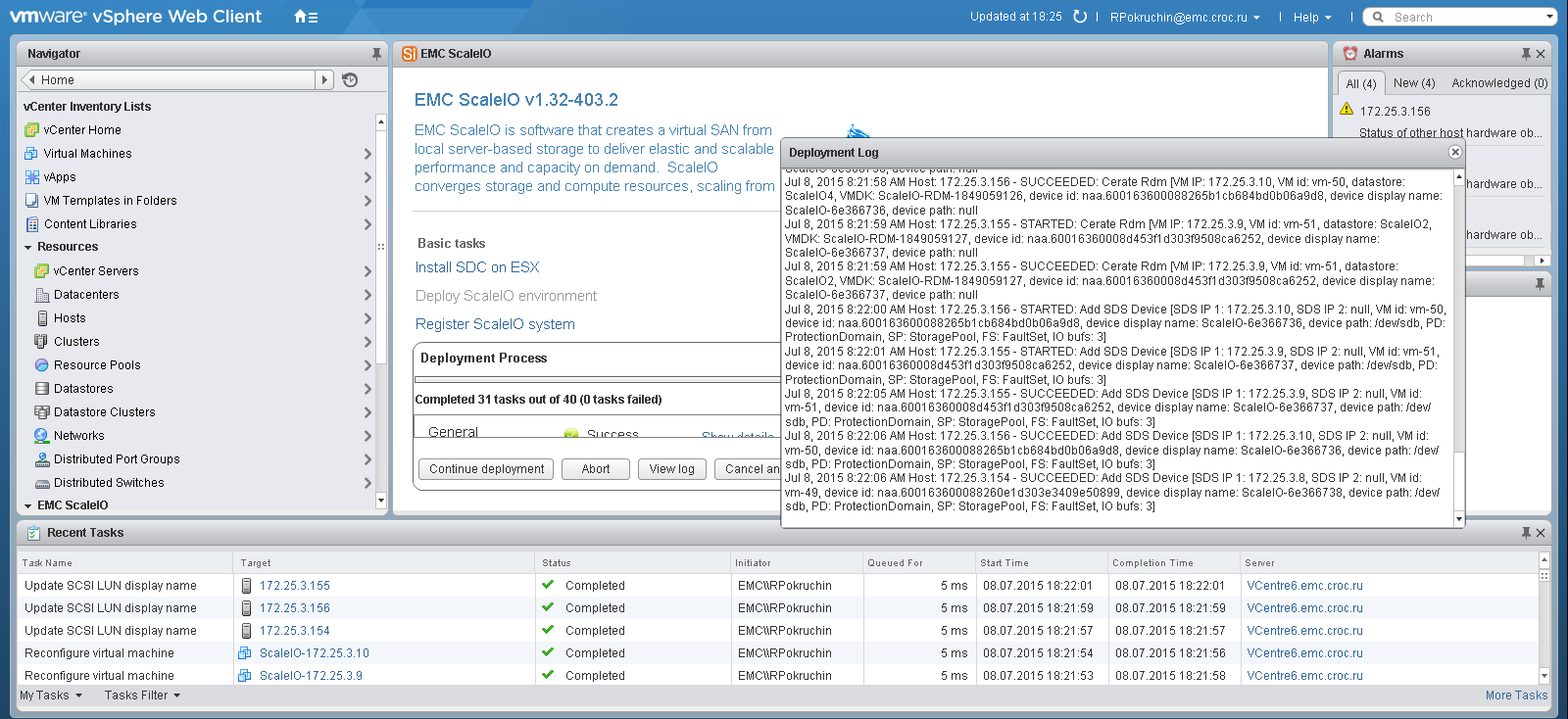
Installing ScaleIO on VMware is very easy. In fact, it consists of 3 points:
- Install the plugin for vSphere;
- We open the plugin and run the installation, in the same paragraph you need to answer 15-20 questions of the wizard.
- We look, how ScaleIO independently creeps on servers.
If the wizard is completed without errors, a special partition for ScaleIO will appear in vSphere, in which you can create moons and give them to ESX servers.
Or you can use the standard ScaleIO console by installing it on a local computer.
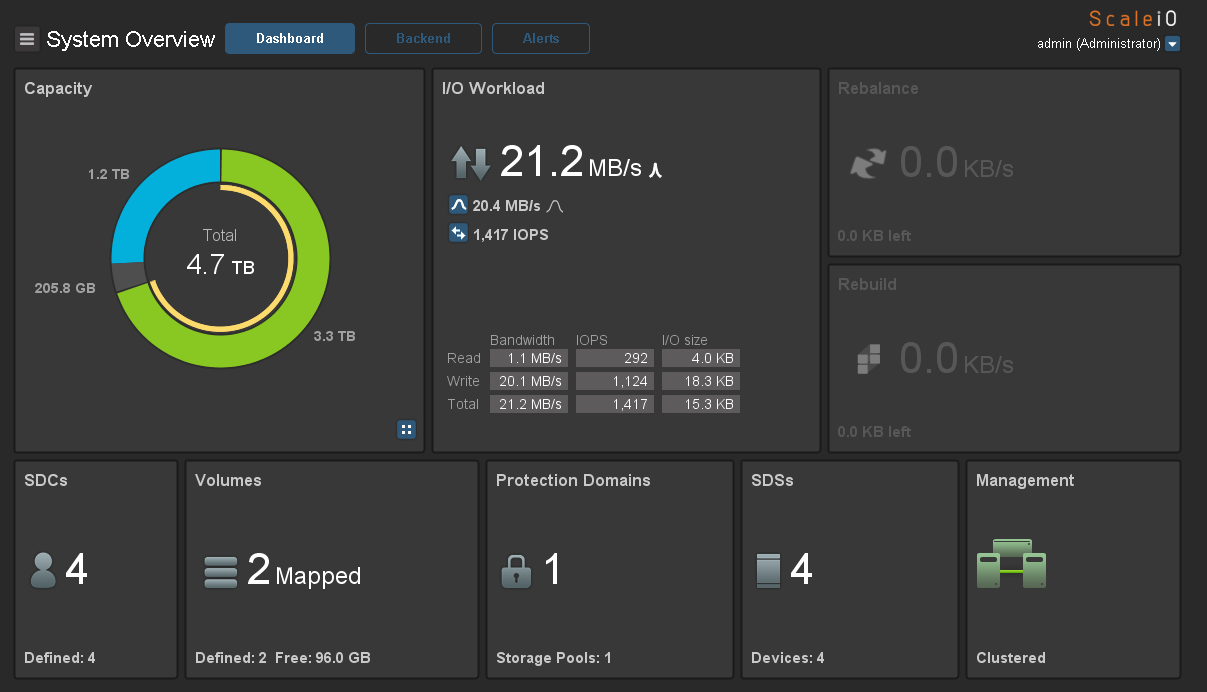
Now a little test for performance. I created a virtual machine with 2 disks of 50Gb on each host and divided them evenly across datastores. Load generated using IOmeter. Here are the maximum results that I managed to get on a load of 100% random, 70% read, 2k.
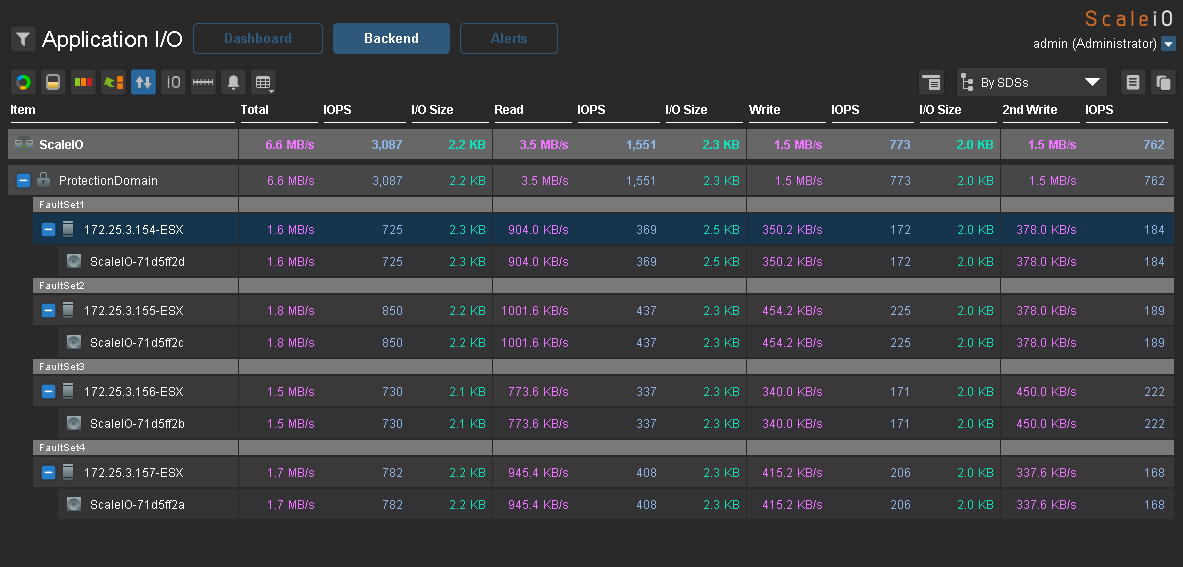
3000 application IO from 4 servers with SAS disks is a good result.
As an entertainment, I tried to "fill up" the system, pulling the nodes in different sequences and at different intervals. If you pull the nodes one at a time and give ScaleIO enough time for a rebuild, then the virtual machines will work even if only one node remains. If you turn off 3 nodes per minute, for example, access to the shared space will stop until those nodes are turned back on. Data becomes available, and the array performs data integrity and rebuild (if necessary) in the background. Thus, the solution is obtained sufficiently reliable in order to use it on combat missions.
Perhaps all about virtualization. It's time to summarize.
Summary
Pros:
- The price of the solution (processor power + memory + disks) is competitive and in many cases will be significantly lower than the servers + storage in similar mono-vendor offers.
- You can use any hardware and get a replacement for “big beautiful” storage for the same tasks. If needed, servers can be replaced with more powerful ones without purchasing any additional licenses for ScaleIO. It is licensed poter byte without being tied to hardware.
- The solution is convergent . Virtual machines and storage on the same server. It is very convenient for almost any medium-sized business. Flash storage is no longer fiction on this level.
- Plus it requires less space in racks , less power consumption.
- Good balancing - even distribution of IO across all disk resources.
- The solution can be spread to 2 different sites by adjusting the mirroring between them at the level of a single ScaleIO cluster.
- Virtual synchronization can be used for synchronous and asynchronous replication between clusters.
Minuses:
- First, you have to apply the brain. Expensive solutions, as a rule, are good because they are implemented very quickly and require almost no special training. Considering that ScaleIO is, in fact, a self-assembled storage system, you will have to figure out the architecture, smoke a couple of forums for optimal configuration, run an experiment on your data to select the optimal configuration.
- Secondly, for redundancy and fault tolerance, you pay disk space. The conversion ratio of the raw space to user space changes depending on the configuration, and you may need more disks than you originally thought.
I remind you, here you can read about the software part in detail , and I will be happy to answer questions in the comments or mail RPokruchin@croc.ru. And a month later, on November 26, my colleagues and I will do an open test drive with a Scale IO vacuum Kärcher, a sledgehammer, and other things until the men say, “Aahhh, zarraz.” Register here .
Source: https://habr.com/ru/post/269289/
All Articles