Algorithm for extracting information in ABBYY Compreno. Part 2
Hello again!
I hope you are interested in our yesterday's post about the information extraction system ABBYY Compreno , in which we talked about the system architecture, the semantic-syntactic parser and its role and, most importantly, about information objects.
Now it is time to talk about the most interesting - how the information extraction engine is arranged.
')

So the goal of our system is to build an RDF graph with the extracted information.
However, the generation of the RDF-graph occurs only at the very end of the system. In the course of work, a more complex object is used to store retrieved information, which we call the “bag of statements”. It is a set of non-contradictory logical statements about information objects and their properties.
The entire work of the information extraction system can be described as the process of filling a bag of statements.
Important properties of bag statements:
The main difference between the RDF-graph and the bag of statements is that the latter allows for functional dependencies.
For example, it can be argued that the set of values of a property of one object always includes the set of values of some other property of another object. Such dependencies are dynamic, the system implements their recalculation itself.
This article is not possible to parse allegations in detail. The main types of statements are shown in the figure below.
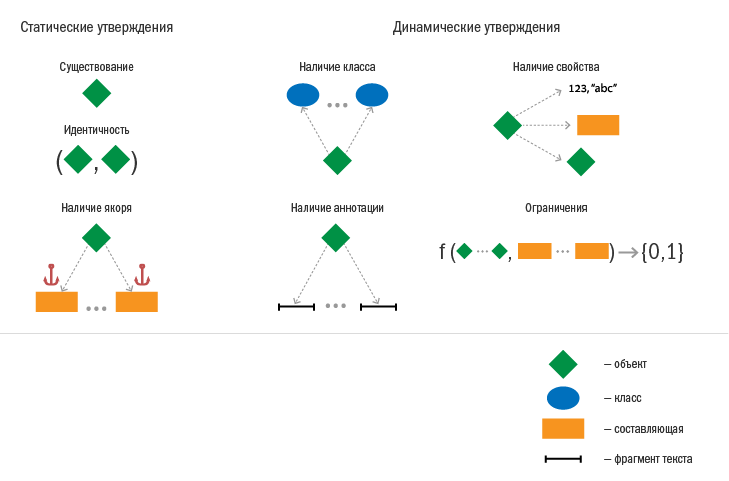
We talked more about the statements in an article at the Dialog conference .
Who fills the bag of statements?
The bag of statements is filled in the process of applying the rules. There are two types of rules:
But how do the rules trigger?
A key concept for understanding the algorithm is matching. By mapping, we mean the following:
The operation of the algorithm begins with the fact that the system processes the rules that contain only templates for parse trees (without object conditions). There is not a single object in the “bag of statements” so far; therefore, rules with object conditions are not yet involved in generating comparisons.
All matches found are placed in a special sorted list queue. This queue is an important structure, the extraction process continues until this queue contains at least one match. The queue is dynamically updated with new comparisons in the process of work, but we will not get ahead of ourselves.
So, the first mappings were generated and placed in a queue. Now the system starts to turn to the queue and at each step extracts the highest priority mapping. On the one hand, priority can be influenced by onto-engineers (a partial order relation is set on the set of rules), on the other hand the system itself can calculate the most successful match.
After the highest priority matching is chosen, a set of statements is formed on the right side of the rule from which it was obtained. The system tries to make these statements take effect, i.e. tries to put this set in a general bag of statements. Here nuances are possible - assertions may conflict with assertions added to the bag earlier.
Contradictions can be of different types:
If the insertion failed (there was a contradiction), then the matching is discarded and the following is selected from the queue. In case of successful insertion, before the selection of the next match is started, the search mechanism for new matches is launched, and the queue of comparisons can be replenished. Please note that as a result of placing new statements in the bag, new rules may start to work, as the overall context changes. The following changes are possible - the emergence of new objects and "anchors", the filling of new attributes of the object, the emergence of new concepts in the object. Because of these changes, those rules can start to work, the template part of which could not be matched before, and the line of comparisons will be replenished.
The following process illustrates the process well.
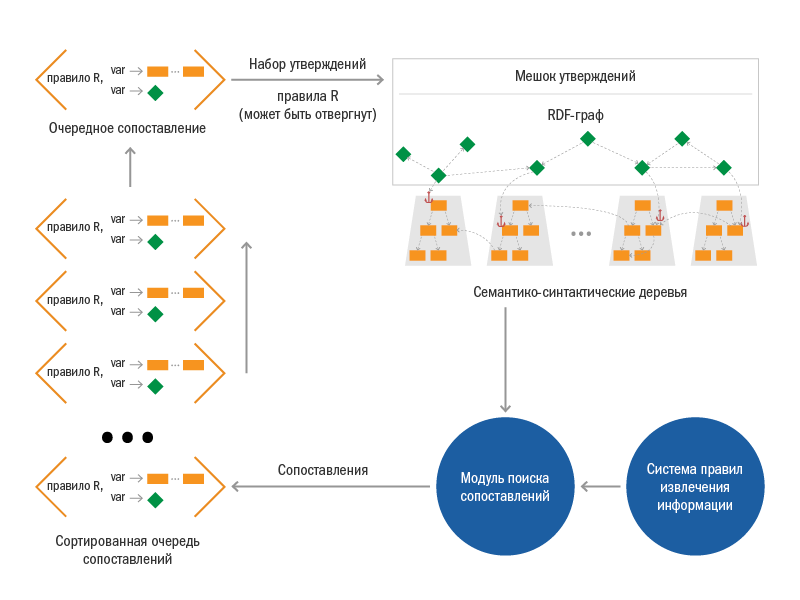
In order to realize all this, we had to work hard. One of the most complex components of the system is the search engine for matching. It has a built-in bytecode interpreter of compiled rules, a system of special indexes over semantic-syntactic trees, a module for tracking changes in the bag of statements, and some other mechanisms. We note some basic features of the mapping search mechanism:
As a result of the work, we have an algorithm that has the following features:
If you want to learn a more formal description of the algorithm, we advise you to refer to the article from the Dialog conference .
This technology provides a wide range of opportunities that allow us to solve various problems, focused on current market needs. About what real business challenges we face, and how Compreno copes with them, we will soon tell in our blog.
I hope you are interested in our yesterday's post about the information extraction system ABBYY Compreno , in which we talked about the system architecture, the semantic-syntactic parser and its role and, most importantly, about information objects.
Now it is time to talk about the most interesting - how the information extraction engine is arranged.
')
RDF and approval bag
So the goal of our system is to build an RDF graph with the extracted information.
However, the generation of the RDF-graph occurs only at the very end of the system. In the course of work, a more complex object is used to store retrieved information, which we call the “bag of statements”. It is a set of non-contradictory logical statements about information objects and their properties.
The entire work of the information extraction system can be described as the process of filling a bag of statements.
Important properties of bag statements:
- Assertions can only be added. Delete - not.
- All statements in the bag do not contradict each other.
- By a bag of statements, at any time you can construct an annotated RDF-graph consistent with the ontology.
The main difference between the RDF-graph and the bag of statements is that the latter allows for functional dependencies.
For example, it can be argued that the set of values of a property of one object always includes the set of values of some other property of another object. Such dependencies are dynamic, the system implements their recalculation itself.
This article is not possible to parse allegations in detail. The main types of statements are shown in the figure below.
We talked more about the statements in an article at the Dialog conference .
Inference based on data
Who fills the bag of statements?
The bag of statements is filled in the process of applying the rules. There are two types of rules:
- Rules for extracting information.
We have already discussed them in the previous article; they allow us to describe fragments of semantic-syntactic trees, upon detection of which certain sets of logical statements come into force. Schematically, the rule can be represented as follows:[ ] => [ ]
Extraction rules are of two types: without object conditions (based only on the tree template) and with object conditions (based on both the tree template and previously selected objects) - Identification rules.
Used in situations where you need to combine multiple information objects. It can be schematically represented as follows:<% 1 %> <% 2 %> [ ] => [ ]
If the rule manages to work, then the bag is replenished with new statements: in the rules for extracting information - due to explicitly written statements in the right part of the rule; in the identification rules - due to the statement of identity.
Information Extraction Algorithm
But how do the rules trigger?
A key concept for understanding the algorithm is matching. By mapping, we mean the following:
- For the rules for extracting information, overlaying the tree pattern described in the rule onto a fragment of the semantic-syntactic tree.
- For identification rules, correlation of the restrictions of the identification rule with specific information objects.
The operation of the algorithm begins with the fact that the system processes the rules that contain only templates for parse trees (without object conditions). There is not a single object in the “bag of statements” so far; therefore, rules with object conditions are not yet involved in generating comparisons.
All matches found are placed in a special sorted list queue. This queue is an important structure, the extraction process continues until this queue contains at least one match. The queue is dynamically updated with new comparisons in the process of work, but we will not get ahead of ourselves.
So, the first mappings were generated and placed in a queue. Now the system starts to turn to the queue and at each step extracts the highest priority mapping. On the one hand, priority can be influenced by onto-engineers (a partial order relation is set on the set of rules), on the other hand the system itself can calculate the most successful match.
After the highest priority matching is chosen, a set of statements is formed on the right side of the rule from which it was obtained. The system tries to make these statements take effect, i.e. tries to put this set in a general bag of statements. Here nuances are possible - assertions may conflict with assertions added to the bag earlier.
Contradictions can be of different types:
- Ontological contradictions (the cardinality of properties is violated, the compatibility of concepts of one object with each other)
- Conflict with a constraint already added to the bag. Such conditions can be set by the onengineers themselves in the rules, as a rule, they are arbitrary conditions on the graph.
If the insertion failed (there was a contradiction), then the matching is discarded and the following is selected from the queue. In case of successful insertion, before the selection of the next match is started, the search mechanism for new matches is launched, and the queue of comparisons can be replenished. Please note that as a result of placing new statements in the bag, new rules may start to work, as the overall context changes. The following changes are possible - the emergence of new objects and "anchors", the filling of new attributes of the object, the emergence of new concepts in the object. Because of these changes, those rules can start to work, the template part of which could not be matched before, and the line of comparisons will be replenished.
The following process illustrates the process well.
In order to realize all this, we had to work hard. One of the most complex components of the system is the search engine for matching. It has a built-in bytecode interpreter of compiled rules, a system of special indexes over semantic-syntactic trees, a module for tracking changes in the bag of statements, and some other mechanisms. We note some basic features of the mapping search mechanism:
- Able to find all the mappings for the rules for extracting information without object conditions
- Constantly monitors the contents of the statements bag and every time new statements appear in it, it tries to generate new comparisons (already with object conditions)
- At each work step, it is possible to generate both comparisons for new rules for information extraction and identification, and comparisons for rules for which other comparisons have already been generated.
This happens in cases when more than one information object satisfies a certain object condition of a rule — each variant is considered as part of a separate comparison.
As a result of the work, we have an algorithm that has the following features:
- Does not consider alternatives. If any mapping is in conflict with the current state of the bag of statements, it is simply discarded.
The use of such a greedy principle was possible primarily due to the fact that linguistic homonymy has already been removed by the semantic-syntactic parser - we almost do not have to hypothesize what a particular tree node is. - The engineer has the ability to influence the order of the rules. A partial order relation is introduced on the rule set. If both triggers are possible and an order is set between them, then the system ensures that the trigger of one of the rules must occur before the trigger of the other. For convenience, the ability to organize groups of rules is also supported. The partial order relation is transitive. When compiling the system of rules, it is checked that the partial order is entered correctly, the system is able to detect cycles. At the same time, the described approach is significantly different from the consistent application of all rules, since the partial order set on the rules only affects the choice between successive triggers, but does not block the reapplication of the same rules.
If you want to learn a more formal description of the algorithm, we advise you to refer to the article from the Dialog conference .
This technology provides a wide range of opportunities that allow us to solve various problems, focused on current market needs. About what real business challenges we face, and how Compreno copes with them, we will soon tell in our blog.
Source: https://habr.com/ru/post/269273/
All Articles