Go Planner
Translator's Preamble: This is a fairly free translation, albeit not the most recent (June 2013), but an intelligible publication about a new planner of parallel branches of execution in Go. The advantage of this note is that it is quite simple, "on the fingers" describes a new planning mechanism for review. For those who are not satisfied with the explanation "on the fingers" and who would like a detailed presentation, I recommend Scheduling Multithreaded Computations by Work Stealing - 29 pages of presentation with a strict and complex mathematical apparatus for analyzing performance, 48 bibliography positions.
One of the biggest innovations in Go 1.1 was a new dispatcher designed by Dmitry Vyukov. The new scheduler gave such a dramatic increase in performance for parallel programs without changing the code that I decided to write something about it.
Most of what is written here is already described in the original text from the author. This text is rather detailed, but it is purely technical.
Everything you need to know about the new planner is contained in this author's text, but my description is illustrative, which exceeds it for understanding.
')
Before we take a look at the new planner, we need to figure out why we need it at all. Why create a user-space scheduler when the operating system schedules threads for you?
The POSIX threading APIs are a very logical continuation of the process model existing in the Unix operating system, and, if so, threads are received by many of those controls as processes.
Threads have their own signal mask, can be assigned to processors using an affinity mask, can be entered into groups, and can be tested for what resources they use. All these elements add overhead for objects, and since they are simply not needed for Go programs using Go-routines, these overhead costs avalanche add up when you have 100,000 threads in your program.
Another problem is that the operating system cannot make meaningful planning decisions based on the Go model. For example, the garbage collector requires all threads to be stopped when the collector starts and their memory must be in a synchronized state. This implies waiting for running threads to reach a point where we know for sure that the memory is in an adequate state.
When you have many threads planned at random points, there is a high probability that you will have to wait for most of them to reach a consistent state. The Go scheduler, on the other hand, can only decide to re-plan in places where he knows that the memory is in consistent states. This means that when we stop for garbage collection, we are forced to expect only those threads that are actively running on the processor cores.
Usually there are 3 models for cutting calculations into threads. The first is N: 1, where several user threads are running on a single kernel thread of the operating system. This method has the advantage of very fast context switching, but it is not possible to take advantage of multi-core systems. The second method is 1: 1, where each user thread of execution coincides with one thread of the operating system. It uses all the kernels automatically, but context switching is slow because it requires interruptions in the operating system.
Go tries to take the best of both worlds using the M: N planner. At the same time, an arbitrary number of Go-routines (M) is planned for an arbitrary number of threads (N) of the operating system. This way you get both a fast context switch and the ability to use all the cores on your system. The main disadvantage of this approach is the complexity of its inclusion in the scheduler.
To perform the scheduling task, the Go scheduler uses 3 basic entities:
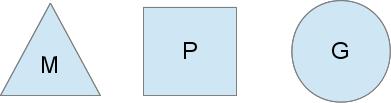
The triangle represents the flow of the operating system. The execution of such a thread is controlled by the operating system, and it works in much the same way as your standard POSIX threads. In executable code, this is called the M machine.
The circle represents the go-routine. It includes a stack, a command pointer, and other important information for planning a go-routine, such as a channel that may be blocked on it. In the executable code, this is denoted as G.
The rectangle represents the planning context. You can understand it as a localized version of the scheduler that executes Go-rutin code in a single kernel thread. This is the important part that allows us to get away from the N: 1 scheduler and the M: N scheduler. At runtime, the context is denoted as P for the processor. In general, this is all, briefly.

The figure shows 2 kernel threads (M), each owning a context (P), each of which performs a Go-routine. For the purposes of the Go routine, the thread must hold the context. The number of contexts is set at the start from the value of the GOMAXPROCS environment variable, or by the GOMAXPROCS () runtime function. Normally this value does not change during the execution of your program.
The fact of a fixed number of contexts means that only GOMAXPROCS of Go code areas are executed simultaneously at any time. We can use this to configure the Go process call for an individual computer, for example, on a 4-core PC, execute the Go code in 4 threads.
Tinted gray in the figure Go-routines are not performed, but are ready for planning. They are placed in lists called run queues. Go-routines are added to the end of the execution queue each time the next go-routine is executed by the go operator. Each time the context has to perform the next Go-routine from the planning point, it pushes the Go-routine out of its execution queue, sets its stack and instruction pointer, and the Go-routine begins.
To prevent disagreement between mutexes, each context has its own local execution queue. The previous version of the Go scheduler had only a global execution queue, with protection by its mutex. Threads were often blocked waiting for the mutex to be released. It was very unfortunate when you use a 32-core machine, wanting to get the maximum performance out as much as possible.
The scheduler keeps scheduling in such a stable state as long as all contexts have running Go routines. However, there are several scenarios that can change this behavior.
You might be wondering, why do we need contexts at all? Can't we just attach execution queues to threads and get rid of contexts? Unreal. The point is that we have contexts so that we can pass them to other threads if the current thread has to block for some reason.
An example of when we need to block is when we make a system call. Since the thread cannot simultaneously execute code and be blocked on a system call, we need to pass the context, because it can delay scheduling.

Here we see a thread abandoning its context, so another thread can start it. The scheduler will make sure that there are enough threads to execute all the contexts. M1 in the figure above can be specially created only for processing a system call, or it can come from some thread pool. The system call that executes the thread will be frozen on the Go-routine that makes the system call, since it is technically still running, although it is blocked in the operating system.
When the system call returns, the thread should attempt to get a context in order to start the returning Go routine. The normal mode of action is to borrow the context from one of the other threads. If the thread cannot borrow, it will put the Go-routine into the global execution queue, returning to the pool of free streams, or going to sleep.
The global execution queue is the execution queue from where contexts are retrieved (jobs) when they end in their local queues. Contexts also periodically check the global queue for Go-Wireout. Otherwise, the go-routines in the global queue may never start and die of starvation.
Such system call processing explains why Go programs run in multiple threads, even when GOMAXPROCS is set to 1. The runtime uses Go routines for system calls, leaving threads following them.
Another way that the stable state of the system can change is when the context falls out of the Go-Route schedule. This can occur if the amounts of work on the execution queues of the contexts are unbalanced. This can happen when the context, in the end, exhausts its turn of execution, despite the fact that there is still work to be done in the system. To continue executing Go code, the context may take Go rouins from the global execution queue, but if there are none and there, it must receive them from another location.
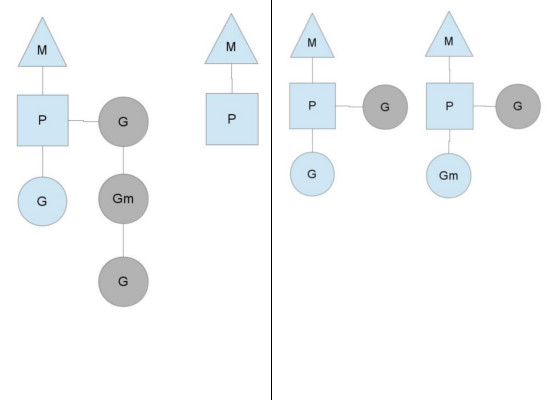
This is somewhere in other contexts. When the context is exhausted, it will attempt to borrow about half of the execution queue from another context. This ensures that there is always work to be performed on each of the contexts, which in turn confirms that all threads are working at the limit of their capabilities.
There are many more details in the scheduler, like cgo threads, LockOSThread () function, and integration with network pulling. They go beyond these notes, but still deserve to be studied. I may write about them later. Of course, many interesting constructs can be found in the Go runtime libraries.
Introduction
One of the biggest innovations in Go 1.1 was a new dispatcher designed by Dmitry Vyukov. The new scheduler gave such a dramatic increase in performance for parallel programs without changing the code that I decided to write something about it.
Most of what is written here is already described in the original text from the author. This text is rather detailed, but it is purely technical.
Everything you need to know about the new planner is contained in this author's text, but my description is illustrative, which exceeds it for understanding.
')
Why go planner at all?
Before we take a look at the new planner, we need to figure out why we need it at all. Why create a user-space scheduler when the operating system schedules threads for you?
The POSIX threading APIs are a very logical continuation of the process model existing in the Unix operating system, and, if so, threads are received by many of those controls as processes.
Threads have their own signal mask, can be assigned to processors using an affinity mask, can be entered into groups, and can be tested for what resources they use. All these elements add overhead for objects, and since they are simply not needed for Go programs using Go-routines, these overhead costs avalanche add up when you have 100,000 threads in your program.
Another problem is that the operating system cannot make meaningful planning decisions based on the Go model. For example, the garbage collector requires all threads to be stopped when the collector starts and their memory must be in a synchronized state. This implies waiting for running threads to reach a point where we know for sure that the memory is in an adequate state.
When you have many threads planned at random points, there is a high probability that you will have to wait for most of them to reach a consistent state. The Go scheduler, on the other hand, can only decide to re-plan in places where he knows that the memory is in consistent states. This means that when we stop for garbage collection, we are forced to expect only those threads that are actively running on the processor cores.
Characters
Usually there are 3 models for cutting calculations into threads. The first is N: 1, where several user threads are running on a single kernel thread of the operating system. This method has the advantage of very fast context switching, but it is not possible to take advantage of multi-core systems. The second method is 1: 1, where each user thread of execution coincides with one thread of the operating system. It uses all the kernels automatically, but context switching is slow because it requires interruptions in the operating system.
Go tries to take the best of both worlds using the M: N planner. At the same time, an arbitrary number of Go-routines (M) is planned for an arbitrary number of threads (N) of the operating system. This way you get both a fast context switch and the ability to use all the cores on your system. The main disadvantage of this approach is the complexity of its inclusion in the scheduler.
To perform the scheduling task, the Go scheduler uses 3 basic entities:
The triangle represents the flow of the operating system. The execution of such a thread is controlled by the operating system, and it works in much the same way as your standard POSIX threads. In executable code, this is called the M machine.
The circle represents the go-routine. It includes a stack, a command pointer, and other important information for planning a go-routine, such as a channel that may be blocked on it. In the executable code, this is denoted as G.
The rectangle represents the planning context. You can understand it as a localized version of the scheduler that executes Go-rutin code in a single kernel thread. This is the important part that allows us to get away from the N: 1 scheduler and the M: N scheduler. At runtime, the context is denoted as P for the processor. In general, this is all, briefly.
The figure shows 2 kernel threads (M), each owning a context (P), each of which performs a Go-routine. For the purposes of the Go routine, the thread must hold the context. The number of contexts is set at the start from the value of the GOMAXPROCS environment variable, or by the GOMAXPROCS () runtime function. Normally this value does not change during the execution of your program.
The fact of a fixed number of contexts means that only GOMAXPROCS of Go code areas are executed simultaneously at any time. We can use this to configure the Go process call for an individual computer, for example, on a 4-core PC, execute the Go code in 4 threads.
Tinted gray in the figure Go-routines are not performed, but are ready for planning. They are placed in lists called run queues. Go-routines are added to the end of the execution queue each time the next go-routine is executed by the go operator. Each time the context has to perform the next Go-routine from the planning point, it pushes the Go-routine out of its execution queue, sets its stack and instruction pointer, and the Go-routine begins.
To prevent disagreement between mutexes, each context has its own local execution queue. The previous version of the Go scheduler had only a global execution queue, with protection by its mutex. Threads were often blocked waiting for the mutex to be released. It was very unfortunate when you use a 32-core machine, wanting to get the maximum performance out as much as possible.
The scheduler keeps scheduling in such a stable state as long as all contexts have running Go routines. However, there are several scenarios that can change this behavior.
Who will you call (system)?
You might be wondering, why do we need contexts at all? Can't we just attach execution queues to threads and get rid of contexts? Unreal. The point is that we have contexts so that we can pass them to other threads if the current thread has to block for some reason.
An example of when we need to block is when we make a system call. Since the thread cannot simultaneously execute code and be blocked on a system call, we need to pass the context, because it can delay scheduling.
Here we see a thread abandoning its context, so another thread can start it. The scheduler will make sure that there are enough threads to execute all the contexts. M1 in the figure above can be specially created only for processing a system call, or it can come from some thread pool. The system call that executes the thread will be frozen on the Go-routine that makes the system call, since it is technically still running, although it is blocked in the operating system.
When the system call returns, the thread should attempt to get a context in order to start the returning Go routine. The normal mode of action is to borrow the context from one of the other threads. If the thread cannot borrow, it will put the Go-routine into the global execution queue, returning to the pool of free streams, or going to sleep.
The global execution queue is the execution queue from where contexts are retrieved (jobs) when they end in their local queues. Contexts also periodically check the global queue for Go-Wireout. Otherwise, the go-routines in the global queue may never start and die of starvation.
Such system call processing explains why Go programs run in multiple threads, even when GOMAXPROCS is set to 1. The runtime uses Go routines for system calls, leaving threads following them.
Borrowing work
Another way that the stable state of the system can change is when the context falls out of the Go-Route schedule. This can occur if the amounts of work on the execution queues of the contexts are unbalanced. This can happen when the context, in the end, exhausts its turn of execution, despite the fact that there is still work to be done in the system. To continue executing Go code, the context may take Go rouins from the global execution queue, but if there are none and there, it must receive them from another location.
This is somewhere in other contexts. When the context is exhausted, it will attempt to borrow about half of the execution queue from another context. This ensures that there is always work to be performed on each of the contexts, which in turn confirms that all threads are working at the limit of their capabilities.
What's next?
There are many more details in the scheduler, like cgo threads, LockOSThread () function, and integration with network pulling. They go beyond these notes, but still deserve to be studied. I may write about them later. Of course, many interesting constructs can be found in the Go runtime libraries.
Source: https://habr.com/ru/post/269271/
All Articles