From zero to 700 gigabits per second - as one of the largest video hosting sites in Russia ships the video
We wrote the code for a long time, read you, and finally decided to step out of the shadows to get involved in a corporate blog and talk about how one of the largest video platforms of the runet delivers video to the end user.
We will reveal the principles of our infrastructure and architecture, tell you about the solutions used, share the experience of solving routine and completely non-standard problems and, of course, listen to all the complaints and suggestions.
Before I talk about what constitutes the Rutube today, I would like to spend a little excursion into history.
The video platform and the site (“Green” RuTube, in corporate slang) were designed and developed in the city of Orel, by Inventos .
')
In 2008, the project was acquired by Gazprom-Media Holding, and the recruitment of a new team began in Moscow, but until the end of 2009, support was provided by Oryol developers.
It is interesting that a significant part of the team now is from this, the first, Moscow “draft”.
This is how the architecture of the project looked in the fall of 2008, at the time of the acquisition of Gazprom-Media Holding.
The development language is Perl. The data was stored in MySQL, for which your ORM was written. Memcached was used as a cache. Several 4 unit SuperMicro servers were used to store video files, with 16 disks of 1 TB each, combined into a RAID-5 array. Each server had its own backup, which contained an exact copy of the data. Replication took place on DRBD (block copying).
Creating a full replica of a 16 terabyte array in such conditions took about a month. At the same time there was a risk to remain without a lively replica.
All this housekeeping was controlled by a tool called FileCluster - it was a MySQL database with an interface in Perl. The database kept all the information about the video files, namely, on what particular machines they are. The idea of FileCluster was to provide the user with an abstract layer that allows you to perform operations to fill, delete, and read files from an entity that logically unites all physical storages.

All communication of auxiliary machines (for example, encoders) with the storage took place via FileCluster.
Files between servers were transferred using a special utility written on the basis of libssh, but, as you might guess, ssh.
HTTP (progressive download) protocol was used as a protocol for video distribution. It should be noted that in those days (2008) only RTMP was the only alternative to play in flash.
The video output system was built on the principle of storage-cache (origin-edge in Adobe terminology). Clients receive video from cache servers. If the requested file is not in the cache, a request is sent to the repository, and the response is cached. This is a very flexible scheme that allows you to simply implement a geographically distributed content delivery network (CDN).
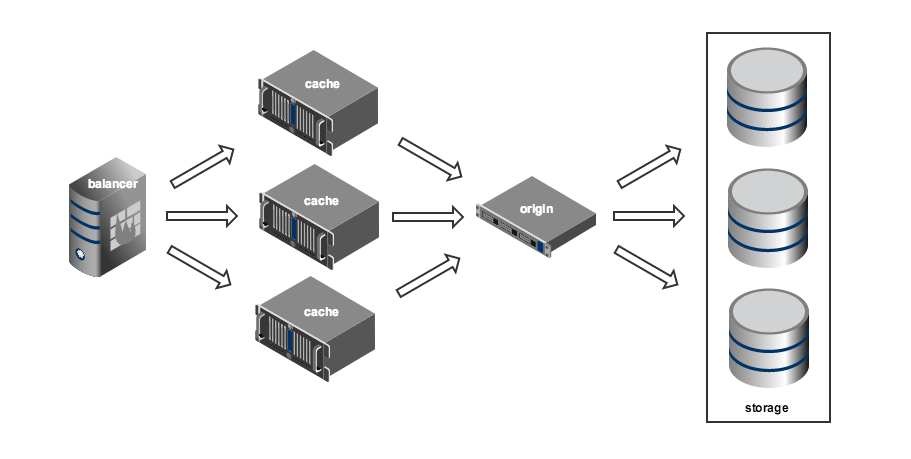
The basis of the video return was another original development - a special demon based on libevent, called VideoD. The daemon is written in C ++ using STL.
Runet old-timers will surely remember that RuTube video was packaged in its own iflv format at that time. The format was a regular flv-file, with metadata about the number of key frames and their location. Such a file could not be reproduced by standard means, but VideoD could request any fragment of the video. On the project front there were several servers running VideoD. When requesting a video, VideoD accessed the repository, retrieved the required file or its fragment, and gave it to the client.
To implement byte range queries and caching, on all the machines that make up the storage, VideoD instances were also launched in a special mode. Fragments of files received from the storage in this way were stored on the caching servers and, upon repeated requests, were sent from there.
The flexibility of the storage-cache scheme is achieved due to the complexity of the load balancing system on the caching servers. For the balancer to work effectively, it is necessary to constantly monitor the state of the entire system, collecting and analyzing a large number of metrics: availability of cache servers, traffic on their network interfaces, loading of the disk subsystem, currently viewed videos, frequency of requests for specific videos (popularity), distribution of requests over regions and much more. The 2009 sample balancing system was implemented on the basis of Perlbal as a special plug-in and was able to track only one metric - the popularity of commercials.
Based on this metric, the balancing system selected a group of servers on which the content should be cached. To get a link to the file, the balancer accessed the cache (memcached). If there was no data in the cache, the balancer accessed the backend (FileCluster), which processed the request and put the data into the cache, and then the balancer re-accessed the cache.
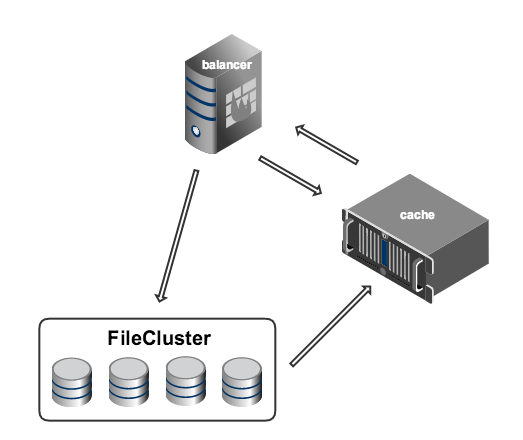
If everything went well, then the data successfully entered the cache and, when re-accessed, the balancer received them. If there were any problems (usually not at the right time), and when re-accessing the cache there was still no data, the user saw the sad message that the video is currently unavailable. It is worth noting that already at that time the balancing system was a separate entity, which later allowed us to rebuild the video platform without making major changes to the backend.
The entire load was distributed between the two sites. In the main data center there were 48 servers, and another 16 in Rostelecom. All servers were behind IPVS, with the help of which fault tolerance was provided - the “fallen” machines simply did not fall into the issue.
Since 2009, global changes have occurred in the architecture of the project, most of which occurred in 2012-2014. The site and the video platform itself were completely rewritten.
Python and the Django framework are used as the main development tool. All independent tasks (video conversion, statistics, duplicate search, website) are separated between independent services that interact with each other through Celery-based RPC. A beanstalk was chosen for queuing messages, but later it was decided to abandon it in favor of RabbitMQ, which now provides a larger share of transport between services. Interaction with RabbitMQ is done using Celery. Caching is organized through Cacheops + Redis. For searching using Sphinx.
The main database is still MySQL, but some projects are looking hard at the left in search of a new life partner.
All platform components are duplicated in two data centers. Master-master replication is organized between the main databases, individual master-slave replicas are also raised for all services that create a significant load on reading, for example, for statistics.
FileCluster has been replaced with a new tool, which we called FileHeap. FileHeap is an almost classic implementation of SDS (software defined storage). Everything is written in Python, MySQL is used as a database. To store files, inexpensive 2-unit servers with 16 GB of RAM, one 6-core processor and 12 disks of 4 TB each are used. Also in this scheme is Tsar-Disk - NetApp, inherited from FileCluster. We plan to get rid of NetApp in the very near future, as soon as we increase the volume of low-cost storage to the required size. All servers used to store files are separated into two data centers. In case of nuclear war, FileHeap always creates three copies of each object, two of which are physically located in different data centers.
FileHeap treats each hard drive as a separate storage and monitors the uniform filling of all available drives. This scheme allows us to easily expand the storage in accordance with our needs, as well as easily replace the failed hard drives.
For downloading files and converting there is a separate group of machines, also equally divided between the two data centers. The service responsible for the conversion was developed on the basis of the Celery library. For conversion, ffmpeg is used. Transcoding of each quality is started by a separate process and, as a rule, on different servers, so if the converter is “dead”, there is a non-zero probability that the source is stored on another converter, and as a result the task will complete without errors. File transfer between converters occurs via WebDAV, nginx is used as a server.
To manage a group of converters, a special service was developed, which was called Duck (Download, Upload and Convert King). It is used to monitor the operation of converters, manage queues of tasks, delete and re-submit for processing, as well as enter new machines for conversion into the system.
Video output balancing is implemented in Python using the Py3 library asyncio. On the servers of the balancing group there are several daemons that monitor the performance of all the sending servers and monitor the status of the channel. In addition, the balancer stores information about the views and popularity of commercials. All these parameters are used to decide which server is faster to deliver user-requested content. The exchange of data between servers of balancing is organized through Redis.
When requesting a video, if there is no data on the location of the video in the cache, the balancer accesses the FileHeap and generates a link to the cache server by which you can get the necessary file from the physical storage.
Rutube has several installation points for caching servers for video output. In Moscow, they are located in three data centers. One third of the servers are for hot content (popular videos, for example, Interns). On the “hot” servers, network interfaces with a capacity of up to 80 gigabits are raised, on the “cold” ones - up to 40. In addition, there are several points served by other telecom operators - one point in Krasnoyarsk and two in Yerevan. Now we are actively working towards expanding our delivery network.
After the infrastructure integration with the live platform (developed by GPM Technology) and the transition of the cinema NOW.ru to the platform player, at the beginning of October 2015, the Rutube platform serves up to 350 thousand simultaneous video views on demand (VOD) and up to 65 thousand simultaneous live- flows, with a total traffic of 700 gigabits.
But this is far from the limit - after all, admins buy servers, the Holding opens new channels, and the development writes code.
We will reveal the principles of our infrastructure and architecture, tell you about the solutions used, share the experience of solving routine and completely non-standard problems and, of course, listen to all the complaints and suggestions.
Before I talk about what constitutes the Rutube today, I would like to spend a little excursion into history.
Early years: the creation and transfer to Moscow
The video platform and the site (“Green” RuTube, in corporate slang) were designed and developed in the city of Orel, by Inventos .
')
In 2008, the project was acquired by Gazprom-Media Holding, and the recruitment of a new team began in Moscow, but until the end of 2009, support was provided by Oryol developers.
Marginal notes: in spite of the fact that the Moscow team was assembled from specialists, who generally had experience working with high-loaded systems, they had little experience with video - therefore, the ideas and developments with which the project was purchased had to be comprehended and rethought. from scratch.
We admit that some of the solutions used in the processed form to this day were not immediately appreciated.
It is interesting that a significant part of the team now is from this, the first, Moscow “draft”.
This is how the architecture of the project looked in the fall of 2008, at the time of the acquisition of Gazprom-Media Holding.
The development language is Perl. The data was stored in MySQL, for which your ORM was written. Memcached was used as a cache. Several 4 unit SuperMicro servers were used to store video files, with 16 disks of 1 TB each, combined into a RAID-5 array. Each server had its own backup, which contained an exact copy of the data. Replication took place on DRBD (block copying).
Notes in the margin: there are many examples of successful operation of such solutions - the scheme is very simple, does not require large investments and knowledge of some cunning tools, however, it has several disadvantages. The failure of any disk leads to degradation of the performance of the array, and in case of failure of the entire master server, the burden of servicing client traffic falls on the replica. After returning to the master server, the load increases due to replication of data in the opposite direction, which also does not add joy.
Creating a full replica of a 16 terabyte array in such conditions took about a month. At the same time there was a risk to remain without a lively replica.
All this housekeeping was controlled by a tool called FileCluster - it was a MySQL database with an interface in Perl. The database kept all the information about the video files, namely, on what particular machines they are. The idea of FileCluster was to provide the user with an abstract layer that allows you to perform operations to fill, delete, and read files from an entity that logically unites all physical storages.
All communication of auxiliary machines (for example, encoders) with the storage took place via FileCluster.
Files between servers were transferred using a special utility written on the basis of libssh, but, as you might guess, ssh.
Marginal notes: in general, FileCluster solved a lot of problems - it allowed to get away from accessing specific physical storages and eliminated the need to produce a large number of mount points on all machines. However, it had a number of serious flaws - for example, due to the lack of the possibility of redistributing content across the repositories, after the commissioning of new ones, they had an increased load.
HTTP (progressive download) protocol was used as a protocol for video distribution. It should be noted that in those days (2008) only RTMP was the only alternative to play in flash.
The video output system was built on the principle of storage-cache (origin-edge in Adobe terminology). Clients receive video from cache servers. If the requested file is not in the cache, a request is sent to the repository, and the response is cached. This is a very flexible scheme that allows you to simply implement a geographically distributed content delivery network (CDN).
The basis of the video return was another original development - a special demon based on libevent, called VideoD. The daemon is written in C ++ using STL.
Runet old-timers will surely remember that RuTube video was packaged in its own iflv format at that time. The format was a regular flv-file, with metadata about the number of key frames and their location. Such a file could not be reproduced by standard means, but VideoD could request any fragment of the video. On the project front there were several servers running VideoD. When requesting a video, VideoD accessed the repository, retrieved the required file or its fragment, and gave it to the client.
To implement byte range queries and caching, on all the machines that make up the storage, VideoD instances were also launched in a special mode. Fragments of files received from the storage in this way were stored on the caching servers and, upon repeated requests, were sent from there.
Marginal notes: although one VideoD instance could serve several clients, the daemon was single-threaded, so any read operation from the hard disk blocked all others. For this reason, network interfaces with a capacity of 1 gigabit were installed on all the sending servers - more was simply not required at that time.
The flexibility of the storage-cache scheme is achieved due to the complexity of the load balancing system on the caching servers. For the balancer to work effectively, it is necessary to constantly monitor the state of the entire system, collecting and analyzing a large number of metrics: availability of cache servers, traffic on their network interfaces, loading of the disk subsystem, currently viewed videos, frequency of requests for specific videos (popularity), distribution of requests over regions and much more. The 2009 sample balancing system was implemented on the basis of Perlbal as a special plug-in and was able to track only one metric - the popularity of commercials.
Based on this metric, the balancing system selected a group of servers on which the content should be cached. To get a link to the file, the balancer accessed the cache (memcached). If there was no data in the cache, the balancer accessed the backend (FileCluster), which processed the request and put the data into the cache, and then the balancer re-accessed the cache.
If everything went well, then the data successfully entered the cache and, when re-accessed, the balancer received them. If there were any problems (usually not at the right time), and when re-accessing the cache there was still no data, the user saw the sad message that the video is currently unavailable. It is worth noting that already at that time the balancing system was a separate entity, which later allowed us to rebuild the video platform without making major changes to the backend.
The entire load was distributed between the two sites. In the main data center there were 48 servers, and another 16 in Rostelecom. All servers were behind IPVS, with the help of which fault tolerance was provided - the “fallen” machines simply did not fall into the issue.
Marginal notes: it may seem that not everything has been done optimally. But one should take into account the fact that Inventos were a kind of pioneer, and many of the decisions that seem strange now, back in 2008 looked justified and sometimes the only true ones. In any case, this architecture allowed serving about 20 thousand simultaneous users, with a total load of 25 gigabits.
Rutube today
Since 2009, global changes have occurred in the architecture of the project, most of which occurred in 2012-2014. The site and the video platform itself were completely rewritten.
Python and the Django framework are used as the main development tool. All independent tasks (video conversion, statistics, duplicate search, website) are separated between independent services that interact with each other through Celery-based RPC. A beanstalk was chosen for queuing messages, but later it was decided to abandon it in favor of RabbitMQ, which now provides a larger share of transport between services. Interaction with RabbitMQ is done using Celery. Caching is organized through Cacheops + Redis. For searching using Sphinx.
The main database is still MySQL, but some projects are looking hard at the left in search of a new life partner.
All platform components are duplicated in two data centers. Master-master replication is organized between the main databases, individual master-slave replicas are also raised for all services that create a significant load on reading, for example, for statistics.
Storage
FileCluster has been replaced with a new tool, which we called FileHeap. FileHeap is an almost classic implementation of SDS (software defined storage). Everything is written in Python, MySQL is used as a database. To store files, inexpensive 2-unit servers with 16 GB of RAM, one 6-core processor and 12 disks of 4 TB each are used. Also in this scheme is Tsar-Disk - NetApp, inherited from FileCluster. We plan to get rid of NetApp in the very near future, as soon as we increase the volume of low-cost storage to the required size. All servers used to store files are separated into two data centers. In case of nuclear war, FileHeap always creates three copies of each object, two of which are physically located in different data centers.
FileHeap treats each hard drive as a separate storage and monitors the uniform filling of all available drives. This scheme allows us to easily expand the storage in accordance with our needs, as well as easily replace the failed hard drives.
File upload and conversion
For downloading files and converting there is a separate group of machines, also equally divided between the two data centers. The service responsible for the conversion was developed on the basis of the Celery library. For conversion, ffmpeg is used. Transcoding of each quality is started by a separate process and, as a rule, on different servers, so if the converter is “dead”, there is a non-zero probability that the source is stored on another converter, and as a result the task will complete without errors. File transfer between converters occurs via WebDAV, nginx is used as a server.
To manage a group of converters, a special service was developed, which was called Duck (Download, Upload and Convert King). It is used to monitor the operation of converters, manage queues of tasks, delete and re-submit for processing, as well as enter new machines for conversion into the system.
Balancing and CDN
Video output balancing is implemented in Python using the Py3 library asyncio. On the servers of the balancing group there are several daemons that monitor the performance of all the sending servers and monitor the status of the channel. In addition, the balancer stores information about the views and popularity of commercials. All these parameters are used to decide which server is faster to deliver user-requested content. The exchange of data between servers of balancing is organized through Redis.
When requesting a video, if there is no data on the location of the video in the cache, the balancer accesses the FileHeap and generates a link to the cache server by which you can get the necessary file from the physical storage.
Rutube has several installation points for caching servers for video output. In Moscow, they are located in three data centers. One third of the servers are for hot content (popular videos, for example, Interns). On the “hot” servers, network interfaces with a capacity of up to 80 gigabits are raised, on the “cold” ones - up to 40. In addition, there are several points served by other telecom operators - one point in Krasnoyarsk and two in Yerevan. Now we are actively working towards expanding our delivery network.
After the infrastructure integration with the live platform (developed by GPM Technology) and the transition of the cinema NOW.ru to the platform player, at the beginning of October 2015, the Rutube platform serves up to 350 thousand simultaneous video views on demand (VOD) and up to 65 thousand simultaneous live- flows, with a total traffic of 700 gigabits.
But this is far from the limit - after all, admins buy servers, the Holding opens new channels, and the development writes code.
Source: https://habr.com/ru/post/269227/
All Articles