Redis and big data problem

Hi, Habr! We continue to share the Retail Rocket technology kitchen. In today's article we will examine the question of choosing a database for storing large and frequently updated data.
At the very beginning of the development of the platform, we faced the following tasks:
- To store the stores' product bases (i.e., information on each product of all the stores connected to our platform with a full update of 25 million items every 3 hours).
- Store recommendations for each product (about 100 million products contain from 20 or more recommended products for each key).
- Ensuring consistently fast delivery of such data upon request.
Schematically can be represented as:
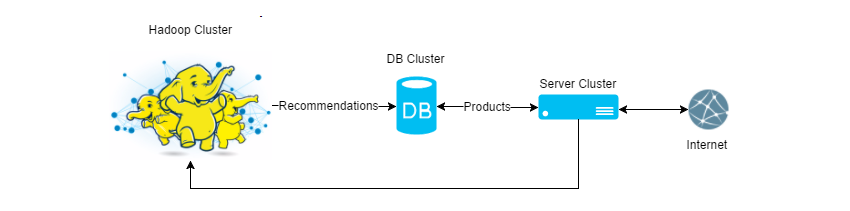
Among the popular relational and documentary databases, we chose MongoDb to start and immediately faced the following difficulties:
- Optimize the update rate of 100K — 1M products at a time.
- MongoDb, while writing data, rested on the disk, and the ghost of a problem with a vacuum (when the record was removed from the database, and the place is still occupied) made us think about In-memory DataBase.
')
Faced with the first difficulties, we decided to continue searching for a solution among In-Memory Db and rather quickly our choice fell on Redis, which was supposed to provide us with the following advantages:
- Persistence (saves its state to disk).
- A wide range of data types (strings, arrays, etc.) and commands to work with them.
- Modern In-Memory Db, which turned out to be important as opposed to Memcached.
But the real world has changed our attitude towards these advantages.
Miracles of Persistence

Almost immediately after the launch of Redis ʻa in "production", we began to notice that at times the rate of issuing recommendations for goods sags significantly and the reason was not in the code. After analyzing several indicators, we noticed that at the moment when disk activity appears on Redis servers, the response time from our service grows - obviously, the point is Redis, or rather, how it behaves when it works with the disk. For a while, we reduced the frequency of saving data to disk and thus “forgotten” about this problem.
The next discovery for us was that Redis is not available all the time while it picks up data from the disk (this is logical, of course), i.e. if suddenly the Redis-process fell at you, then until the newly raised service lifts all its state from the disk, the service will not respond, even if the lack of data for you is a much smaller problem than the inaccessible database.
Because of the two above described features of Redis, we faced the question: “But can we not disable its persistence?”. Moreover, all the data that we store in it, we can perezalit from scratch in a time comparable to how he himself lifts them from the disk and, in this case, Redis will respond. Resolved! We made it a rule not to store data in Redis, without which the operation of the system is not possible and which we cannot quickly recover, and then turned off the persistence. 1.5 years have passed since then, and we believe that we made the right decision.
Choosing a driver for Redis
For us from the very beginning it was an unpleasant fact that Redis has no driver for .Net. Having conducted tests among unofficial drivers for performance, ease of use, it turned out that there is only one suitable driver. And even worse, after a while it became paid and all new features began to be released only in the paid version.
It should be noted that much time has passed since that moment, and, most likely, something has changed in this situation. But we didn’t see a quick analysis among the free redis-cluster support drivers, so the situation is not perfect at all.
Horizontal scaling
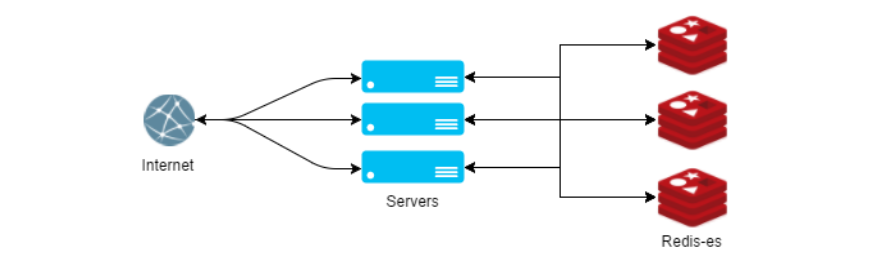
After only half a year of using Redis, we rented a server for it with the maximum allowable amount of RAM in the DC, and it became clear that sharding was not far off. Redis-cluster, at that time, was just about to exit, and the drivers that became paid, suggested that we would have to solve this problem ourselves.
It still seems to us that there is only one option to make shading in Redis ʻe right. If to describe this method is simple, then we have proxied all the methods that receive the key of the record in the parameter. Within each such method, the key is hashed, and a simple remainder of the division selects the server to which the key is written / read. It would seem that a rather primitive solution, not without its obvious shortcomings, allows us to still not successfully think about problems with horizontal scaling.
You can see the code for our implementation of the wrapper for RedisClient with sharding support in our repository on GitHub .
After the introduction of sharding, the main task was to monitor the availability of RAM on Redis servers. There should be enough free memory on the servers so that if 1-2 Redis machines fall, we would have enough memory to transfer all the data to the servers remaining in battle and continue working until the outgoing servers are back in service.
First performance problems
Since Redis can store only text data, it is necessary to serialize objects before saving, and before issuing it to deserialize into some text format. Our default driver serializes the data to JSON format and we notice that the deserialization process eats away the significant time to issue recommendations. After a cursory analysis of serializers, we decided to replace the standard serializer driver by JIL, which completely eliminated the issue of serializer performance.
Finally
Having read all the points above, it may appear that Redis is a problematic database with a bunch of hidden risks, but in fact it was with Redis that everything went predictably. We always understood where to wait for problems, so we solved them in advance. We have been using Redis in battle for 2 years now and, although we sometimes have thoughts of “Wouldn’t you replace it with“ a regular database? ”, We still believe that we made the right choice at the very beginning of our path.
Our checklist "how to cook radishes":
- Store only data that can be quickly recovered in case of loss.
- Do not use radish persistence.
- Own sharding.
- Use an efficient serializer.
Source: https://habr.com/ru/post/269151/
All Articles