Big data, Beeline and Coco
A couple of days ago, having accidentally logged on Habr without an adblock, I saw a banner: “Beeline, be a man - solve the shaitan-task”. Challenge sounded interesting, to determine the age by a set of parameters such as region, tariff plan, etc.

It should be noted that I have no experience in solving such a plan of tasks. The whole idea that I had was made up of review articles, readily diagonally read, and laboratory work at the institute. As part of the labs on the delphi, a neural network was filed and trained to determine the letters of the alphabet from b / w pictures of size 64x64.

')
I have long been impatient to immerse myself in bigdatu, and then the case turned up. I began to look for an entry point to this technology. Quickly impudent stateek, tutorials and all sorts of examples that tried to chew basic things and demonstrate some tools to work with the whole thing. I had to dive into the python.

Not very upset, all the python is not R. And with serious intentions and valiant enthusiasm deflated the trial JetBrains PyCharm. Picked up a few examples, approximately, I realized that I decided to, finally take up the Beeline.
Anticipating how I will impose my social picture of the world on the data provided, trying to understand to whom and for how many years I began to download the task. After downloading the data, I felt very deceived. Instead of the promised tariffs and other nishtyakov, I saw a set of disconnected columns 1-61 and values in the table in the form of hashes and some crazy numbers. Hi harsh cyberpunk.

Having developed a solution for such a formulation of the problem, it becomes completely unclear, but what will it actually do? To recommend lace panties to the Japanese Tian or to pass massively court sentences in China. Rejecting reflection and focusing on the fact that this is a harmless competition, I began to pick the data. The first thing I did randomly scattered the 3 most popular groups and uploaded the result, which was 27.03%, ok, let's start with this.
It quickly turned out that the task goes far beyond any tutor and is not so easy to solve. At the same time, the pycharm feilil and did not give the promised autocomplexes because of this, at every step it was necessary to climb into the docks of the Pitonvian libs, designed in the style of the beginning of 00, which also did not bring joy. The charts that pylab drew looked even worse.

But the last straw was the realization of how much time I spend on coding, some kind of nonsense, although I just need one schedule! And at this moment of pain and discomfort from all these tools, refusing to believe that everything is so bad, I, for some reason, remembered the machine learning tab of azure, although I never opened it.

I open the ML and I immediately offer a splint - I agree. It turns out that they are not vidos or tooltips with black masks, but naturally create an example in the environment, telling and showing what and how. Everything is extremely simple, there is a bunch of modules divided into types: sources, data transformers, algorithms, training, evaluation, etc. It was necessary, of course, to read what modules are available, what they are for, and what parameters they are responsible for, at the same time, in theory, I figured out. But how is it all humanly done. After studying the docks, it took 5 minutes to concoct everything and get the first real result.

Having chosen the most accurate algorithm, I decided to use the parameter selection module. After going through all the options, the captain's module reported that the more the better. Without hesitation, I increased the basic parameters 100 times and left the whole thing to study. The most inconvenient in this process is the lack of any progress in the bar or at least some estimeytov and in fact it remains only to guess when the process will end. Several times there were thoughts to stop, but I finished it and it took 13 hours.

As a result, I received:
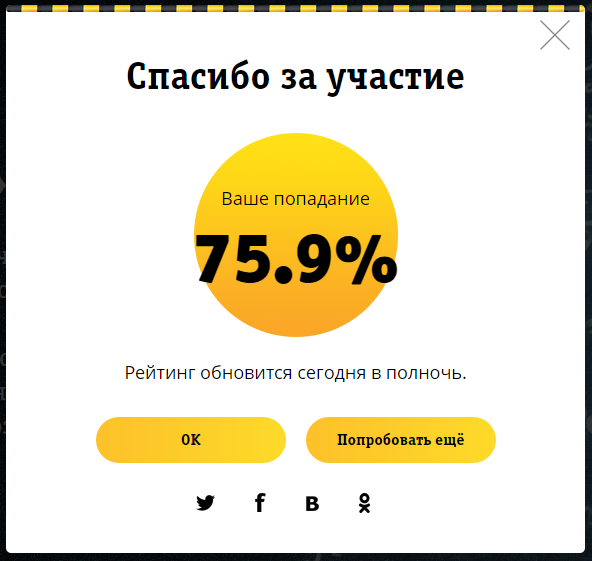
This is only 0.9% less than the top 25, given that the spread in the top25 is 0.6% and it increases to the bottom, then in the top40, I think I hit. I think this is an excellent result for a person who did not know anything in this area just yesterday.
Speaking of the material side, all this indulgence in the ML studio cost me for 24.38 Hours in RUB1,219.04.
It should be noted that I have no experience in solving such a plan of tasks. The whole idea that I had was made up of review articles, readily diagonally read, and laboratory work at the institute. As part of the labs on the delphi, a neural network was filed and trained to determine the letters of the alphabet from b / w pictures of size 64x64.
')
I have long been impatient to immerse myself in bigdatu, and then the case turned up. I began to look for an entry point to this technology. Quickly impudent stateek, tutorials and all sorts of examples that tried to chew basic things and demonstrate some tools to work with the whole thing. I had to dive into the python.
Not very upset, all the python is not R. And with serious intentions and valiant enthusiasm deflated the trial JetBrains PyCharm. Picked up a few examples, approximately, I realized that I decided to, finally take up the Beeline.
Anticipating how I will impose my social picture of the world on the data provided, trying to understand to whom and for how many years I began to download the task. After downloading the data, I felt very deceived. Instead of the promised tariffs and other nishtyakov, I saw a set of disconnected columns 1-61 and values in the table in the form of hashes and some crazy numbers. Hi harsh cyberpunk.
Having developed a solution for such a formulation of the problem, it becomes completely unclear, but what will it actually do? To recommend lace panties to the Japanese Tian or to pass massively court sentences in China. Rejecting reflection and focusing on the fact that this is a harmless competition, I began to pick the data. The first thing I did randomly scattered the 3 most popular groups and uploaded the result, which was 27.03%, ok, let's start with this.
It quickly turned out that the task goes far beyond any tutor and is not so easy to solve. At the same time, the pycharm feilil and did not give the promised autocomplexes because of this, at every step it was necessary to climb into the docks of the Pitonvian libs, designed in the style of the beginning of 00, which also did not bring joy. The charts that pylab drew looked even worse.
But the last straw was the realization of how much time I spend on coding, some kind of nonsense, although I just need one schedule! And at this moment of pain and discomfort from all these tools, refusing to believe that everything is so bad, I, for some reason, remembered the machine learning tab of azure, although I never opened it.
I open the ML and I immediately offer a splint - I agree. It turns out that they are not vidos or tooltips with black masks, but naturally create an example in the environment, telling and showing what and how. Everything is extremely simple, there is a bunch of modules divided into types: sources, data transformers, algorithms, training, evaluation, etc. It was necessary, of course, to read what modules are available, what they are for, and what parameters they are responsible for, at the same time, in theory, I figured out. But how is it all humanly done. After studying the docks, it took 5 minutes to concoct everything and get the first real result.
Having chosen the most accurate algorithm, I decided to use the parameter selection module. After going through all the options, the captain's module reported that the more the better. Without hesitation, I increased the basic parameters 100 times and left the whole thing to study. The most inconvenient in this process is the lack of any progress in the bar or at least some estimeytov and in fact it remains only to guess when the process will end. Several times there were thoughts to stop, but I finished it and it took 13 hours.
As a result, I received:
This is only 0.9% less than the top 25, given that the spread in the top25 is 0.6% and it increases to the bottom, then in the top40, I think I hit. I think this is an excellent result for a person who did not know anything in this area just yesterday.
Speaking of the material side, all this indulgence in the ML studio cost me for 24.38 Hours in RUB1,219.04.
Source: https://habr.com/ru/post/269065/
All Articles