Altera + OpenCL: we program under FPGA without knowledge of VHDL / Verilog

Hello!
The Altera SDK for OpenCL is a set of libraries and applications that allows you to compile code written in OpenCL into the FPGA firmware from Altera . This allows the programmer to use FPGA as a high-performance computing accelerator without knowledge of HDL languages, and write on what he is used to when it does under the GPU.
')
I played with this tool with a simple example and I want to tell you about it.
Plan:
- A few words about FPGA
- What to run?
- Development process (workflow)
- OpenCL BSP
- Compile Kernel
- ... and run
- Conclusion
Welcome under the cut! Carefully , there will be pictures!
A few words about FPGA (FPGA)
FPGA (Field-Programmable Gate Array) is a user-programmable gate array, a type of FPGA .
Such chips are based on small blocks of logic elements. On such primitives, you can build the logic of any chip - from an 8-bit microcontroller to a miner of bitcoins.
More on FPGA
I recommend to watch a very high-quality video:
There is also a good FPGAs for Dummies book, which explains in a very simple language what FPGA is and how these chips are used.
There is also a good FPGAs for Dummies book, which explains in a very simple language what FPGA is and how these chips are used.
"Classic" development for FPGA looks like this:
Sometimes FPGA is perceived as a more expensive kind of microcontroller: there and there you can blink an LED, unify UART, SPI, I2C. In the past, this was partly true due to the fact that the FPGAs were small (in terms of resources and frequencies), and it was impossible to speak about any serious data processing and competition with processors. Now FPGA chips are getting fatter, and their performance is compared to the GPU.
FPGA makes it possible to control processing at the lowest level: create caches of the right size in the right place, organize pipelining, describe explicit parallelism. You can connect various peripherals (for example, video cameras or Ethernet ports) and perform calculations without a general-purpose processor.
All the charms of FPGA are leveled by the fact that if there is a low level control, then this low level must be programmed! A low level of abstraction always leads to the complexity of development and debugging, an increase in time .
FPGA manufacturers have thought very reasonably about shortening the time-to-market: letting programmers write to FPGA very easily and quickly. One of the standard options for describing a parallel computing program is OpenCL . Altera decided to support OpenCL : it was developed by Altera SDK for OpenCL .
I deliberately omit the OpenCL description: there is a lot of literature in the Russian-speaking Internet on this topic, for example, Introduction to OpenCL .
What to run?

You cannot start OpenCL with every FPGA board: Altera has created a special affiliate program, within which the devkits receive the above-mentioned tag, if the board is ready to run OpenCL, it runs regular regression tests, etc.
PCIe
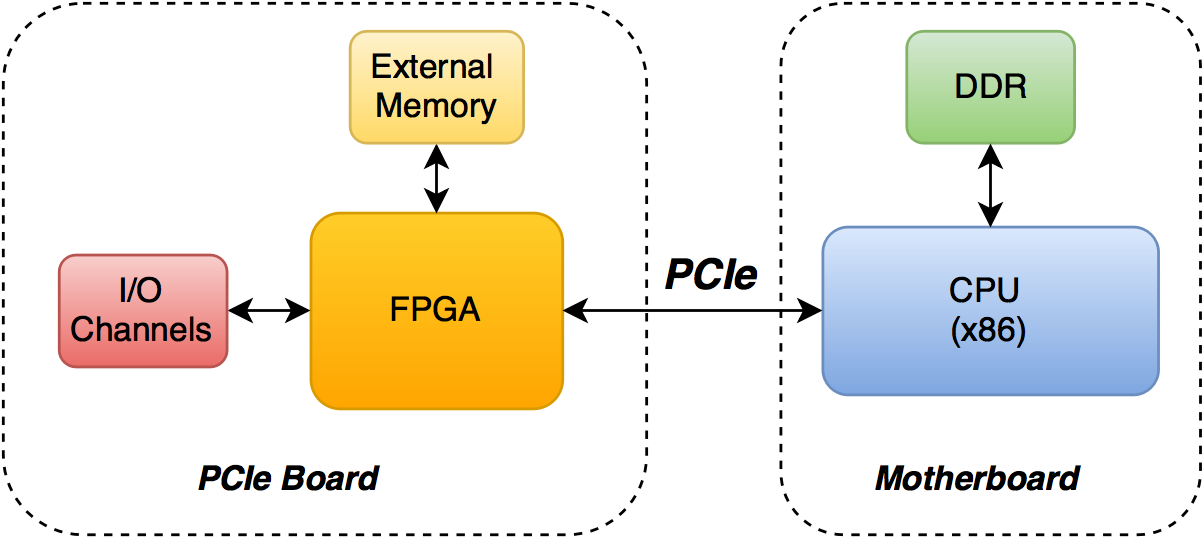
A chip with FPGA can be placed on a PCIe card , which is plugged into the motherboard in the appropriate slot (at least instead of the GPU). Through DMA and PCIe FPGA can communicate with DDR memory that is connected to the processor (to collect data for calculations). Also on the board can be placed external memory, which is only available for FPGA (the OS on the CPU will not have access to this memory).
External memory may be needed to store intermediate calculations: access to it will be cheaper than access via DMA to host memory. It does not have to be DDR: for some calculations, low-latency SRAM may work better.
Data for processing can be sent to the kernel not only from global memory, but also from I / O channels, for example, from Ethernet ports. In this case, the host only configures the kernels, and the data is processed with minimal delay. (If you see the words Ethernet, FPGA and low-latency next to them, then in most cases high-frequency trading is implied).
SoC
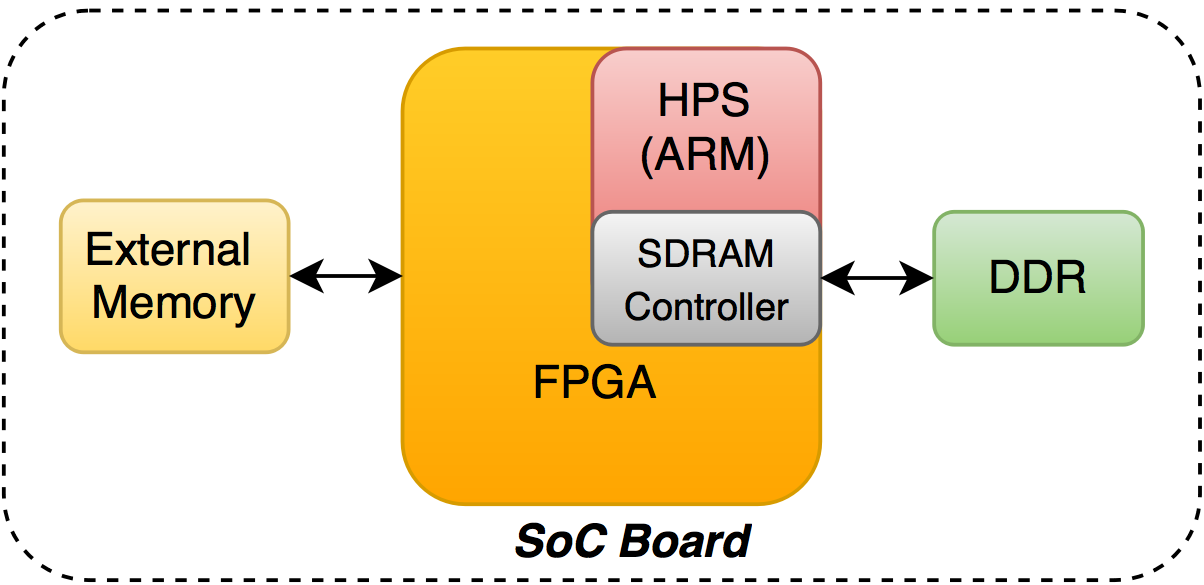
The second option is possible on SoC 'ax, where programmable logic and an ARM processor are located in one crystal.
DDR-memory, shaded green, is a shared resource: on the one hand it uses the CPU (there you can run linux ), and on the other, the FPGA can read / write directly to this memory via an SDRAM controller with minimal overhead. As with a PCIe card, external memory can be connected to the FPGA, but the need for this is less, because always on hand DDR.
Read more about the platforms here .
It is possible to run OpenCL on those boards that do not have the Altera Preferred Board for OpenCL sign. I will not talk about this, as a starting point I propose to look at the official Altera SDK for OpenCL manual : Custom Platform Toolkit User Guide .
Development process (workflow)
What steps need to be performed to start the kernel?
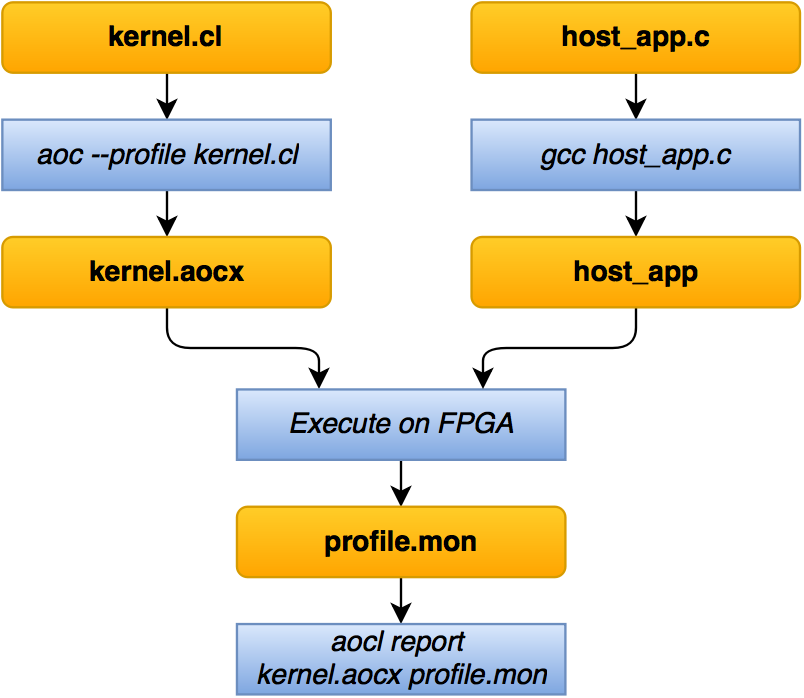
- Kernel code is described in the * .cl file.
- A C / C ++ host application is being prepared that will allocate the required memory and “load” values into the kernel.
- Using the aoc utility, which is included in the Altera OpenCL SDK , the kernel is “compiled” into the aocx file. Using gcc , the host application is built.
- When host_app is launched, the FPGA firmware will be loaded, the prepared data will be loaded into the kernel and its processing will begin.
- Profiling counters collect data that will fit into the profile.mon file.
- Using the aocl utility, you can view this report and make a conclusion: does this implementation satisfy the execution / performance time requirements?
- If satisfied, then you can recompile the kernel without --profile , since profiling counters take away resources in FPGA. On the other hand, if additional cores are not planned to be added, then it is possible and not to recompile.
- If not satisfied, then you need to optimize / write pens / take another chip or accept.
I note that compilation into aocx file can take several hours !
What happens when aoc kernel.cl is called ?
Build aocx
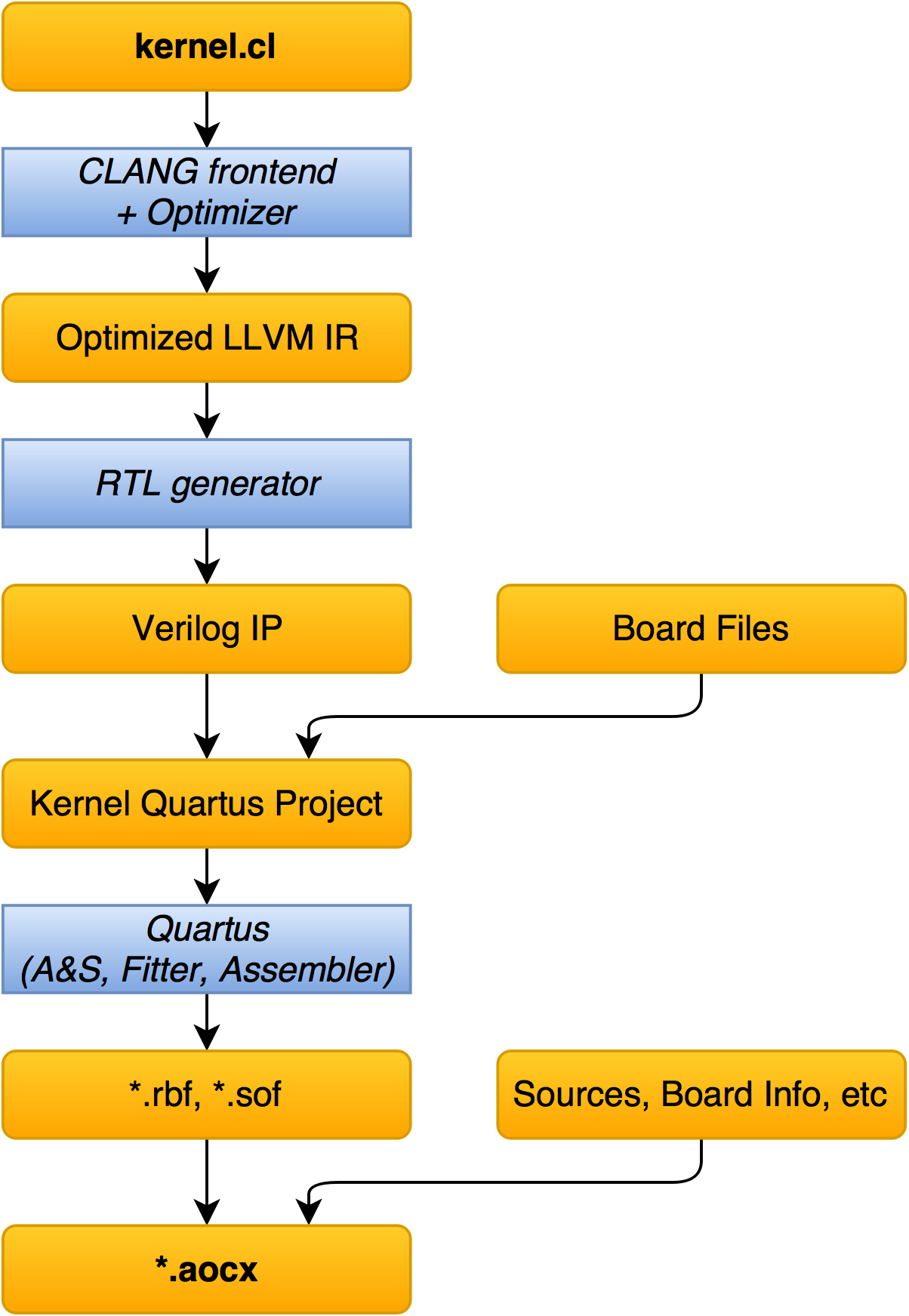
- kernel.cl is fed by clang , which translates the description into IR , and also performs various optimizations.
- RTL is generated by Verilog IP core. Generated files are readable (unencrypted) and can be simulated in a regular simulator (for example, ModelSim). However, there is not all the code is autogenous: there are modules that are clearly written by people.
- The resulting IP “joins” to the default project for the board and it turns out the usual project for Quartus .
- The project builds (Analysis & Synthesis, Fitter, Assembler). It is this item that takes the most time (from ten minutes to several hours): the search for optimal locations of primitives requires a lot of calculations.
- The result of the assembly, information about the board and so on is placed in aocx , which is simply an ELF file.
This aocx file is then used to “boot” the kernel.
DE1-SoC OpenCL BSP
In words and pictures, everything looks very smoothly: Verilog's knowledge is not needed.
What really?
The DE1-SoC board from Terasic again appeared in my hands. It is based on the stone Cyclone V SoC ( 5CSEMA5F31C6 ).

Hidden text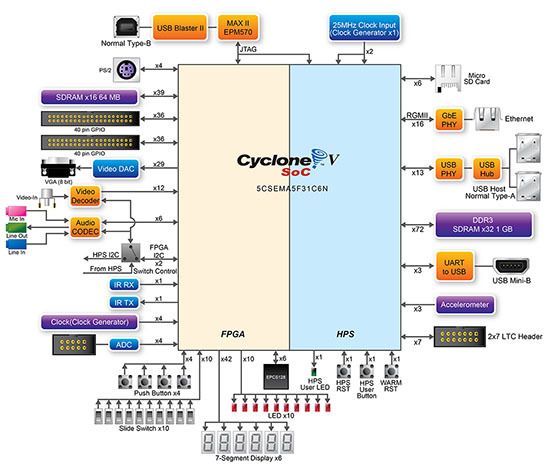
This card has the Altera Preferred Board for OpenCL sign, so the launch of OpenCL should be out of the box: we need an OpenCL BSP for this particular board. You can take it here .
The OpenCL BSP archive includes:
- The image of a flash drive (linux will boot from it).
- The default project, where all the pins are configured, as well as interfaces (fpga2sdram, lwhps2fpga, etc.).
- Simple examples.
The image is recorded on the microSD simply through dd .
Note : it is advisable to use a 10 class flash drive .
There is already linux :
root@socfpga:~# uname -a Linux socfpga 3.13.0-00298-g3c7cbb9-dirty #3 SMP Fri Jul 4 15:42:32 CST 2014 armv7l GNU/Linux root@socfpga:~# cat /etc/issue Poky 8.0 (Yocto Project 1.3 Reference Distro) 1.3 \n \l root@socfpga:~# cat /proc/cpuinfo processor : 0 model name : ARMv7 Processor rev 0 (v7l) Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpd32 CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x3 CPU part : 0xc09 CPU revision : 0 processor : 1 model name : ARMv7 Processor rev 0 (v7l) Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpd32 CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x3 CPU part : 0xc09 CPU revision : 0 Hardware : Altera SOCFPGA Revision : 0000 Serial : 0000000000000000 You can also find compiled examples and OpenCL Run-Time Environment .
The thoughtful README offers:
Run "source ./init_opencl.sh" to setup OpenCL Run-Time Environment, including loading driver, on this board. Do it once right after booting the board. OpenCL Run-Time Environment is pre-installed in opencl_arm32_rte folder. The init_opencl.sh itself looks very trivial:
root@socfpga:~# cat init_opencl.sh export ALTERAOCLSDKROOT=/home/root/opencl_arm32_rte export AOCL_BOARD_PACKAGE_ROOT=$ALTERAOCLSDKROOT/board/c5soc export PATH=$ALTERAOCLSDKROOT/bin:$PATH export LD_LIBRARY_PATH=$ALTERAOCLSDKROOT/host/arm32/lib:$LD_LIBRARY_PATH insmod $AOCL_BOARD_PACKAGE_ROOT/driver/aclsoc_drv.ko Run this script, go to the directory helloworld and run the application of the same name:
root@socfpga:~/helloworld# ./helloworld Querying platform for info: ========================== CL_PLATFORM_NAME = Altera SDK for OpenCL CL_PLATFORM_VENDOR = Altera Corporation CL_PLATFORM_VERSION = OpenCL 1.0 Altera SDK for OpenCL, Version 14.0 Querying device for info: ======================== CL_DEVICE_NAME = de1soc_sharedonly : Cyclone V SoC Development Kit CL_DEVICE_VENDOR = Altera Corporation CL_DEVICE_VENDOR_ID = 4466 CL_DEVICE_VERSION = OpenCL 1.0 Altera SDK for OpenCL, Version 14.0 CL_DRIVER_VERSION = 14.0 CL_DEVICE_ADDRESS_BITS = 64 CL_DEVICE_AVAILABLE = true CL_DEVICE_ENDIAN_LITTLE = true CL_DEVICE_GLOBAL_MEM_CACHE_SIZE = 32768 CL_DEVICE_GLOBAL_MEM_CACHELINE_SIZE = 0 CL_DEVICE_GLOBAL_MEM_SIZE = 536870912 CL_DEVICE_IMAGE_SUPPORT = false CL_DEVICE_LOCAL_MEM_SIZE = 16384 CL_DEVICE_MAX_CLOCK_FREQUENCY = 1000 CL_DEVICE_MAX_COMPUTE_UNITS = 1 CL_DEVICE_MAX_CONSTANT_ARGS = 8 CL_DEVICE_MAX_CONSTANT_BUFFER_SIZE = 134217728 CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS = 3 CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS = 8192 CL_DEVICE_MIN_DATA_TYPE_ALIGN_SIZE = 1024 CL_DEVICE_PREFERRED_VECTOR_WIDTH_CHAR = 4 CL_DEVICE_PREFERRED_VECTOR_WIDTH_SHORT = 2 CL_DEVICE_PREFERRED_VECTOR_WIDTH_INT = 1 CL_DEVICE_PREFERRED_VECTOR_WIDTH_LONG = 1 CL_DEVICE_PREFERRED_VECTOR_WIDTH_FLOAT = 1 CL_DEVICE_PREFERRED_VECTOR_WIDTH_DOUBLE = 0 Command queue out of order? = false Command queue profiling enabled? = true Using AOCX: hello_world.aocx Kernel initialization is complete. Launching the kernel... Thread #2: Hello from Altera's OpenCL Compiler! Kernel execution is complete. Okay, some specially prepared examples and files on the flash drive work and print something.
What should I do to build and run a simple example?
Install SDK
We need:
- Quartus
- Altera SDK for OpenCL
- SoC Embedded Design Suite : a set of tools for building and debugging applications on SoC'e.
Installing all of these tools is trivial, but there are subtle points:
- Root rights may be required, and you will be told about this only at the end of the installation.
- After installation, you need to register something in PATH, ALTERAOCLSDKROOT, QUARTUS_ROOTDIR. What is there to prescribe can podcherpnut from the respective guides.
Maybe I did something wrong, but in the end my script for setting environment variables began to look like this:
export PATH=/home/ish/altera/14.1/quartus/bin:$PATH export PATH=/home/ish/altera/14.1/hld/bin:$PATH export PATH=/usr/local/DS-5/bin:$PATH export PATH=/usr/local/DS-5/sw/gcc/bin:$PATH export PATH=/home/ish/altera/14.1/hld/linux64/bin/:$PATH export ALTERAOCLSDKROOT=/home/ish/altera/14.1/hld/ export QUARTUS_ROOTDIR=/home/ish/altera/14.1/quartus/ export LD_LIBRARY_PATH=/home/ish/altera/14.1/hld/linux64/lib/:$LD_LIBRARY_PATH # , export AOCL_BOARD_PACKAGE_ROOT=/home/ish/altera/14.1/hld/board/de1soc Hidden text
Yes, I do not have the latest Quartus'a, and therefore, perhaps, what I will show below was improved in the fifteenth version.
If there is something fundamentally changed in terms of OpenCL, I would be grateful if you knock me in PM.
If there is something fundamentally changed in terms of OpenCL, I would be grateful if you knock me in PM.
After all this is set up and preoccupied with licenses, it is necessary to install our board.
How to do this tells README.txt , which lies in the archive c BSP:
note:before the below operations,make sure you have install the opencl SDK 14.0 and SoCEDS 14.0. 1. directly unzip the de1soc_openCL_bsp.zip into %ALTERAOCLSDKROOT%/board directory. 2. set the "User variables" AOCL_BOARD_PACKAGE_ROOT to %ALTERAOCLSDKROOT%/board/de1soc 3. open the windows command window and type "aoc --list-boards", it should output "de1soc_sharedonly" We execute and check:
ish@xmr:~$ aoc --list-boards Board list: de1soc_sharedonly The fee appeared in the list - it means everything was done right.
We collect an example
To start, I chose a very simple example:
Z = X + Y ,
where X and Y are arrays of N uint (32-bit) numbers.
Kernel vector_add looks very simple :
// ACL kernel for adding two input vectors __kernel void vector_add( __global const uint *restrict x, __global const uint *restrict y, __global uint *restrict z ) { // get index of the work item int index = get_global_id(0); // add the vector elements z[index] = x[index] + y[index]; } I will not give the whole code for the host: you can look at it here .
What he does:
- trying to recognize what OpenCL devices are
- reprograms FPGA using aocx file
- initializes buffers for arrays X, Y, Z
- generates data in arrays X and Y, and also calculates (on the processor) the reference response
- passes pointers to arrays to the kernel
- starts processing
- waiting for her to finish
- compares the reference response with what the kernel considers
Building it is trivial: we run a very simple Makefile that uses the ARM cross compiler. (In our case, the host will be ARM, which is located in SoC'e).
We get aocx :
ish@xmr:~/tmp/cl/vector_add$ aoc device/vector_add.cl -o bin/vector_add.aocx --board de1soc_sharedonly --profile -v aoc: Environment checks are completed successfully. You are now compiling the full flow!! aoc: Selected target board de1soc_sharedonly aoc: Running OpenCL parser.... aoc: OpenCL parser completed successfully. aoc: Compiling.... aoc: Linking with IP library ... aoc: First stage compilation completed successfully. aoc: Hardware generation completed successfully. I remind you that the --profile flag adds counters to the firmware for profiling, and -v is just for verbose.
It takes ten to fifteen minutes.
The vector_add.aocx appeared in the bin directory, and in the bin_vector_add there was a Quartus project, which was going all this time.
Build report:
+-------------------------------------------------------------------------------+ ; Fitter Summary ; +---------------------------------+---------------------------------------------+ ; Fitter Status ; Successful - Sat Oct 17 21:36:01 2015 ; ; Quartus II 64-Bit Version ; 14.1.0 Build 186 12/03/2014 SJ Full Version ; ; Revision Name ; top ; ; Top-level Entity Name ; top ; ; Family ; Cyclone V ; ; Device ; 5CSEMA5F31C6 ; ; Timing Models ; Final ; ; Logic utilization (in ALMs) ; 5,570 / 32,070 ( 17 % ) ; ; Total registers ; 9685 ; ; Total pins ; 103 / 457 ( 23 % ) ; ; Total virtual pins ; 0 ; ; Total block memory bits ; 127,344 / 4,065,280 ( 3 % ) ; ; Total DSP Blocks ; 0 / 87 ( 0 % ) ; ; Total HSSI RX PCSs ; 0 ; ; Total HSSI PMA RX Deserializers ; 0 ; ; Total HSSI TX PCSs ; 0 ; ; Total HSSI PMA TX Serializers ; 0 ; ; Total PLLs ; 2 / 6 ( 33 % ) ; ; Total DLLs ; 1 / 4 ( 25 % ) ; +---------------------------------+---------------------------------------------+ Most of all here are two lines of interest: Logic utilization and Total block memory bits .
This simple example ranked 5570 ALM. In fact, the addition operation takes less than 1% of this number: the rest is taken by the “infrastructure”, which reads and writes data from the DDR (as well as the profiling counters). It is also important to note that the project in Quartus was going with default settings that did not include any resource / frequency optimization.
It is also interesting that automatically “somewhere” appeared a memory with a total volume of ~ 128 Kbps.
By the way, you can see which sections appeared in vector_add.aocx :
Hidden text
ish@xmr:~/tmp/cl/vector_add$ readelf -a bin/vector_add.aocx ELF Header: Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: NONE (None) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 2370388 (bytes into file) Flags: 0x0 Size of this header: 52 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 40 (bytes) Number of section headers: 20 Section header string table index: 1 Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .shstrtab STRTAB 00000000 000080 00011c 00 S 0 0 128 [ 2] PROGBITS 00000000 000200 001000 00 0 0 128 [ 3] .acl.board PROGBITS 00000000 001200 000011 00 0 0 128 [ 4] .acl.compileoptio PROGBITS 00000000 001280 000002 00 0 0 128 [ 5] .acl.version PROGBITS 00000000 001300 00000a 00 0 0 128 [ 6] .acl.file.0 PROGBITS 00000000 001380 000030 00 0 0 128 [ 7] .acl.source.0 PROGBITS 00000000 001400 0006c2 00 0 0 128 [ 8] .acl.nfiles PROGBITS 00000000 001b00 000001 00 0 0 128 [ 9] .acl.source PROGBITS 00000000 001b80 0006c2 00 0 0 128 [10] .acl.opt.rpt.xml PROGBITS 00000000 002280 000019 00 0 0 128 [11] .acl.mav.json PROGBITS 00000000 002300 00107f 00 0 0 128 [12] .acl.area.json PROGBITS 00000000 003380 0009da 00 0 0 128 [13] .acl.profiler.xml PROGBITS 00000000 003d80 002f08 00 0 0 128 [14] .acl.profile_base PROGBITS 00000000 006d00 0009c8 00 0 0 128 [15] .acl.autodiscover PROGBITS 00000000 007700 000071 00 0 0 128 [16] .acl.autodiscover PROGBITS 00000000 007780 00021e 00 0 0 128 [17] .acl.board_spec.x PROGBITS 00000000 007a00 0003eb 00 0 0 128 [18] .acl.fpga.bin PROGBITS 00000000 007e00 23ab98 00 0 0 128 [19] .acl.quartus_repo PROGBITS 00000000 242a00 000151 00 0 0 128 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), l (large) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific) There are no section groups in this file. There are no program headers in this file. There are no relocations in this file. There are no unwind sections in this file. No version information found in this file. Run the kernel
Copy via vector_add and vector_add.aox to the board and run:
root@socfpga:~/myvectoradduint# ls -l -rwxr-xr-x 1 root root 42525 Apr 16 06:57 vector_add -rw-r--r-- 1 root root 2371188 Apr 16 06:58 vector_add.aocx root@socfpga:~/myvectoradduint# ./vector_add Initializing OpenCL Platform: Altera SDK for OpenCL Using 1 device(s) de1soc_sharedonly : Cyclone V SoC Development Kit Using AOCX: vector_add.aocx Launching for device 0 (1000000 elements) Time: 112.475 ms Kernel time (device 0): 7.270 ms Verification: PASS We managed to add 1 million pairs of 32-bit numbers in 7.270 ms or one pair in 7.27 ns. In fact, this indicator is not so interesting right now: the example has not been optimized for performance. (Spoiler: only one adder was used: there was no parallelization of calculations).
After running profile.mon appeared in the directory:
root@socfpga:~/myvectoradduint# ls -l -rw-r--r-- 1 root root 170 Apr 16 06:58 profile.mon -rwxr-xr-x 1 root root 42525 Apr 16 06:57 vector_add -rw-r--r-- 1 root root 2371188 Apr 16 06:58 vector_add.aocx Copy it back to your computer and see the result of profiling:
ish@xmr:~/tmp/cl/vector_add$ aocl report bin/vector_add.aocx profile.mon 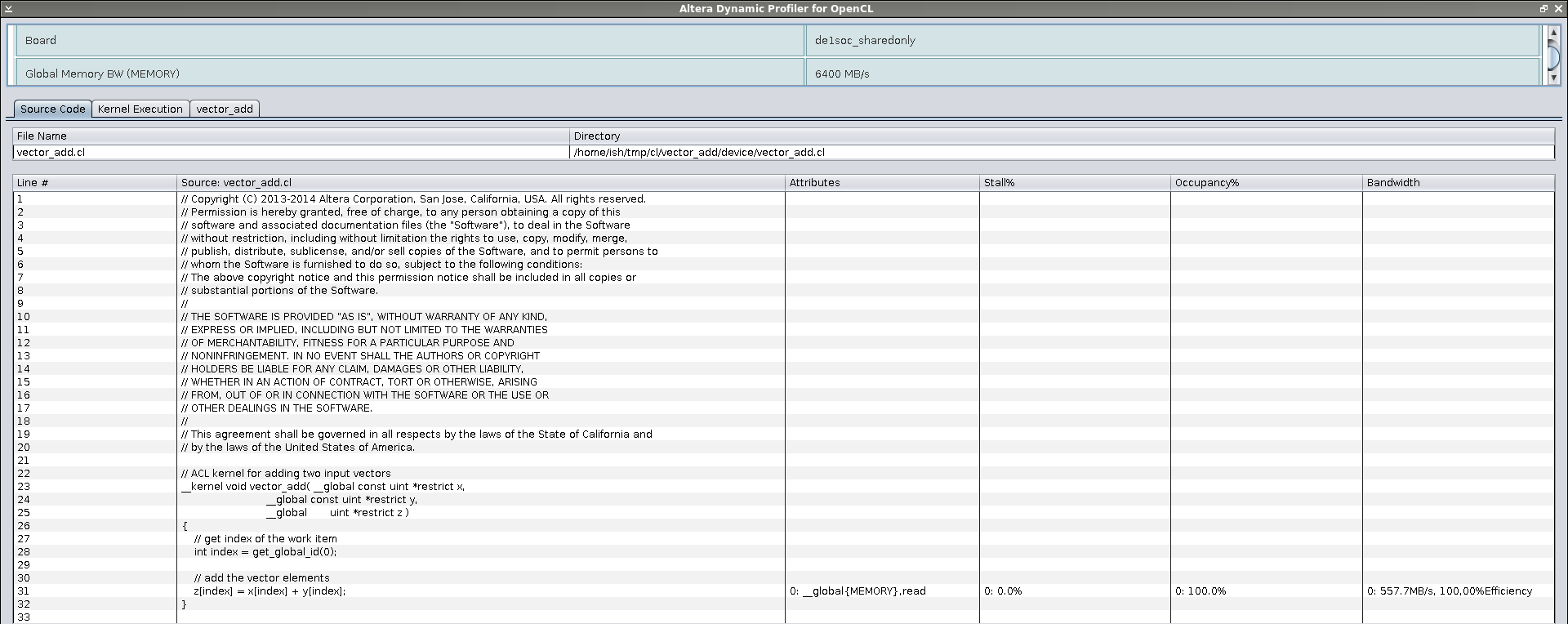


The profiler showed that we used only a third of the bandwidth to global memory.
It is possible to start the visualizer:
ish@xmr:~/tmp/cl/vector_add$ aocl vis bin/vector_add.aocx 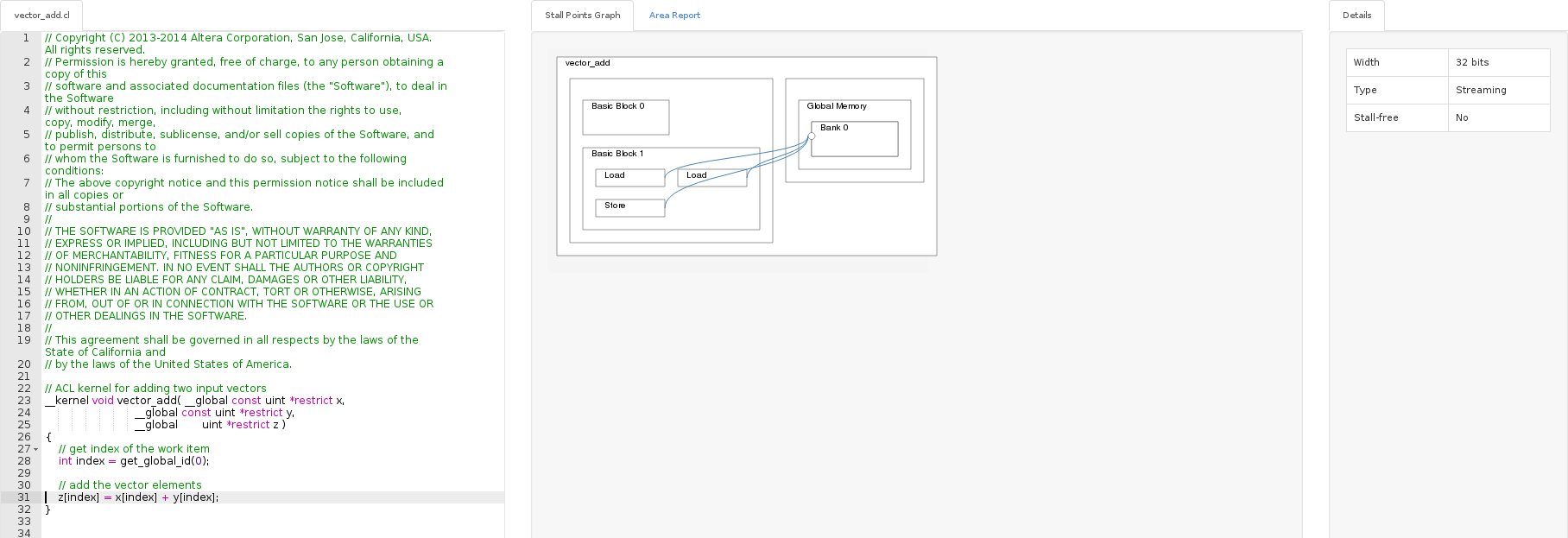
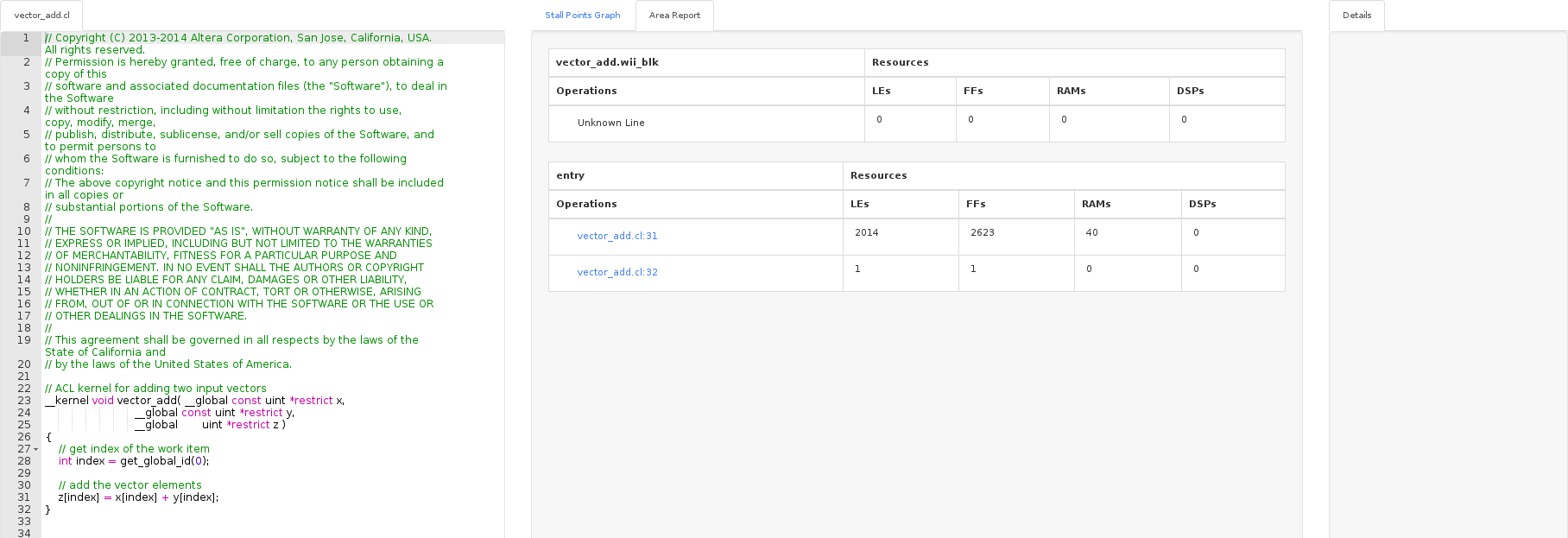
The visualizer showed that there are three blocks that communicate with the global memory: two for reading, one for writing. Access to global memory in this case may be a narrow link. In the Area report for each line you can see the amount of resources spent in the FPGA for implementation. Of course, the example from one line is not indicative.
On the altera's youtube channel there is a video where all the steps I mentioned above are shown in detail:
The rest of the video from this cycle can be found under the spoiler:
Hidden text
Conclusion
In this article I tried a tool that allows writing under FPGA at a high level without knowledge of HDL languages. As we see, it works (on a simple example), and we really didn’t have to do anything extra.
OpenCL under FPGA will not be a gold hammer:
- It does not allow to describe the processes up to the tact (but this is exactly what we wanted to leave!)
- Not applicable on small chips: the infrastructure eats away a huge amount of resources.
However, using it FPGA can make a very real competition for the GPU in such areas as video processing (machine vision), encryption, DSP, simulation (simulation) of various processes. If we talk about the areas where I work (generation, filtering, switching of Ethernet packets), where squeezing the maximum performance just happens due to the lowest level control, I don’t understand how to use OpenCL (and get a similar result).
If there is a need for maximum performance, then you need to understand very well what is the result of this or that construction of the language. Therefore, it seems to me that those who want to write something more or less serious on OpenCL under FPGA will have to learn Quartus, Qsys and Verilog (at the reading level) at a basic level. Perhaps, the visualizer and profiler will suffice, but as long as they look like student fakes, I hope this will be fixed in new releases of the quarter.
If we talk about real-time video processing, I recommend looking at this demo:
The guys from iABRA initially did machine vision on OpenCL under an AMD GPU, but then moved to Altera. The programmer emphasizes that the use of OpenCL allowed “not to understand the VHDL, because they have no experience in this, but write on what they can. ”
In some reports comparing implementations of algorithms (encryption, video processing) on the GPU and OpenCL FPGA, it is argued that the number of operations performed per second is about the same, but the FPGA consumes 10 times less power. I am always skeptical about such benchmarks, because I have not tried them myself)
With the release of the new Arria 10 and Stratix 10 families, I admit that more and more parallel computing will switch to the use of FPGA: we will see these chips in supercomputers and in data centers.
And one more video about the real use of Altera SDK for OpenCL:
Thanks for attention! I will be glad to questions and comments in the comments or in a personal)
Useful links :
- Sample sources and auto-twisted verilog code
- Altera SDK for OpenCL: Overview
- Altera SDK for OpenCL: Getting Started Guide
- Harnessing the Power of FPGAs using Altera's OpenCL Compiler : a very large presentation (> 100 slides) for those who love to watch pictures :)
- Altera SDK for OpenCL: Programming Guide
- Altera SDK for OpenCL: Optimization Guide
- Altera SDK for OpenCL: Best Practices Guide
Update :
Released the second part of the article: Altera + OpenCL: open the kernel .
Source: https://habr.com/ru/post/269009/
All Articles