Machine learning, predicting the future and analyzing the reasons for success in e-commerce

We continue to publish materials from the summer conference Bitrix Summer Fest . This time we want to share with Alexander Serbul’s presentation on current machine learning trends, available techniques, and practical ways to use mathematics to increase conversion and retain customers.
The material in any case does not claim to be formal and scientifically strict. Think of it as a light, fun, useful and introductory "reading matter."
In the world of big-data, higher mathematics and machine learning, something unimaginable is happening now. When we enter this area and start counting the money it can give, it turns out that we need knowledge, materials and experience from various other areas. We, as a rule, are developers. Some of us may be with some mathematical background, someone writes a good code, someone, for example, a dock in mathematical statistics. And machine learning just requires knowledge and skills in these areas.
')

And it does not forgive us some amateurishness. But very few people can with sufficiently high competence to understand all these areas. And this is a big problem. This is understood by modern researchers of machine learning, scientists and employees of various companies. It turns out that everyone wants to use machine learning, but there are no people who are well versed in all the necessary areas and can eclectically connect the components together.
If you turn to Wikipedia or Google in the hope of understanding what logistic regression is, you can go crazy. A normal person will not understand what is written there. After all, mathematics is a separate culture that lives by its own laws. This also applies to us, the developers. If I tell some mathematics about the TCP / IP stack, about state diagrams, datagrams, refer to the authors of Unix, then he will not understand me either. And if the developer does not have a "sufficient" mathematical education, it will be quite difficult for him to master the theory of sets, the theory of probability, mathematical statistics, higher mathematics, series, and much more. And scoring by habit in the search engine query, you will understand little of the results.

You will say that a good developer should know mathematics and be able to learn in general, and refer to the “correct” literature. For example, re-read "Reference book on higher mathematics" Vygodskogo. And in general, it will be necessary to remember what we were taught in universities, to get into the theory of probability, because the expectation, the correlation matrix, the variance, the standard deviation, the median, the mode - all this we need to know and remember. But life imposes its own “professional deformation”: the modern IT world requires narrow specialization, since it is almost impossible to be a universal, deeply understanding a number of scientific and applied disciplines. And it is very clearly manifested in the situation around big data and machine learning.
What to do?
In fact, now nobody knows what to do with it. But I still want to try to give a recipe. I will give an analogy with karate. This martial art originated among the Japanese peasants who wanted to confront armed and well-trained samurai. Thanks to karate, peasants armed with sticks and hoes managed to resist the soldiers in armor with swords and spears.
In Big Data, I want to suggest that you use an approach where you need to know a small amount of things, but know them well. Someone may become a sensei over time if he develops intensively and reads the necessary literature.
To begin, let's consider what types of machine learning are, what are the principles of their actions, how to evaluate their quality and how they can be applied.
What is machine learning?
Why do we need machine learning, why did it come up?
Typically, the developer solves the task as follows: he sat down, poured coffee, invented (he took it ready - this is more often) the algorithm, coded it - it works. The problem is that there are situations where it is extremely difficult to logically solve a problem because of the volume of data and complex interrelations. Also, often there is little time to solve the problem. In such cases, it is best to have the computer do all the work for you, learn how to make decisions yourself. Those. you need to make a drone out of it and make it not only work, but also think for you.
The basic assumptions of the theory of probability state that it is possible to sit down and think over all the connections between entities, but this is very long and expensive. For example, it is necessary to calculate the range of the projectiles, while there are fluctuations in mass, temperature, quantity and chemical composition of gunpowder, the angle of inclination of the gun, etc. All this can be taken into account, but you will create a model for a long time and it will be suitable for a specific case - it is expensive. Therefore, at one time, a probability theory was created, which studies random phenomena and carries out operations with them - in general, they came up with “how to save” and “shorten the way”. And with the help of machine learning, you can just “teach” a computer to use the tools of probability theory, and it will be done a priori faster than a person.
What can you teach a computer?
First, to classify things: you can determine the gender (male / female), classify mail (spam or not spam), carry out multiclass classification (stone, scissors, paper). An example of a multi-class life classification: the definition of customer income (low, medium or high — three categories).
A computer can also learn on its own - this is a clustering task - it takes the data and understands how to group it - but that’s if you're lucky. There are tasks where the computer needs to be taught. That is, there are roughly two types of training: with a teacher and without.
You can teach a computer to predict certain data using regression. Suppose we have a database of apartments with their value and certain attributes (district, area, presence of a kindergarten nearby, etc.). We train the model and then enter new data, new attributes, based on which it predicts the price. This is a regression.

How does a computer learn?
Perceptron
People have always tried to find out how the human brain works. But only relatively recently it was found out that the model of neural connections is quite simple and can be implemented algorithmically.
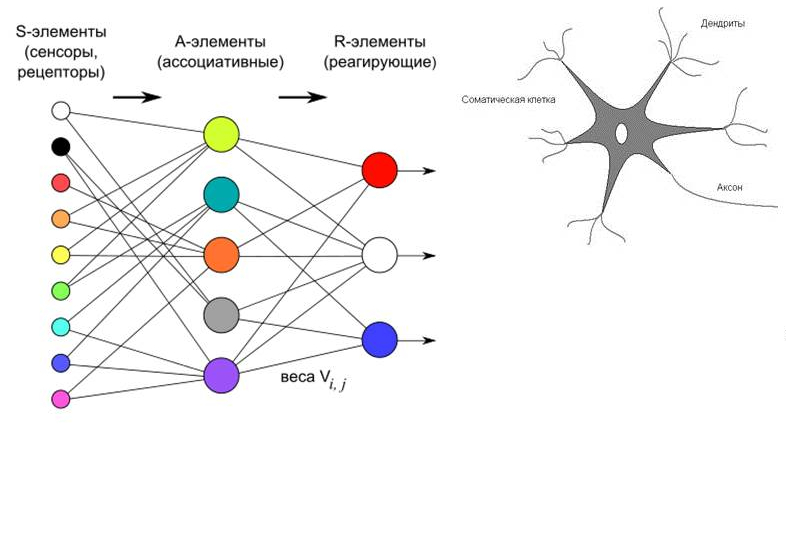
Data (S-elements) are fed to the input, then A-elements (neurons) take on some values. We can assign weights, that is, the number of signals reaching each neuron can be varied using mathematical methods. And the output is R-elements, that is, a kind of prediction issued by neurons.
The disadvantage of this approach, implemented “head-on,” is that neurons can predict only by dividing elements in space linearly.
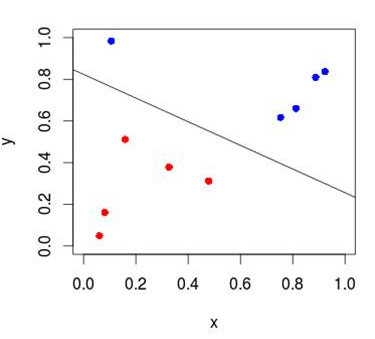
If we have two-dimensional space, then the boundary will be a line, if multidimensional, then the hyperplane. With this approach, it is possible to solve problems associated with binary classification, that is, with the division of data into two groups.
You can also add an intermediate layer. As a rule, it is not recommended to add more than one intermediate (hidden) layer (otherwise the training time will greatly increase).
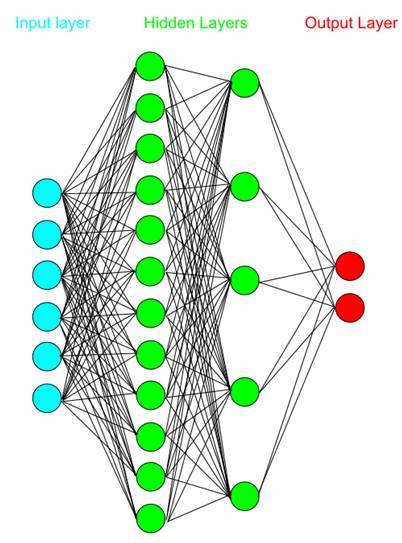
The resulting system is a multilayer perceptron - a neural network. Due to the additional layer of neurons, the perceptron can group data in much more complicated patterns. That is, not a straight line or a plane, but much more complex lines and surfaces will act as a border. In other words, the perceptron can approximate any surface. Developing an idea, you can even learn to recognize faces.

Today, perceptrons, both ordinary and multilayer (MLP, multilayer perceptron), are well studied and widely used, especially in deep learning
Bayesian ID
Englishman Thomas Bayes was a mathematician and priest. In between worship he created the Bayes theorem . It deals with the probability of one event, subject to the origin of another interconnected event. That is, the whole theorem is visually represented as two intersecting circles.

This theorem and Bayes classifier are used almost everywhere. For example, mail filtering - spam / non-spam is a Bayesian classifier. It is much easier to code than a multilayer perceptron. He learns faster than the neural network. In addition, it is much more accessible to understand. Therefore, when you face the task of quickly classifying something, this is the easiest option.
Another popular option for binary classification is logistic regression.
Decision tree
Suppose you are faced with the task of quickly determining whether a certain animal is flying or crawling. You can ask if he has paws, tail, eyes, esophagus, nose - all this does not bring us closer to solving the problem. Just ask if he has wings. If yes - it is a flying animal.
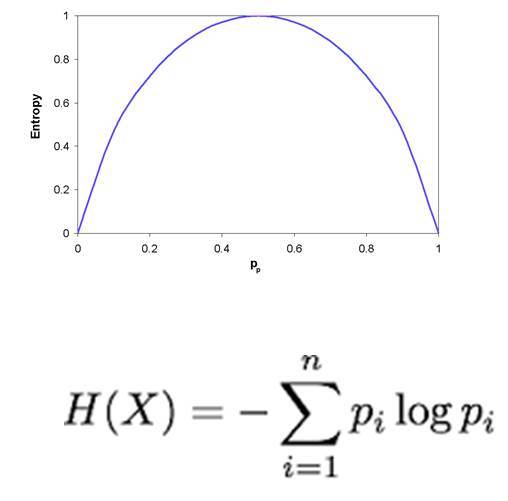
If there are attributes at the input, then with the help of the tree, attributes are searched that allow unambiguously to cut off a part of the input data as if they do not satisfy any condition. With the help of leading questions, you can very quickly share many possible solutions, step by step reducing the amount of input data. How effectively each attribute divides data is called entropy.
You can train a classifier and he will build a decision tree inside himself. Here is an example of a tree with which you can determine the probability of survival in the crash of the Titanic.

The decision tree is built quickly and transparently, you can expand the constructed model and see how it works.
Random forests

Random forests are a collection of decision trees. How it works? You can build a lot of small trees that do not work “well enough”, but if you combine the results of their work, then the efficiency of this set of trees is much higher than that of a single large and complex tree. The word random is used because an element of randomness is added to the operation of this forest.
This algorithm is now very popular, because it is very well parallelized - you can deploy thousands, millions of trees on a heap of cheap iron and conduct machine learning, which will work at the level of the best analogues in the world. This algorithm is very efficient.
Boosting
This algorithm works as follows: it builds, for example, trees one after another, and each next tree learns from the results of the previous one, and the data is modified. The algorithm can thus divide nested rings into classes, which is a rather difficult classification task.
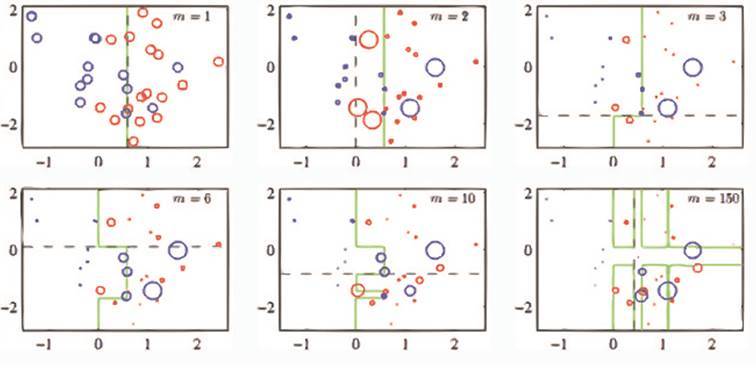
Boosting takes much longer to complete than the Random forests. This is due to the fact that in this algorithm it is necessary to consistently train each tree. This is a big problem.
Hidden Markov Model
This model was developed on the basis of the Markov process created by the famous Russian mathematician Andrei Andreevich Markov. Markov models are popular in the world, they are actively used by many companies, including Google. The essence of the Markov model is very simple.
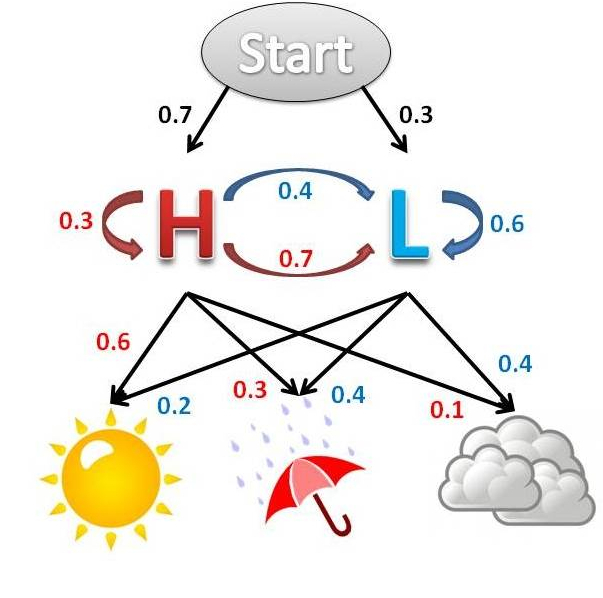
There is a certain state - for example, high or low air temperature. But what kind of condition - you do not know. But you know the signs: the sun was shining, it was raining, there were clouds. You have a certain set of values collected for the statistical period: the sun - rain, the sun - rain - clouds. The numbers above the arrows are probabilities, i.e. if the sun, then with a probability of 60% is warm and with a probability of 20% it is cold. If the clouds, it is warm with a probability of 10%, and cold with a probability of 40%.
When you get a list of states, you can calculate in which internal, hidden state the system was. What can it be useful for? Say, when you analyze the client's action - he paid for it with a card, turned to tech support, made an order, looked at the catalog item - you can tie these actions to hidden actions.
For example, actions that show the level of customer loyalty to you - low, medium, high. And based on this, you predict the state of the client. If yesterday he was in a "high" state of loyalty, tomorrow on average, the day after tomorrow in a low one, then the trend will let you know that you need to do something, otherwise you can "accidentally" lose the client. Hidden Markov models are widely used for solving such problems.
How to evaluate the quality of the model?
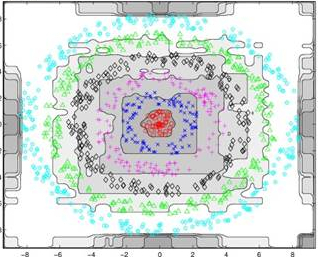
There is one fairly good, understandable to all measure of the effectiveness of mathematical models, predictors - Confusion matrix .

Suppose you have trained a certain model and it has decomposed the original data into groups. Horizontally, real groups are deposited, and vertically - predicted by the model. In the example above, we have in fact 209 ducks (the total number in the Duck group horizontally), 242 birds (Bird), 209 frogs (Frog), 198 gulls (Seagull) and 198 pigeons (Dove). Quantitative distribution of results by groups is presented in columns. The more accurately your model works, the better it is, the brighter the data diagonal on the matrix is, the smaller the values in the cells outside the diagonals.
Where and what to apply?
Churn-rate : classifier, regressor. It is used to calculate the probability that a particular person may cease to be your client. This is useful when conducting marketing campaigns to retain customers. You make a classifier: enter customer data and, on their basis, determine whether it will leave or not. This saves the marketing budget.
CLV (customer lifetime value) : classifier, regressor. By the activity of the client allows you to assess how much money he can bring to your company. Enter all statistics into the system, make a perceptron, or build a decision tree, or a Bayesian classifier, or a logistic regression, and determine how much money the client has brought - a small amount, medium, large. Then enter the customer data and the model predicts that this customer can bring you a large amount (before that you already learned how to count the probability). And when the client is ready to leave, and he is expensive and can bring a lot of money, you start working only with him, and not with everyone. As a result, your marketing campaigns shrink and become more efficient. Or if such a client calls you, then CRM redirects the call not to the manager, but to the manager. This approach is widely used in the West by banks, insurance companies, large retailers. We are just starting to develop it.
The effectiveness of a marketing campaign for a specific client : a classifier. By collecting data from several past marketing campaigns, you can assess whether a new customer will respond to the next campaign.
For example, you have developed five advertising campaigns. And when you need to stimulate a client who is ready to leave and is valuable to you, you are mathematically testing which advertising campaign he will respond to. Thus, it is possible to group the client base and target advertising and marketing campaigns for the sake of increasing their efficiency.
Customer loyalty trend : hidden Markov model. You track the internal state of the client in the system by his actions. If the trend of the internal state falls, you are doing something.
Price / volume of purchases : regressor. The classic problem of forecasting the volume of purchases of goods based on the intensity of sales.
Similar products : KNN (k nearest neighborhoods). You are clustering products, looking for the nearest cluster and returning products that are most similar. This is a variant of the search engine algorithm in mathematical KNN.
Accessories : item2item collaborative filtering. You have basic products and you need to bind related accessories, for example, cases to smartphones. Customers, walking through the site and choosing, give you data from which you can build a matrix to perform the binding. Thus, we offer the client relevant products, increasing turnover and customer satisfaction.
Recommendations : item2item collaborative filtering. The approach is similar to the previous one. For example, you watched two films from the Star Wars series, and we recommend the rest to you. That is, we recommend you products that have already been bought by your friends or people who resemble you by some criteria or behavioral patterns.
Soft
You can play with different algorithms with RapidMiner, IBM SPSS, SAS, Spark MLlib. For example, in our project we need to count everything in a parallel cloud, and for this we need Spark, MapReduce and a lot of beer cans.
Colleagues, we wish you good luck in the fascinating process of applied machine learning. The main thing is not to give up, constantly go ahead and useful models for business will open in all its glory. Only by diligently experimenting with algorithms, data sets, and measuring the quality of the output, you can achieve sustained success and overtake competitors. Good luck to you!
Source: https://habr.com/ru/post/268971/
All Articles