Mastering the Data Science specialty on Coursera: personal experience (part 1)

Recently, Vladimir Podolsky vpodolskiy , an analyst in the department for work with education of IBS , completed a course in Data Science on Coursera. This is a set of 9 course courses from Johns Hopkins University + thesis, the successful completion of which entitles you to a certificate. For our blog on Habré, he wrote a detailed post about his studies. For convenience, we have divided it into 2 parts. We add that Vladimir became also the editor of the project for translating the Data Science specialization into Russian, which was launched in the spring by IBS and ABBYY LS .
Part 1. On the specialty of Data Science in general. Courses: Data Analysis Tools (R Programming); Preliminary data processing; Documenting data processing.
')
Hi, Habr!
Not so long ago, my 7-month marathon to master the Data Science specialization at Coursera ended. The organizational aspects of mastering a specialty are very precisely described here . In my post I will share my impressions of the course content. I hope that after reading this note, everyone will be able to draw conclusions for themselves whether it is worth spending time getting knowledge of data analytics or not.
About specialty in general
The specialty “Data Science” at Coursera is a set of 9 interrelated courses on various topics related to all aspects of data analysis: from data collection to the development of a full-fledged analytical product (online application). Cherry on a nine-layer pie is a graduation project in the specialty (the so-called Data Science Capstone), which makes it possible not only to practice all the mastered skills in the complex, but also to try to solve the real problem. The project is given already 2 months and it starts three times a year, whereas each of the 9 regular courses takes a month of study and begins every month.
Mastering the whole specialty “Data Science” with obtaining certificates for each of the 9 courses is not a cheap pleasure. I was lucky with paying courses - IBS fully sponsored my training. The company was looking for volunteers for the development of the Data Science profession and offered to pay for the certificate to each employee who successfully completed the Coursera course. Nevertheless, if you don’t bother and don’t take three courses a month, your own funds will be enough - each course costs $ 49, except for the first one, which is cheaper than the rest (in rubles, as a rule, the price is also fixed, but periodically changes ). However, no one cancels the free option in case there is no need for certificates.
To be honest, it was not easy to study - it was impossible to watch lectures and perform tasks either late in the evening after work (hello, beloved Moscow region), or on weekends. And it was not uncommon for the students to pass situations at the last moment that were typical for students. Additional problems created a limited time for passing tests and reporting materials - if you do not have time on time, blame yourself - points for being late are removed. In case the task is evaluated by fellow students, the late student does not receive points at all. Nevertheless, such an approach keeps in good shape.
And, finally, about what I received from the specialty "Data Science"
- systematized knowledge of data analytics. I had learned to form analytics of various levels of complexity before mastering DSS, but my knowledge and skills were rather fragmented. Although in Baumanka they gave high quality matstatistics and teverver, but not a word was said about how to process the data (the course on databases was, but it was about Oracle and sql queries);
- learned to work with the language of R and RStudio. Very handy tools, by the way. If it was necessary to somehow change the processing process, it turned out to be much easier for me to make changes to the code on R and restart it than to repeat the same sequence of actions using the mouse in Excel. However, this is a matter of taste. In any case, the commands and functions of R are very well adapted for processing data of any kind: almost all the necessary functions can be found in freely distributed packages, and the missing ones can be added independently (if there are corresponding coding skills in C);
- Got an idea of how to do data research with maximum efficiency. As in any study, it has its own structure, its own rules, basic data and results. Everything, let's say, fell into place: we receive data, clear them and normalize, conduct exploratory analysis (record its results along the way), conduct a full study, record the result and create, if necessary, an application for processing data using a fictitious method. This is if in rough terms - each process has its own subtleties and pitfalls. For example, I was particularly interested in the preparation of reports on the results of data analysis - the lecturers led a very good report structure from an unprepared user’s understanding;
- An additional bonus was the presence in R of special packages for processing and visualizing graphs. The fact is that I am also laden with my PhD thesis, where the lion’s share of the methods used is based on graph approaches. Perhaps nothing easier and clearer implementation of R operations on graphs I have not seen. I did not have to reinvent the wheel ...
About courses
According to my subjective feelings, all 9 specialization courses can be grouped into five blocks. Each such block simultaneously overlaps a number of fundamental points in data science. Grouping is given in the table.
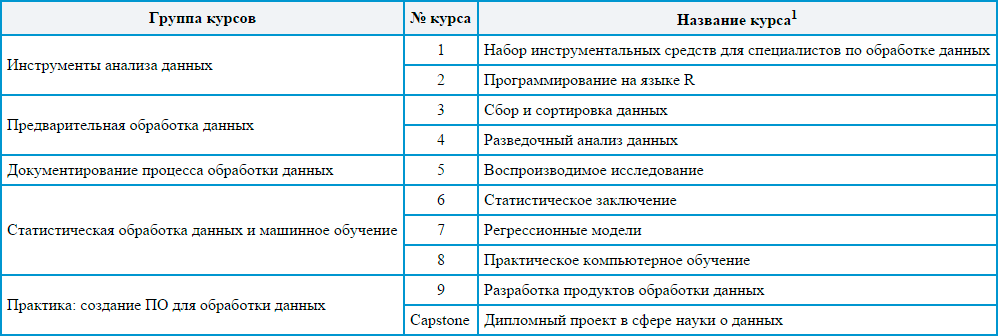
1 The titles are given in accordance with the official translation of the DSS into Russian on the Coursera website.
Data Analysis Tools (Courses 1 and 2)
There is a widespread opinion that if in the first minute the lessons on tools (software, etc.) the students did not fall asleep, then the lesson can be considered successful. In this regard, the courses on the DSS toolkit were fully successful - it is interesting to listen, and it is more interesting to try the tools on the go than to listen. The attention of both courses on data analysis tools is focused on the R programming language. In essence, the student is smoothly introduced into the topic of data analysis and is immediately given to try out the tools in practice in order to get comfortable. The courses are largely unhurried, but cover all the necessary basics. Deeper knowledge of R is given during the rest of the courses - as needed. Somewhere dplyr'u teach, but somewhere closer with ggplot will be introduced. Such a practice-oriented approach “to explain as necessary” is, in my opinion, very effective - dry instructions for using tools quickly evaporate from the head. If you do not use a skill, then it dries out. L On the screenshot is a typical RStudio.
But, as usual, not without a spoon of tar ... Although the authors clearly did not set out to make an exhaustive overview of all the R tools and give the opportunity to properly test each tool, the given review still seemed to me insufficient. In particular, the topic of creating own packages of functions for R was very poorly disclosed. It might be worthwhile for her to create an advanced unit that would not be included in the test questions. From the experience of working with R, I can say that writing modules is extremely important for those who seriously decided to do data analytics on R. I would love to delve into this topic (which, apparently, I will do, but on my own).
I would also like to have more detailed information in the video format on examples of using functions from different auxiliary packages, but this is more of a fault - most of the time, working with functions from different packages is quite transparent when reading the corresponding manuals.
Preliminary data processing (courses 3 and 4)
In this group, I threw courses on data collection, pre-processing and exploratory analysis. In general, these are really all the phases that precede the process of deep data analysis. These courses seemed to me very interesting, if not exciting. And why? As part of these courses, we are shown and told: a) how to collect data from various sources (including social networks and from web pages) and b) how to build simple graphs explaining what the collected data can tell us. In general, it turns out such a scanty, but more or less complete approach to data analysis.
From the preprocessing it is worthwhile to select extremely useful information on how best to bring the data to normal form. Under the normal form means the form of data organization, in which each column of the data table corresponds to only one variable, and each row - only one observation. It is these tables that are easiest to further process and analyze. However, as a rule, the data to us gets in a poorly organized form or even completely unstructured (for example, messages in social networks are arrays of symbols, text). For further processing, such data arrays should be reduced to normal form, which can be done with the help of various commands from the dplyr package . Moreover, it is important to understand that for each new data source, its own sequence of transitions must be defined for the implementation of the final normalization. Without manual coding here, as usual, nowhere ...
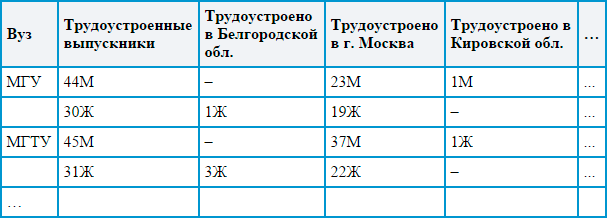
Using the example of two tables, I tried to show what kind of a beast it is - “normalization”. The data for the tables are invented on the basis of the project on the work ...
If the original data table looks like this:
Then during normalization we should get something like this:
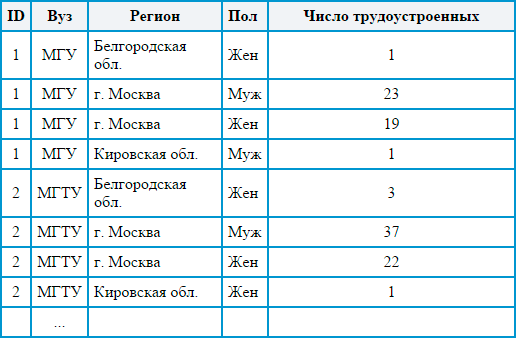
Agree, the second option is easier to handle automatically using formulas and functions, and it looks much more presentable. Here, each observation has a unique identifier, and the value of each variable can be selected separately, and in general, the structure turns out to be more logical and easy to read. Processing tables in a normalized form is easy and fast using automation tools (as a rule, this form is not always convenient for people). On the basis of such data, R makes it easy to build various descriptive diagrams, like the one below. The data for the diagrams are taken from the official website of the Ministry of Education and Science of the Russian Federation .
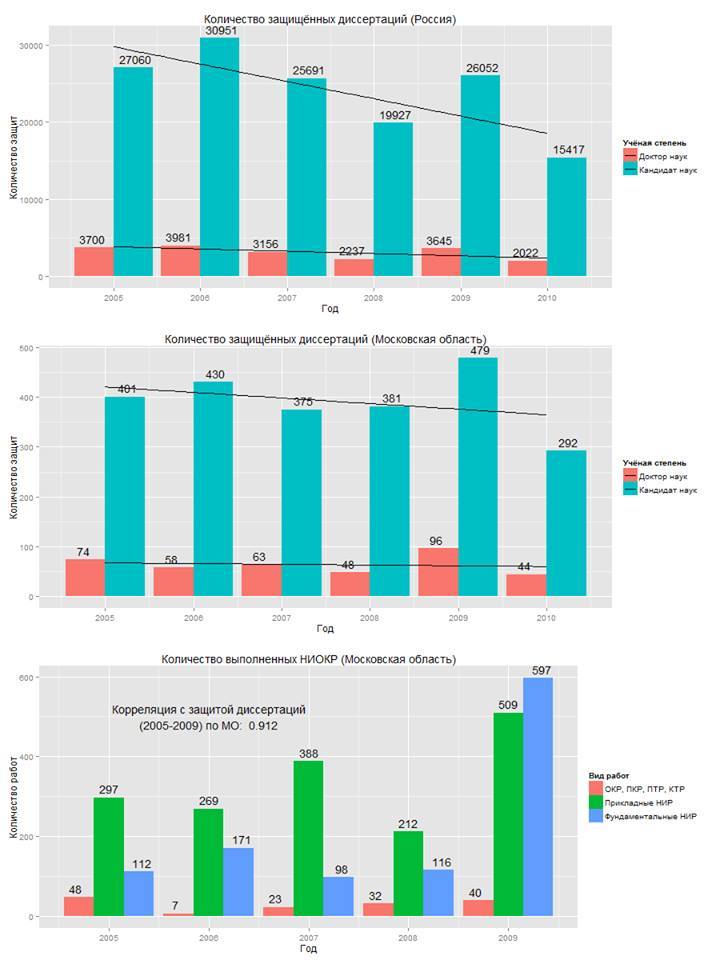
I like the style of the R diagrams - they combine simplicity with the rigor of scientific style and clarity. The functionality allows you to color diagrams, but you still should not get too carried away - it will be difficult for users to find their way in a diagram dazzling with all the colors of the rainbow. In addition, diagrams can be saved in separate files and later used as illustrations in scientific articles, presentations or other works. By the way, to build a single diagram, it is enough to write only a simple line of code (although with preliminary data processing to build a diagram, sometimes you have to tinker).
Summarizing this part of my opus, I would like to note the extraordinary importance of the steps described in this section for conducting a high-level analysis. In data analytics, as well as in work with anti-aircraft installations, if the sight hits at least half a degree, the projectile will not hit the target. In order to ensure high accuracy of the “sight”, it is necessary already at the first stages to properly prepare the data for analysis, as well as find out what questions and how they will help to answer. For the second goal, this very exploratory data analysis helps a lot - the simplest graphs already built at the initial stage are able to demonstrate basic patterns and even generally answer the question of whether further analysis is needed and whether it can be performed on the available data or not.
Documenting Data Processing (Course 5)
Documenting anything has always seemed to me an incredibly boring act. When everything is done and works fine, it would seem, why document the actions performed? Why spawn new and new documents? Why all this waste paper?
But in analytics of the data of the conducted research and the results obtained it is not enough - in order to convince the rest of the cohort of analysts, it is necessary to tell how and over which data the processing was carried out. So, if your research cannot be repeated, then such a study is worthless. Therefore, in one of the courses, DSS is taught how best to document the data processing performed. In essence, they teach the rules of good form in science: did — tell everyone how I did.
Documentation within the course is quite extensive. For this process, the built-in RStudio toolkit is used. The document describing your data exploration will be created on the basis of the Rmd file, in which you will describe exactly how you worked on it. Examples of documents can be found here .
In general, within the framework of the course, it was recommended to adhere to approximately the following structure for presenting information:
- summary of work performed (including the goal);
- description of the data set (decoding of variables, description of the order of receipt, references to data sets);
- description of the data preprocessing procedure (data cleansing, normalization);
- a description of the data processing conditions (for example, the initiation of a random number counter value);
- results of exploratory data analysis;
- in-depth analysis results;
- findings;
- applications: tables, graphs, etc.
Of course, this is not a panacea - it is worth retreating from a given structure, if you need to describe something in addition or describe something inappropriate. However, it is this structure that allows the reader to quickly understand the essence of the research you have done and, if necessary, repeat it.
What I like about R in terms of documentation is the fact that in the Rmd file you can provide textual description with data processing code inserts, which when compiled Rmd file to PDF is converted into processing results: calculation results, beautiful graphics and so on. In fact, it is very convenient - no need to think where and how to add another illustration.
You can create a very neat PDF or HTML document from an Rmd file (including a presentation, but this is a slightly different story). This dock is not ashamed to show colleagues in the shop data analysis. Yes, and it will be useful for yourself: so when you want to return to your research a year later, you probably don’t remember where the data came from, how it was processed, and why you did it at all.
The end of the first part
Read in the second part : Courses on stat. data processing and machine learning; Practice: creation of software for data processing (thesis project); other useful courses on the Curser.
Source: https://habr.com/ru/post/268491/
All Articles