Three days that shook us in 2013

“If you have doubts whether this is an accident or not, then this is an accident!”
(c) Wisdom of the ancestors
Big failures in online projects are rare. And in large projects - even less. Of course, the more complex the system, the higher the probability of error. One hour of downtime for large systems, especially social networks, is expensive, and therefore large projects make a lot of efforts to prevent accidents and reduce the negative effect on users. But sometimes either the stars add up to a special combination, or Murphy's law takes on real power, and big accidents do occur. In the history of Odnoklassniki, the largest failure occurred on April 4, 2013: for three days the project was wholly or partially inoperable. About what happened then, for what reasons and how we struggled with this, there will be our story.
1. What happened?
One evening, the monitoring system recorded a minor problem with one of the servers. To fix it, you had to fix the configuration template. The administrator on duty asked for help from a colleague who developed this template. It turned out that it was necessary only to add one small line of code, in the image and likeness of the previous ones. The administrator made the necessary corrections and sent the file to production.
')
Soon the messages about failures on different servers fell down, their number quickly grew. The attendants immediately raised the log and suggested that the whole thing was a modified configuration template. Naturally, the changes immediately tried to roll back, returning the original version of the template to the servers. However, by that time, all Linux machines, which then made up most of the Odnoklassniki server park, had already failed. So began the longest three days.
A follow-up analysis in hot pursuit helped to establish the cause of the avalanche-like failure that paralyzed all subsystems.
- At that time, we used the old version of openSUSE and, as a result, the old version of bash out of the box. Zabekportit changes we needed looked easier than updating to a new branch (now bash has been updated to a new branch, which required fixing the syntax of some system and our scripts). In the process of backporting, an error was made that manifested itself only with the next change of the configuration template, common to all servers.
- The developer who created and tested the template worked in a text editor that does not automatically add a newline at the end of the file.
- But the duty administrator of the rules is the template file in another editor, which placed this symbol at the end of the file.
- It turned out that in our centralized management system (CFEngine) there was a bug , because of which a line break character is always added to the edited file. The result is two hyphenation characters in a row — an empty line at the end of the file.
- In the code we modified, bash turned out to be another bug, due to which the interpreter, upon detecting an empty line at the end of the configuration file, entered into an infinite loop and stopped responding to external commands.
As you know, the command interpreter is used in a variety of operations, including during the execution of service scripts. The bash processes launched on the servers immediately went in cycles and swiftly absorbed the available computing resources of the machines. As a result, the servers quickly reached the maximum load. But it was still half the trouble. The fact is that bash was also used by the centralized control system. Therefore, overloaded servers in addition stopped responding to any external commands. We could not log in to them, and within a very short period of time about 5,000 servers ceased to function.
Questions for self-test:
What will you do if your centralized management system fails? And if at the same time it will not be possible to log in to the server?
2. Three days of recovery
Unfortunately, it was impossible to restore the system to work just by restarting the servers. This is due to the architecture of the portal.
2.1. Interconnection subsystems
Classmates consist of approximately 150 subsystems (various databases, business logic servers, caches, graphs, frontends, configuration systems, etc.). And the performance of almost every subsystem depends on the availability of others. If the servers are chaotically restarted, then it is possible to disrupt the work of not only one specific subsystem, but also many other related subsystems.
An example of connections between subsystems:
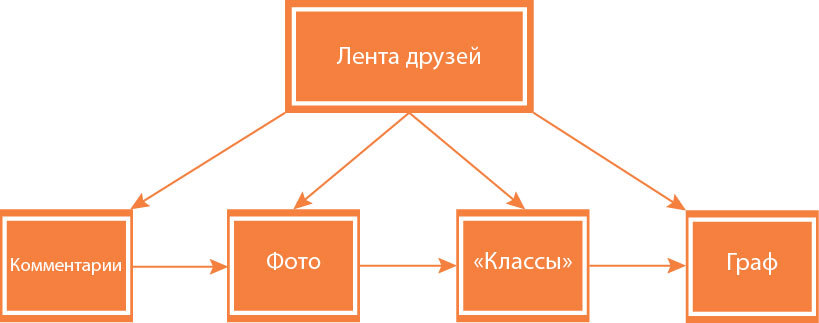
Something like a classic:
The fact is that the development and changes in the project architecture did not create a scenario in which the entire server cluster could fail at the same time. In the code of some subsystems, there was no mechanism for starting and operating under conditions of complete unavailability of some related components. It was assumed that all systems will work at least partially due to duplication of functionality and the use of backup machines.
Questions for self-test:
Do you have a mechanism for starting services in the event that all or part of interconnected subsystems are inoperable?
2.2. Server restart
In order to launch the main subsystems at the same time, at first it was necessary to restore a small number of servers: the service ones and those needed to start one or another service. This made it possible to gradually restore the work of services dependent on it, then others, etc. As far as possible, duplicate servers were raised from non-existence for the most critical services.
As you remember, it was necessary to revive about 5,000 cars. It was impossible to reload them remotely and download over the network, since many were simply not configured for this. This was the result of a once chosen approach to building infrastructure. After all, Classmates did not deploy several thousand servers from scratch at the same time - the park gradually grew over several years. Therefore, we had to manually reboot thousands of servers and allow the BIOS to control the network to automate the recovery.
Initially, on some servers it was possible to “reach the bootstrap” - get a description of the cluster and find out exactly where certain data is stored in it. While the servers were not restarted, they very slowly, but still gave the configuration, and it was possible to start some services. With the acceleration of the recovery process, we had to restart these servers. But for the start or normal operation of each subsystem it is necessary that other related subsystems are available. Because of the reset, access to the description of some clusters and the ability to start many subsystems was lost. Those that could be running, have not started. And those who worked, stopped working, and had to re-restore them.
Another problem was related to hard drives. If they work for a long time without stopping under a high load, then they often fail when shut down. It is with this phenomenon that we encountered. Therefore, we had to regularly replace failed disks and restore database consistency. There were even cases when disks with a working copy and its backup failed. And the servers were in different data centers. So it coincided.

Questions for self-test:
- Are your servers configured for remote restart?
- How secure is your data backup system?
2.3. Data recovery
It was necessary to restore backups, making in them the accumulated transaction logs, then to deploy working copies and start services. We were unable to restore the entire backup of one of the databases. Then we simultaneously launched a new storage cluster, into which we transferred the missing data, collecting them from other subsystems, where they were stored for some minor needs. First, we figured out where and what to look for, then changed the logic of the services, wrote scripts for data transfer, configured a new cluster, transferred data ... In the end, we completely recovered all the lost information.
2.4. Starting services
After the servers were restarted, we sent a set of scripts to them to start the OS and remove that hapless empty line from the configuration template. In parallel with writing and testing scripts, we manually restored servers around the clock. Not only the Odnoklassniki team was involved in this work, but also employees from other projects.
If, after the server restart, the hardware and file system did not fail, the scripts brought the service to a working state. If, due to dependencies on other subsystems, the service could not be started, it was necessary to edit the code. If this did not help, they understood and looked for a solution. Fortunately, a significant amount of data and services was already distributed between data centers and we needed to revive only the part necessary for recovery.
Monitoring and statistics systems are widely used in Internet projects, and such a large project as Odnoklassniki is no exception. Constantly monitored a huge number of parameters relating to both the correct operation of equipment and applications, and user behavior. During the elimination of the accident due to too many failures, information was collected slowly or not at all - attempts to connect monitors to many servers ended in timeouts. As a result, the monitors marked the servers that had been fixed long ago as failed, and vice versa - they considered the non-working servers to be working, as they were not yet reached the turn in question by the monitor. Often, monitoring systems failed at all. We could not get current data on the status of servers and find out if the applications are working correctly. Therefore, we had to do manual checks, which took extra time

Questions for self-test:
Do you use the distribution of data and services across different data centers? How much does this increase resistance to failure?
2.5. Completion of recovery
From the very beginning, we drew up a recovery plan, outlining the sequence of work. All procedures performed during the recovery process have been documented. The work of the people was coordinated, and when someone completed the next task, he was given the following. The assignment of tasks was carried out on the basis of the current situation and the operational plan. That is, the process was manageable, but only in part. I had to improvise a lot.
Restoration of primary operability, when the portal began to at least load and earned some of the functionality, took about a day.
The accident occurred on Thursday evening, and on Sunday morning we fully restored the work of the portal.
3. Learning lessons
3.1. Incident management
In Odnoklassniki, as in many other projects, incident management is applied. That is, all emergency situations are recorded and divided into categories:
- bug in our code
- configuration errors
- hardware failure
- employee erroneous actions
- failures on the side of our partners: payment aggregators, telecom operators, data centers, etc.
To eliminate the causes and consequences of the incident immediately assigned a performer.
Separately understand incidents that have serious consequences for users or potentially capable of it. This allows you to detect suspicious trends (for example, an increase in the number of failures of a category), to prevent major accidents, and also to greatly reduce the negative effect of failures.
Serious accidents have happened before. For example, in 2012 Odnoklassniki did not work for several hours due to the unavailability of one of the data centers due to a fire in the communication collector. After that, we set ourselves a global goal: our portal must be fully operational in case of loss of any of the data centers. We will reach this goal soon.
Questions for self-test:
Will your service be available:
- at failure of several servers?
- one or more subsystems?
- one of the data centers?
- How do you work with incidents?
But we were not ready for an accident of this scale. Nobody thought that all servers would become inaccessible and that such complicating circumstances would arise.
After the accident, we analyzed the sequence and progress of all restoration work:
- how long did it take
- what difficulties arose and why
- how they were solved
- why some decisions were made.
3.2. Changes in infrastructure, monitoring and management
According to the results of the analysis, a plan of necessary works was drawn up, in which various accidents are foreseen. To date, we have done the following:
- Completed the process of replacing unreliable storage systems (hereinafter referred to as storage systems) based on Berkeley DB . Since Odnoklassniki was founded, similar systems have been used to store large binary data and key value for various small business entities. This storage system was characterized by many shortcomings. For example, due to the specifics of the Single Master replication architecture, changes were periodically lost when the master failed, and sometimes when its replica failed. Also during the accident, it turned out that the recovery procedure from backups is very slow and unreliable. At the moment, the transition to systems based on Cassandra and Voldemort has been completed .
- Implemented an autonomous centralized server management system via IPMI . Now it’s enough to manage the servers so that they have power and network access to IPMI.
- Increased reliability and accuracy of monitoring systems. After the accident, we disassembled the work of all monitoring systems and did the following:
- completely rewritten the scripts to improve the stability of the work,
- reduced timeouts checks,
- introduced dependencies of application checks on the availability of servers over the network,
- updated software,
- changed active checks to passive ones and made many other changes. - Implemented protection against configuration changes on all servers. Now changes can be automatically applied only in one of the data centers and only during working hours.
Questions for self-test:
- How long have you been restoring data from a backup and how long did it take?
- Do you have the ability to remotely manage all servers?
- Is your monitoring system able to function correctly in the event of a full-scale accident?
- Is it physically possible to disrupt all servers in a short period of time by a single configuration change?
3.3. Changes on the portal
- Changed the procedure for making changes to the configuration on production. Entered forced verification of all changes by another employee. Testing any changes now passes through more environments:
- unstable (virtuals where you can “hack it out with an ax”),
- testing (with a full set of service systems, but not in production),
- stable (a dedicated group of hundreds of production servers of various types)
- and then in production, separately for data centers. - Determined the mandatory types of tests that are exposed to new service systems or modified service components (load, integration, fault tolerance, etc.), and supplemented them with examples.
- Redid service systems and network, taking into account additional emergency scenarios.
- Reduced dependence on infrastructure, added duplication, organized emergency access.
- Fixed dependencies that prevented the launch of applications and implemented testing of service failures. Now, on an ongoing basis, the functionality is checked when the subsystems completely fail. Also introduced "knife switches" that allow forcibly disable services.
Questions for self-test:
- How do you build a procedure for checking and testing changes made to production?
- How prone are your service and work tools infrastructure failures?
3.4. Accident Plan
One of the main problems for us was the lack of an action plan for such a large-scale accident. We developed it based on the results of the analysis of the restoration work. What is included in the plan:
- Checklist for the monitoring team with a list of responsible persons to be contacted and their contact details.
- Distribution of roles and responsibilities:
- what employees are involved in the elimination of the accident,
- what areas of responsibility should be distributed and by whom,
- who is the coordinator
- who is responsible for preparing the operational plan,
- who is responsible for periodic general information on the status of the fix,
- who, why and how can take on roles - this applies both to the repair itself, and subsequent analysis and possible actions after the accident.
- Checklist on the restoration of services : what to repair, in what order and how. Here are defined lists of priority services and the order of their restoration; lists of tools and systems that need to be monitored; links to instructions and information on what to do if something went wrong.
- Separate instructions for the person performing the role of coordinator. The manager of the accident elimination process should assess the scale, plan, provide the necessary information to the higher management, delegate, control, attract additional resources, record the necessary information and organize the analysis of the incident.
- Separate instructions for the case of falling data center. It defines a list of specific actions in case of the fall of one of the data centers.
- Rules of interaction with partners. Here, the ways of communication and the distribution of roles on our part when interacting with partners, as well as the levels of interaction with them:
- Informational - in which case we limit ourselves to informing only.
- Resource mobilization - in which case we massively mobilize resources on the side of a partner or on our side.
- Working group - in which case we create a working group with the participation of partners and who participates in it.
“Emergency” action plans should be tested regularly. The importance of this procedure is difficult to overestimate. If you do not, then after a few months your plan will become obsolete. And when a problem arises one day, your actions either do not improve the situation or aggravate. Therefore, we review our action plans every quarter, and sometimes more often, if we need to train new employees. Each time it turns out that it is necessary to make some adjustments due to server migration, starting and closing microservices, changes in the operating system and monitoring systems, etc.
Questions for self-test:
Do you have plans for accidents of varying degrees of severity? What will you do if all the data centers where your servers are located will be completely unavailable?
A couple of words in conclusion
Provide all the events and failures in such a complex system, which are Odnoklassniki, impossible. However, the project architecture, protection systems and all sorts of planned procedures allow us to retain most of the functionality and all the data in the event of a complete failure of any of our data centers. Moreover, in the near future, even the fall of the data center will not be able to affect the operation of our portal.
Source: https://habr.com/ru/post/268413/
All Articles