Network overlay technologies for data centers. Part 2

Greetings to all! In the previous post, we tried to understand the prerequisites for the emergence of new overlay technologies for the data center, as well as their general classification. In this part of the article I would like to dwell on TRILL, FabricPath and VXLAN in more detail.
TRILL and FabricPath
TRILL (Transparent Interconnection of Lots of Links) is a technology that works at the data link layer of the OSI model and ensures the transmission of packets within the data center by unique identifiers. By the word “packet” at the link level, we, of course, mean a frame.
')
Ports on devices on the network (usually switches) switch to TRILL mode. These devices will be called - switches TRILL. In this mode, packet switching between such ports inside the device is no longer the classic way (as we used to see on Ethernet), but in a new way - by identifiers.

In order for TRILL switches to know how to get to a switch on the TRILL network, they use a dynamic routing protocol. But instead of the usual prefixes (subnet addresses), the exchange is carried out by its own unique identifiers. This allows you to get a tree of shortest paths to each of the TRILL switches.
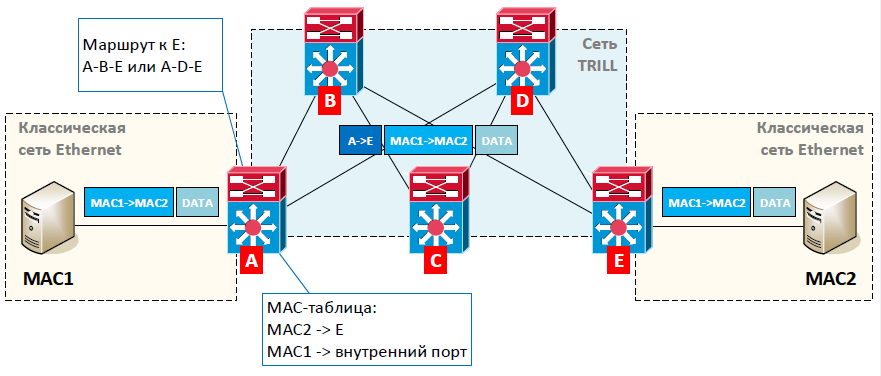
- the absence of any L2-loops, which means that we no longer need the STP protocols, all the channels are active;
- uniform utilization of channels for the same routes;
- reducing the load on the MAC tables of part of the switches, because inside the network we use the identifiers of the TRILL switches, and not the MAC addresses (only for those devices for which there are no hosts, in our case for switches B, C and D).
And since the recommended architecture of the TRILL network is the Clos architecture, we get all its advantages (as we discussed in the previous article).
It would seem a miracle, not a protocol. But, first, you have to pay for everything - equipment supporting TRILL is not cheap. Secondly, not all L2 problems this technology allows to solve. For example, the question of flooding still remains relevant.
Various network equipment manufacturers have their own TRILL implementations. In particular, Cisco has implemented the concept of TRILL in its FabricPath technology. It is worth noting that even though FabricPath is an implementation of the IETF TRILL standard, there are certain differences in their work. About some of them I will give the information below.
As I noted earlier, TRILL and FabricPath, in their work, use the dynamic routing protocol to build the shortest routes. For this task, the IS-IS protocol was chosen. This protocol, developed in the distant 80s, can be said to have found a second life. Why is-is? It works over the channel level.
Supports the transfer of any data within its messages. In other words, within IS-IS packets, we can transmit, for example, some names, tags, or any other information. Those. IS-IS is very easy to adapt for the operation of other network protocols. The calculation of the shortest route occurs according to the Dijkstra algorithm (as well as in the OSPF protocol).
I suggest a little more detail on the question of filling in the MAC table, which contains the correspondences of the MAC addresses of the hosts and the TRILL / FabricPath device identifiers.
For FabricPath technology, this process is as follows. After the network is “turned on”, this table is empty on all switches. Its filling on each device occurs as packets pass through it. The MAC addresses of local devices are memorized in the same way as on a regular Ethernet network (when they reach the switch port). For packets received from the FabricPath network, a “MAC address - device identifier” entry is added only if the switch already knows about the recipient of this packet (that is, it has a record of the recipient's MAC address). If there is no recipient data, the switch remembers nothing. As long as the necessary entry “MAC address - device identifier” is missing, the switch sends such packets to all devices on the FabricPath network.

For TRILL (IETF), several options for filling in the MAC table are described. The simplest is the operation of a conventional Ethernet network. As soon as the packet arrived, we enter the correspondence “MAC-address - port” for local hosts and “MAC-address - device identifier” for the packets received from the TRILL network side. There is also the option of data exchange on MAC-addresses through the specialized protocol End Station Address Distribution Information (ESADI). In this case, each TRILL switch informs everyone else about the MAC addresses of the local hosts.
As noted earlier, although TRILL (IETF) and FabricPath (Cisco) have common work patterns, there are significant differences. Different device identifiers, protocol headers, MAC address “learning” schemes, as well as the packet transfer process within the TRILL / FabricPath network.
Where to use these technologies? TRILL and FabricPath work on the link layer (L2). Therefore, in particular, FabricPath is recommended by the vendor for building a network inside the data center. FabricPath is supported on Cisco Nexus family switches (5500, 6000, 7000).
VXLAN
VXLAN (Virtual Extensible LAN) is another overlay technology, primarily designed for the virtualization world. A number of companies are working on its development (Cisco, Vmware, Citrix, etc.).
Looking at the name, immediately come the thought that this is something close to our usual VLAN'am. The way it is. VXLAN, in my opinion, can be compared to an advanced VLAN. In fact, it is his replacement. What is there advanced? VXLAN supports up to 16 million subnets, against 4096 for VLANs (this is about unique identifiers). Also VXLAN allows to provide connectivity of distributed L2-segments through the IP-network. How it is implemented and what it gives us, consider below.
VXLAN's work can be partially compared with the previously described TRILL / FabricPath technologies. The transmission of a packet when it is switched is divided into stages. After the packet has got on the device where the VXLAN technologies are launched (hereinafter referred to as the VXLAN device), the remote VXLAN device through which the recipient is connected is determined for this packet. The header is added to the packet, and it is sent first to the VXLAN device of interest to us, and then to the recipient host. This is where the similarity ends. VXLAN encapsulates the original Ethernet packet into a regular UDP datagram. So, when transferring packets between VXLAN devices, such a packet is processed according to standard routing and switching rules. Those. the transport network (the network between VXLAN devices) can be fully routable and does not require support for VXLAN technology. So there are no loops (there is no need to use STP), you can use simultaneous transmission of packets along several paths, etc. We get all the benefits of full routing for packets that need to be switched.

A very important point on which we run VXLAN. Since VXLAN was originally designed for virtualization, this technology can be configured on a virtual switch (Host-based) inside the server. This is very cool, since in this case there are no requirements for the “glands” on the network at all. VXLAN can also be run on switching equipment (Network-based). And coupled with the fact that we can use VXLAN both inside the data center and between them, we get the perfect technology. But, as usual, the devil is in the details.

In general, the idea of VXLAN is quite simple. Received a packet, looked at the table of MAC addresses, found where to send, encapsulated in UDP and transmitted. I am sure that many have already had a question, but how is the MAC address table filled in? How does each VXLAN device know where the MAC address is?
And here are the nuances of the VXLAN. The very first implementation is the use of multicast packets. We remember that multicast gives us the opportunity to transmit a packet over the network to several recipients (united groups). VXLAN decided to use it. All VXLAN devices report to the network that they want to receive multicast traffic addressed to a specific multicast group (this is done via IGMP). Further, any VXLAN device to send a packet to other VXLAN devices, specifies the address of multicast groups as the destination address. And then everything is simple. While the MAC address table is empty, packets are simply transmitted at once to all VXLAN devices (using multicast). Having received such a packet, the VXLAN device enters into the table the corresponding MAC addresses of the sender and the IP address of the VXLAN device that transmitted the packet. Thus, after a while, all VXLAN devices will know where this or that MAC address is located. Accordingly, packets addressed to a known MAC address are transmitted in the form of unicast traffic.
Ah bad luck, because the whole network must support multicast. Moreover, if the VXLAN devices are on different subnets, you need to support multicast traffic routing. Here we come to the first catch. If we can do this for the internal network, it is difficult for the Internet. What could be the way out? Abandon multicast and use only unicast traffic.
If only unicast traffic is used, how can we fill in the MAC address table? The most logical option is to have some kind of database where all VXLAN devices (their IP addresses) will be stored. In this case, VXLAN devices can work on the same principle as in multicast mode. Only when you need to send a packet to all devices (for example, when there is no data on the MAC address) you will have to look into the table and send not one multicast packet, but several unicast packets (for each VXLAN device). That was done.
The main disadvantage of this implementation is the increased load on the VXLAN device in the case of sending broadcast, multicast and unknown unicast traffic (that is, when there is no exact recipient of traffic, or we still do not know where the MAC address is located). If we have, for example, 20 VXLAN devices in our network, then we will need to generate 20 identical VXLAN packages from one such packet and send them over the network. Therefore, the unicast mode was supplemented with an add-on, in which additional information about MAC addresses is added to the database. What does this give us? Now, the VXLAN device can look into such a database and immediately determine where the desired MAC address is located. It is no longer necessary to send traffic to all VXLAN devices at once.
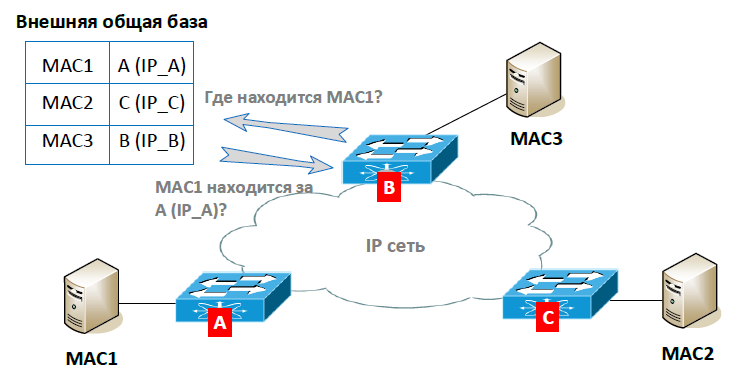
The first implementation of VXLAN in unicast mode is available on the Cisco Nexus 1000V Virtual Switch. In this case, the Virtual Supervisor Module (VSM) collects information from all the Cisco virtual switches on the MAC addresses behind them. Thus, a base of correspondences of VXLAN devices (virtual switches) and MAC addresses is formed.
The second variant of VXLAN implementation in unicast mode is already available on hardware. In this mode, VXLAN devices exchange data about MAC addresses through a specialized protocol. Those. in this case, the base of correspondences will be stored separately on each VXLAN device. Multiprotocol Ethernet Gateway Protocol Ethernet Private Network (MP-BGP EVPN) was chosen as such a protocol. This is an extension of the BGP protocol that allows us to send the data we need in BGP messages: the MAC address of the host, its IP address and the VXLAN IP address of the device through which this host is available.
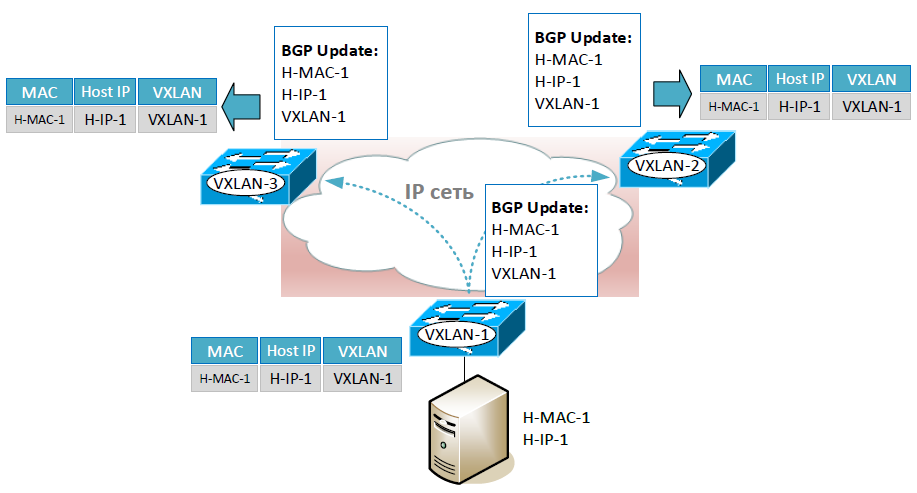
I think you have already noticed that the host’s IP address is also transmitted along with the MAC address. As we noted earlier, this can significantly reduce unknown unicast traffic. The operation of the ARP protocol is also optimized (in order not to once again drive ARP traffic between VXLAN devices).
The last option (it’s really a bit degenerate) is a static indication of the address of the remote VXLAN device. And you can specify just one such device, i.e. make a point-to-point connection.
Support for VXLAN modes on Cisco hardware:
| Multicast | Unicast | |
|---|---|---|
| Nexus 1000V | Yes | Yes, the base MAC addresses on VSM |
| Nexus 7000, 9000, ASR 9000 | Yes | Yes, MP-BGP EVPN |
| ASA | Yes | Yes, the address of one VXLAN device is statically set |
| ASR 1000 | Yes | Yes, the address of one VXLAN device is statically set |
| CSR | Yes | Not |
| ISR 4000 | Yes | n / a |
As a small summary I would like to once again highlight the main points. TRILL and FabricPath work on the data link layer of the OSI model. All equipment in the network begins to process packets in a new way. Routing on the link layer is used. These technologies are recommended for building a network within a data center. VXLAN technology encapsulates Ethernet packets in UDP datagrams. Thus, this technology allows you to leave the transport network unchanged, including the use of the Internet. Virtual tunnels are built between VXLAN devices, in which packets run between distributed segments of one L2 network. VXLAN can be used both inside and between data centers.
This concludes the general consideration of TRILL, FabricPath and VXLAN. I would like to note that for ease of understanding, some of the points were omitted. In particular, in the MAC address tables, I deliberately lowered the MAC address / port port of the switch to a particular VLAN (VXLAN). Also I didn’t consider the interface between a regular network and a VXLAN network, issues of a fail-safe connection to the FabricPath network (vPC + and HSRP), etc. All this is necessary, as it seems to me, for a deeper immersion. And here we are still swimming at shallow depths. I emphasize, we are swimming in the depths , not on the surface.
In the next article, we will look at OTV and LISP technologies, as well as summarize the results.
Source: https://habr.com/ru/post/268247/
All Articles