Recommended system on .Net or first steps with MyMediaLite
")
I once went to the courses on BigData, on the recommendation of friends and I was lucky enough to participate in the competition. I will not talk about learning on the course, but I will tell you about the MyMediaLite library on .Net and how I used it.
Foreplay
On the nose was the final laboratory work. Throughout the course, I didn’t really compete in laboratory work, towards the end, life forced me to fight - in order to receive a certificate, I had to earn points. The last lecture was not very informative, rather a review, and I decided not to waste time, in parallel to do the last lab. Unfortunately, I did not have a cluster with Apache Spark installed at that time. On the educational cluster, as everyone rushed to do the laboratory, there were few chances and resources for success. My choice fell on MyMediaLite on C # .Net. Fortunately, there was a working server, not very loaded and dedicated for experiments, quite good, with two percents and 16 Gb of RAM.
Conditions of the problem
We were provided with the following data:
')
- The train.csv movie rating table (userId, movieId, rating, timestamp). A good half of the sample is given to the mercy (randomly sorted by movieId and userId), the second half remains with the course supervisor, to assess the quality of the recommender system
- table tags.csv (userId, movieId, tag, timestamp fields) with movie tags
- the movies.csv table (movieId, title, genres fields) with the movie title and its genre
- table links.csv (movieId, imdbId, tmdbId fields) matching movie identifier in imdb and themoviedb databases (there you can find additional movie features)
- the test.csv table (userId, movieId and rating fields) is actually the second half of the sample, but without ratings.
It is necessary to predict movie ratings in the test.csv table, generate a result file that contains data in the format: userId, movieId, rating and fill in the checker. The quality of the recommendations will be evaluated by RMSE and it should be no worse (means no more) 0.9 for the test. Next will be a struggle for the best result.
All data files are available here https://goo.gl/iVEbfA
Excellent article about how to count RMSE
My decision
The latest version of the code is available in Gihab.
Well, who goes into battle without intelligence? “Intelligence data” was received during the breaks in lectures and it turned out that we were slipped :) the notorious movielens 1m , with the addition of some other data set. Those who have already coped with the laby praised SVD ++.
As a rule, any machine learning consists of three parts:
- Representation
- Evaluation
- Optimization
I also went down this path and divided the sample into two parts, 70% and 30%, respectively. The second part of the sample is needed to verify the accuracy of the model. The very first version of the code was written, according to the results of which the laboratory work was successfully submitted. The result is 0.880360573502 on the BiasedMatrixFactorization model. I dismounted all the tinsel with tags and links immediately, they could be used as additional features to get the best result. I did not spend time on it and it was the right decision, IMHO. Users who were not in the training set were also ignored boldly, and ratings were put down by unknown values, which were returned by the BiasedMatrixFactorization class. This was a serious mistake that cost me first place. On the SVD ++ model, the result was 0.872325203952 . Checker showed the first place and I, with peace of mind, rehearsing the speech of the winner went to sleep. But as they say, chickens count in the fall.
Results of the competition
I will be brief, the winning place has passed from hand to hand several times. As a result, at the time of the deadline, my friend got the first place, and I - the second. We, programmers - stubborn people, managed to squeeze out the best result on BiasedMatrixFactorization . Alas, after the deadline.
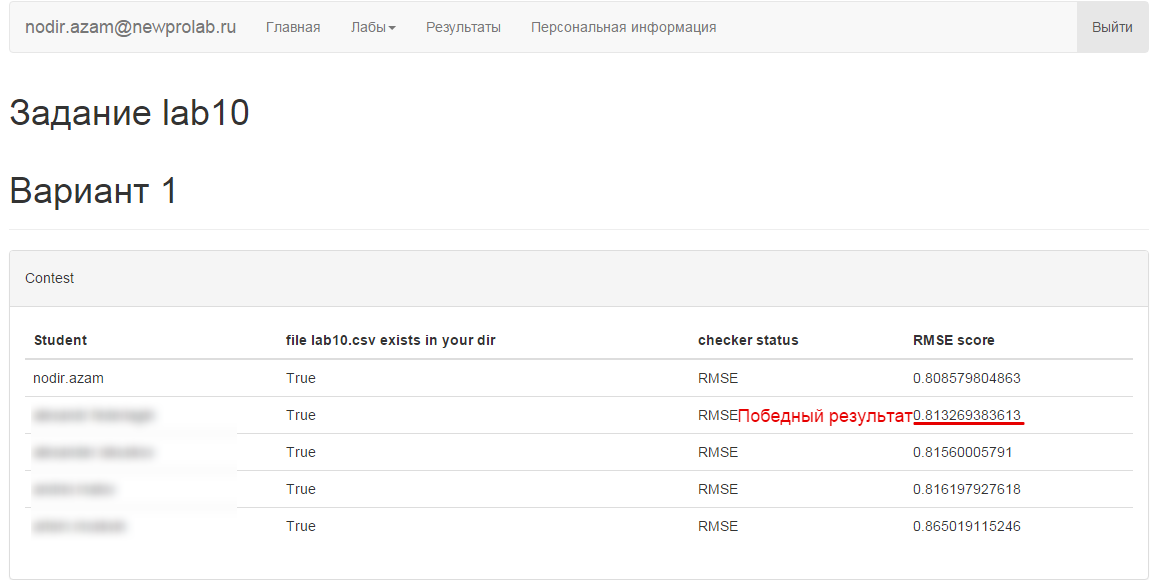
Alternative solution
My friend wenk , who received the first place, kindly agreed to provide his code. His solution was implemented on a cluster with Apache Spark, using ALS from scikit-learn.
# coding: utf-8 # In[1]: import os import sys os.environ["PYSPARK_SUBMIT_ARGS"]=' --driver-memory 5g --packages com.databricks:spark-csv_2.10:1.1.0 pyspark-shell' sys.path.insert(0, os.environ.get('SPARK_HOME', None) + "/python") import py4j from pyspark import SparkContext,SparkConf,SQLContext conf = (SparkConf().setMaster("spark://bd-m:7077") .setAppName("lab09") .set("spark.executor.memory", "50g") .set("spark.driver.maxResultSize","5g") .set("spark.driver.memory","2g") .set("spark.cores.max", "26")) sc = SparkContext(conf=conf) sqlCtx = SQLContext(sc) # In[2]: ratings_src=sc.textFile('/lab10/train.csv',26) ratings=ratings_src.map(lambda r: r.split(",")).filter(lambda x: x[0]!='userId').map(lambda x: (int(x[0]),int(x[1]),float(x[2]))) ratings.take(5) # In[3]: test_src=sc.textFile('/lab10/test.csv',26) test=test_src.map(lambda r: r.split(",")).filter(lambda x: x[0]!='userId').map(lambda x: (int(x[0]),int(x[1]))) test.take(5) # In[4]: from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel from pyspark.mllib.recommendation import Rating rat = ratings.map(lambda r: Rating(int(r[0]),int(r[1]),float(r[2]))) rat.cache() rat.first() # In[14]: training,validation,testing = rat.randomSplit([0.6,0.2,0.2]) # In[15]: print training.count() print validation.count() print testing.count() # In[16]: training.cache() validation.cache() # In[17]: import math def evaluate_model(model, dataset): testdata = dataset.map(lambda x: (x[0],x[1])) predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2])) ratesAndPreds = dataset.map(lambda r: ((r[0], r[1]), r[2])).join(predictions) MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).reduce(lambda x, y: x + y) / ratesAndPreds.count() RMSE = math.sqrt(MSE) return {'MSE':MSE, 'RMSE':RMSE} # In[12]: rank=20 numIterations=30 # In[28]: model = ALS.train(training, rank, numIterations) # In[ ]: numIterations=30 lambda_=0.085 ps = [] for rank in range(25,500,25): model = ALS.train(training, rank, numIterations,lambda_) metrics = evaluate_model(model, validation) print("Rank = " + str(rank) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE'])) ps.append((rank,metrics['RMSE'])) # In[10]: ls = [] rank=2 numIterations = 30 for lambda_ in [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]: model = ALS.train(training, rank, numIterations, lambda_) metrics = evaluate_model(model, validation) print("Lambda = " + str(lambda_) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE'])) ls.append((lambda_,metrics['RMSE'])) # In[23]: ls = [] rank=250 numIterations = 30 for lambda_ in [0.085]: model = ALS.train(training, rank, numIterations, lambda_) metrics = evaluate_model(model, validation) print("Lambda = " + str(lambda_) + " MSE = " + str(metrics['MSE']) + " RMSE = " + str(metrics['RMSE'])) ls.append((lambda_,metrics['RMSE'])) #Lambda = 0.1 MSE = 0.751080178965 RMSE = 0.866648821014 #Lambda = 0.075 MSE = 0.750219897276 RMSE = 0.866152352232 #Lambda = 0.07 MSE = 0.750033337876 RMSE = 0.866044651202 #Lambda = 0.08 MSE = 0.749335888762 RMSE = 0.865641894066 #Lambda = 0.09 MSE = 0.749929174577 RMSE = 0.865984511742 #rank 200 Lambda = 0.085 MSE = 0.709501168484 RMSE = 0.842318923261 get_ipython().run_cell_magic(u'time', u'', u'rank=400\nnumIterations=30\nlambda_=0.085\nmodel = ALS.train(rat, rank, numIterations,lambda_)\npredictions = model.predictAll(test).map(lambda r: (r[0], r[1], r[2]))') # In[7]: te=test.collect() base=sorted(te,key=lambda x: x[0]*1000000+x[1]) # In[8]: pred=predictions.collect() # In[9]: t_=predictions.map(lambda x: (x[0], {x[1]:x[2]})).reduceByKey(lambda a,b: dict(a.items()+b.items())).collect() t={} for i in t_: t[i[0]]=i[1] s="userId,movieId,rating\r\n" for i in base: if t.has_key(i[0]): u=t[i[0]] if u.has_key(i[1]): s+=str(i[0])+","+str(i[1])+","+str(u[i[1]])+"\r\n" else: s+=str(i[0])+","+str(i[1])+",3.67671059005\r\n" else: s+=str(i[0])+","+str(i[1])+",3.67671059005\r\n" # In[12]: text_file = open("lab10.csv", "w") text_file.write(s) text_file.close() My experience
I noted some facts for myself:
- You should always carefully study the data, not “fill in the gaps”, but try to fill them with similar values. For example, the average rating of the sample instead of empty values, significantly improved the result
- Rounding the result (rating) reduced prediction accuracy rather than a long tail.
- The best option was calculated for the entire sample, without validation. The DoCrossValidation method was used .
- Ideally, it was necessary to plot the parameters (number of iterations, etc.) and the result of RMSE. Move to victory is not blind, but sighted
- Apache Spark gives a gain in computation time, since it runs on several machines. If time is critical - use spark
- MyMediaLite is quite a decent library for small, non-time-critical tasks. It can justify itself when it is unprofitable to raise a cluster with a spark
Oh, if I knew all this before, I would have won ... I am grateful for your opinion and advice from friends, do not kick much ...
Source: https://habr.com/ru/post/268073/
All Articles