Transition from SQL to NoSQL: the experience of the SMEV 2.0 project
In recent years, NoSQL and BigData have become very popular in the IT industry, and thousands of projects have been successfully implemented based on NoSQL. Often at different conferences and forums, students ask how to upgrade or move legacy systems to NoSQL. Fortunately, we had the experience of switching from SQL to NoSQL in a large project SMEV 2.0, which I will discuss under the cat.

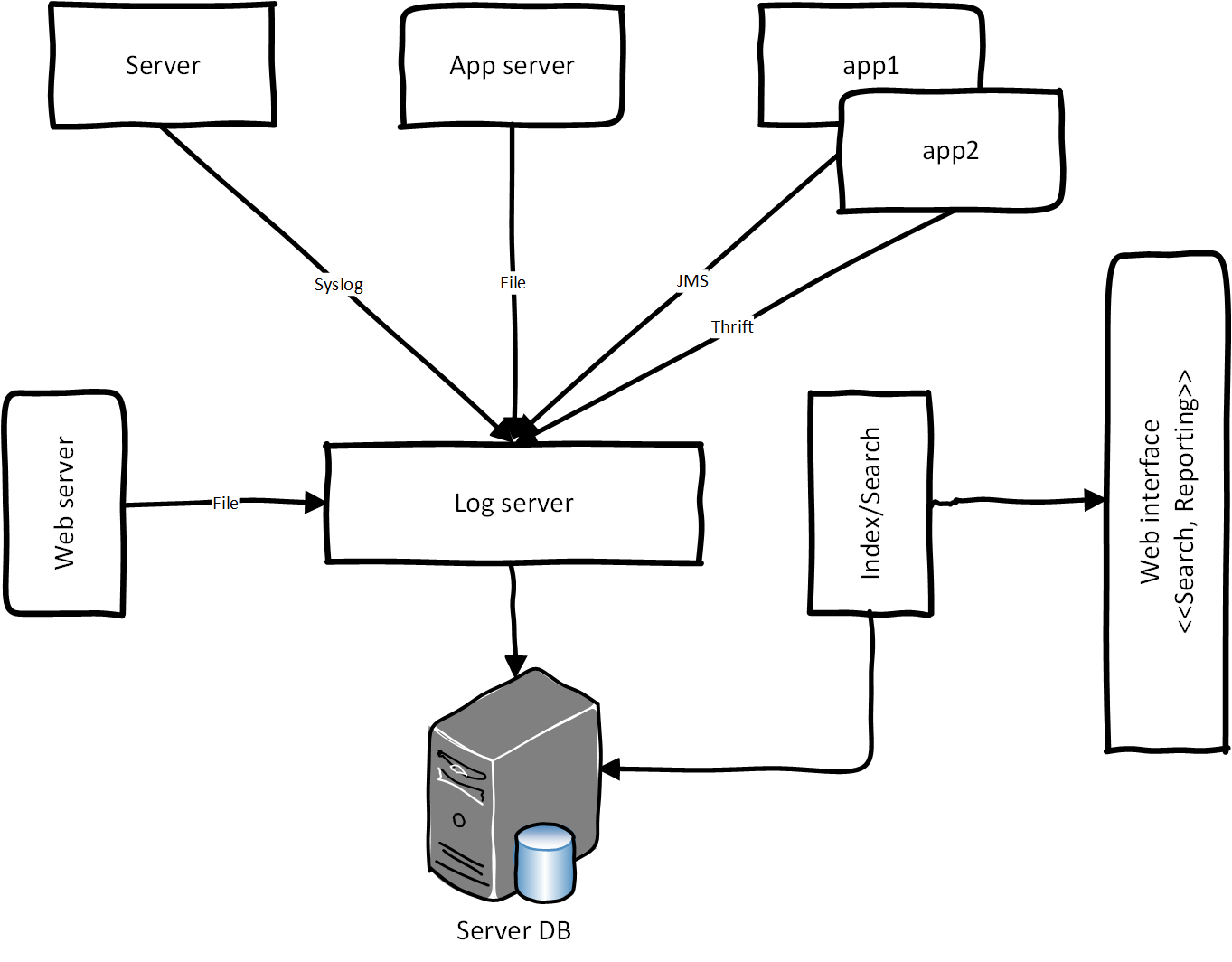
In 2011, in one of the flagship projects of the Electronic Government of the Russian Federation, we were faced with the problem of designing a centralized logging (logging) system. CSL is a logging for processing application and system logs (events) in a single repository. Application logs from the server application (citizens accessing the service through the public services portal), balancing log, load and integration bus log the logs through the server log, enter the storage, then the data is indexed and aggregated for reporting. For reporting, we used the BI system. Below is the conceptual architecture of CSL:
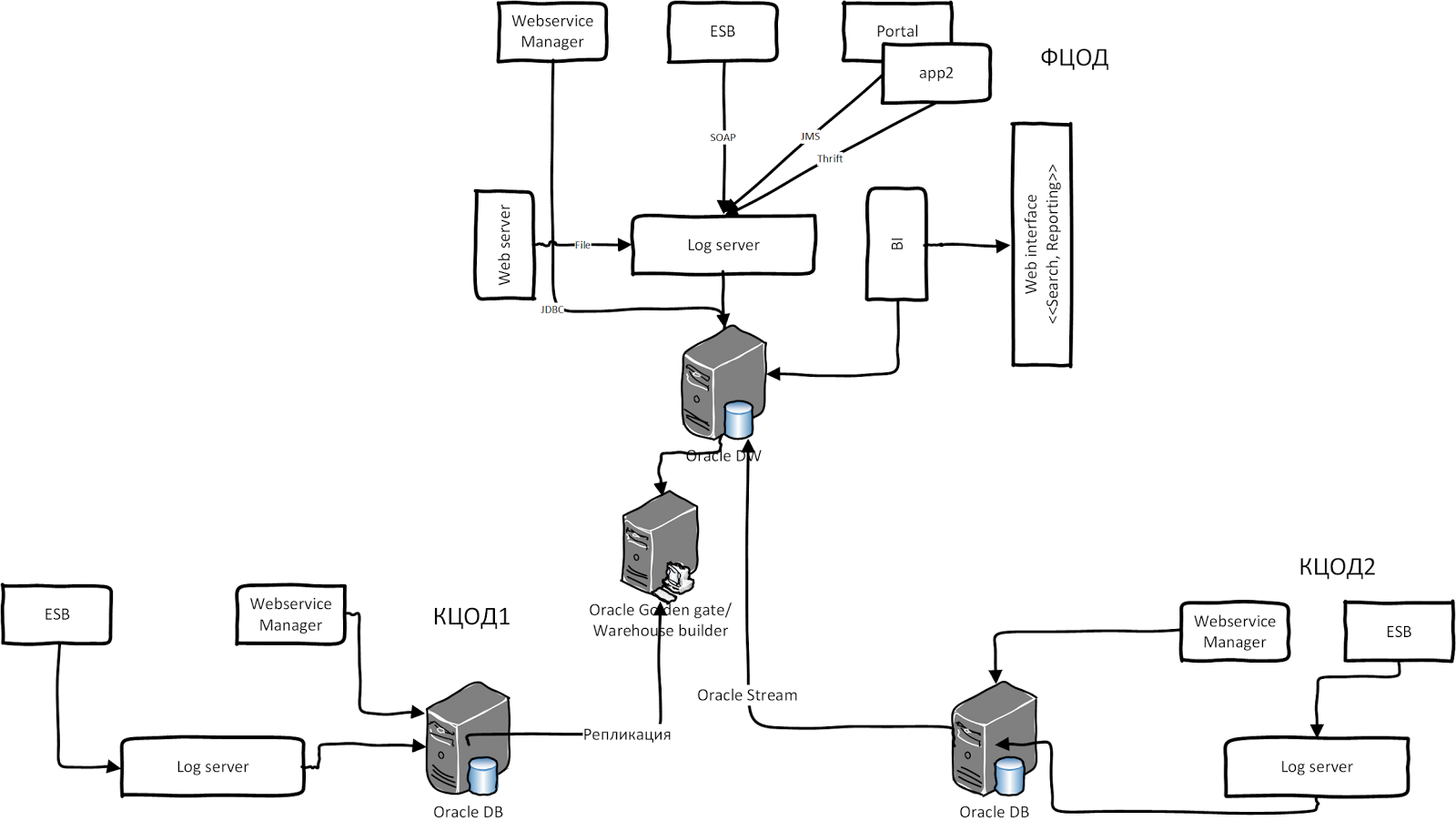
The situation is complicated when different legacy heterogeneous systems with their storage and logging system are involved. One of such systems is SMEV (System of Interdepartmental Electronic Interaction, Architecture 2011). It contains two types of Oracle integration buses: WSM and Oracle OSB. Oracle WSM always logs messages as BLOBs in its own database schema. OSB also logs messages in its schema, while other software has its own approach to logging. Now imagine that this whole system is installed in several regions of the Russian Federation. Data is replicated from other data centers to a federal data center for processing and aggregation. After consolidation and aggregation, the resulting data is reported through the BI system. The illustration below shows the high-level architecture of SMEV 2.0:
')
This system had a number of drawbacks:
All these reasons led us to revise our architecture and switch to NoSQL. After a bit of discussion and benchmarking, we decided to use the Cassandra repository. Its advantages were obvious:
As a result, we have the following conceptual architecture based on Cassandra:
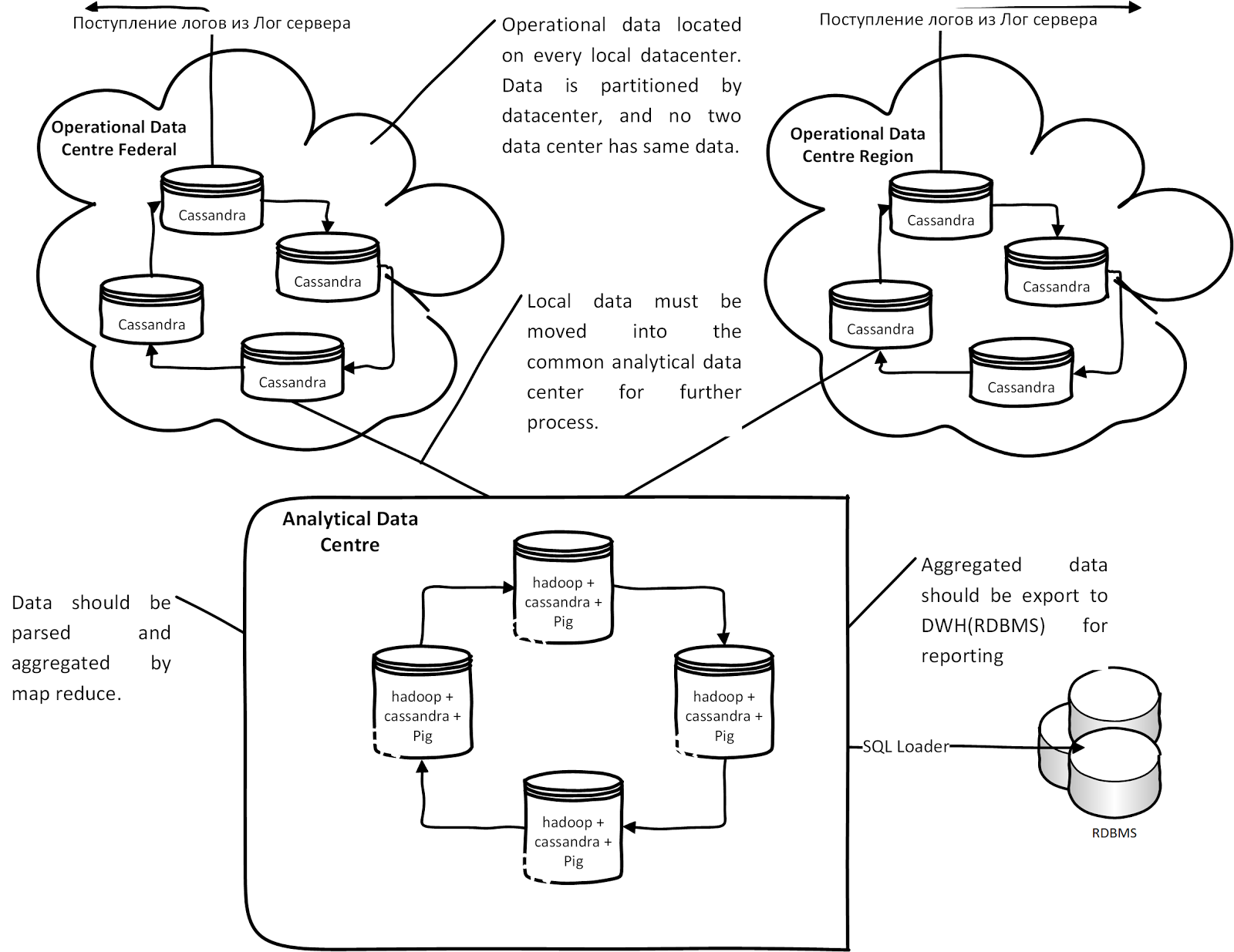
Each region or data center log server writes protocols in its Cassandra cluster node. Data is automatically replicated to the analysis center for analysis. After analyzing and processing data in Hadoop Map Reduce, the data is uploaded through the SQL loader for reporting to Oracle. If, for some reason, the communication channel between the analytical centers and the DCS is missing, data is accumulated (Hinted hands of) in each operational node of Cassandra and when a connection appears, the data from the DCS are sent to the analytical nodes.
The data model is the Column Family, consisting of columns and values. All columns are static, because Pig did not know how to work with dynamic columns: thus, we have a payload of soap payload in a column. Through Hadoop Map Reduce, the message is parsed, and the result is stored in the Cassandra table for building the aggregate. After that, Reduce is run in the resulting metadata to build different aggregates. Aggregated data is exported via Oracle SQL Loader from Hadoop HDFS to Oracle DB.
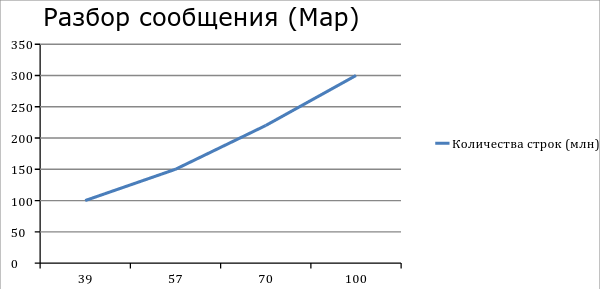
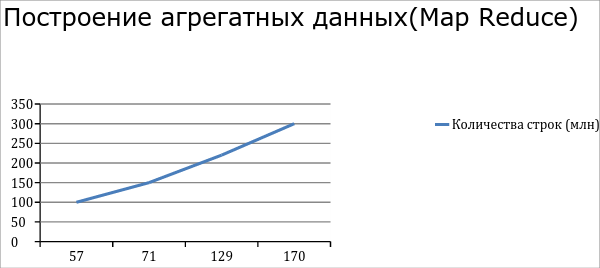
After tuning (fine tuning) Hadoop we got such performance. Analysis of 300 million lines from Cassandra takes about 100 minutes. Building an aggregate of 300 million records takes an average of 170 minutes. The Pig script of the data aggregate in our case contains 3 large join operators, so 3 more temporary maps appear.
During the transition, it is very important to understand the data model and the reason for the transition. Relational databases are still leading among data warehouses; using the relational model, you can implement almost all domain models: for example, we transferred only non-transactional data (application and system logs). Cassandra helped us solve the problem of replication between data centers, and Hadoop solved the issue of data processing performance.
References:
In 2011, in one of the flagship projects of the Electronic Government of the Russian Federation, we were faced with the problem of designing a centralized logging (logging) system. CSL is a logging for processing application and system logs (events) in a single repository. Application logs from the server application (citizens accessing the service through the public services portal), balancing log, load and integration bus log the logs through the server log, enter the storage, then the data is indexed and aggregated for reporting. For reporting, we used the BI system. Below is the conceptual architecture of CSL:
The situation is complicated when different legacy heterogeneous systems with their storage and logging system are involved. One of such systems is SMEV (System of Interdepartmental Electronic Interaction, Architecture 2011). It contains two types of Oracle integration buses: WSM and Oracle OSB. Oracle WSM always logs messages as BLOBs in its own database schema. OSB also logs messages in its schema, while other software has its own approach to logging. Now imagine that this whole system is installed in several regions of the Russian Federation. Data is replicated from other data centers to a federal data center for processing and aggregation. After consolidation and aggregation, the resulting data is reported through the BI system. The illustration below shows the high-level architecture of SMEV 2.0:
')
This system had a number of drawbacks:
- Poor scalability : the first problem was the dynamics of growth of registrations and the use of services in all authorities. At the beginning of 2011, only 4,000 services were registered, and already in the second quarter of 2013, more than 10,000. Approximately 1,000 soap-services were registered on the integration bus in each data center, and about 2,000 services were registered in the federal data center. Thus, the need for service has increased by almost 6 times: at the federal level, the number of logs reached 21 million per day, and throughout Russia - about 41 million records, during peak hours RPS (Request per second) - 1375. Of course, compared With a high load system, these are tiny numbers. The whole process of data processing and reporting is implemented on the basis of PL / SQL, i.e. message handling and data consolidation were implemented in PL / SQL, which was not productive enough. After a big update, we could parse 450 thousand messages in 110 minutes, when we received several million messages a day at the entrance.
- The second strongly influenced factor is data replication between data centers, which was carried out through various heterogeneous tools: WHB, Oracle Goldengate, Oracle Stream. If for some reason there was no communication channel, they had to be restarted to avoid errors.
- Oracle RAC scaling: also with increasing growth in demand for services, it was necessary to scale the database, which was very expensive and difficult.
- Costly licenses for Oracle software.
All these reasons led us to revise our architecture and switch to NoSQL. After a bit of discussion and benchmarking, we decided to use the Cassandra repository. Its advantages were obvious:
- Automatic data replication between data centers;
- Sharding data out of the box;
- Linear scaling of the Cassandra cluster;
- No single point of failure;
- Google Big Table based data model;
- Open source software.
As a result, we have the following conceptual architecture based on Cassandra:
Each region or data center log server writes protocols in its Cassandra cluster node. Data is automatically replicated to the analysis center for analysis. After analyzing and processing data in Hadoop Map Reduce, the data is uploaded through the SQL loader for reporting to Oracle. If, for some reason, the communication channel between the analytical centers and the DCS is missing, data is accumulated (Hinted hands of) in each operational node of Cassandra and when a connection appears, the data from the DCS are sent to the analytical nodes.
Software stack
- Cassandra 1.1.5
- Hadoop 1.0.3
- Apache pig 0.1.11
- AzKaban
Data model and their processing
The data model is the Column Family, consisting of columns and values. All columns are static, because Pig did not know how to work with dynamic columns: thus, we have a payload of soap payload in a column. Through Hadoop Map Reduce, the message is parsed, and the result is stored in the Cassandra table for building the aggregate. After that, Reduce is run in the resulting metadata to build different aggregates. Aggregated data is exported via Oracle SQL Loader from Hadoop HDFS to Oracle DB.
Performance
After tuning (fine tuning) Hadoop we got such performance. Analysis of 300 million lines from Cassandra takes about 100 minutes. Building an aggregate of 300 million records takes an average of 170 minutes. The Pig script of the data aggregate in our case contains 3 large join operators, so 3 more temporary maps appear.
Results
During the transition, it is very important to understand the data model and the reason for the transition. Relational databases are still leading among data warehouses; using the relational model, you can implement almost all domain models: for example, we transferred only non-transactional data (application and system logs). Cassandra helped us solve the problem of replication between data centers, and Hadoop solved the issue of data processing performance.
References:
Source: https://habr.com/ru/post/267979/
All Articles