GO Download Manager Development
Multi-threaded download manager for GO.
http://loafter.imtqy.com/godownloader/
https://github.com/Loafter/godownloader
Long ago, in the year 1998, I used a modem at my father’s work to access the Internet. He turned it on in the evening after work and I could enjoy the Internet at a speed of 31.2 kbit / s. At that time there were no hysterical bloggers, the pages were not weighed in megabytes, and in news sites they spoke only the truth. Naturally, the main interest was resources. Pictures, programs, any additions to games, like machines. As I remember now, downloading via IE was a real hell. Download file weighing more than 500 kb was simply impossible, the ancient donkey was much more stubborn.
At that time there were a lot of download managers like Getright, Go! Zilla, Download Accelerator and, of course, FlashGet. At that time, 90% of them were overloaded with advertising shit, the best was FlashGet. He could beat the downloadable file and worked smartly. As I remember, version 1.7 was the last. I used this version in those days.
15 years have passed and it took me to download a large amount of data via vpn from overseas.
And what has changed in 15 years?
Never mind. Still there are all the same managers with minimal changes. Even flashget left version 1.7 along with the newfangled 3.xx.
After the wxfast download failed to download a 50 gigabyte file, I decided to try to write my download manager, which would include many multithreaded tasks with the ability to control the degree of execution, stop at any time, and save the state of downloads between application launches. All this is a great challenge for the GO language.
')
Where to begin? The first thing we need is to be able to stop the download and receive information about the download at any time. GO has lightweight streams that can be used in our program. That is, at least one stream will be with us for downloading, another for managing the process (stopping, starting download, getting information on the progress). If there are no problems with the process of obtaining information about the downloaded data (we can get them by reference through the streams), then with the process of stopping the download, everything is a little more complicated, we cannot stop or kill another goroutine. But we can send her a signal to exit the stream. Actually so we will do. We implement a simple wrapper, which would allow to create arbitrary discrete work with the possibility of pause and obtain information about the status of work.
In order to wrap any structure, it is necessary that it support the following interface:
The wrapper itself:
After starting the stream, wgoroute (), in the loop, the function executes each iteration step by step by calling the DoWork () method. If an error occurs during the execution of the work, the function exits the loop and ends the stream. Also in the loop sampling from the channel.
If a Stopped message arrives, the algorithm exits the stream and sets the appropriate state.
We use the test tools built into the language to test the wrapper:
After we have created a working wrapper for tasks, we can proceed to the main function - download data via http. Probably the main problem of the http protocol is low speed when loading data into one stream. That is why, when the Internet was slow, there were so many download managers who knew how to split the downloaded file into fragments and download them into several http connections, thereby achieving a speed gain. Naturally, our download manager is not an exception, he should also be able to take a file in several streams. For normal operation of this scheme, it is necessary that the server supports resuming.
On the client side, a request must be formed that has a Range field in the header. The whole raw request looks like this:
My first implementation worked extremely slowly. The thing is that for each small portion of the data a request was prepared; if it was necessary to download a segment from 1 to 2 megabytes in blocks of 100 kb. this meant that 10 requests for each block were executed successively. I quickly realized that something was wrong.
In the wireshark program, I checked how the download is performed by another program - download master. The correct scheme of work was different. If we need to download 10 segments, we first prepared 10 http-requests for each segment, and the division into blocks was implemented by sequential reading from the body block within one http-response.
By wrapping the bootloader class in the DiscretWork interface from the previous part of the note, we can try to test its work:
For quite a long time, I have been doing all my services on go in the same way. As a rule, a web-interface through which the user interacts with the json-service through http-requests. Such a scheme of work gives a number of advantages over the traditional graphic interests listed below.
The interface is updated every 500 milliseconds. The pseudo-file localhost / progress.json is used as the data source for the download table. If you open it in the browser, it will open dynamically updated json-data. The jgrid is used as a table component. Due to its simplicity, the code takes up very little space.

There is another interesting feature of the service about which I would like to tell. This is how the web service ends. The fact is that when the http service starts, the program hangs on the start function and hangs until we finish the application. But Go has the ability to subscribe to signals sent by the operating system. Thus, we can intercept the moment when our process terminates, even if we do it through the kill command and perform some final actions. For example, this is the preservation of settings and the current progress of downloads.
There are many extensions to the standard go implementation of the http service that allow you to perform any actions after the service is completed. In my opinion, the method described above is the most simple and reliable, this method works even if we kill the service.
In principle, this is probably all that I wanted to convey to readers.
I don’t know how relevant the download manager is for others, but I’m already downloading the distributions and images of virtual machines with the help of my download manager.
But I check the checksums from time to time.
Download release for Mac, Windows, Linux: http://loafter.imtqy.com/godownloader/
Git: https://github.com/Loafter/godownloader
http://loafter.imtqy.com/godownloader/
https://github.com/Loafter/godownloader
Introduction
Long ago, in the year 1998, I used a modem at my father’s work to access the Internet. He turned it on in the evening after work and I could enjoy the Internet at a speed of 31.2 kbit / s. At that time there were no hysterical bloggers, the pages were not weighed in megabytes, and in news sites they spoke only the truth. Naturally, the main interest was resources. Pictures, programs, any additions to games, like machines. As I remember now, downloading via IE was a real hell. Download file weighing more than 500 kb was simply impossible, the ancient donkey was much more stubborn.
At that time there were a lot of download managers like Getright, Go! Zilla, Download Accelerator and, of course, FlashGet. At that time, 90% of them were overloaded with advertising shit, the best was FlashGet. He could beat the downloadable file and worked smartly. As I remember, version 1.7 was the last. I used this version in those days.
15 years have passed and it took me to download a large amount of data via vpn from overseas.
And what has changed in 15 years?
Never mind. Still there are all the same managers with minimal changes. Even flashget left version 1.7 along with the newfangled 3.xx.
After the wxfast download failed to download a 50 gigabyte file, I decided to try to write my download manager, which would include many multithreaded tasks with the ability to control the degree of execution, stop at any time, and save the state of downloads between application launches. All this is a great challenge for the GO language.
')
Wrapper
Where to begin? The first thing we need is to be able to stop the download and receive information about the download at any time. GO has lightweight streams that can be used in our program. That is, at least one stream will be with us for downloading, another for managing the process (stopping, starting download, getting information on the progress). If there are no problems with the process of obtaining information about the downloaded data (we can get them by reference through the streams), then with the process of stopping the download, everything is a little more complicated, we cannot stop or kill another goroutine. But we can send her a signal to exit the stream. Actually so we will do. We implement a simple wrapper, which would allow to create arbitrary discrete work with the possibility of pause and obtain information about the status of work.
In order to wrap any structure, it is necessary that it support the following interface:
type DiscretWork interface { DoWork() (bool, error) GetProgress() interface{} BeforeRun() error AfterStop() error } The wrapper itself:
func (mw *MonitoredWorker) wgoroute() { log.Println("info: work start", mw.GetId()) mw.wgrun.Add(1) defer func() { log.Print("info: release work guid ", mw.GetId()) mw.wgrun.Done() }() for { select { case newState := <-mw.chsig: if newState == Stopped { mw.state = newState log.Println("info: work stopped") return } default: { isdone, err := mw.Itw.DoWork() if err != nil { log.Println("error: guid", mw.guid, " work failed", err) mw.state = Failed return } if isdone { mw.state = Completed log.Println("info: work done") return } } } } } func (mw *MonitoredWorker) Start() error { mw.lc.Lock() defer mw.lc.Unlock() if mw.state == Completed { return errors.New("error: try run completed job") } if mw.state == Running { return errors.New("error: try run runing job") } if err := mw.Itw.BeforeRun(); err != nil { mw.state = Failed return err } mw.chsig = make(chan int, 1) mw.state = Running go mw.wgoroute() return nil } After starting the stream, wgoroute (), in the loop, the function executes each iteration step by step by calling the DoWork () method. If an error occurs during the execution of the work, the function exits the loop and ends the stream. Also in the loop sampling from the channel.
select { case newState := <-mw.chsig: if newState == Stopped { mw.state = newState log.Println("info: work stopped") return } If a Stopped message arrives, the algorithm exits the stream and sets the appropriate state.
We use the test tools built into the language to test the wrapper:
package dtest import ( "errors" "fmt" "godownloader/monitor" "log" "math/rand" "testing" "time" ) type TestWorkPool struct { From, id, To int32 } func (tw TestWorkPool) GetProgress() interface{} { return tw.From } func (tw *TestWorkPool) BeforeRun() error { log.Println("info: exec before run") return nil } func (tw *TestWorkPool) AfterStop() error { log.Println("info: after stop") return nil } func (tw *TestWorkPool) DoWork() (bool, error) { time.Sleep(time.Millisecond * 300) tw.From += 1 log.Print(tw.From) if tw.From == tw.To { fmt.Println("done") return true, nil } if tw.From > tw.To { return false, errors.New("tw.From > tw.To") } return false, nil } func TestWorkerPool(t *testing.T) { wp := monitor.WorkerPool{} for i := 0; i < 20; i++ { mw := &monitor.MonitoredWorker{Itw: &TestWorkPool{From: 0, To: 20, id: rand.Int31()}} wp.AppendWork(mw) } wp.StartAll() time.Sleep(time.Second) log.Println("------------------Work Started------------------") log.Println(wp.GetAllProgress()) log.Println("------------------Get All Progress--------------") time.Sleep(time.Second) wp.StopAll() log.Println("------------------Work Stop-------------------") time.Sleep(time.Second) wp.StartAll() time.Sleep(time.Second * 5) wp.StopAll() wp.StartAll() wp.StopAll() } Data loading
After we have created a working wrapper for tasks, we can proceed to the main function - download data via http. Probably the main problem of the http protocol is low speed when loading data into one stream. That is why, when the Internet was slow, there were so many download managers who knew how to split the downloaded file into fragments and download them into several http connections, thereby achieving a speed gain. Naturally, our download manager is not an exception, he should also be able to take a file in several streams. For normal operation of this scheme, it is necessary that the server supports resuming.
On the client side, a request must be formed that has a Range field in the header. The whole raw request looks like this:
GET /PinegrowLinux64.2.2.zip HTTP/1.1 Host: pinegrow.s3.amazonaws.com User-Agent: Go-http-client/1.1 Range: bytes=34010904-42513630 My first implementation worked extremely slowly. The thing is that for each small portion of the data a request was prepared; if it was necessary to download a segment from 1 to 2 megabytes in blocks of 100 kb. this meant that 10 requests for each block were executed successively. I quickly realized that something was wrong.
In the wireshark program, I checked how the download is performed by another program - download master. The correct scheme of work was different. If we need to download 10 segments, we first prepared 10 http-requests for each segment, and the division into blocks was implemented by sequential reading from the body block within one http-response.
func (pd *PartialDownloader) BeforeDownload() error { //create new req r, err := http.NewRequest("GET", pd.url, nil) if err != nil { return err } r.Header.Add("Range", "bytes="+strconv.FormatInt(pd.dp.Pos, 10)+"-"+strconv.FormatInt(pd.dp.To, 10)) f,_:=iotools.CreateSafeFile("test") r.Write(f) f.Close() resp, err := pd.client.Do(r) if err != nil { log.Printf("error: error download part file%v \n", err) return err } //check response if resp.StatusCode != 206 { log.Printf("error: file not found or moved status:", resp.StatusCode) return errors.New("error: file not found or moved") } pd.req = *resp return nil } …. func (pd *PartialDownloader) DownloadSergment() (bool, error) { //write flush data to disk buffer := make([]byte, FlushDiskSize, FlushDiskSize) count, err := pd.req.Body.Read(buffer) if (err != nil) && (err.Error() != "EOF") { pd.req.Body.Close() pd.file.Sync() return true, err } //log.Printf("returned from server %v bytes", count) if pd.dp.Pos+int64(count) > pd.dp.To { count = int(pd.dp.To - pd.dp.Pos) log.Printf("warning: server return to much for me i give only %v bytes", count) } realc, err := pd.file.WriteAt(buffer[:count], pd.dp.Pos) if err != nil { pd.file.Sync() pd.req.Body.Close() return true, err } pd.dp.Pos = pd.dp.Pos + int64(realc) pd.messureSpeed(realc) //log.Printf("writed %v pos %v to %v", realc, pd.dp.Pos, pd.dp.To) if pd.dp.Pos == pd.dp.To { //ok download part complete normal pd.file.Sync() pd.req.Body.Close() pd.dp.Speed = 0 log.Printf("info: download complete normal") return true, nil } //not full download next segment return false, nil } By wrapping the bootloader class in the DiscretWork interface from the previous part of the note, we can try to test its work:
func TestDownload(t *testing.T) { dl, err := httpclient.CreateDownloader("http://pinegrow.s3.amazonaws.com/PinegrowLinux64.2.2.zip", "PinegrowLinux64.2.2.zip", 7) if err != nil { t.Error("failed: can't create downloader") } errs := dl.StartAll() if len(errs)>0 { t.Error("failed: can't start downloader") } …..wait for finish download } Interface
For quite a long time, I have been doing all my services on go in the same way. As a rule, a web-interface through which the user interacts with the json-service through http-requests. Such a scheme of work gives a number of advantages over the traditional graphic interests listed below.
- Ability to automatically add new downloads;
- No binding to a specific operating system, just a browser is enough.
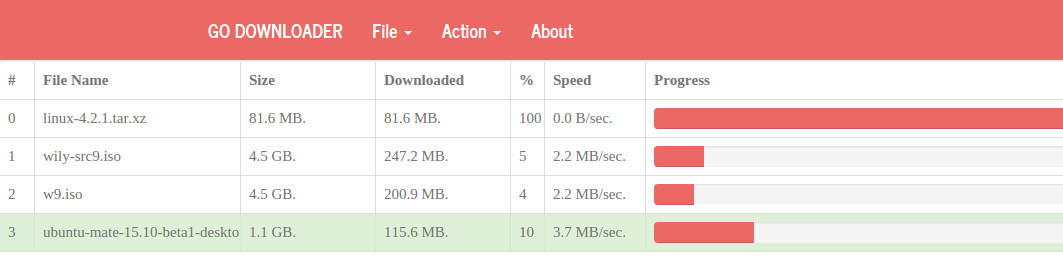
The interface is updated every 500 milliseconds. The pseudo-file localhost / progress.json is used as the data source for the download table. If you open it in the browser, it will open dynamically updated json-data. The jgrid is used as a table component. Due to its simplicity, the code takes up very little space.
function UpdateTable() { $("#jqGrid") .jqGrid({ url: 'http://localhost:9981/progress.json', mtype: "GET", ajaxSubgridOptions: { async: false }, styleUI: 'Bootstrap', datatype: "json", colModel: [{ label: '#', name: 'Id', key: true, width: 5 }, ….. { label: 'Speed', name: 'Speed', width: 15, formatter: FormatByte }, { label: 'Progress', name: 'Progress', formatter: FormatProgressBar }], viewrecords: true, rowNum: 20, pager: "#jqGridPager" }); } Finishing the service and saving the settings
There is another interesting feature of the service about which I would like to tell. This is how the web service ends. The fact is that when the http service starts, the program hangs on the start function and hangs until we finish the application. But Go has the ability to subscribe to signals sent by the operating system. Thus, we can intercept the moment when our process terminates, even if we do it through the kill command and perform some final actions. For example, this is the preservation of settings and the current progress of downloads.
c := make(chan os.Signal, 1) signal.Notify(c, os.Interrupt) signal.Notify(c, syscall.SIGTERM) go func() { <-c func() { gdownsrv.StopAllTask() log.Println("info: save setting ", gdownsrv.SaveSettings(getSetPath())) }() os.Exit(1) }() There are many extensions to the standard go implementation of the http service that allow you to perform any actions after the service is completed. In my opinion, the method described above is the most simple and reliable, this method works even if we kill the service.
In principle, this is probably all that I wanted to convey to readers.
I don’t know how relevant the download manager is for others, but I’m already downloading the distributions and images of virtual machines with the help of my download manager.
But I check the checksums from time to time.
Download release for Mac, Windows, Linux: http://loafter.imtqy.com/godownloader/
Git: https://github.com/Loafter/godownloader
Source: https://habr.com/ru/post/267943/
All Articles