Nothing is easier than calling a function; I myself have done this repeatedly.

The previous article about exceptions in C ++ left a bunch of dark places,
the main thing that remained incomprehensible is how is it done
transfer of control when an exception is raised?
With SJLJ, everything is clear, but it is argued that this technology is practically
pushed out by some no-cost (with no exceptions) tabular mechanism.
But what kind of mechanism it is and how it works, we will understand under the cut.
This article appeared in the process of preparing to speak in C ++ Siberia, when it turned out some details that may well be useful to someone else, except the author, known for his tediousness.
Introduction
It all began with a simple desire to find out the size of the buffer that the setjmp / longjmp functions use:
- sizeof (jmp_buf) == 64 bytes (MSVC 2013, win32)
- sizeof (jmp_buf) == 256 bytes (MSVC 2013, x64)
- sizeof (jmp_buf) == 200 bytes (GCC-4.8.4, Ubuntu 14.04 x64)
And how does this fit in with the number of registers ( AMD x86-64 )?
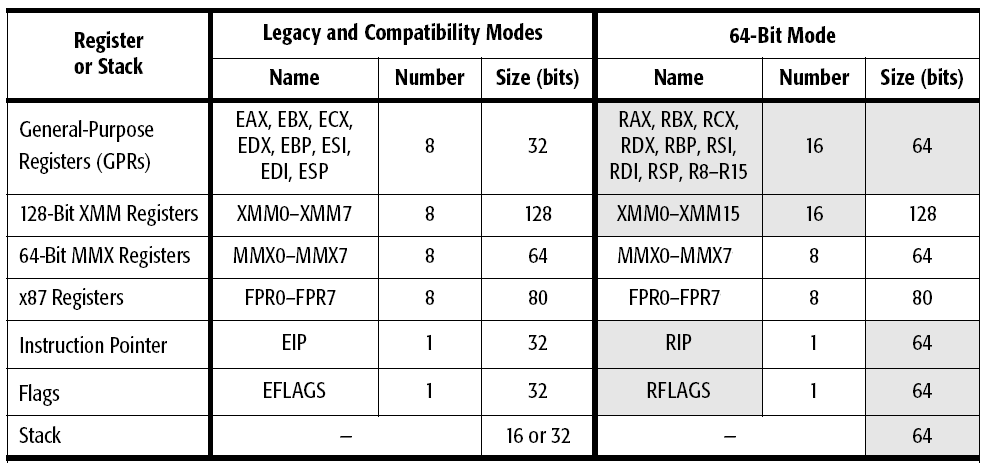
MMX and FP87 registers are combined.
In 32 - bit mode - 32 + 128 + 80 + 12 (eip, flags) = 252 bytes
In 64-bit - 128 + 256 + 80 + 24 (...) = 480 bytes
Something does not converge.
We read documentation :
When you call setjmp, the current stack position, non-volatile registers, and flags are saved.What other non-volatile registers? Again, read the documentation :
When calling a function, the responsibility for saving the contents of a part of the registers lies with the caller, and these are the so-called volatile registers. The callee takes care of the contents of the other registers and these are non-volatile registers.So what is it and why is it needed?
Register division by volatile and non-volatile
It is about optimizing call functions. Such a division has existed for a long time.
In any case, in the architecture of 68K (1979), two out of 8 general-purpose registers and seven address registers were considered volatile, the rest were protected by the called party.
')
In the 88K architecture (1988), 12 of 32 general-purpose registers were protected by the called party + (pointers to the stack and frame).
In the IBM S / 360 (1964), there are 16 integer registers (32-bit) for general purpose and 4 floating point, but no hardware stack. Before calling a function, all registers are stored in a special area. For a recursive call, you need to dynamically request memory from the OS. Parameters are passed as a pointer to a list of pointers to parameter values. In fact, 11 registers are non-volatile.
For architectures with fewer registers, there is no problem with their preservation. In PDP-11 (1970), there are a total of 6 general-purpose registers. And the parameters are passed through the stack. Actually, this is how “C calling convention” ( cdecl ) appeared and it was here that the C language crystallized .
8086. Where do without him. The processor has 8 general-purpose registers, but only BX has no architectural burdens. There were several agreements on calling functions, they concerned the transfer of parameters, and all registers were considered volatile.
We will not dwell on IA-32 , we will return again to x86-64 . In this case, there are too many registers to save their values before each call. In the case of a full-fledged function, this will somehow have to be done, but for small “functionlets” it is wasteful. Need a compromise.
Who can determine which class belongs to a particular register? The compiler itself, to the architecture is indirectly related. Here is what one of the GCC developers wrote in 2003 about this:
The decision to which category to assign a specific register was not easy. AMD64 has 15 general-purpose registers (av. Ln .:% rsp does not count, save it anyway), and using 8 of them (the so-called extended registers) in the instruction requires the REX prefix, which increases its size. In addition, the% rax,% rdx,% rcx,% rsi, and% rdi registers are implicitly used in some IA-32 instructions. We decided to make these volatile registers to avoid restrictions on the use of instructions.
Thus, we can make non-volatile only% rbx,% rbp and extended registers. A series of tests showed that the smallest code is obtained when non-volatile registers are assigned (% rbx,% rbp,% r12-% r15).
Initially, we wanted to make volatile 6 SSE registers. However, difficulties arose - these registers are 128-bit and only 64 bits are usually used to store data, so saving them for the caller is more expensive than for the party being called.
Various experiments were carried out and we came to the conclusion that the most compact and fast code is obtained in the case when all SSE registers are declared as volatile.
This is exactly how things are still, see AMD64 ABI spec , page 21.
The same ABI is supported in B OS X.
Microsoft considered it different and their division is as follows :
- volatile: RAX, RCX, RDX, R8: R11, XMM0: XMM5, YMM0: YMM5
- non-volatile: RSI, RDI, RBX, RBP, RSP, R12: R15, XMM6: XMM15, YMM6: YMM15
What about more case-rich architectures?
This is how things work with the OS X 64-bit compiler for PowerPC, where there are 32 integer registers and floating point ones:
- volatile: GPR0, GPR2: GPR10, GPR12, FPR0: FPR13, a total of 11 + 14
- non-volatile: GPR1, GPR11 (*), GPR13: GPR31, FPR14: FPR31, total 21 + 18
Total: division of registers into two classes implements a universal optimization of function calls:
- some registers are used to pass arguments, this is faster than working through the stack (plus some registers are used for official needs)
- the number of these registers is determined by compiler developers on the basis of statistics and their own ideas about typical code.
- the contents of the other registers are saved only by necessity, so in the case of small and non-greedy functions, it can save nothing
- and when calling a full function, the contents of all registers will be saved, but this is nothing compared to the time the body of this function
Register windows
An alternative approach, processors using this technique , grow from the project Berkeley RISC (1980..1984).
Intel i960 (1989) is a 32-bit processor with 16 local and 16 global general-purpose registers. Parameters are passed through global registers; when a function is called, all local registers are saved with a special instruction. In fact, all local registers are non-volatile, but they are saved forcibly in the hope that hardware support will give this some kind of acceleration. However, in modern times this is just one line of cache .
AMD 29K (1988) - 32-bit processor with 192 (sic!) Registers
- 64 global and 128 local integer registers
- local registers form the top of the stack, continued in memory, access to the stack goes in offsets from the top of the stack (one of the global registers)
- input parameters of the function are transmitted through local registers, return - through global
- there is also a real stack in memory for data that did not fit in 16 words, as well as those that may require an address from someone, for example, for local arrays or anything that has this.
SPARC (1987) may have a different number of registers (S in the name means Scalable)
- typical processor has 128 general purpose registers
- of which only 32 - 8 global and 24 local, which form a window, are visible at a time
- the window consists of 8 input (arguments), 8 local and 8 output (for the next call)
- local registers form a ring buffer; when the function is called, the window is shifted by 16 registers. In this case, 8 output registers for the called function become input.
- when preempted, registers are pushed onto the stack
Itanium (2001) SPARC follower.
- only 128 general-purpose general-purpose general-purpose registers (64-bit) and as many floating
- 32 of them are considered global.
- 96 - local and they form the top of the register stack
- the processor itself takes care of loading and unloading them, creating the illusion of an infinite register stack (RSE, Register Stack Engine)
- when calling a function, a register window is created for it with a special instruction alloc , and the compiler must explicitly set its dimensions
- the window is similar to SPARC, but the dimensions of its parts are flexible and are also set by the compiler, the total size is not more than 96 registers
- in part is intended for function input parameters, not more than 8
- local part for local data
- out - intended for parameters of functions that will be called and this one, not more than 8
- when a function is called from a function, the register window shifts and with a light movement out the part turns into in
- the usual stack is also present, the compiler puts everything that could not be placed on the stack of local registers.
Definitely, Itanium gets the audience award, it’s a pity that this processor didn’t take off.
Function call
So, having considered all this architectural splendor, we can draw the following conclusions about the function call.
Yes, after the optimizer, the contents of the function body sometimes remind of the primary broth , where it is not always clear why this or that instruction is needed and how to find the value of a variable.
However, at the time of the child function call, all this hectic activity freezes.
Regardless of the processor architecture, the actual data from the registers is somehow prevented from being lost. For architects with register windows, this happens naturally. For other volatile registers are saved in memory, if this is a temporary value and it has no place in memory, it will have to be re-evaluated. Non-volatile registers either remain unchanged or their values are restored.
Suppose an exception occurred in the underlying function and we want to transfer control to one of the catch blocks of a certain function. All the information we need to restore the execution context is already in the stack or in registers,
The try block may take no effort, it does not need to allocate space on the stack and save there anything. All information is already saved. But now the problem arises how to save information about where we placed that information.
Fortunately, this information is static and is determined at compile time. The compiler collects all of this into tables, and that’s how it turned out to be a no-cost tabular mechanism.
Let's see how this is implemented in the MSVC (x64) and GCC (x64) compilers.
MSVC (x64)
MSVC creates a prolog and an epilog for each function, while the RSP value between them remains unchanged. RBP is considered a regular register until someone uses alloca . Take for experiments some nontrivial function and look in the debugger at the significant part of its prologue for us:
000000013F440850 mov rax, rspthe optimizer dilutes the prolog code with initialization instructions whenever possible .
000000013F440853 push rbp
000000013F440854 push rdi
000000013F440855 push r12
000000013F440857 push r14
000000013F440859 push r15
000000013F44085B lea rbp, [rax-0B8h] # initialization
000000013F440862 sub rsp, 190h
000000013F440869 mov qword ptr [rbp + 20h], 0FFFFFFFFFFFFFFFEh # initialization
000000013F440871 mov qword ptr [rax + 10h], rbx
000000013F440875 mov qword ptr [rax + 18h], rsi
000000013F440879 mov rax, qword ptr [__security_cookie (013F4C5020h)] #from hereafter - the function body
And an epilogue in which non-volatile registers are brought to their original state.
000000013F4410C2 lea r11, [rsp + 190h]The compiler collects information for the promotion of the stack in the .pdata section. A RUNTIME_FUNCTION structure is created for each function, from which there is a link to the unwind table . Its contents can be pulled out using the link utility with the parameters -dump -unwindinfo. For the same function we find:
000000013F4410CA mov rbx, qword ptr [r11 + 38h]
000000013F4410CE mov rsi, qword ptr [r11 + 40h]
000000013F4410D2 mov rsp, r11
000000013F4410D5 pop r15
000000013F4410D7 pop r14
000000013F4410D9 pop r12
000000013F4410DB pop rdi
000000013F4410DC pop rbp
000000013F4410DD ret
00001D70 00020880 0002110E 000946C0? Write_table_header ...We are interested in Unwind codes - they contain actions that must be performed when an exception is raised.
Unwind version: 1
Unwind flags: EHANDLER UHANDLER
Size of prologue: 0x3A
Count of codes: 11
Unwind codes:
29: SAVE_NONVOL, register = rsi offset = 0x1D0
25: SAVE_NONVOL, register = rbx offset = 0x1C8
19: ALLOC_LARGE, size = 0x190
0B: PUSH_NONVOL, register = r15
09: PUSH_NONVOL, register = r14
07: PUSH_NONVOL, register = r12
05: PUSH_NONVOL, register = rdi
04: PUSH_NONVOL, register = rbp
Handler: 0006BFD0 __GSHandlerCheck_EH
EH Handler Data: 00087578
GS Unwind flags: UHandler
Cookie Offset: 00000188
- the number at the beginning of the line means a shift from the beginning of the function of the instruction address following the described one. If an exception occurs in the middle of the prologue (which is very strange), only the changes made can be rolled back.
- Then comes the type of instruction, for example, ALLOC_LARGE means allocating a certain amount of memory on the stack, SAVE_NONVOL - saving the register to already allocated memory, PUSH_NONVOL - saving the register on the stack with decreasing RSP
- instructions go in reverse order, repeating the actions of the epilogue
GCC (x64)
Similarly, we analyze the prologue and epilogue of the same function created by GCC.
Prologue
.cfi_startprocEpilogue:
.cfi_personality 0x9b, DW.ref .__ gxx_personality_v0
.cfi_lsda 0x1b, .LLSDA11339
pushq% r15
.cfi_def_cfa_offset 16
.cfi_offset 15, -16
pushq% r14
.cfi_def_cfa_offset 24
.cfi_offset 14, -24
pushq% r13
.cfi_def_cfa_offset 32
.cfi_offset 13, -32
movq% rdi,% r13
pushq% r12
.cfi_def_cfa_offset 40
.cfi_offset 12, -40
pushq% rbp
.cfi_def_cfa_offset 48
.cfi_offset 6, -48
pushq% rbx
.cfi_def_cfa_offset 56
.cfi_offset 3, -56
subq $ 456,% rsp
.cfi_def_cfa_offset 512
addq $ 456,% rspCFI prefix means Call Frame Information; these are directives to the assembler how to write additional information for stack promotion. This information is collected in the .eh_frame section, you can see it in a readable form using the dwarfdump utility with the -F key
.cfi_remember_state
.cfi_def_cfa_offset 56
popq% rbx
.cfi_def_cfa_offset 48
popq% rbp
.cfi_def_cfa_offset 40
popq% r12
.cfi_def_cfa_offset 32
popq% r13
.cfi_def_cfa_offset 24
popq% r14
.cfi_def_cfa_offset 16
popq% r15
.cfi_def_cfa_offset 8
ret
#prologueWhat we see here:
〈0〉 〈0x00000e08: 0x00000f4a 〈〉 〈fde offset 0x00000e00 length: 0x00000060 eh aug data len 0x0
0x00000e08: 〈off cfa = 08 (r7) 〈off r16 = -8 (cfa)
0x00000e0a: 〈off cfa = 16 (r7) 〈off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e0c: 〈off cfa = 24 (r7) 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e0e: 〈off cfa = 32 (r7) 〈off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e10: 〈off cfa = 40 (r7) off r12 = -40 (cfa) 〈off r13 = -32 (cfa)
〈Off r14 = -24 (cfa)〉 〈off r15 = -16 (cfa) 〈off r16 = -8 (cfa)
0x00000e11: 〈off cfa = 48 (r7) 〈off r6 = -48 (cfa)
〈Off r12 = -40 (cfa)〉 〈off r13 = -32 (cfa)
〈Off r14 = -24 (cfa)〉 〈off r15 = -16 (cfa)
〈Off r16 = -8 (cfa)
0x00000e12: 〈off cfa = 56 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
#body
0x00000e19: 〈off cfa = 64 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e51: 〈off cfa = 56 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e52: 〈off cfa = 48 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e53: 〈off cfa = 40 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e55: 〈off cfa = 32 (r7) 〈off r3 = -56 (cfa) 〈off r6 = -48 (cfa)
〈〈Off r12 = -40 (cfa)〉 〈off r13 = -32 (cfa)
〈Off r14 = -24 (cfa)〉 〈off r15 = -16 (cfa)
〈Off r16 = -8 (cfa)
0x00000e57: 〈off cfa = 24 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e59: 〈off cfa = 16 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e5b: 〈off cfa = 08 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000e60: 〈off cfa = 64 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa) 〈off r14 = -24 (cfa) 〈off r15 = -16 (cfa)
〈Off r16 = -8 (cfa)
0x00000f08: 〈off cfa = 56 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f09: 〈off cfa = 48 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f0a: 〈off cfa = 40 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f0c: 〈off cfa = 32 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa) 〈off r14 = -24 (cfa) 〈off r15 = -16 (cfa)
〈Off r16 = -8 (cfa)
0x00000f0e: 〈off cfa = 24 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f10: 〈off cfa = 16 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f12: 〈off cfa = 08 (r7) 〈off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
0x00000f18: 〈off cfa = 64 (r7) off r3 = -56 (cfa)
〈Off r6 = -48 (cfa)〉 〈off r12 = -40 (cfa)
〈Off r13 = -32 (cfa)〉 〈off r14 = -24 (cfa)
〈Off r15 = -16 (cfa)〉 〈off r16 = -8 (cfa)
- the first number is the instruction address
- for each address you can find the interval to which the entry corresponds
- the record consists of a descriptor which register is a frame-pointer 〈off cfa = 48 (r7) (r7 is% rsp, see dwarfdump.conf ),
- and a list of register descriptors, for example, r off r3 = -56 (cfa) means that the register% rbx is stored at -56 offset from frame-pointer
- The prologue is similar to assembly language, the% r16 register has been added, which the compiler uses for some of its own purposes.
- There is no description of the epilogue, apparently, the compiler believes that when executing the epilogue there can be no exceptions
- we see several code branches in which the value of cfa monotonously decreases. It is not clear why this happens, perhaps the compiler inline functions and places their temporary data on the stack, saves the stack rollback until everything fits in the red zone .
Total
So we got to the end. In the process, it turned out that there was no magic. In order to be able to recover from the exception after catching the exception, no action is needed, everything is saved by itself during the natural execution of the code.
But in order to restore the state, a little help from the compiler is required, but everything is rather modest, without frills.
In general, exception handling by modern compilers is an excellent example of how the most difficult problem can be solved calmly, without any fuss, using completely “worker-peasant” methods. Developers respect.
Source: https://habr.com/ru/post/267771/
All Articles