Using DPDK to provide high performance application solutions (part 0)
Kernel is the root of all evil ⊙.☉
Now it’s hardly possible to surprise anyone with the use of epoll () / kqueue () in the event pollers. To solve the C10K problem, there are quite a lot of various solutions ( libevent / libev / libuv ), with different performance and rather high overhead costs. The article discusses the use of DPDK for solving the problem of processing 10 million connections (C10M), and achieving maximum performance gains when processing network requests in common application solutions. The main feature of this task is the delegation of responsibility for processing traffic from the OS kernel to the user space (userspace), precise control of interrupt handling and DMA channels, the use of VFIO , and many other not very clear words. Java Netty was selected as the target application environment using the Disruptor pattern and offheap caching .

In short, this is a very efficient way to handle traffic, in terms of performance close to existing hardware solutions. The overhead of using funds provided by the OS kernel itself is too high, and for such tasks it is the source of most problems. The difficulty lies in the support of the drivers of the target network interfaces, and the architectural features of the applications as a whole.
')
The article discusses in great detail the issues of installation, configuration, use, debugging, profiling and deployment of DPDK for building high-performance solutions.
Why DPDK ?
There are also Netmap , OpenOnload and pf_ring .
netmap
The main task in the development of netmap was the development of an easy-to-use solution, so the most common synchronous interface select () is provided for it, which significantly simplifies porting existing solutions. From the point of view of flexibility and abstraction of iron, netmap 's obviously lacks functionality. Nevertheless, this is the most accessible and widespread solution (even under
pf_ring
pf_ring appeared as a means of overclocking pcap 'a, and historically it was that at the time of development there were no ready-to-use, stable solutions. There are not many obvious advantages over the same netmap, but there is support for IOMMU in the proprietary ZC version. By itself, the product has long been not distinguished by high performance or quality, is nothing more than a means of collecting and analyzing pcap dumps and was not intended to handle traffic in user applications. The main feature of pf_ring 'a ZC is complete independence from existing network interface drivers.
OpenOnload
OpenOnload highly specialized, high-performance,
Other
There are also Napatech solutions, but, as far as I know, they have just a library with their API there, without a hardware program like SolarFlare , so their solutions are less common.
Naturally, I didn’t consider all existing solutions - I just couldn’t face everything, but I don’t think that they can be very different from what was described above.
DPDK
Historically, the most common adapters for working with 10 / 40GbE are Intel adapters serviced by e1000 igb ixgbe i40e drivers. Therefore, they are frequent target adapters for high-performance traffic processing tools. So it was with Netmap and pf_ring , the developers of which are
DPDK is Intel 's OpenSource project, on the basis of which entire offices were built ( 6WIND ) and for which manufacturers rarely provide drivers, for example, Mellanox . Naturally, commercial support for solutions based on it is simply wonderful, it provides a fairly large number of vendors (6WIND, Aricent, ALTEN Calsoft Labs, Advantech, Brocade, Radisys, Tieto, Wind River, Lanner, Mobica)
DPDK has the broadest functionality and best abstracts existing iron.
It is not created conveniently - it is created flexible enough to achieve high, possibly maximum, performance.
List of supported drivers and cards
- Chelsio cxgbe ( Terminator 5 )
- Cisco enic (all Virtual Interface Card series)
- Emulex oce ( OneConnect OCe14000 family)
- Mellanox mlx4 ( ConnectX-3 , ConnectX-3 Pro )
- QLogic / Broadcom bnx2x ( NetXtreme II )
Intel all existing drivers in the linux kernel
- e1000 (82540, 82545, 82546)
- e1000e (82571..82574, 82583, ICH8..ICH10, PCH..PCH2)
- igb (82575..82576, 82580, I210, I211, I350, I354, DH89xx)
- ixgbe (82598..82599, X540, X550)
- i40e (X710, XL710)
- fm10k
All of them are ported as Poll Mode drivers for execution in user space ( usermode ).
Something else ?
Actually, yes, there is still support
- virtualization based on QEMU , Xen , VMware ESXi
- paravirtualized network interfaces based on copying buffers,
even though it is evil - AF_PACKET sockets and PCAP dumps for testing
- network adapters with ring buffers
DPDK Architecture
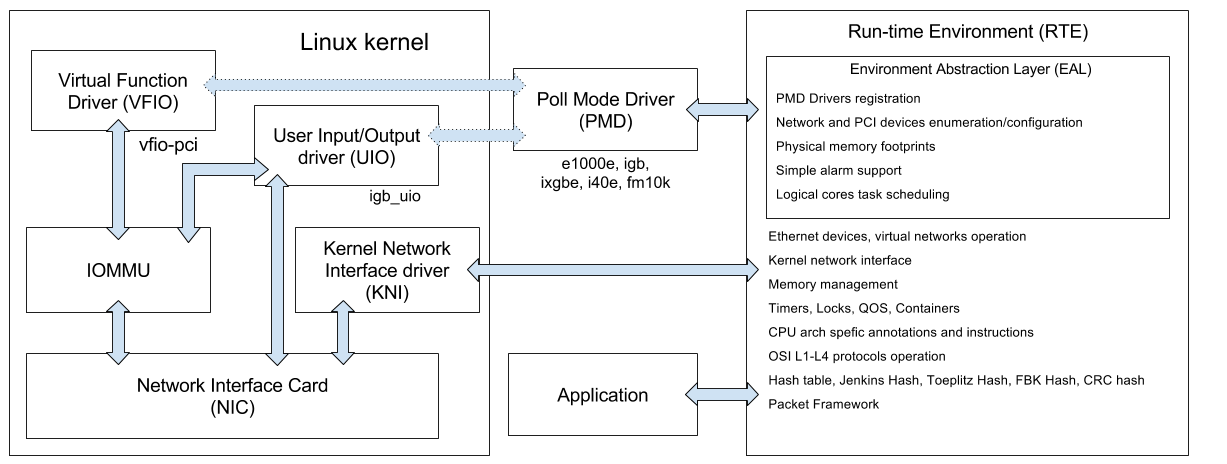
* this is it in my head so funtsiruet, the reality may be slightly different
DPDK itself consists of a set of libraries (the contents of the lib folder ):
- librte_acl -
CEPaccess control lists for VLANs - librte_compat - compatibility of exported binary interfaces (ABI)
- librte_ ether - control of ethernet adapter, work with ethernet frames
- librte_ ivshmem - sharing buffers with ivshmem
- librte_ kvargs - parsing key-value arguments
- librte_ mbuf - message buffer management ( message buffer - mbuf )
- librte_ net - a piece of BSD's IP stack with ARP / IPv4 / IPv6 / TCP / UDP / SCTP
- librte_ power - power and frequency management ( cpufreq )
- librte_ sched - QOS hierarchical scheduler
- librte_ vhost - virtual network adapters
- librte_ cfgfile - parsing configuration files
- librte_ distributor - a means of distributing packages between existing tasks
- librte_ hash - hash functions
- librte_ jobstats - measuring task execution time
- librte_lpm - Longest Prefix Match functions, used to look for forwarding tables
- librte_mempool - memory object pool manager
- librte_ pipeline - package framework pipeline
- librte_ reorder - sorting packets in a message buffer
- librte_ table - lookup table implementation (lookup table)
- librte_ cmdline - parsing command line arguments
- librte_ eal - platform dependent environment
- librte_ip_frag - IP packet fragmentation
- librte_ kni - API for interacting with KNI
- librte_ malloc - easy to guess
- librte_ meter - QOS metric
- librte_ port - implementing ports for network packets
- librte_ ring - ring lock-free FIFO queues
- librte_ timer - timers and counters
UIO drivers ( lib / librte_eal / linuxapp ) network interfaces under linux:
- uio_igb - ethernet network adapter
- xen_dom0 - clear from the title
and BSD
- nic_uio
And the aforementioned Poll Mode drivers ( PMD ) that run in the user space ( userspace ): e1000, e1000e, igb, ixgbe, i40e, fm10k and others.
Kernel Network Interface (KNI) is a specialized driver that allows you to interact with the kernel network API, perform ioctl calls to ports of interfaces that work with DPDK , use common utilities ( ethtool , ifconfig , tcpdump ) to manage them.
As you can see, DPDK , in comparison with other
Requirements and fine tuning of the target system
The main recommendations of the official documentation have been translated and supplemented.
The issue of setting up XEN and VMware hypervisor for working with DPDK is not affected.
Are common
If you put your DPDK under the Intel Communications Chipset 89xx, then you are here .
To build you need coreutils , gcc , kernel headers, glibc headers.
It seems to support clang , and there is support for Intel 's icc .
To run auxiliary scripts - Python 2.6 / 2.7
The Linux kernel must be compiled with UIO support and monitoring of process address spaces, these are the kernel parameters:
CONFIG_UIO
CONFIG_UIO_PDRV
CONFIG_UIO_PDRV_GENIRQ
CONFIG_UIO_PCI_GENERIC
and
CONFIG_PROC_PAGE_MONITOR
I want to draw attention to the fact that in grsecurity the parameter PROC_PAGE_MONITOR is considered too informative - it helps in exploiting kernel vulnerabilities and bypassing the ASLR .
HPET
For organizing periodic interruptions of high accuracy, an HPET timer is needed.
You can look availability
grep hpet /proc/timer_list Advanced -> PCH-IO Configuration -> High Precision TimerAnd build a kernel with CONFIG_HPET and CONFIG_HPET_MMAP enabled .
By default, HPET support is disabled in the DPDK itself, so you need to enable it by setting the CONFIG_RTE_LIBEAL_USE_HPET flag manually in the config / common_linuxapp file .
In some cases it is advisable to use HPET , in others - TSC .
To implement a high-performance solution, you need to use both, since they have a different purpose and they compensate for each other’s shortcomings. Usually, the default is TSC . Initialization and availability check of the HPET timer is performed by calling rte_eal_hpet_init (int make_default ) < rte_cycles.h >. It's strange that the API documentation misses it.
Core insulation
For unloading the system scheduler, a fairly common practice is to isolate the logical cores of the processor for the needs of high-performance applications. This is especially true for dual-processor systems.
If your application runs on even-numbered kernels 2, 4, 6, 8, 10, you can add a kernel parameter to your favorite bootloader
isolcpus = 2,4,6,8,10For the widespread grub 'a, this is the GRUB_CMDLINE_LINUX_DEFAULT parameter in the / etc / default / grub config.
Hugepages
Large pages are needed to allocate memory for network buffers. Allocating large pages has a positive effect on performance since fewer calls are needed to translate virtual memory addresses into TLBs . True, they should stand out in the process of loading the kernel to avoid fragmentation.
To do this, add a kernel parameter:
hugepages = 1024This will allocate 1024 pages of 2 MB each.
To highlight four pages per gigabyte:
default_hugepagesz = 1G hugepagesz = 1G hugepages = 4But we need the appropriate support - the pdpe1gb processor flag in / proc / cpuinfo .
grep pdpe1gb /proc/cpuinfo | uniq For 64-bit applications, using 1GB pages is preferred.
To obtain information about the distribution of pages between the cores in the NUMA system, you can use the following command
cat /sys/devices/system/node/node*/meminfo | fgrep Huge You can read more about managing the policy of allocating and freeing large pages in NUMA systems in the official documentation .
To support large pages, you need to build a kernel with the parameter CONFIG_HUGETLBFS
Management of allocated memory areas for large pages is carried out by the Transparent Hugepage mechanism, which performs defragmentation in a separate khugepaged kernel stream . To support it, you need to collect with the CONFIG_TRANSPARENT_HUGEPAGE parameter and the CONFIG_TRANSPARENT_HUGEPAGE_ALWAYS policies or CONFIG_TRANSPARENT_HUGEPAGE_MADVISE policies .
This mechanism remains relevant even in the case of allocation of large pages during the OS boot, since, nevertheless, there remains the probability of not being able to allocate continuous memory areas for 2 MB pages, for various reasons.
There is a NUMA blockbuster and memory from Intel 's adepts.
There is a small article about using large pages from Rad Hat.
After configuring and selecting pages, you need to mount them; to do this, add the corresponding mount point to / etc / fstab
nodev /mnt/huge hugetlbfs defaults 0 0 For 1GB pages, the page size must be specified as an additional parameter.
nodev /mnt/huge hugetlbfs pagesize=1GB 0 0 According to my personal observations, the most problems with setting up and operating DPDK arise with large pages. It is worth paying special attention to the administration of large pages.
By the way, in Power8, the size of large pages is 16 MBytes and 16 GB, which, as for me, is a little overkill.
Energy Management
The DPDK already has the means to control the frequencies of the processor, so that the standard policies "do not stick in the wheels."
To use them you need to enable SpeedStep and C3 C6 .
In BIOS, the path to the settings might look like this
Advanced-> Processor Configuration-> Enhanced Intel SpeedStep TechThe l3fwd-power application provides an example of an L3 switch using power management features.
Advanced-> Processor Configuration-> Processor C3 Advanced-> Processor Configuration-> Processor C6
Access rights
It is clear that it is very insecure to execute an application with root access rights.
It is advisable to use ACLs to create permissions for a particular user group.
setfacl -su::rwx,g::rwx,o:---,g:dpdk:rw- /dev/hpet setfacl -su::rwx,g::rwx,o:---,g:dpdk:rwx /mnt/huge setfacl -su::rwx,g::rwx,o:---,g:dpdk:rw- /dev/uio0 setfacl -su::rwx,g::rwx,o:---,g:dpdk:rw- /sys/class/uio/uio0/device/config setfacl -su::rwx,g::rwx,o:---,g:dpdk:rwx /sys/class/uio/uio0/device/resource* That will add full access for the dpdk user group for the resources used and the uio0 device.
Firmware
For 40GbE network adapters, processing small packets is quite a challenge, and from firmware to firmware, Intel introduces additional optimizations. Support for FLV3E series firmware is implemented in DPDK 2.2-rc2, but for now the most optimal version is 4.2.6 . You can either contact vendor support or directly contact Intel for an update, or upgrade it yourself.
Extended labels, size of request and read handles in PCIe devices
The PCIe bus parameters extended_tag and max_read_request_size significantly affect the processing speed of small packets - on the order of 100 byte 40GbE adapters. In some versions of the BIOS, you can install them manually - 125 Bytes and "1", respectively, for 100 byte packets.
Values can be set in the config / common_linuxapp config when building DPDK using the following parameters:
CONFIG_RTE_PCI_CONFIGOr using the setpci lspci commands.
CONFIG_RTE_PCI_EXTENDED_TAG
CONFIG_RTE_PCI_MAX_READ_REQUEST_SIZE
This is the difference between the MAX_REQUEST and MAX_PAYLOAD parameters for PCIe devices, but there is only MAX_REQUEST in the configs.
For the i40e driver, it makes sense to reduce the size of the read handles to 16 bytes, you can do this by setting the following parameter: CONFIG_RTE_LIBRTE_I40E_16BYTE_RX_DESC in config / common_linuxapp or in config / common_bsdapp, respectively.
You can also specify the minimum interval between the processing of the write interrupts CONFIG_RTE_LIBRTE_I40E_ITR_INTERVAL depending on the existing priorities: maximum throughput or per packet latency.
Also, there are similar parameters for the driver Mellanox mlx4.
CONFIG_RTE_LIBRTE_MLX4_SGE_WR_NWhich for certain somehow influence productivity.
CONFIG_RTE_LIBRTE_MLX4_MAX_INLINE
CONFIG_RTE_LIBRTE_MLX4_TX_MP_CACHE
CONFIG_RTE_LIBRTE_MLX4_SOFT_COUNTERS
All other parameters of network adapters are associated with debugging modes that allow very finely profile and debug the target application, but more on that later.
IOMMU for working with Intel VT-d
You need to build a kernel with parameters
CONFIG_IOMMU_SUPPORT
CONFIG_IOMMU_API
CONFIG_INTEL_IOMMU
For igb_uio driver, the boot parameter must be set.
iommu = ptWhich leads to the correct translation of DMA addresses ( DMA remapping ). IOMMU support for the target network adapter in the hypervisor is turned off . By itself, IOMMU is quite wasteful for high-performance network interfaces. DPDK implements one-to-one mapping, so full IOMMU support is not required, even though this is another security breach.
If the INTEL_IOMMU_DEFAULT_ON flag is set when building the kernel, then the boot parameter should be used
intel_iommu = onThat guarantees the correct initialization of Intel IOMMU .
I want to note that the use of UIO ( uio_pci_generic , igb_uio ) is optional for kernels supporting VFIO (vfio-pci), which are used to interact with the target network interfaces.
igb_uio is needed if there are no support for some interrupts and / or virtual functions by the target network adapters, otherwise you can safely use uio_pci_generic .
Despite the fact that the iommu = pt parameter is mandatory for the igb_uio driver, the vfio-pci driver functions correctly both with the iommu = pt parameter and with iommu = on.
By itself, the VFIO functions quite
If your device is located behind a PCI-to-PCI bridge, then the bridge driver will be included in the same IOMMU group as the target adapter, so the bridge driver must be unloaded — so that the VFIO can pick up the devices behind the bridge.
You can check the location of existing devices and the drivers used by the script
./tools/dpdk_nic_bind.py --status You can also explicitly bind drivers to specific network devices.
./tools/dpdk_nic_bind.py --bind=uio_pci_generic 04:00.1 ./tools/dpdk_nic_bind.py --bind=uio_pci_generic eth1 It is convenient however.
Installation
We take the source and collect as described below.
DPDK itself comes with a set of example applications, where you can test the correctness of the system setup.
Configuring the DPDK, as mentioned above, is done by setting the parameters in the config / common_linuxapp and config / common_bsdapp files . Standard values for platform-specific parameters are stored in config / defconfig_ * files.
First, the configuration template is applied, the build folder is created with all the living creatures and targets:
make config T=x86_64-native-linuxapp-gcc The following target environments are available in DPDK 2.2 (mine)
arm-armv7a-linuxapp-gcc arm64-armv8a-linuxapp-gcc arm64-thunderx-linuxapp-gcc arm64-xgene1-linuxapp-gcc i686-native-linuxapp-gcc i686-native-linuxapp-icc ppc_64-power8-linuxapp-gcc tile-tilegx-linuxapp-gcc x86_64-ivshmem-linuxapp-gcc x86_64-ivshmem-linuxapp-icc x86_64-native-bsdapp-clang x86_64-native-bsdapp-gcc x86_64-native-linuxapp-clang x86_64-native-linuxapp-gcc x86_64-native-linuxapp-icc x86_x32-native-linuxapp-gcc ivshmem is a QEMU mechanism that seems to allow sharing a memory area between several guest virtual machines without copying, by means of a common specialized device. Although copying to shared memory is necessary in the case of communication between guest OSs, this is not the case with DPDK . By itself, ivshmem is implemented quite simply .
The purpose of the rest of the configuration templates should be obvious, otherwise why are you reading this at all?
In addition to the configuration template, there are other optional parameters.
EXTRA_CPPFLAGS - EXTRA_CFLAGS - EXTRA_LDFLAGS - EXTRA_LDLIBS - RTE_KERNELDIR - CROSS - V=1 - D=1 - O - `build` DESTDIR - `/usr/local` Further, just good old
make The target list for make is pretty trite
all build clean install uninstall examples examples_clean To work, you need to load UIO modules
sudo modprobe uio_pci_generic or sudo modprobe uio sudo insmod kmod/igb_uio.ko If VFIO is used
sudo modprobe vfio-pci If KNI is used
insmod kmod/rte_kni.ko Build and run examples
DPDK uses 2 environment variables to build examples:
- RTE_SDK - path to the folder where DPDK is installed
- RTE_TARGET - the name of the configuration template used for the assembly
They are used in the respective Makefile 'ah.
EAL already provides some command line parameters to configure the application:
- -c <mask> - a hexadecimal mask of logical cores on which the application will be executed
- -n <number> of memory channels per processor
- -b <domain: bus: identifier.function>, ... - black list of PCI devices
- --use-device <domain: bus: identifier.function>, ... - white list of PCI devices, cannot be used simultaneously with black
- --socket-mem MB - amount of memory allocated for large pages per processor socket
- -m MB - the amount of memory allocated for large pages, ignoring the physical location of the processor
- -r <number> of memory slots
- -v - version
- - huge-dir - folder to which large pages are mounted
- --file-prefix - the prefix of files that are stored in the file system of large pages
- --proc-type is a process instance, used together with --file-prefix to run an application in several processes
- --xen-dom0 - execution in Xen domain0 without support for large pages
- --vmware-tsc-map - use TSC counter provided by VMWare , instead of RDTSC
- --base-virtaddr - base virtual address
- --vfio-intr - interrupt type used by VFIO
To check the numbering of cores in the system, you can use the lstopo command from the hwloc package.
It is recommended to use all the memory allocated in the form of large pages, this is the default behavior if the -m and --socket-mem parameters are not used. Allocating contiguous areas of memory less than what is available in large pages can lead to EAL initialization errors, and sometimes to undefined behavior.
To allocate 1GB of memory
- on zero socket () you need to specify - socket-mem = 1024
- on the first - socket-mem = 0.1024
- on zero and second - socket-mem = 1024,0,1024
To build and run Hello World
export RTE_SDK=~/src/dpdk cd ${RTE_SDK}/examples/helloworld make ./build/helloworld -cf -n 2 Thus, the application will run on four cores, taking into account that 2 memory bars have been installed.
And we get 5 hello worlds from different cores.
Chicken, egg and pterodactyl problem
I chose Java as the target platform because of the relatively high performance of the virtual machine and the possibility of introducing additional memory management mechanisms. The question of how to allocate responsibility: where to allocate memory, where to manage flows, how to perform task scheduling, and what is special about DPDK mechanisms is quite complex and two-digit. I had to uncommonly pokolovatsya in the source DPDK , Netty, and most OpenJDK . As a result, specialized versions of netty components with very deep DPDK integration were developed .
To be continued.
Source: https://habr.com/ru/post/267591/
All Articles