As a result, I wrote a new RTOS, tested and stable
I have been working with embedded systems for several years: our company develops and manufactures on-board computers for cars, chargers, etc.

The processors used in our products are mainly 16- and 32-bit Microchip microcontrollers with 8 to 32 kB RAM, and 128 to 512 kB RAM, without MMU. Sometimes, for the most simple devices, even more modest 8-bit chips are used.
')
Obviously, we have no (reasonable) chance of using the Linux kernel. So we need some RTOS (Real-Time Operating System). There are even people who do not use any OS in microcontrollers, but I do not consider this a good practice: if the iron allows me to use the OS, I use it.
A few years ago, when we were switching from 8-bit to the more powerful 16-bit microcontrollers, my colleagues, who were much more experienced than I, recommended the preemptive RTOS TNKernel . So this is the OS that I used in different projects for a couple of years.
Not that I was very pleased with it: for example, there are no timers in it. And it does not allow the thread to wait for messages from several queues at once. And there is no software control over stack overflow (this really strained). But she worked, so I continued to use it.
Just to make sure that we understand each other, I will make a brief overview of how the preemptive OS works in principle. I apologize if the things I present here are too trivial for the reader.
Microcontrollers are "single-threaded": they can execute only one instruction at a time (of course, there are multi-core processors, but now this is not about that). To run multiple threads on a single core processor, we need to switch between threads, so the user feels that they are running in parallel.
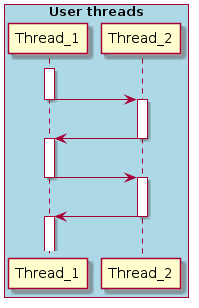
This is what the OS is all about in the first place: it switches control between threads. How exactly does she do it?
The microcontroller has a set of registers. Since microcontrollers are single-threaded, this set of registers belongs to only one thread. For example, when we find the sum of two numbers:
In fact, something like the following is happening (of course, the specific sequence of actions depends on the architecture, but in general the idea remains the same):
There are 4 actions. Since in a preemptive OS, one thread can force out another thread at any time, then, of course, this can happen in the middle of this sequence. Imagine that another thread pushes the current one after the values for summation have been loaded into the V0 and V1 registers. The new thread has its own business and, therefore, it uses these registers as it needs. Of course, the two streams should not interfere with each other, so that when the first thread gets control again, the values of the V0 and V1 registers (and others) should be as they were before crowding out.
So, when we switch from flow A to flow B, first of all we have to save the values of all the registers of flow A, then restore the values of all the registers of flow B. And only then the flow B gets control, and continues to work.
So a more accurate flow switching diagram will look like this:
When you need to switch from one thread to another, the kernel receives control, performs the necessary service actions (at least, saves and restores the values of the registers), and then control is transferred to the next thread.
Where exactly are the values of the registers for each thread? Very often, this is a thread stack.
In modern operating systems, the (user) stack grows dynamically thanks to the MMU: the more the thread needs, the more it gets (if the kernel allows it). But the microcontrollers I work with do not have this luxury: all RAM is statically mapped to the address space. So each thread gets its some RAM, which is used under the stack; and if the thread uses more stack than it was allocated, then this leads to memory corruption and, therefore, to incorrect operation. In fact, the stack space for each thread is just an array of bytes.
When we decide how much stack each particular thread needs, first we just figure out how much it may need it, and take it with some margin. For example, if it is a deeply nested GUI stream, it may require several kilobytes, but if it is a small stream that processes user input, then a few hundred bytes may suffice.
Let's assume that we have three threads, and their stack consumption is as follows:
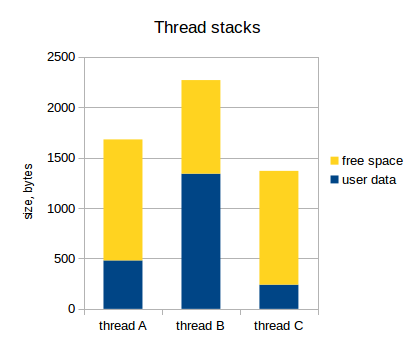
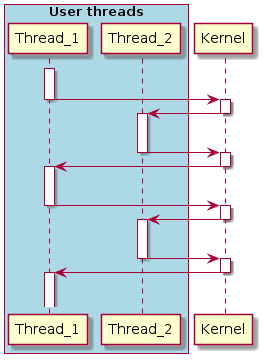
As I have already indicated, the set of register values for each thread is saved to the stack of that thread. This set of register values is called a thread context . The following diagram reflects this (the active stream is indicated by an asterisk):
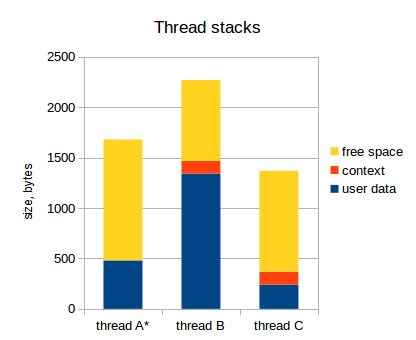
Notice that the active thread (thread A) has no context saved to the stack. The stack pointer in the microcontroller points to the top of user data stream A, and the entire set of registers of the microcontroller belongs to stream A (in fact, there may be special registers that are not related to the stream, but this does not interest us now).
When the kernel decides to switch control from thread A to thread B, it does the following:
After that, we have the following:

And stream B continues to go about its business.
We have not yet touched on a very important topic: interruptions.
An interrupt is when a thread currently executing stops (most often, due to an external event), the processor switches to something else for a while (to interrupt processing), and then returns to the interrupted thread. An interrupt can be generated at any time, and we need to be ready for this.
Microcontrollers used for embedded systems usually have quite a lot of peripherals: timers, transceivers (UART, SPI, CAN, etc.), ADCs, etc. This periphery can generate interrupts when a certain event occurs: for example, the UART periphery can generate an interrupt when a new byte is received, so the program can save it somewhere. Timers generate an overflow interrupt, so the program can use this for some periodic tasks, etc.
The interrupt handler is called ISR (Interrupt Service Routine).
Interrupts can have different priorities: for example, when a low priority interrupt is generated, the thread being executed is suspended, and the ISR gets control. Now, if a high-priority interrupt is generated, then the current ISR, again, is suspended, and the ISR of the new interrupt gets control. Obviously, when it completes, the first ISR continues its work, and when it completes, then, as a result, control is transferred back to the interrupted flow.
There are short periods of time when interrupts are not allowed: for example, if we process some data that may change in the ISR. If we process this data in several steps, the interruption can occur in the middle of processing and change the data. As a result, the stream will process non-integral data, which leads to incorrect operation of the program.
These short periods of time are called “critical sections”: when we enter a critical section, we prohibit interrupts, and when we exit it, we allow interrupts back. That is, if some interrupt is generated inside the critical section, then the ISR will be called only at the moment of exiting it (when the interrupts are enabled).
Very interesting question: where to save the ISR stack?
In general, we have two options:
If we use the stack of the interrupted thread, it looks like this (in the diagram below, flow B is interrupted):
When the interrupt is generated:
This can work quite quickly, but in the context of embedded systems, where our resources are very limited, this approach has a significant drawback. Guess exactly how?
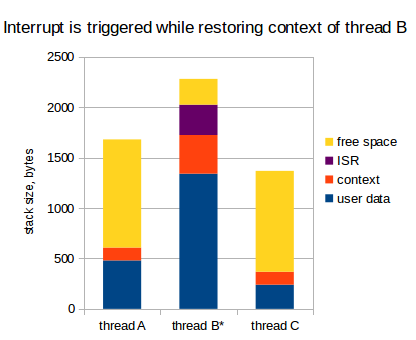
Remember that an interrupt can occur at any time, so obviously we cannot know in advance which thread will be active when the interrupt happens. So, when we estimate the stack size for each thread, we must assume that all existing interrupts can occur in this thread, given their worst nesting. This can significantly increase the size of stacks for all streams: 1 KB is easy, and maybe more (it depends on the application, of course). For example, if in our application there are 7 threads, then the required RAM size for interrupts is 1 * 7 = 7 KB. If our microcontroller has only 32 kb of RAM (and this is already a rich microcontroller), then 7 kb is 20%! Oh shi ~.
In total, the stack of each thread should contain the following:
Ok, move to the next option when we use a separate stack for interrupts:
Now, 1 kB for the ISR from the previous example should be allocated only once. I think this is a much more competent approach: in embedded systems, RAM is a very expensive resource.
After such a superficial overview of the principles of RTOS, go on.
As I indicated at the beginning of the article, we used TNKernel for our development on 16-bit and 32-bit microcontrollers.
Unfortunately, the author of the port of TNKernel for PIC32 , Alex Borisov, used the approach when interrupts use the stack of the interrupted thread. It wastes a lot of RAM in vain and does not make me very happy, but otherwise TNKernel looked good: it is compact and fast, so I continued to use it. Until the day of X, when I was very surprised to learn that in fact everything is much worse.
I was working on another project: a device analyzing an analog signal from a car plug and allowing the user to see some parameters of this signal: duration, amplitude, etc. Since the signal changes rapidly, we need to measure it often enough: once every 1 or 2 microseconds.
For this task, the Microchip PIC32 processor (with the MIPS core) was chosen.
The task should not be very difficult, but one day I had problems: sometimes, when the device started measuring, the program fell in a completely unexpected place. “It must be the case of a tainted memory,” I thought, and I was very upset because the process of finding errors related to memory corruption can be long and completely non-trivial: as I said, there is no MMU, and all RAM is available to all threads in the system, so if one of the threads gets out of control and corrupts the memory of another thread , the problem can manifest itself very far from the actual place with an error.
I have already said that TNKernel does not have software control over stack overflow, so when there is a suspicion of memory corruption, first of all it is worth checking whether the stack of any thread is full. When a thread is created, its stack is initialized to a specific value (in TNKernel under PIC32, it’s just
On MIPS, the stack grows down, so
Well, this is already something. But the fact is that the stack for this stream was allocated with a large margin: when the device works normally, only about 300 bytes from 880 are used! There must be some wild mistake that so hard overflows the stack.
Then I began to study memory more carefully, and it became clear that the stack was filled with repeating patterns. See: sequence
And the same sequence again:
Addresses
Hmm, 34 words ... This is just the size of the context in MIPS! And the same pattern repeats over and over again. So it seems that the context has been saved several times in a row. But ... How can this be ?!
Unfortunately, it took me a long time to figure everything out. First of all, I tried to examine the saved context in more detail: among other things, there should be an address in the program memory, where the interrupted thread should resume work later. On the PIC32, the program memory is mapped to a region from
This characteristic sequence from LW (Load Word) from addresses relative to SP (Stack Pointer) is a context recovery procedure. Now it is clear that the thread was preempted when the context was restored from the stack. Well, this can happen because of an interruption, but why so many times in a row? I don't even have so many interrupts in the system.
Before that, I just used TNKernel without a clear understanding of how it works, because it just worked. So I was even somewhat scared to go deep into the core. But this time, I had to.
We have already discussed the context switching process in general, but for now, let's refresh this topic and add some details of a specific implementation (TNKernel).
When the kernel decides to switch the context from thread A to thread B, it does the following:
As you can see, there is a short critical section, while the kernel operates with pointers to the thread descriptor and to the top of the stack: otherwise a situation may occur when an interrupt is generated between these actions, and the non-integrity of the data, of course, leads to incorrect operation.
In TNKernel, under PIC32, there are two types of interrupts:
Now we are only interested in system interrupts. And TNKernel has a restriction for this type of interrupt: all System Interrupts in the application must have the same priority, so these interrupts cannot be nested.
As a small reminder, this is what happens when an interrupt is generated:
Now the ISR is active, and using the stack looks like this:
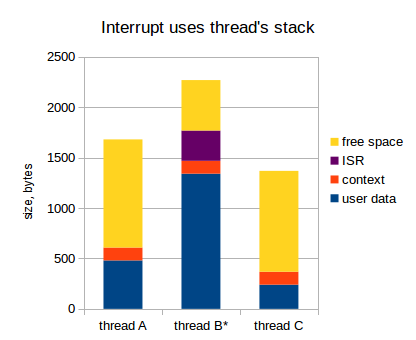
As already mentioned, this approach significantly increases the required stack size for threads: each thread must be large enough to accommodate the following:
The need to multiply the ISR stack by the number of threads is not the most pleasant thing, but, generally speaking, with this I was ready to live.
And what happens if the interrupt is generated during the context switch process, i.e. while the context of the current thread is saved to the stack or restored from the stack?
I think you guessed it: interrupts are not prohibited in the process of saving / restoring the context, the context will be saved twice . Here is:
So, when the kernel decides to switch from thread B to thread A, this is what happens:
We get the following picture:

See: the context is saved twice in the stack of thread B. In fact, this is not a disaster if the stack is not full, since this double-saved context will be restored twice as soon as thread B has control. For example, suppose that thread A goes into waiting for something, and the kernel switches control back to thread B:
Now we, in fact, have returned at that moment when the context was saved to thread stack B before switching to thread A. So we just continue to keep the context:
After that, the flow continues to work, as if nothing had happened:
As you can see, in fact, nothing broke, but we have to draw an important conclusion from this study: our assumption that it should accommodate the context of each stream was wrong . At a minimum, it should contain two contexts, not one.
As you remember, all system interrupts in TNKernel must have the same priority, so that they cannot be nested: this means that the context cannot be saved more than twice.
If so, then the final conclusion: the stack of each thread should contain the following:
Oh ... another 136 bytes for each stream. Again, multiply by the number of threads: for 7 threads, this is almost 1 kilobyte: another 3% from 32 KB.
OK. Good.I, probably , would agree on this situation, but our final conclusion, in fact, it is not final. All the more worse.
Let's examine the process of saving dual context more deeply: even after our recent research, we still cannot explain how it happened that the context was saved on the thread stack many times: when the interrupt is generated, the current interrupt level of the processor is increased (to the priority of the generated interrupt) ), and if another system interrupt occurs, it will be processed after the current ISR returns control.
Take another look at this diagram: the ISR has already returned control, and we switched to stream A:
At this moment, the interrupt level of the processor is again lowered, and the context is saved to thread stack B twice .
Guess what's next?
That's right: when we switch back to thread B, and while its context is restored, another interrupt can occur . Consider:
Yes, the context has already been saved to the thread stack three times. And what's worse, it can even be the same interrupt: the same interrupt can save the context to the thread's stack several times .
So, if you are so unlucky that an interrupt will be generated periodically, and with the same frequency with which threads will switch back and forth, then the context will be stored in the thread stack over and over again, which ultimately leads to stack overflow.
This was clearly not taken into account by the author of the TNKernel port under PIC32.
And this is exactly what happened with my device, which measured the analog signal: the ADC interrupt was generated with exactly this “successful” frequency. This is what happened:
Of course, this is my cant that ADC interrupts are generated so often, but the behavior of the system is completely unacceptable. Correct behavior: my threads stop receiving control (because there is no time) until such frequent interrupt generation is stopped. The stack should not be filled with a bunch of saved contexts, and when interrupts are no longer generated so often, the system quietly continues its work.
And one more consequence: even if we don’t have such periodic interruptions, there’s still a non-zero probability that the different interruptions that exist in the application will occur at such unsuccessful moments that the context will be saved again and again. Embedded systems are often designed for continuous operation over a long period of time (months and years): for example, car alarms, on-board computers, etc. And if the operating time of the device will tend to infinity, then the probability of such a development of events will tend to unity. Sooner or later, it happens. Of course, this is unacceptable, so it is impossible to leave the current state of affairs.
Good: at least now I know the cause of the problems. Next question: how to eliminate this cause?
Perhaps the fastest and dirtiest hack is to simply disable interrupts for the duration of the save / restore context. Yes, this will eliminate the problem, but this is a very, very bad decision: the critical sections should be as short as possible, and prohibiting interruptions for such long periods of time is hardly a good idea.
A much better solution is to use a separate stack for interrupts.
There is another TNKernel port under PIC32 by Anders Montonen, and it uses a separate stack for interrupts. But this port does not have some convenient buns that are present in the port of Alex Borisov: convenient Sishny macros for announcing system interrupts, services for working with system ticks, and others.
So I decided to fork it and implement what I need. Of course, in order to make such changes in the core, I needed to understand how it works. And the more I studied the TNKernel code, the less I liked it. TNKernel gives the impression of a project written on the knee: a lot of duplicate code and there is no integrity.
The most common example found everywhere in the kernel is a code like the following:
If we have several operators
Now, we do not need to remember that before returning it is necessary to enable interrupts. Let the compiler do this work for us.
There is no need to go far for the consequences: here is the function from the last TNKernel 2.7 currently:
See: if incorrect parameters are passed to the function, it returns
The original TNKernel 2.7 code contains a huge amount of code duplication. A lot of similar things are done in different places through a simple copy.
If we have several similar services (for example, services that send a message: from a stream, from a stream without waiting, or from an interrupt), then these are three very similar functions, in which there are 1-2 lines, without any attempts to generalize things .
Switching between thread states is implemented very inextricably. For example, when we need to move a stream from the Runnable state to the Wait state, it is not enough just to remove one flag and put another: we also need to remove it from the start queue in which the thread was, then, perhaps, find the next thread to start, set the cause wait, add stream to queue for wait (if needed), set timeout (if needed), etc. In TNKernel 2.7, there is no general mechanism for this, for each case the code is written “here and now”.
In the meantime, the correct way to implement these things is to write three functions for each state:
Now, when we need to transfer a stream from one state to another, we usually just need to call two functions: one to output the stream from the old state, and another to enter it in the new state. Simple and reliable.
As a result of regular violation of the DRY rule, when we need to change something, we need to edit the code in several places. Needless to say, this is a vicious practice.
In short, TNKernel has a bunch of things that need to be implemented differently.
I decided to refactor it thorough. To make sure that I didn't break anything, I started implementing unit tests for the kernel. And it soon became clear that TNKernel was not tested at all: there are unpleasant bugs in the core itself!
For specific information about found and fixed bugs, seeWhy reimplement TNKernel .
At a certain point, it became clear that what I was doing went far beyond the framework of “refactoring”: I, in fact, rewrote almost everything in its entirety. Plus, there are some things in the TNKernel API that have strained me for a long time, so I slightly changed the API; and also there are things that I lacked, so I implemented them: timers, program control of stack overflow, the ability to wait for messages from several queues, etc.
I thought about the name for a long time: I wanted to designate a direct link with TNKernel, but add something fresh and cool. So the first name was: TNeoKernel.
But after a while, it naturally shrunk to concise TNeo.
TNeo has a standard feature set for RTOS, plus some bonuses that are not everywhere. Most features are optional, so you can turn them off, thereby saving memory and slightly increasing performance.
Project posted on GitHub: TNeo .
At the moment, the kernel is ported to the following architectures:
Full documentation is available in two versions: html and pdf.
Of course, it is very difficult to cover the implementation of the entire kernel in one article; instead, I will try to remember what was not clear to me myself, and focus on these things.
But above all, we need to consider one internal structure: a linked list.
A linked list is a well-known data structure, and the reader is likely already familiar with it. However, for completeness, let's look at the implementation of linked lists in TNeo.
Related lists are used throughout TNeo. More specifically, a circular bidirectional linked list is used. The structure in C is as follows:
It is declared in the src / core / tn_list.c file .
As you can see, the structure contains pointers to instances of the same structure: the previous one and the next one. We can organize a chain of such structures, so that they will be linked as follows:
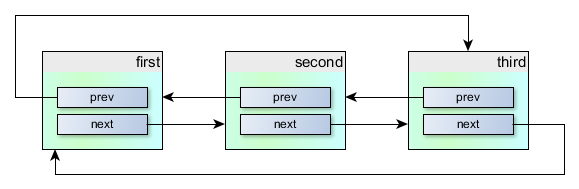
This is great, but there is not a lot of benefit from this: we would like to have some useful data in each object, right?
The solution is to embed
And we want to be able to build a sequence of instances of this structure. First of all, we embed
For this example, it would be logical to place it
Okay, and now let's create some instances:
And now, one more important point: create a list itself , which can be either empty or non-empty. This is just an instance of the same structure
When the list is empty, both its pointers to the previous and next items point to itself
Now we can organize the list as follows:
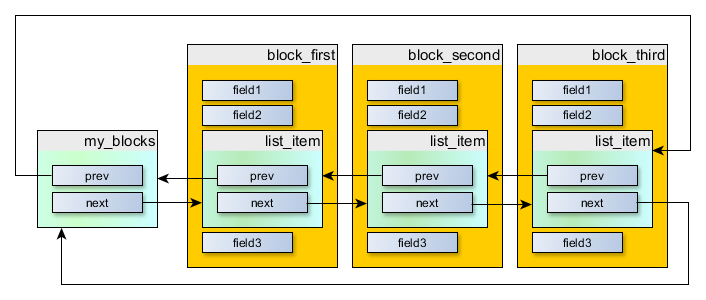
It can be created using code like the following:
This is excellent, but from the above, it is clear that we still have a list of
There is a special macro for this:
So having a pointer to
Now we can, for example, bypass all the elements in the list
This code works, but it is somewhat confused and overloaded with implementation details of the list. It is better to have a special macro to bypass the lists:
Then we can hide all the details and go around the list of our copies
In summary, this is a fairly convenient way to create lists of objects. And, of course, we can include the same object in several lists: for this, the structure must have several built-in instances
After I posted a link to the original article (English) on Hacker News , one of the readers asked the question: why linked lists are implemented by embedding it
The question is interesting, so I decided to include the answer in the article itself:
TNeo never allocates memory from the heap: it operates only with objects, pointers to which are passed as parameters to one or another kernel service. And this is, in fact, very good: often, embedded systems do not use a bunch at all, because her behavior is not sufficiently deterministic.
So, for example, when a task goes into waiting for a mutex, this task is added to the list of tasks waiting for this particular mutex, and the complexity of this operation is O (1), i.e. it is always executed in constant (and, by the way, short) time.
If we use the approach with
Both options are unacceptable. Therefore, the version with embedding is used and, by the way, the exact same approach is used in the Linux kernel (see the book “Linux Kernel Development” by Robert Love). And almost all the helper macros (to bypass the lists) were taken from the Linux kernel, with a few changes: at a minimum, we cannot use GCC-specific language extensions, for example
As already mentioned, TNeo uses lists intensively:
Tasks or streams are the most important part of the system: after all, this is exactly what RTOS does exist for. In the context of TNeo and other RTOS for relatively simple microcontrollers, a task is a subroutine that runs (as if) in parallel with other tasks.
Generally speaking, I prefer the term “thread” (thread), but TNKernel uses the term “task” (task), so TNeo also uses the term task to maintain compatibility. In this article, I use both terms in the same sense.
Each existing task in the system has its own descriptor:,
The first element of the task descriptor is a pointer to the top of the task stack:
There are two pointers in the kernel: to the task currently being executed, and to the next task that needs to be started.
In src / core / internal / _tn_sys.h :
As can be seen from the comments, if they point to different descriptors, then the context should be switched as soon as possible.
Tasks have different priorities. The maximum number of available priorities is determined by the dimension of the processor word: on 16-bit microcontrollers, we have 16 priorities, and on 32-bit ones - 32. Why this will be clear later, but, generally speaking, for our applications I never needed more, than 5 or 6 priorities.
For each priority, there is a linked list of ready-to-run tasks that have this priority.
In src / core / internal / _tn_sys.h :
Where
And the task descriptor has an instance
The core also has a bitmask (one word size), where each bit corresponds to one priority. If the bit is set, this means that there are tasks in the system that are ready to start and have a corresponding priority:
So, when the kernel needs to determine which task it is necessary to transfer control to, it executes an architecture - specific find-first-set instruction for
Of course, when a task enters or exits the Runnable state (ready to run), it serves the corresponding bit in
Recall that when a task is not currently running, its context (the value of all registers, plus the address in program memory from which the task should continue execution) is stored in its stack. And
For each core architecture supported (MIPS, ARM Cortex-M, etc.) there is a specific contest structure, i.e. exactly how all these registers are placed on the stack. When a task has just been created and is preparing to start, the beginning of its stack is filled with an “initialization” context, so that when the task finally gets control, this initialization context is restored. Thus, each task runs in an isolated, clean environment.
A task can be in one of the following states:
When a task goes out of a state or, on the contrary, enters it, there is a certain set of actions that must be performed. For example:
The fact is that when a task, for example, exits the Runnable state, we don’t need to worry about the new state that the task goes to: Wait? Suspended? Dormant? It does not matter: in any case, we must always remove it from the launch queue, and perform the remaining mandatory actions.
A simple and reliable way to do this is to write three functions for each state:
So in the src / core / tn_tasks.c file we have the following functions:
And when we need to transfer a task from one state to another, it usually boils down to the following:
And we can be sure that all internal affairs will be settled. Is it cool?
There is one thing that a task needs to perform: a space for the stack. So, before a task can be created, we need to allocate an array that will be used as a stack for this task, and pass this array along with the rest of the things to
The kernel sets the top of the task stack at the beginning of this array (or at the end — depending on the architecture), and puts the task in the Dormant state. At the moment, it is not yet ready to launch. When the user calls
Now the scheduler will take care of this task, and run it when needed.
Let's take a look at how tasks get started.
The exact sequence of actions required to run a task, of course, depends on the architecture. But, as a general idea, the kernel acts as follows:
How exactly the kernel transfers control to the task is completely dependent on the architecture. For example, on MIPS, you need to save the program counter of the task in the EPC (Exception Program Counter) register, and execute the instruction
The process, when the kernel suspends the execution of the current task and transfers control to the next task, is called “context switching”. This procedure is always performed in a special ISR that has the lowest priority. So, when you need to switch the context, the kernel sets the corresponding interrupt bit. If a user task is currently running, then the ISR, which switches the context, is called by the processor immediately. If this bit is set from some other ISR (regardless of the interrupt priority), then the context switch will be triggered later: when all the ISRs currently being executed return control.
Of course, the specific interrupt that is used to switch the context depends on the architecture. For example, to use PIC32 Core Software Interrupt 0. there is a special exception provided for OS context switching on the Cortex-M on ARM:
When the core ISR switching context is invoked, it does the following:
Context switching occurs when a task with a higher priority than the current task becomes ready to be executed; or when the current task goes to the Wait state.
For example, suppose we have two tasks: a low-priority Transmitter and a high-priority Receiver. Receiver is trying to get a message from the queue, and since the queue is empty, the task goes to the Wait state. It is no longer available for execution, so the kernel shifts to the low-priority Transmitter task.
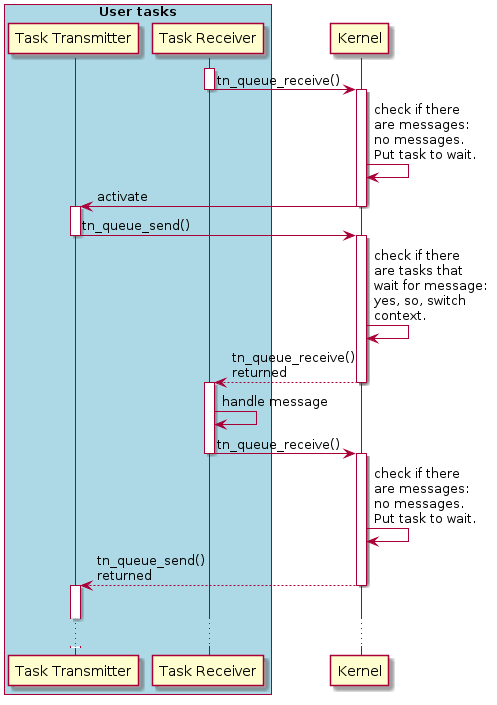
As you can see from the diagram, when the low-priority task Transmitter sends a message calling the service
Thus, the system is very responsive: if you set the correct priorities of tasks, then the events are processed very quickly.
TNeo has one special task: Idle. It has the lowest priority (user tasks cannot have such a low priority), and it should always be ready to start, so it
An application can implement a callback function that will be called from the Idle task all the time. This can be used for various useful purposes:
Since The Idle task must always be ready to start, it is forbidden to call any kernel services from this callback that can transfer the task to the Wait state.
The kernel must have an idea of the time. Two schemes are available: static tick and dynamic tick .
A static tick is the simplest way to implement timeouts: we need some kind of hardware timer that will generate interrupts at regular intervals. In this article, this timer will be called the system timer . The period of this timer is user defined (I always used 1 ms, but, of course, you can set an arbitrary period). In the ISR of this timer, we just need to call a special kernel service:
Every time when it
The simplest implementation of timers can look like this: we have a linked list with all active timers, and for each system tick we go through the entire list of timers by performing the following actions for each timer:
This approach has significant drawbacks:
The last item may not be so important in embedded systems, because it is unlikely that anyone would need such a large number of timers; but the first point is very significant: we definitely want to be able to add (or reconfigure) a timer from the timer callback.
So in TNeo, a more cunning approach is applied. The basic idea is taken from the Linux kernel, but the implementation is much simpler because: (1) embedded systems have significantly fewer resources than the machines for which Linux is written, and (2) TNeo does not need to scale as well as Linux should scale. You can read about the implementation of timers in Linux in the book Linux Device Drivers, 3rd edition:
This book is available to everyone at the link: http://lwn.net/Kernel/LDD3/
So, we proceed to the implementation of timers in TNeo.
We have a custom value of N, which should be a power of two; typical values are 4, 8, or 16. And there is an array of lists (so-called tick lists), this array consists of N elements. That is, we have N tick-lists.
If the timer expires after the number of system ticks from 1 to (N - 1), then this timer is added to one of these tick lists. The tick-list number is calculated simply by overlaying the corresponding mask with a timeout (which is why N must be a power of two). If the timer expires later, then it is added to the “generic” list.
The mask, of course, corresponds to N: for example, when N = 4, the mask is used
Each N-th system tick, the kernel passes through all the timers from the "general" list, and for each timer performs the following actions:
And for each system tick, we go through one corresponding tick-list, and unconditionally execute callbacks of all timers from this list. This solution is more efficient than the simplest one discussed above: we have to go through the entire list of timers only 1 time in N ticks, but in other cases, we simply unconditionally shoot all the timers, the list of which has already been prepared.
The attentive reader may wonder: why do we use only (N - 1) tick-lists, when we actually have N lists? This is due to the fact that we just want to be able to modify the timers from the timer callbacks. If we used N lists, and the user adds a timer with a timeout equal to N, then the new timer will be added to the list that we are currently passing. This can not be done.
If we use (N - 1) lists, then we guarantee that the new timer cannot be added to the tick-list that we are going through at the moment (by the way, the timer can be removed from this list, but this will not create problems) .
Although this implementation of timers is quite acceptable for many applications, sometimes it is not ideal: if a device spends most of the time without doing anything, instead of constantly being on standby (with reduced consumption), the MCU will have to wake up regularly to process the system tick and go back to sleep. For this, a dynamic tick was implemented .
The basic idea is to get rid of useless calls
To do this, the kernel must be able to communicate with the application:
So, when the dynamic tick mode is active (
For normal operation, the kernel needs the following:
So, before starting the system, the application must allocate arrays for the Idle task stack and for interrupts, provide the Idle callback task (it can be empty), and provide a special callback that must create at least one (and usually just one) user task. This is the first task to be launched, and in my applications I usually call it
B
The kernel does the following:
After that, the system works as usual: a user task takes control and can do everything that any user task can do. Usually, she does the following:
Okay, it seems I should stop at some point: it’s unlikely that I will be able to describe every detail of the implementation in this article, which, frankly, is too big.
I tried to touch on the most interesting topics that are needed to understand the picture as a whole; for other topics, the reader can easily study the source code, which I tried to make really good and understandable. Sources are available: use them !
If you have any questions, ask in the comments.
Usually, when they talk about unit tests, they mean tests run on the host machine. But, unfortunately, the compilers used for embedded systems often contain errors, so I decided to test the kernel right in the hardware. Thus, I can be sure that the kernel works 100% on my device.
Overview of test implementation:
There is a high-priority task “test director”, which creates for itself “working” tasks and various RTOS objects (message queues, mutexes, etc.), and then tells work tasks what to do. For example:
After each step, the test director waits for the workers to do their work, and then checks that everything is going according to plan: checks the status of tasks, their priorities, the last returned values from the kernel services, various properties of objects, etc.
The detailed log is displayed in the UART. Usually, after each step, the following is displayed:
Here is an example of the output log:
If something goes wrong, there will be no “as expected”, but an error and details.
I really tried to simulate all possible situations within a single subsystem (mutexes, queues, etc.), including situations with suspended tasks, remote tasks, remote objects, etc. This helps a lot to keep the core really stable.
OK, there are several reasons.
Firstly, I do not like their license: under license, FreeRTOS is forbidden to compare with other products! Look at the last paragraph of FreeRTOS license :
As far as I know, they added this condition after a very old discussion on the Microchip forum , where people posted graphs comparing several cores, and these graphs were not in favor of FreeRTOS. The author of FreeRTOS stated that the measurements are incorrect , but, no matter how funny, could not provide the "correct" measurements.
So, if I write a kernel that FreeRTOS leaves behind in one or another aspect, I will not be able to write about it. Maybe I do not understand something, but, in my opinion, some kind of nonsense. I do not like these things.
By the way, a few years ago, when my colleagues recommended TNKernel, they said that TNKernel is much faster than FreeRTOS. After I implemented TNeo, out of curiosity, I, of course, made a couple of comparisons, but, unfortunately, I cannot publish them because of the FreeRTOS license.
Secondly, I don’t like its source code either . Maybe I’m just too idealistic, but for me, the real-time core is, to some extent, a special project, and I want it to be as close to the ideal as possible.
Yes, now is the time to check out the TNeo code on GitHub and explain why it sucks. Perhaps this will help me make the kernel even better!
Thirdly, I wanted to have a more or less ready TNKernel replacement.so that I can easily port existing applications to the new kernel. Taking into account the problems in TNKernel under microchip microcontrollers described in the first part of the article, our devices always had the probability of undefined behavior.
And last but not least , working on the core is an extremely exciting experience!
However, FreeRTOS has an undeniable advantage over (possibly) all other similar products: it is ported to a huge number of architectures. Fortunately, I do not need so much.
At the moment, I ported to TNeo all existing applications that previously worked on TNKernel: on-board computers, chargers, etc. Works flawlessly.
I also presented the core at the annual Microchip MASTERS 2014 seminar, the head of the StarLine development department became interested and asked me to port the core to the Cortex-M architecture. Now it is already ready for a long time, and the core is used in their latest products.
TNeo is a thoroughly tested replacement RTOS for 16-bit and 32-bit open source microcontrollers.
Project posted on GitHub: TNeo .
At the moment, the kernel is ported to the following architectures:
Full documentation is available in two versions: html and pdf.
My original article in English: How I ended up writing new real-time kernel . Since the author of the original article is myself, then, with your permission, I did not place this article in the category of "translation" .
The processors used in our products are mainly 16- and 32-bit Microchip microcontrollers with 8 to 32 kB RAM, and 128 to 512 kB RAM, without MMU. Sometimes, for the most simple devices, even more modest 8-bit chips are used.
')
Obviously, we have no (reasonable) chance of using the Linux kernel. So we need some RTOS (Real-Time Operating System). There are even people who do not use any OS in microcontrollers, but I do not consider this a good practice: if the iron allows me to use the OS, I use it.
A few years ago, when we were switching from 8-bit to the more powerful 16-bit microcontrollers, my colleagues, who were much more experienced than I, recommended the preemptive RTOS TNKernel . So this is the OS that I used in different projects for a couple of years.
Not that I was very pleased with it: for example, there are no timers in it. And it does not allow the thread to wait for messages from several queues at once. And there is no software control over stack overflow (this really strained). But she worked, so I continued to use it.
How does the forcing OS work
Just to make sure that we understand each other, I will make a brief overview of how the preemptive OS works in principle. I apologize if the things I present here are too trivial for the reader.
Run multiple threads
Microcontrollers are "single-threaded": they can execute only one instruction at a time (of course, there are multi-core processors, but now this is not about that). To run multiple threads on a single core processor, we need to switch between threads, so the user feels that they are running in parallel.
This is what the OS is all about in the first place: it switches control between threads. How exactly does she do it?
The microcontroller has a set of registers. Since microcontrollers are single-threaded, this set of registers belongs to only one thread. For example, when we find the sum of two numbers:
//-- assume we have two ints: a and b int c = a + b; In fact, something like the following is happening (of course, the specific sequence of actions depends on the architecture, but in general the idea remains the same):
# the MIPS disassembly: LW V0, -32744(GP) # a RAM V0 LW V1, -32740(GP) # b RAM V1 ADDU V0, V1, V0 # V1 V0 , V0 SW V0, -32496(GP) # V0 RAM ( c) There are 4 actions. Since in a preemptive OS, one thread can force out another thread at any time, then, of course, this can happen in the middle of this sequence. Imagine that another thread pushes the current one after the values for summation have been loaded into the V0 and V1 registers. The new thread has its own business and, therefore, it uses these registers as it needs. Of course, the two streams should not interfere with each other, so that when the first thread gets control again, the values of the V0 and V1 registers (and others) should be as they were before crowding out.
So, when we switch from flow A to flow B, first of all we have to save the values of all the registers of flow A, then restore the values of all the registers of flow B. And only then the flow B gets control, and continues to work.
So a more accurate flow switching diagram will look like this:
When you need to switch from one thread to another, the kernel receives control, performs the necessary service actions (at least, saves and restores the values of the registers), and then control is transferred to the next thread.
Where exactly are the values of the registers for each thread? Very often, this is a thread stack.
Flow stack
In modern operating systems, the (user) stack grows dynamically thanks to the MMU: the more the thread needs, the more it gets (if the kernel allows it). But the microcontrollers I work with do not have this luxury: all RAM is statically mapped to the address space. So each thread gets its some RAM, which is used under the stack; and if the thread uses more stack than it was allocated, then this leads to memory corruption and, therefore, to incorrect operation. In fact, the stack space for each thread is just an array of bytes.
When we decide how much stack each particular thread needs, first we just figure out how much it may need it, and take it with some margin. For example, if it is a deeply nested GUI stream, it may require several kilobytes, but if it is a small stream that processes user input, then a few hundred bytes may suffice.
Let's assume that we have three threads, and their stack consumption is as follows:
As I have already indicated, the set of register values for each thread is saved to the stack of that thread. This set of register values is called a thread context . The following diagram reflects this (the active stream is indicated by an asterisk):
Notice that the active thread (thread A) has no context saved to the stack. The stack pointer in the microcontroller points to the top of user data stream A, and the entire set of registers of the microcontroller belongs to stream A (in fact, there may be special registers that are not related to the stream, but this does not interest us now).
When the kernel decides to switch control from thread A to thread B, it does the following:
- Saves the values of all registers to the stack (that is, to the stack of thread A);
- Switches the stack pointer to the top of the thread B stack;
- Restores the values of all registers from the stack (that is, from the stack of thread B).
After that, we have the following:
And stream B continues to go about its business.
Interruptions
We have not yet touched on a very important topic: interruptions.
An interrupt is when a thread currently executing stops (most often, due to an external event), the processor switches to something else for a while (to interrupt processing), and then returns to the interrupted thread. An interrupt can be generated at any time, and we need to be ready for this.
Microcontrollers used for embedded systems usually have quite a lot of peripherals: timers, transceivers (UART, SPI, CAN, etc.), ADCs, etc. This periphery can generate interrupts when a certain event occurs: for example, the UART periphery can generate an interrupt when a new byte is received, so the program can save it somewhere. Timers generate an overflow interrupt, so the program can use this for some periodic tasks, etc.
The interrupt handler is called ISR (Interrupt Service Routine).
Interrupts can have different priorities: for example, when a low priority interrupt is generated, the thread being executed is suspended, and the ISR gets control. Now, if a high-priority interrupt is generated, then the current ISR, again, is suspended, and the ISR of the new interrupt gets control. Obviously, when it completes, the first ISR continues its work, and when it completes, then, as a result, control is transferred back to the interrupted flow.
There are short periods of time when interrupts are not allowed: for example, if we process some data that may change in the ISR. If we process this data in several steps, the interruption can occur in the middle of processing and change the data. As a result, the stream will process non-integral data, which leads to incorrect operation of the program.
These short periods of time are called “critical sections”: when we enter a critical section, we prohibit interrupts, and when we exit it, we allow interrupts back. That is, if some interrupt is generated inside the critical section, then the ISR will be called only at the moment of exiting it (when the interrupts are enabled).
Very interesting question: where to save the ISR stack?
Interrupt stack
In general, we have two options:
- Use the stack of the thread that was interrupted;
- Use a separate stack for interrupts.
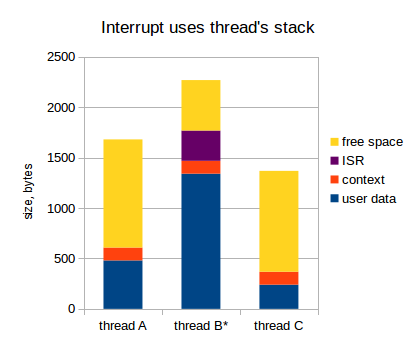
If we use the stack of the interrupted thread, it looks like this (in the diagram below, flow B is interrupted):
When the interrupt is generated:
- The context of the current thread is saved to the thread stack (so that when the ISR is completed, we can immediately switch to another thread);
- ISR does its work (handles interruption);
- If you need to switch to another thread, switch (at least, modify the stack pointer);
- The thread context is restored from the stack;
- The flow continues its work.
This can work quite quickly, but in the context of embedded systems, where our resources are very limited, this approach has a significant drawback. Guess exactly how?
Remember that an interrupt can occur at any time, so obviously we cannot know in advance which thread will be active when the interrupt happens. So, when we estimate the stack size for each thread, we must assume that all existing interrupts can occur in this thread, given their worst nesting. This can significantly increase the size of stacks for all streams: 1 KB is easy, and maybe more (it depends on the application, of course). For example, if in our application there are 7 threads, then the required RAM size for interrupts is 1 * 7 = 7 KB. If our microcontroller has only 32 kb of RAM (and this is already a rich microcontroller), then 7 kb is 20%! Oh shi ~.
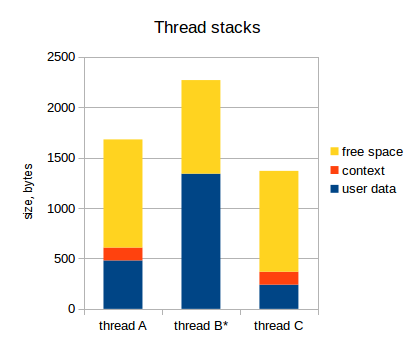
In total, the stack of each thread should contain the following:
- Own data flow;
- Flow context (values of all registers);
- The data of all ISRs with the worst nesting.
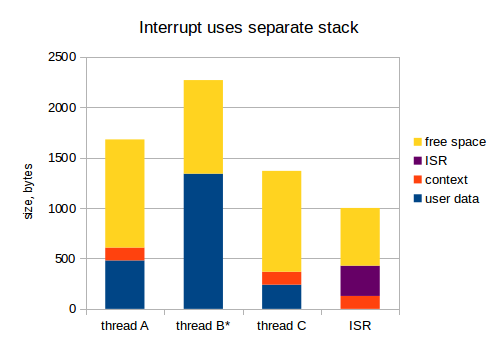
Ok, move to the next option when we use a separate stack for interrupts:
Now, 1 kB for the ISR from the previous example should be allocated only once. I think this is a much more competent approach: in embedded systems, RAM is a very expensive resource.
After such a superficial overview of the principles of RTOS, go on.
TNKernel
As I indicated at the beginning of the article, we used TNKernel for our development on 16-bit and 32-bit microcontrollers.
Unfortunately, the author of the port of TNKernel for PIC32 , Alex Borisov, used the approach when interrupts use the stack of the interrupted thread. It wastes a lot of RAM in vain and does not make me very happy, but otherwise TNKernel looked good: it is compact and fast, so I continued to use it. Until the day of X, when I was very surprised to learn that in fact everything is much worse.
Fail TNKernel under PIC32
I was working on another project: a device analyzing an analog signal from a car plug and allowing the user to see some parameters of this signal: duration, amplitude, etc. Since the signal changes rapidly, we need to measure it often enough: once every 1 or 2 microseconds.
For this task, the Microchip PIC32 processor (with the MIPS core) was chosen.
The task should not be very difficult, but one day I had problems: sometimes, when the device started measuring, the program fell in a completely unexpected place. “It must be the case of a tainted memory,” I thought, and I was very upset because the process of finding errors related to memory corruption can be long and completely non-trivial: as I said, there is no MMU, and all RAM is available to all threads in the system, so if one of the threads gets out of control and corrupts the memory of another thread , the problem can manifest itself very far from the actual place with an error.
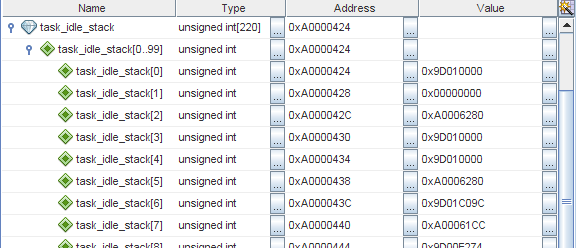
I have already said that TNKernel does not have software control over stack overflow, so when there is a suspicion of memory corruption, first of all it is worth checking whether the stack of any thread is full. When a thread is created, its stack is initialized to a specific value (in TNKernel under PIC32, it’s just
0xffffffff ), so we can easily see if the end of the stack is dirty. I checked, and indeed, the idle thread stack is clearly full:On MIPS, the stack grows down, so
task_idle_stack[0] is the last available word in the idle thread stack.Well, this is already something. But the fact is that the stack for this stream was allocated with a large margin: when the device works normally, only about 300 bytes from 880 are used! There must be some wild mistake that so hard overflows the stack.
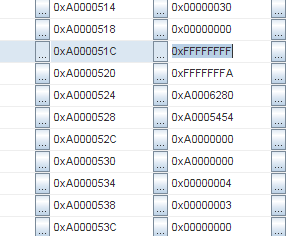
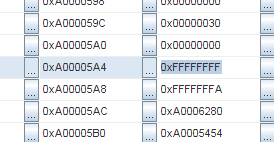
Then I began to study memory more carefully, and it became clear that the stack was filled with repeating patterns. See: sequence
0xFFFFFFFF, 0xFFFFFFFA, 0xA0006280, 0xA0005454 :And the same sequence again:
Addresses
0xA000051C and 0xA00005A4 . The difference is 136 bytes. We divide by 4 (word size), these are 34 words.Hmm, 34 words ... This is just the size of the context in MIPS! And the same pattern repeats over and over again. So it seems that the context has been saved several times in a row. But ... How can this be ?!
Unfortunately, it took me a long time to figure everything out. First of all, I tried to examine the saved context in more detail: among other things, there should be an address in the program memory, where the interrupted thread should resume work later. On the PIC32, the program memory is mapped to a region from
0x9D000000 to 0x9D007FFF , so these addresses are easily distinguishable from the rest of the data. I took these addresses from a saved context: one of them was 0x9D012C28 . We look into the disassembler: 9D012C04 AD090000 SW T1, 0(T0) 9D012C08 8FA80008 LW T0, 8(SP) 9D012C0C 8FA9000C LW T1, 12(SP) 9D012C10 01000013 MTLO T0, 0 9D012C14 01200011 MTHI T1, 0 9D012C18 8FA10010 LW AT, 16(SP) 9D012C1C 8FA20014 LW V0, 20(SP) 9D012C20 8FA30018 LW V1, 24(SP) 9D012C24 8FA4001C LW A0, 28(SP) 9D012C28 8FA50020 LW A1, 32(SP) # <- 9D012C2C 8FA60024 LW A2, 36(SP) 9D012C30 8FA70028 LW A3, 40(SP) 9D012C34 8FA8002C LW T0, 44(SP) 9D012C38 8FA90030 LW T1, 48(SP) 9D012C3C 8FAA0034 LW T2, 52(SP) 9D012C40 8FAB0038 LW T3, 56(SP) 9D012C44 8FAC003C LW T4, 60(SP) 9D012C48 8FAD0040 LW T5, 64(SP) 9D012C4C 8FAE0044 LW T6, 68(SP) 9D012C50 8FAF0048 LW T7, 72(SP) 9D012C54 8FB0004C LW S0, 76(SP) 9D012C58 8FB10050 LW S1, 80(SP) 9D012C5C 8FB20054 LW S2, 84(SP) 9D012C60 8FB30058 LW S3, 88(SP) 9D012C64 8FB4005C LW S4, 92(SP) 9D012C68 8FB50060 LW S5, 96(SP) 9D012C6C 8FB60064 LW S6, 100(SP) 9D012C70 8FB70068 LW S7, 104(SP) 9D012C74 8FB8006C LW T8, 108(SP) 9D012C78 8FB90070 LW T9, 112(SP) 9D012C7C 8FBA0074 LW K0, 116(SP) 9D012C80 8FBB0078 LW K1, 120(SP) 9D012C84 8FBC007C LW GP, 124(SP) 9D012C88 8FBE0080 LW S8, 128(SP) 9D012C8C 8FBF0084 LW RA, 132(SP) 9D012C90 41606000 DI ZERO 9D012C94 000000C0 EHB 9D012C98 8FBA0000 LW K0, 0(SP) 9D012C9C 8FBB0004 LW K1, 4(SP) 9D012CA0 409B7000 MTC0 K1, EPC This characteristic sequence from LW (Load Word) from addresses relative to SP (Stack Pointer) is a context recovery procedure. Now it is clear that the thread was preempted when the context was restored from the stack. Well, this can happen because of an interruption, but why so many times in a row? I don't even have so many interrupts in the system.
Before that, I just used TNKernel without a clear understanding of how it works, because it just worked. So I was even somewhat scared to go deep into the core. But this time, I had to.
Context switch in TNKernel under PIC32
We have already discussed the context switching process in general, but for now, let's refresh this topic and add some details of a specific implementation (TNKernel).
When the kernel decides to switch the context from thread A to thread B, it does the following:
- Saves the values of all registers to the stack (that is, to the stack of thread A);
- Disable interrupts ;
- Switches the stack pointer to the top of the thread B stack;
- Toggles pointer to active stream descriptor (to stream B descriptor)
- Enable interrupts ;
- Restores the values of all registers from the stack (that is, from the stack of thread B).
As you can see, there is a short critical section, while the kernel operates with pointers to the thread descriptor and to the top of the stack: otherwise a situation may occur when an interrupt is generated between these actions, and the non-integrity of the data, of course, leads to incorrect operation.
Interrupts in TNKernel under PIC32
In TNKernel, under PIC32, there are two types of interrupts:
- System interrupts: they can cause kernel services, which can lead to context switching immediately after the execution of an ISR. When such an interrupt is called, the kernel saves full context to the stack of the current thread.
- User interrupts: they cannot call kernel services. The kernel takes no action when this interrupt is generated.
Now we are only interested in system interrupts. And TNKernel has a restriction for this type of interrupt: all System Interrupts in the application must have the same priority, so these interrupts cannot be nested.
As a small reminder, this is what happens when an interrupt is generated:
- The context of the current thread is saved to the thread stack;
- ISR gets control.
Now the ISR is active, and using the stack looks like this:
As already mentioned, this approach significantly increases the required stack size for threads: each thread must be large enough to accommodate the following:
- Own data flow;
- Flow context (values of all registers);
- The data of all ISRs with the worst nesting.
The need to multiply the ISR stack by the number of threads is not the most pleasant thing, but, generally speaking, with this I was ready to live.
Interrupt at the time of context switching
And what happens if the interrupt is generated during the context switch process, i.e. while the context of the current thread is saved to the stack or restored from the stack?
I think you guessed it: interrupts are not prohibited in the process of saving / restoring the context, the context will be saved twice . Here is:
So, when the kernel decides to switch from thread B to thread A, this is what happens:
- The context is saved to thread stack B;
- In the middle of this process, an interrupt occurs;
- In thread stack B, space is allocated for another context, and the context is stored there.
- ISR gets control, does its work and ends
- When the ISR is complete, the kernel looks to which thread the control should be transferred (this is flow A: remember, we wanted to switch to thread And before the interruption occurred)
- We prohibit interruptions
- Switch the stack pointer and the pointer to the current thread handle
- Allow interrupts
- Context is restored from the stack (i.e., from the top of task A stack)
We get the following picture:
See: the context is saved twice in the stack of thread B. In fact, this is not a disaster if the stack is not full, since this double-saved context will be restored twice as soon as thread B has control. For example, suppose that thread A goes into waiting for something, and the kernel switches control back to thread B:
- The context is saved to thread stack A;
- We prohibit interrupts, switch the stack pointer, etc., enable interrupts;
- The context is restored from the stack of thread B.
Now we, in fact, have returned at that moment when the context was saved to thread stack B before switching to thread A. So we just continue to keep the context:
- We finish saving the context to the stack of thread B;
- We take the stream that needs to be activated (in fact, it is already activated: stream B);
- Restoring context back.
After that, the flow continues to work, as if nothing had happened:
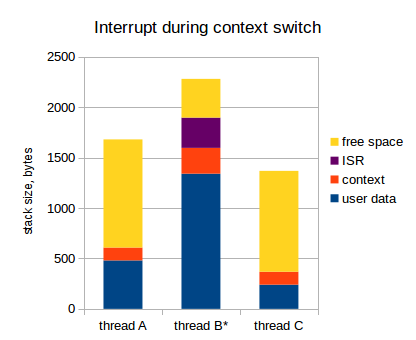
As you can see, in fact, nothing broke, but we have to draw an important conclusion from this study: our assumption that it should accommodate the context of each stream was wrong . At a minimum, it should contain two contexts, not one.
As you remember, all system interrupts in TNKernel must have the same priority, so that they cannot be nested: this means that the context cannot be saved more than twice.
If so, then the final conclusion: the stack of each thread should contain the following:
- Own data flow;
- Flow context (values of all registers);
- The second context in case the interruption occurs at the moment the context is saved;
- The data of all ISRs with the worst nesting.
Oh ... another 136 bytes for each stream. Again, multiply by the number of threads: for 7 threads, this is almost 1 kilobyte: another 3% from 32 KB.
OK. Good.I, probably , would agree on this situation, but our final conclusion, in fact, it is not final. All the more worse.
Digging deeper
Let's examine the process of saving dual context more deeply: even after our recent research, we still cannot explain how it happened that the context was saved on the thread stack many times: when the interrupt is generated, the current interrupt level of the processor is increased (to the priority of the generated interrupt) ), and if another system interrupt occurs, it will be processed after the current ISR returns control.
Take another look at this diagram: the ISR has already returned control, and we switched to stream A:
At this moment, the interrupt level of the processor is again lowered, and the context is saved to thread stack B twice .
Guess what's next?
That's right: when we switch back to thread B, and while its context is restored, another interrupt can occur . Consider:
Yes, the context has already been saved to the thread stack three times. And what's worse, it can even be the same interrupt: the same interrupt can save the context to the thread's stack several times .
So, if you are so unlucky that an interrupt will be generated periodically, and with the same frequency with which threads will switch back and forth, then the context will be stored in the thread stack over and over again, which ultimately leads to stack overflow.
This was clearly not taken into account by the author of the TNKernel port under PIC32.
And this is exactly what happened with my device, which measured the analog signal: the ADC interrupt was generated with exactly this “successful” frequency. This is what happened:
- The periphery of the ADC completes the next measurement, and generates an interrupt;
- ISR , , , - ;
- ISR , (.. , );
- ;
- , - . , .
- 2.
Of course, this is my cant that ADC interrupts are generated so often, but the behavior of the system is completely unacceptable. Correct behavior: my threads stop receiving control (because there is no time) until such frequent interrupt generation is stopped. The stack should not be filled with a bunch of saved contexts, and when interrupts are no longer generated so often, the system quietly continues its work.
And one more consequence: even if we don’t have such periodic interruptions, there’s still a non-zero probability that the different interruptions that exist in the application will occur at such unsuccessful moments that the context will be saved again and again. Embedded systems are often designed for continuous operation over a long period of time (months and years): for example, car alarms, on-board computers, etc. And if the operating time of the device will tend to infinity, then the probability of such a development of events will tend to unity. Sooner or later, it happens. Of course, this is unacceptable, so it is impossible to leave the current state of affairs.
Good: at least now I know the cause of the problems. Next question: how to eliminate this cause?
Perhaps the fastest and dirtiest hack is to simply disable interrupts for the duration of the save / restore context. Yes, this will eliminate the problem, but this is a very, very bad decision: the critical sections should be as short as possible, and prohibiting interruptions for such long periods of time is hardly a good idea.
A much better solution is to use a separate stack for interrupts.
We are trying to improve TNKernel
There is another TNKernel port under PIC32 by Anders Montonen, and it uses a separate stack for interrupts. But this port does not have some convenient buns that are present in the port of Alex Borisov: convenient Sishny macros for announcing system interrupts, services for working with system ticks, and others.
So I decided to fork it and implement what I need. Of course, in order to make such changes in the core, I needed to understand how it works. And the more I studied the TNKernel code, the less I liked it. TNKernel gives the impression of a project written on the knee: a lot of duplicate code and there is no integrity.
Examples of poor implementation
Violation of the rule “One entry point, one exit point”
The most common example found everywhere in the kernel is a code like the following:
int my_function(void) { tn_disable_interrupt(); //-- do something if (error()){ //-- do something tn_enable_interrupt(); return ERROR; } //-- do something tn_enable_interrupt(); return SUCCESS; } If we have several operators
return, and even more so if we need to perform some actions before returning, such a code is a guarantee of problems. It would be much better to rewrite it as follows: int my_function(void) { int rc = SUCCESS; tn_disable_interrupt(); if (error()){ rc = ERROR; } else { //-- so something } tn_enable_interrupt(); return rc; } Now, we do not need to remember that before returning it is necessary to enable interrupts. Let the compiler do this work for us.
There is no need to go far for the consequences: here is the function from the last TNKernel 2.7 currently:
int tn_sys_tslice_ticks(int priority,int value) { TN_INTSAVE_DATA TN_CHECK_NON_INT_CONTEXT tn_disable_interrupt(); if(priority <= 0 || priority >= TN_NUM_PRIORITY-1 || value < 0 || value > MAX_TIME_SLICE) return TERR_WRONG_PARAM; tn_tslice_ticks[priority] = value; tn_enable_interrupt(); return TERR_NO_ERR; } See: if incorrect parameters are passed to the function, it returns
TERR_WRONG_PARAM, and interrupts remain prohibited. If we followed the rule of one entry point, one exit point , then this error most likely would not have occurred.Violation of the principle of DRY
(don't repeat yourself)The original TNKernel 2.7 code contains a huge amount of code duplication. A lot of similar things are done in different places through a simple copy.
If we have several similar services (for example, services that send a message: from a stream, from a stream without waiting, or from an interrupt), then these are three very similar functions, in which there are 1-2 lines, without any attempts to generalize things .
Switching between thread states is implemented very inextricably. For example, when we need to move a stream from the Runnable state to the Wait state, it is not enough just to remove one flag and put another: we also need to remove it from the start queue in which the thread was, then, perhaps, find the next thread to start, set the cause wait, add stream to queue for wait (if needed), set timeout (if needed), etc. In TNKernel 2.7, there is no general mechanism for this, for each case the code is written “here and now”.
In the meantime, the correct way to implement these things is to write three functions for each state:
- Enter the stream in the specified state;
- Remove the stream from the specified state;
- Check if the stream is in the given state.
Now, when we need to transfer a stream from one state to another, we usually just need to call two functions: one to output the stream from the old state, and another to enter it in the new state. Simple and reliable.
As a result of regular violation of the DRY rule, when we need to change something, we need to edit the code in several places. Needless to say, this is a vicious practice.
In short, TNKernel has a bunch of things that need to be implemented differently.
I decided to refactor it thorough. To make sure that I didn't break anything, I started implementing unit tests for the kernel. And it soon became clear that TNKernel was not tested at all: there are unpleasant bugs in the core itself!
For specific information about found and fixed bugs, seeWhy reimplement TNKernel .
Meet: TNeo
At a certain point, it became clear that what I was doing went far beyond the framework of “refactoring”: I, in fact, rewrote almost everything in its entirety. Plus, there are some things in the TNKernel API that have strained me for a long time, so I slightly changed the API; and also there are things that I lacked, so I implemented them: timers, program control of stack overflow, the ability to wait for messages from several queues, etc.
I thought about the name for a long time: I wanted to designate a direct link with TNKernel, but add something fresh and cool. So the first name was: TNeoKernel.
But after a while, it naturally shrunk to concise TNeo.
TNeo has a standard feature set for RTOS, plus some bonuses that are not everywhere. Most features are optional, so you can turn them off, thereby saving memory and slightly increasing performance.
- Tasks , or threads: the most basic feature for which the kernel was written at all;
- Mutexes : objects to protect shared resources:
- Recursive mutexes : optional, mutexes allow nested locking
- Deadlock detection : if a deadlock occurs, the kernel can notify you by calling an arbitrary callback function
- Semaphores : objects to synchronize tasks
- Fixed-size memory blocks : a simple and deterministic memory manager
- : , , , ;
- : - : ,
- : FIFO ,
- : .
- : RAM
- : ,
- Dynamic tick : if the system has nothing to do, then you can not be distracted by the periodic processing of system ticks
- Profiler : allows you to find out how much time each of the threads was executed, the maximum execution time for a row, and other information
Project posted on GitHub: TNeo .
At the moment, the kernel is ported to the following architectures:
- ARM Cortex-M cores: Cortex-M0 / M0 + / M1 / M3 / M4 / M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX / PIC24 / dsPIC
Full documentation is available in two versions: html and pdf.
TNeo implementation
Of course, it is very difficult to cover the implementation of the entire kernel in one article; instead, I will try to remember what was not clear to me myself, and focus on these things.
But above all, we need to consider one internal structure: a linked list.
Related Lists
A linked list is a well-known data structure, and the reader is likely already familiar with it. However, for completeness, let's look at the implementation of linked lists in TNeo.
Related lists are used throughout TNeo. More specifically, a circular bidirectional linked list is used. The structure in C is as follows:
/** * Circular doubly linked list item, for internal kernel usage. */ struct TN_ListItem { /// /// pointer to previous item struct TN_ListItem *prev; /// /// pointer to next item struct TN_ListItem *next; }; It is declared in the src / core / tn_list.c file .
As you can see, the structure contains pointers to instances of the same structure: the previous one and the next one. We can organize a chain of such structures, so that they will be linked as follows:
This is great, but there is not a lot of benefit from this: we would like to have some useful data in each object, right?
The solution is to embed
struct TN_ListItemanother structure, the instances of which we want to link. For example, suppose we have a structure MyBlock: struct MyBlock { int field1; int field2; int field3; }; And we want to be able to build a sequence of instances of this structure. First of all, we embed
struct TN_ListItemit inside.For this example, it would be logical to place it
struct TN_ListItemat the beginning struct MyBlock, but just to emphasize that it struct TN_ListItemcan be anywhere, not only at the beginning, let's put it in the middle: struct MyBlock { int field1; int field2; //-- say, embed it here. struct TN_ListItem list_item; int field3; }; Okay, and now let's create some instances:
//-- blocks to put in the list struct MyBlock block_first = { /* ... */ }; struct MyBlock block_second = { /* ... */ }; struct MyBlock block_third = { /* ... */ }; And now, one more important point: create a list itself , which can be either empty or non-empty. This is just an instance of the same structure
struct TN_ListItem, but not embedded anywhere: //-- list head struct TN_ListItem my_blocks; When the list is empty, both its pointers to the previous and next items point to itself
my_blocks.Now we can organize the list as follows:
It can be created using code like the following:
//-- , , // . . my_blocks.next = &block_first.list_item; my_blocks.prev = &block_third.list_item; block_first.list_item.next = &block_second.list_item; block_first.list_item.prev = &my_blocks; block_second.list_item.next = &block_third.list_item; block_second.list_item.prev = &block_first.list_item; block_third.list_item.next = &my_blocks; block_third.list_item.prev = &block_second.list_item; This is excellent, but from the above, it is clear that we still have a list of
TN_ListItem, not of MyBlock. But the idea is that the offset from the beginning MyBlockto the list_itemsame is the same for all instances MyBlock. So if we have a pointer to TN_ListItem, and we know that this instance is embedded in MyBlock, then we can subtract a certain offset from the pointer, and get a pointer to MyBlock.There is a special macro for this:
container_of()(defined in the src / core / internal / _tn_sys.h file ): #if !defined(container_of) /* given a pointer @ptr to the field @member embedded into type (usually * struct) @type, return pointer to the embedding instance of @type. */ #define container_of(ptr, type, member) \ ((type *)((char *)(ptr)-(char *)(&((type *)0)->member))) #endif So having a pointer to
TN_ListItem, we get a pointer to the external MyBlockas follows: struct TN_ListItem *p_list_item = /* ... */; struct MyBlock *p_my_block = container_of(p_list_item, struct MyBlock, list_item); Now we can, for example, bypass all the elements in the list
my_blocks: //-- loop cursor struct TN_ListItem *p_cur; //-- my_blocks for (p_cur = my_blocks.next; p_cur != &my_blocks; p_cur = p_cur->next) { struct MyBlock *p_cur_block = container_of(p_cur, struct MyBlock, list_item); //-- , p_cur_block MyBlock } This code works, but it is somewhat confused and overloaded with implementation details of the list. It is better to have a special macro to bypass the lists:
_tn_list_for_each_entry()defined in the src / core / internal / _tn_list.h file .Then we can hide all the details and go around the list of our copies
MyBlocklike this: struct MyBlock *p_cur_block; _tn_list_for_each_entry( p_cur_block, struct MyBlock, &my_blocks, list_item ) { //-- , p_cur_block MyBlock } In summary, this is a fairly convenient way to create lists of objects. And, of course, we can include the same object in several lists: for this, the structure must have several built-in instances
struct TN_ListItem: for each list in which it is planned to include this object.After I posted a link to the original article (English) on Hacker News , one of the readers asked the question: why linked lists are implemented by embedding it
struct TN_ListItemin other structures, and not, for example, like this: struct TN_ListItem { TN_ListItem *prev; TN_ListItem *next; void *data; //-- } The question is interesting, so I decided to include the answer in the article itself:
TNeo never allocates memory from the heap: it operates only with objects, pointers to which are passed as parameters to one or another kernel service. And this is, in fact, very good: often, embedded systems do not use a bunch at all, because her behavior is not sufficiently deterministic.
So, for example, when a task goes into waiting for a mutex, this task is added to the list of tasks waiting for this particular mutex, and the complexity of this operation is O (1), i.e. it is always executed in constant (and, by the way, short) time.
If we use the approach with
void *data;, then we have two options:- When we add a new object to some list, the kernel has to allocate an instance somewhere
struct TN_ListItem(from a heap or, possibly, from some pool of objects); - The client code must allocate
struct TN_ListItemindependently (in any way) and transfer it to any kernel service that may need it.
Both options are unacceptable. Therefore, the version with embedding is used and, by the way, the exact same approach is used in the Linux kernel (see the book “Linux Kernel Development” by Robert Love). And almost all the helper macros (to bypass the lists) were taken from the Linux kernel, with a few changes: at a minimum, we cannot use GCC-specific language extensions, for example
typeof(), because TNeo should not be compiled by GCC at all.As already mentioned, TNeo uses lists intensively:
- : (, )
- , ( )
- , ,
- Etc.
()
Tasks or streams are the most important part of the system: after all, this is exactly what RTOS does exist for. In the context of TNeo and other RTOS for relatively simple microcontrollers, a task is a subroutine that runs (as if) in parallel with other tasks.
Generally speaking, I prefer the term “thread” (thread), but TNKernel uses the term “task” (task), so TNeo also uses the term task to maintain compatibility. In this article, I use both terms in the same sense.
Each existing task in the system has its own descriptor:,
struct TN_Taskdeclared in the src / core / tn_tasks.h file . This is a rather large structure.The first element of the task descriptor is a pointer to the top of the task stack:
stack_cur_pt. This fact is actively used by assembler context switching routines: having a pointer to a task handle, we can simply distribute it, and the resulting value will point to the top of the task stack. Pretty comfortable.Current and next tasks
There are two pointers in the kernel: to the task currently being executed, and to the next task that needs to be started.
In src / core / internal / _tn_sys.h :
/// task that is running now extern struct TN_Task *_tn_curr_run_task; /// task that should run as soon as possible (if it isn't equal to /// _tn_curr_run_task, context switch is needed) extern struct TN_Task *_tn_next_task_to_run; As can be seen from the comments, if they point to different descriptors, then the context should be switched as soon as possible.
Task Priorities and Launch Queues
Tasks have different priorities. The maximum number of available priorities is determined by the dimension of the processor word: on 16-bit microcontrollers, we have 16 priorities, and on 32-bit ones - 32. Why this will be clear later, but, generally speaking, for our applications I never needed more, than 5 or 6 priorities.
For each priority, there is a linked list of ready-to-run tasks that have this priority.
In src / core / internal / _tn_sys.h :
/// list of all ready to run (TN_TASK_STATE_RUNNABLE) tasks extern struct TN_ListItem _tn_tasks_ready_list[TN_PRIORITIES_CNT]; Where
TN_PRIORITIES_CNT- user configurable value (of course, it can not be greater than the maximum).And the task descriptor has an instance
struct TN_ListItemthat is added to one of these task lists: /** * Task */ struct TN_Task { /* ... */ /// queue is used to include task in ready/wait lists struct TN_ListItem task_queue; /* ... */ } The core also has a bitmask (one word size), where each bit corresponds to one priority. If the bit is set, this means that there are tasks in the system that are ready to start and have a corresponding priority:
/// bitmask of priorities with runnable tasks. /// lowest priority bit (1 << (TN_PRIORITIES_CNT - 1)) should always be set, /// since this priority is used by idle task which should be always runnable, /// by design. extern volatile unsigned int _tn_ready_to_run_bmp; So, when the kernel needs to determine which task it is necessary to transfer control to, it executes an architecture - specific find-first-set instruction for
_tn_ready_to_run_bmp, and immediately receives the highest priority from all tasks ready for launching. Then, we take the first task from the task list for the corresponding priority, and transfer control to it.Of course, when a task enters or exits the Runnable state (ready to run), it serves the corresponding bit in
_tn_ready_to_run_bmp, which is rather trivial. In general, everything works quickly.Task context
Recall that when a task is not currently running, its context (the value of all registers, plus the address in program memory from which the task should continue execution) is stored in its stack. And
stack_cur_ptrin the task descriptor it indicates exactly the top of this saved context.For each core architecture supported (MIPS, ARM Cortex-M, etc.) there is a specific contest structure, i.e. exactly how all these registers are placed on the stack. When a task has just been created and is preparing to start, the beginning of its stack is filled with an “initialization” context, so that when the task finally gets control, this initialization context is restored. Thus, each task runs in an isolated, clean environment.
Task states
A task can be in one of the following states:
- Runnable: the task is ready to start (this does not mean that the task is actually running at the moment)
- Wait: the task is waiting for something (messages from the queue, mutex, semaphore, etc.)
- Suspended: The task has been suspended by another task.
- Wait + Suspended: the task was in the Wait state, after which it was suspended by another task
- Dormant: the task has not yet been activated after creation, or was destroyed by a call
tn_task_terminate. The next time the task is activated, its previous state will be reset to zero and it will run in a clean environment.
When a task goes out of a state or, on the contrary, enters it, there is a certain set of actions that must be performed. For example:
- Dormant, , ,
- Runnable,
_tn_ready_to_run_bmp, - Runnable, , -
_tn_ready_to_run_bmp, , - Wait, ( ), ,
- When the task exits the Wait state, we remove it from the wait queue (if it was in such a queue), and reset the timer (if it was set)
- Etc.
The fact is that when a task, for example, exits the Runnable state, we don’t need to worry about the new state that the task goes to: Wait? Suspended? Dormant? It does not matter: in any case, we must always remove it from the launch queue, and perform the remaining mandatory actions.
A simple and reliable way to do this is to write three functions for each state:
- Enter the task in the specified state;
- Take the task out of the specified state;
- Check whether the task is in a given state.
So in the src / core / tn_tasks.c file we have the following functions:
void _tn_task_set_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_clear_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_set_waiting( struct TN_Task *task, struct TN_ListItem *wait_que, enum TN_WaitReason wait_reason, TN_TickCnt timeout ) { /* ... */ } void _tn_task_clear_waiting(struct TN_Task *task, enum TN_RCode wait_rc) { /* ... */ } //-- etc. And when we need to transfer a task from one state to another, it usually boils down to the following:
_tn_task_clear_dormant(task); _tn_task_set_runnable(task); And we can be sure that all internal affairs will be settled. Is it cool?
Creating tasks
There is one thing that a task needs to perform: a space for the stack. So, before a task can be created, we need to allocate an array that will be used as a stack for this task, and pass this array along with the rest of the things to
tn_task_create().The kernel sets the top of the task stack at the beginning of this array (or at the end — depending on the architecture), and puts the task in the Dormant state. At the moment, it is not yet ready to launch. When the user calls
tn_task_activate()(or if the flag TN_TASK_CREATE_OPT_STARTwas passed in tn_task_create()), the kernel acts as follows:- Displays a task from the Dormant state: as you already know, at this moment the task stack is initialized with a clean context;
- Enters the task into the Runnable state: as you already know, at this moment the task is placed at the end of the corresponding launch queue.
Now the scheduler will take care of this task, and run it when needed.
Let's take a look at how tasks get started.
Running tasks
The exact sequence of actions required to run a task, of course, depends on the architecture. But, as a general idea, the kernel acts as follows:
- Retrieves the stack pointer from the task handle it points
_tn_next_task_to_runto and sets it as the current stack pointer; - Performs
_tn_curr_run_task = _tn_next_task_to_run;; - Loads the values of all registers from the stack, one by one (remember that the stack pointer has just been set to the top of the task stack). Among other things, the address is also loaded in the program memory where the task should be resumed;
- Sends control to the task.
How exactly the kernel transfers control to the task is completely dependent on the architecture. For example, on MIPS, you need to save the program counter of the task in the EPC (Exception Program Counter) register, and execute the instruction
eret(return from exception). That is, the kernel "deceives" the processor so that it behaves as if it is returned from the "normal" interrupt. After execution eret, the current PC (Program Counter) is set to the value stored in the EPC, and, in fact, the task continues execution.Context switch
The process, when the kernel suspends the execution of the current task and transfers control to the next task, is called “context switching”. This procedure is always performed in a special ISR that has the lowest priority. So, when you need to switch the context, the kernel sets the corresponding interrupt bit. If a user task is currently running, then the ISR, which switches the context, is called by the processor immediately. If this bit is set from some other ISR (regardless of the interrupt priority), then the context switch will be triggered later: when all the ISRs currently being executed return control.
Of course, the specific interrupt that is used to switch the context depends on the architecture. For example, to use PIC32 Core Software Interrupt 0. there is a special exception provided for OS context switching on the Cortex-M on ARM:
PendSV.When the core ISR switching context is invoked, it does the following:
- Saves the values of all registers to the stack of the current task, one after another. Among other things, the address is stored in the program memory at which the task was interrupted;
- When all registers are saved to the stack, the kernel saves the current stack pointer to the current task handle;
- Possibly, performs on-context-switch handler (it is needed for the profiler and for software control over stack overflow, if any of these functions is enabled);
- Then go to the sequence specified in the previous section "Running Tasks".
Context switching occurs when a task with a higher priority than the current task becomes ready to be executed; or when the current task goes to the Wait state.
For example, suppose we have two tasks: a low-priority Transmitter and a high-priority Receiver. Receiver is trying to get a message from the queue, and since the queue is empty, the task goes to the Wait state. It is no longer available for execution, so the kernel shifts to the low-priority Transmitter task.
As you can see from the diagram, when the low-priority task Transmitter sends a message calling the service
tn_queue_send(), this task is pushed out by the core in favor of the high-priority Receiver immediately. So, by the time the tn_queue_send()control returns to Transmitter, many things have already happened:- Context switches to Receiver;
- Receiver receives the message and processes it;
- Receiver tries to get the next message, and goes to the Wait state;
- Context switches back to Transmitter.
Thus, the system is very responsive: if you set the correct priorities of tasks, then the events are processed very quickly.
Idle task
TNeo has one special task: Idle. It has the lowest priority (user tasks cannot have such a low priority), and it should always be ready to start, so it
_tn_ready_to_run_bmpalways has at least one set bit: the bit for the lowest priority of the Idle task. Obviously, the kernel transfers control to this task when there are no other tasks ready to run.An application can implement a callback function that will be called from the Idle task all the time. This can be used for various useful purposes:
- MCU sleep. When the system has nothing to do, it often makes sense to put the processor in sleep to reduce power consumption. Of course, the application must configure some condition on which the processor must exit sleep: most often, this is some kind of interruption;
- Calculate system load. The simplest implementation: simply increment by one the value of a variable in an infinite loop. The faster the value changes, the less load on the system.
Since The Idle task must always be ready to start, it is forbidden to call any kernel services from this callback that can transfer the task to the Wait state.
Timers
The kernel must have an idea of the time. Two schemes are available: static tick and dynamic tick .
Static tick
A static tick is the simplest way to implement timeouts: we need some kind of hardware timer that will generate interrupts at regular intervals. In this article, this timer will be called the system timer . The period of this timer is user defined (I always used 1 ms, but, of course, you can set an arbitrary period). In the ISR of this timer, we just need to call a special kernel service:
//-- example for PIC32, hardware timer 5 interrupt: tn_p32_soft_isr(_TIMER_5_VECTOR) { INTClearFlag(INT_T5); tn_tick_int_processing(); } Every time when it
tn_tick_int_processing()is called, we say that a system tick has occurred . Inside this function, the kernel checks if it is time to call a callback of some timer, and if it is time, then it calls it.The simplest implementation of timers can look like this: we have a linked list with all active timers, and for each system tick we go through the entire list of timers by performing the following actions for each timer:
- Reduce the timeout value by 1;
- If the new value is zero, then remove this timer from the list (i.e., make the timer inactive), and start the callback timer.
This approach has significant drawbacks:
- We cannot manage timers from callbacks: if we, for example, add a new timer, the list of timers will be modified. But since , ;
- : .
The last item may not be so important in embedded systems, because it is unlikely that anyone would need such a large number of timers; but the first point is very significant: we definitely want to be able to add (or reconfigure) a timer from the timer callback.
So in TNeo, a more cunning approach is applied. The basic idea is taken from the Linux kernel, but the implementation is much simpler because: (1) embedded systems have significantly fewer resources than the machines for which Linux is written, and (2) TNeo does not need to scale as well as Linux should scale. You can read about the implementation of timers in Linux in the book Linux Device Drivers, 3rd edition:
- Time, Delays, and Deferred Work
- Kernel timers
- The Implementation of Kernel Timers
- The Implementation of Kernel Timers
- Kernel timers
This book is available to everyone at the link: http://lwn.net/Kernel/LDD3/
So, we proceed to the implementation of timers in TNeo.
We have a custom value of N, which should be a power of two; typical values are 4, 8, or 16. And there is an array of lists (so-called tick lists), this array consists of N elements. That is, we have N tick-lists.
If the timer expires after the number of system ticks from 1 to (N - 1), then this timer is added to one of these tick lists. The tick-list number is calculated simply by overlaying the corresponding mask with a timeout (which is why N must be a power of two). If the timer expires later, then it is added to the “generic” list.
The mask, of course, corresponds to N: for example, when N = 4, the mask is used
0b0011; when N = 8, a mask is used 0b0111, etc.Each N-th system tick, the kernel passes through all the timers from the "general" list, and for each timer performs the following actions:
- The timeout is reduced by N;
- If the resulting timeout is less than N, then the timer moves to the corresponding tick list.
And for each system tick, we go through one corresponding tick-list, and unconditionally execute callbacks of all timers from this list. This solution is more efficient than the simplest one discussed above: we have to go through the entire list of timers only 1 time in N ticks, but in other cases, we simply unconditionally shoot all the timers, the list of which has already been prepared.
The attentive reader may wonder: why do we use only (N - 1) tick-lists, when we actually have N lists? This is due to the fact that we just want to be able to modify the timers from the timer callbacks. If we used N lists, and the user adds a timer with a timeout equal to N, then the new timer will be added to the list that we are currently passing. This can not be done.
If we use (N - 1) lists, then we guarantee that the new timer cannot be added to the tick-list that we are going through at the moment (by the way, the timer can be removed from this list, but this will not create problems) .
Although this implementation of timers is quite acceptable for many applications, sometimes it is not ideal: if a device spends most of the time without doing anything, instead of constantly being on standby (with reduced consumption), the MCU will have to wake up regularly to process the system tick and go back to sleep. For this, a dynamic tick was implemented .
Dynamic tick
The basic idea is to get rid of useless calls
tn_tick_int_processing(). If the kernel has to wake up some task through 100 system ticks, then it tn_tick_int_processing()should be called after exactly 100 periods of the system tick (but external asynchronous events, of course, can occur and change this).To do this, the kernel must be able to communicate with the application:
- To schedule the next call
tn_tick_int_processing()via N ticks; - To ask how much time (i.e. get the current system ticks count).
So, when the dynamic tick mode is active (
TN_DYNAMIC_TICKset to 1), the application must provide pointers to these callbacks at system startup. Of course, the actual implementation of these callbacks depends entirely on the type of MCU (even on the same architecture there are a huge number of different MCUs that have different peripherals, etc.), therefore the correct implementation of these callbacks lies on the application.System start
For normal operation, the kernel needs the following:
- Space for the Idle task stack;
- Space for interrupt stack;
- Callback for idle task;
- Any user task (tasks).
So, before starting the system, the application must allocate arrays for the Idle task stack and for interrupts, provide the Idle callback task (it can be empty), and provide a special callback that must create at least one (and usually just one) user task. This is the first task to be launched, and in my applications I usually call it
task_initor task_conf. Obviously, it initializes the application.B
main(), the application should:- Disable system interrupts by calling
tn_arch_int_dis(); - Perform the main initialization of the microcontroller: at least, the oscillator settings;
- Configure a system timer interrupt (from which the ISR is called
tn_tick_int_processing()); - Call
tn_sys_start(), providing all the necessary information: pointers to arrays for stacks, their sizes, and callback functions.
The kernel does the following:
- Initializes startup queues (an array of lists
_tn_tasks_ready_list), and other aspects of the internal state of the kernel; - Creates and activates the Idle task (after that,
_tn_next_task_to_runpoints to the Idle task handle) - Invokes a user-defined function, in which the first user task is created and activated (after that, it
_tn_next_task_to_runindicates the handle of the highest-priority user task); - Invokes an architecture-specific function
_tn_arch_sys_start()that initializes an interrupt for a context switch, and performs the first context switch to the task that it is pointing to_tn_next_task_to_run.
After that, the system works as usual: a user task takes control and can do everything that any user task can do. Usually, she does the following:
- Initializes various peripherals on the board (LCD displays, flash drives, or whatever);
- Initializes software modules used in the application;
- Creates all other user tasks (since everything is already initialized, they can now begin their work).
More implementation details
Okay, it seems I should stop at some point: it’s unlikely that I will be able to describe every detail of the implementation in this article, which, frankly, is too big.
I tried to touch on the most interesting topics that are needed to understand the picture as a whole; for other topics, the reader can easily study the source code, which I tried to make really good and understandable. Sources are available: use them !
If you have any questions, ask in the comments.
Unit tests
Usually, when they talk about unit tests, they mean tests run on the host machine. But, unfortunately, the compilers used for embedded systems often contain errors, so I decided to test the kernel right in the hardware. Thus, I can be sure that the kernel works 100% on my device.
Overview of test implementation:
There is a high-priority task “test director”, which creates for itself “working” tasks and various RTOS objects (message queues, mutexes, etc.), and then tells work tasks what to do. For example:
- Task A, you block mutex M1
- Task B, you block mutex m1
- Task C, you block mutex M1
- Task A, you delete mutex M1
After each step, the test director waits for the workers to do their work, and then checks that everything is going according to plan: checks the status of tasks, their priorities, the last returned values from the kernel services, various properties of objects, etc.
The detailed log is displayed in the UART. Usually, after each step, the following is displayed:
- Verbatim comment;
- Test director writes what he does;
- Each work task writes what it does;
- Test director checks everything and writes a report.
Here is an example of the output log:
//-- A locks M1 (line 404 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: locking mutex (0xa0004c40).. [I]: [Task A]: mutex (0xa0004c40) locked [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- B tries to lock M1 -> B blocks, A has priority of B (line 413 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task B: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task B]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- C tries to lock M1 -> B blocks, A has priority of C (line 422 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task C: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task C]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- A deleted M1 -> B and C become runnable and have retval TN_RC_DELETED, A has its base priority (line 431 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: delete mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: deleting mutex (0xa0004c40).. [I]: [Task C]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task C]: waiting for command.. [I]: [Task B]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task B]: waiting for command.. [I]: [Task A]: mutex (0xa0004c40) deleted [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Mutex M1: holder=NONE (as expected), lock_cnt=0 (as expected), exists=no (as expected) If something goes wrong, there will be no “as expected”, but an error and details.
I really tried to simulate all possible situations within a single subsystem (mutexes, queues, etc.), including situations with suspended tasks, remote tasks, remote objects, etc. This helps a lot to keep the core really stable.
Final words
Why not just use FreeRTOS?
OK, there are several reasons.
Firstly, I do not like their license: under license, FreeRTOS is forbidden to compare with other products! Look at the last paragraph of FreeRTOS license :
FreeRTOS may not be used for any competitive or comparative purpose, including the publication of any form of run time or compile time metric, without the express permission of Real Time Engineers Ltd. (this is the norm within the industry and is intended to ensure information accuracy).
As far as I know, they added this condition after a very old discussion on the Microchip forum , where people posted graphs comparing several cores, and these graphs were not in favor of FreeRTOS. The author of FreeRTOS stated that the measurements are incorrect , but, no matter how funny, could not provide the "correct" measurements.
So, if I write a kernel that FreeRTOS leaves behind in one or another aspect, I will not be able to write about it. Maybe I do not understand something, but, in my opinion, some kind of nonsense. I do not like these things.
By the way, a few years ago, when my colleagues recommended TNKernel, they said that TNKernel is much faster than FreeRTOS. After I implemented TNeo, out of curiosity, I, of course, made a couple of comparisons, but, unfortunately, I cannot publish them because of the FreeRTOS license.
Secondly, I don’t like its source code either . Maybe I’m just too idealistic, but for me, the real-time core is, to some extent, a special project, and I want it to be as close to the ideal as possible.
Yes, now is the time to check out the TNeo code on GitHub and explain why it sucks. Perhaps this will help me make the kernel even better!
Thirdly, I wanted to have a more or less ready TNKernel replacement.so that I can easily port existing applications to the new kernel. Taking into account the problems in TNKernel under microchip microcontrollers described in the first part of the article, our devices always had the probability of undefined behavior.
And last but not least , working on the core is an extremely exciting experience!
However, FreeRTOS has an undeniable advantage over (possibly) all other similar products: it is ported to a huge number of architectures. Fortunately, I do not need so much.
Where is TNeo used?
At the moment, I ported to TNeo all existing applications that previously worked on TNKernel: on-board computers, chargers, etc. Works flawlessly.
I also presented the core at the annual Microchip MASTERS 2014 seminar, the head of the StarLine development department became interested and asked me to port the core to the Cortex-M architecture. Now it is already ready for a long time, and the core is used in their latest products.
Documentation and source code
TNeo is a thoroughly tested replacement RTOS for 16-bit and 32-bit open source microcontrollers.
Project posted on GitHub: TNeo .
At the moment, the kernel is ported to the following architectures:
- ARM Cortex-M cores: Cortex-M0 / M0 + / M1 / M3 / M4 / M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX / PIC24 / dsPIC
Full documentation is available in two versions: html and pdf.
My original article in English: How I ended up writing new real-time kernel . Since the author of the original article is myself, then, with your permission, I did not place this article in the category of "translation" .
Source: https://habr.com/ru/post/267573/
All Articles