How many tweets do you need to know your character?
The extensive growth in the amount of unstructured data (tweets, posts, comments, photos and videos) generated by humanity is both fantastic opportunities and a headache for many old and new industries.
The other day we have already quoted factual data on the volume of the number of messages produced by humanity per day , it is clear that billions of statements require completely different solutions and technologies. “Old” (horror, 3-5 years have passed, and already old) approaches and people who develop them are fighting for a place in the sun. But…
')
As a classic example, here is a translation of recent material from IBM Watson:
======
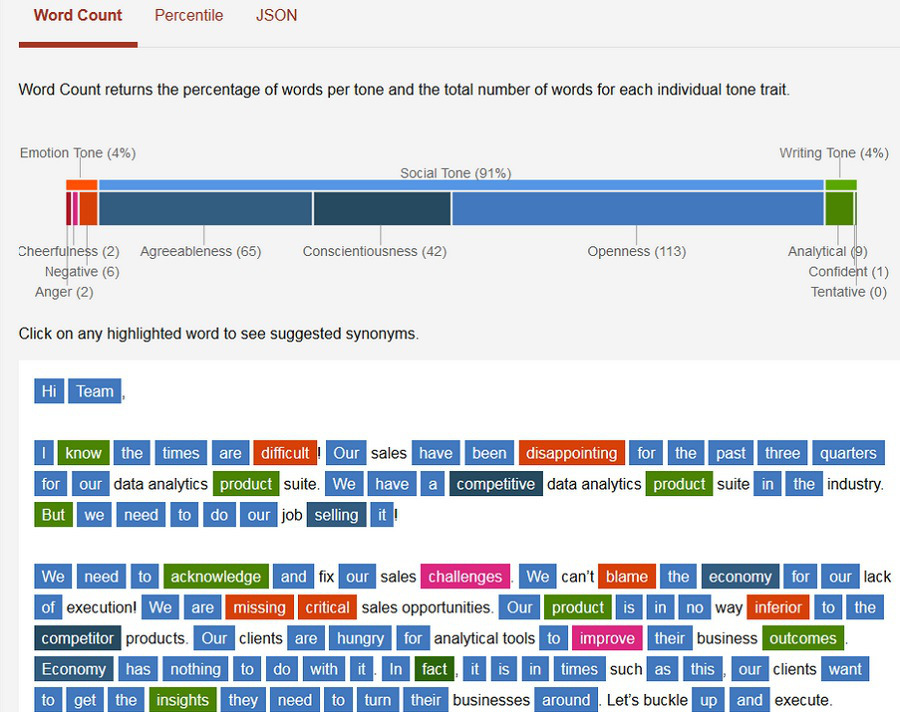
IBM Watson can recognize the emotional tone of the message
( source )
Researchers from IBM have created IBM Watson Tone Analyzer, an application for supercomputers, which can read the message and determine the emotions transmitted in it.
This task is from the category of those that are naturally easily performed by man, but, as a rule, making the right decision requires much more information about the world than the one that the computer owns.
Rama to Akkiradzhu, an engineer and experienced inventor at IBM Watson User Technologies, wrote in a blog post: “Can a computer automatically recognize the emotions conveyed in a message accurately enough? Helping people evaluate and improve their emotional tone in written communication is an interesting challenge in the fields of artificial intelligence and the cognitive sciences. With the help of IBM Watson, we can finally begin to answer this question. ”
All this sounds as if there is a person behind the curtain. But back in 2013, we wrote how IBM researchers can “decode” your character with just 200 tweets .
Sometimes the emotional tone of the message may be missed, undesirable or insufficiently disclosed by the author. The IBM Watson Tone Analyzer is already available in experimental mode; it is a service that will help evaluate and improve the emotional tone in written communication. ”
The technology component is similar to the linguistic analysis that is used in IBM Watson Personality Insights. Tone Analyzer analyzes the selected text and provides information on the emotional, social and written accents reflected in the text. Such information can be applied to a variety of tasks, including personal and business communications, branding, market research, PR, and a contact center, ”says Akkiraju.
The main emotional elements of tonality include cheerfulness, negative emotions and anger. “Cheerfulness implies positive emotions such as joy, optimism, contentment, inspiration and happiness. Negative emotions include feelings of fear, disgust, despair, guilt, and humiliation. Anger is also a kind of negative emotion with the most intense emotional color, such as irritation, hostility, aggression, pain, frustration and rage. ”
IBM Watson can also recognize social tones, such as openness, pliability, and good faith. “Openness is a measure of a person’s willingness to engage in new activities; flexibility - a tendency to empathy and active interaction with others; conscientiousness is the propensity for organized and thoughtful action. We use these three dimensions to illustrate the author’s openness, flexibility and integrity as reflected in the text. ”
=================
It would seem - everything is great? But judging by the latest actions of the Blue Giant on the market, such “turtle” speeds in the development of linguistics do not suit the management. A few years (at least since 2013) to solve the problem of semantic analysis and automatic determination of the tonality with coloring statements is impermissible development sluggishness in our time, when business needs prompt decisions.
Bottom line: IBM buys AlchemyAPI for $ 100 million in spring (see episode 9 of the Big Data series ), a company that can quickly handle English-language unstructured data streams.
Not only IBM has similar problems, but all the “whales” (SAP, Google, MS, HP, etc.) involved in developing products and systems for processing unstructured data. If the English language (from the point of view of linguistics is quite simple) is somehow more or less, then with others, like German or Russian, it’s just a disaster.
Communicating with European centers is impressive when, after years of research and requirements from above, “ you are breaking deadlines! ”, Solutions of the type are born: translate from Russian to English and take the tonality of the translation text. And it's not a joke.
For those interested in linguistics: you can work with Russian-language linguistics on the Eureka Engine website , and there is a detailed description of various linguistic modules.
For those who want to check " Rule 200 tweets / posts " from IBM researchers: take messages from some of the leading media people in different social media (see the public Authors and Groups Rating ) and check how wrong linguists are :-)
And if someone of the readers has a desire to make a full-fledged "wrapper" in the form of the system " Who are you in your posts? ", Then we will provide access to the data (messages) and the Eureka Engine API. Who knows, suddenly "It rotates!"?
The other day we have already quoted factual data on the volume of the number of messages produced by humanity per day , it is clear that billions of statements require completely different solutions and technologies. “Old” (horror, 3-5 years have passed, and already old) approaches and people who develop them are fighting for a place in the sun. But…
')
As a classic example, here is a translation of recent material from IBM Watson:
======
IBM Watson can recognize the emotional tone of the message
( source )
Researchers from IBM have created IBM Watson Tone Analyzer, an application for supercomputers, which can read the message and determine the emotions transmitted in it.
This task is from the category of those that are naturally easily performed by man, but, as a rule, making the right decision requires much more information about the world than the one that the computer owns.
Rama to Akkiradzhu, an engineer and experienced inventor at IBM Watson User Technologies, wrote in a blog post: “Can a computer automatically recognize the emotions conveyed in a message accurately enough? Helping people evaluate and improve their emotional tone in written communication is an interesting challenge in the fields of artificial intelligence and the cognitive sciences. With the help of IBM Watson, we can finally begin to answer this question. ”
All this sounds as if there is a person behind the curtain. But back in 2013, we wrote how IBM researchers can “decode” your character with just 200 tweets .
Sometimes the emotional tone of the message may be missed, undesirable or insufficiently disclosed by the author. The IBM Watson Tone Analyzer is already available in experimental mode; it is a service that will help evaluate and improve the emotional tone in written communication. ”
The technology component is similar to the linguistic analysis that is used in IBM Watson Personality Insights. Tone Analyzer analyzes the selected text and provides information on the emotional, social and written accents reflected in the text. Such information can be applied to a variety of tasks, including personal and business communications, branding, market research, PR, and a contact center, ”says Akkiraju.
The main emotional elements of tonality include cheerfulness, negative emotions and anger. “Cheerfulness implies positive emotions such as joy, optimism, contentment, inspiration and happiness. Negative emotions include feelings of fear, disgust, despair, guilt, and humiliation. Anger is also a kind of negative emotion with the most intense emotional color, such as irritation, hostility, aggression, pain, frustration and rage. ”
IBM Watson can also recognize social tones, such as openness, pliability, and good faith. “Openness is a measure of a person’s willingness to engage in new activities; flexibility - a tendency to empathy and active interaction with others; conscientiousness is the propensity for organized and thoughtful action. We use these three dimensions to illustrate the author’s openness, flexibility and integrity as reflected in the text. ”
=================
It would seem - everything is great? But judging by the latest actions of the Blue Giant on the market, such “turtle” speeds in the development of linguistics do not suit the management. A few years (at least since 2013) to solve the problem of semantic analysis and automatic determination of the tonality with coloring statements is impermissible development sluggishness in our time, when business needs prompt decisions.
Bottom line: IBM buys AlchemyAPI for $ 100 million in spring (see episode 9 of the Big Data series ), a company that can quickly handle English-language unstructured data streams.
Not only IBM has similar problems, but all the “whales” (SAP, Google, MS, HP, etc.) involved in developing products and systems for processing unstructured data. If the English language (from the point of view of linguistics is quite simple) is somehow more or less, then with others, like German or Russian, it’s just a disaster.
Communicating with European centers is impressive when, after years of research and requirements from above, “ you are breaking deadlines! ”, Solutions of the type are born: translate from Russian to English and take the tonality of the translation text. And it's not a joke.
For those interested in linguistics: you can work with Russian-language linguistics on the Eureka Engine website , and there is a detailed description of various linguistic modules.
For those who want to check " Rule 200 tweets / posts " from IBM researchers: take messages from some of the leading media people in different social media (see the public Authors and Groups Rating ) and check how wrong linguists are :-)
And if someone of the readers has a desire to make a full-fledged "wrapper" in the form of the system " Who are you in your posts? ", Then we will provide access to the data (messages) and the Eureka Engine API. Who knows, suddenly "It rotates!"?
Source: https://habr.com/ru/post/267247/
All Articles