How to improve resiliency of billing: The experience of "Hydra"

We have already written about what problems a company may have when developing complex systems on its own. In the comments, readers asked us to tell more about the technical component of our project - billing for operators of communication " Hydra ".
Fulfilling this request, today we will talk about how we worked to improve the resiliency of the system.
')
Components of billing: where reliability is most important
Billing is a system that should work 24x7 all 365 days a year. Therefore, the reservation of all its components is necessary. Let's take a closer look at what the billing system consists of.
Data
Information about services consumed by subscribers, personal account balances, detailing payments and debits. This is the most valuable information business, and therefore, it must be rescued in the first place.
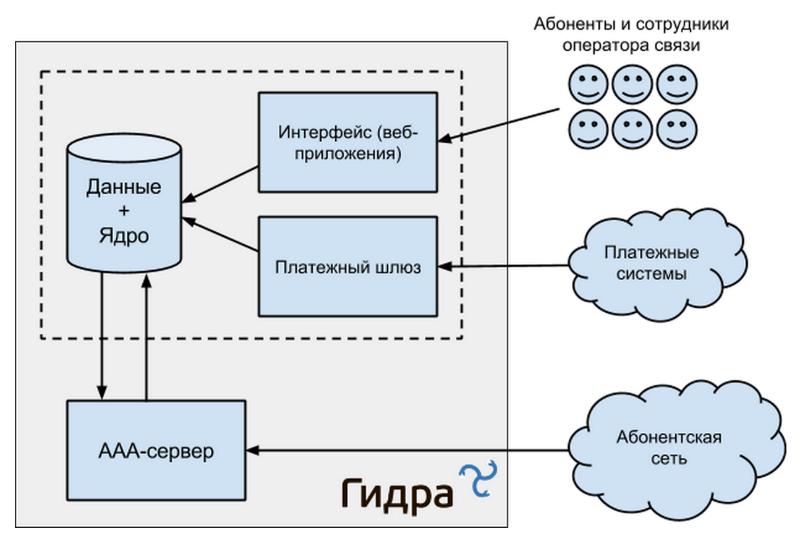
Core
The kernel is part of the system in which all data operations are conducted. In Hydra, it is integrated with data - business logic is located directly in the database in the form of stored procedures. Modifying data directly to external applications is prohibited, it can be done only through the API. Therefore, in order for data to be available, the kernel must remain operable.
AAA server (Authentication, Authorization, Accounting)
The element that is responsible for authentication, authorization and accounting of important information about the services consumed by subscribers. Network equipment interacts with the AAA server (server providing access to services). In case of failure of the AAA server, as a rule, subscribers face the impossibility of opening new sessions, connecting new services and disconnecting old ones.
In addition, in such situations information about services already rendered may be lost - this not only leads to inconvenience for customers, but also fraught with “free” service provision during a billing failure. Thus, the AAA server is one of the most sensitive components of the entire system.
Payment gateway
Accepts information about payments made from various payment systems. The failure of the gateway leads to delays in the passage of information about the payments made by customers to their personal billing accounts.
In some cases, this may adversely affect the quality of service - for example, if all subscribers have a settlement day on the first day of the month, and the failure occurred on that day. The failure of the payment gateway at this time leads to the fact that subscribers can not replenish their personal account and restore access to the services if they are disabled for non-payment.
The health of the payment gateway depends on the health of the kernel, since if the kernel is unavailable, it will not be able to inform the other components of the billing about the receipt of funds to the account. However, even a few hours of downtime are unlikely to lead to serious problems, since almost all payment systems automatically make payments again if previous requests received an error in response, and there is no need to undertake anything besides the restoration of the service itself.
Subscriber Account and Web Control Panel
If the billing control panel and personal account of the users fall, the billing itself remains operable, however, company employees and its customers temporarily lose their ability to work with the system.
What and how to reserve?
Above, we have reviewed the main components of billing and their importance from the point of view of ensuring fault tolerance. Now let's talk about the steps we have taken to improve the reliability of the system.
Let's start with a description of common approaches. The components of billing are divided into two broad categories: those that store the state and those that do not. The condition is traditionally stored in a database, we have two of them, while in normal operation they actively exchange data.
Reservation of the main database
The main database stores data and the core of the system. We use a degenerate three-tier architecture - business logic (stored procedures and functions in Oracle) and data (tables) are tightly integrated into the DBMS, the browser (“thin client”) acts as a client, and the web interface serves as a program shell to the kernel. Since the Oracle Database is used as the RDBMS, we use the manufacturer’s recommended backup database approaches:
- Periodic backup . The simplest way, which, nevertheless, is fraught with certain difficulties - data recovery when using it can take a long time, and upon completion of this process the information will be irrelevant. For taking backups in Oracle, expdp utilities can be used - for small installations (they are easy to use, data is restored for a long time), and the universal RMAN manager, which allows you to remove full and incremental backups on a schedule and unzip them.
- Copying redo-logs from the DBMS to the standby-server . This method allows you to organize a "hot" backup, in which changes from the working database are applied to the standby-server. In the event of a working server failure, maintenance is automatically or manually transferred to a backup server with actual data.
To speed up switching to a backup server, we use a little trick. The primary and backup servers have their own IP addresses. Above them is the IP alias, which normally hangs on the main server. If it fails, this alias can be quickly “moved” to the standby server - users will not notice the difference.
Application Backup
All applications, except for the AAA server (it will be discussed later), store the state in the main database, so the backup server only needs to keep the applications of the required versions, their configuration files, as well as startup scripts.
Applications are configured to work with a backup database and are ready to accept an incoming request at any time, which will be processed after the backup database is switched to active mode.
AAA server backup
The AAA server is the system’s most sensitive component to interruptions. Strictly speaking, it does not apply to billing, but works in conjunction with it. As soon as the access server is unavailable, subscribers will notice this immediately. Allowed idle time is a few minutes, otherwise subscribers will “fill up” with calls a call center of any size.
As a rule, the AAA server is placed on a separate physical machine closer to the subscribers, in order not to depend on the availability of the server from the main database. This is very useful for geographically distributed networks in which the risks of interrupting the connection of the AAA server with the core are high.
The access server itself is reversed in two modes: automatic and manual. For automatic backup, you must have at least three physical servers (to solve the problem of a network break, netsplit). For manual mode, two servers are enough, but in this case, the decision on switching the load must be taken by the duty officer.
Consider an example of an installation with automatic failover:
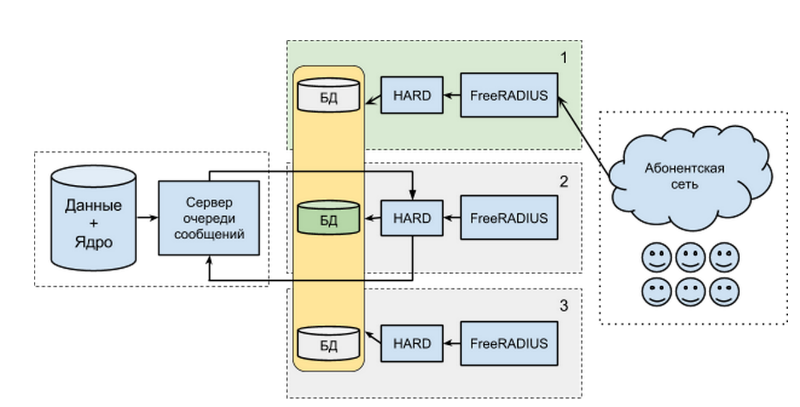
Each AAA server consists of three components:
- Database with subscriber profiles and data on consumed services.
- Our application codenamed HARD. It responds to HTTP requests that come from the next component.
- FreeRADIUS - directly the server implementing the standard AAA-protocol - RADIUS. It directly communicates with the subscriber network and translates requests from the binary format into plain HTTP + JSON for HARD.
The databases of all AAA servers (this is MongoDB) are combined into a group with one main node (master) and two subordinate (slave). All requests from the subscriber network go to one AAA-server, while it is not necessary and even undesirable that they be a server from the main database.
Let's see what happens if something goes wrong, and one of the components fails:
- If the connection with the billing core is lost, then the access server database stops receiving updates, however, all authentication and authorization parameters for subscribers remain available to the server. If you had access to the Internet before the accident, then after the accident you will have it, you will not notice anything.
- If the AAA server number 1 fails, the network will start accessing the next server in order. This is the standard failover support scheme for modern BRAS.
- If server 2 fails, the primary node with the database will be unavailable. In this case, after some time (about one minute), a new main node will be selected among the remaining ones. After that, the billing core will communicate with this server.
- The failure of the third server will not cause any additional action.
Thus, any non-global failures will not lead to the loss of subscriber access to services. Whatever happens, users will most likely not notice anything.
Conclusion
Our project has been developing for 8 years already, and during this time we have participated in more than 80 implementation projects. We are constantly working to make the system more reliable and convenient for customers.
In the next posts we will continue to talk about the architecture of "Hydra", technologies and approaches that are used in its development.
Subscribe to our blog to not miss anything interesting!
Source: https://habr.com/ru/post/267083/
All Articles