Publishing logs in Elasticsearch - life without regular expressions and without logstash
When using the approach of this solution, file parsing will not be necessary. When changing the format of logging or the appearance of new messages, it is not necessary to support a large set of regulators. We will intercept calls to the error, warn, info, debug, trace tracers and send the data immediately to elasticsearch. With this, aspect-oriented programming will help us!
You can see the screencast at the end of the article.
I hope that you will be interested to learn how using aspects written in the form of a script and configuration, you can work with the elasticsearch client, gson serializer and parameters of the intercepted method in jvm.
The experimental program remains the SonarQube, as in the articles about hawt.io/h2 , jdbc and CRaSH-ssh logging . You can read more about the installation and configuration of sonar and virtual machine agent in the hawt.io/h2 publication.
')
This time we’ll use the jvm sonar launch options:
sonar.web.javaAdditionalOpts = -javaagent: aspectj-scripting-1.0-agent.jar -Dorg.aspectj.weaver.loadtime.configuration = config: file: es.xml
And for the example to work, you need to download the jvm agent aspectj-scripting and the es.xml configuration file:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <configuration> <aspects> <name>com.github.igorsuhorukov.Loging</name> <type>AROUND</type> <pointcut>call(* org.slf4j.Logger.error(..)) || call(* org.slf4j.Logger.warn(..)) || call(* org.slf4j.Logger.info(..)) || call(* org.slf4j.Logger.debug(..)) || call(* org.slf4j.Logger.trace(..))</pointcut> <process> <expression> res = joinPoint.proceed(); log = new java.util.HashMap(); log.put("level", joinPoint.getSignature().getName()); log.put("srcf", joinPoint.getSourceLocation().getFileName().substring(0, joinPoint.getSourceLocation().getFileName().length()-5)); log.put("srcl", joinPoint.getSourceLocation().getLine()); if(joinPoint.getArgs()!=null && joinPoint.getArgs().?length>0){ log.put("message", joinPoint.getArgs()[0].?toString()); if(joinPoint.getArgs().length > 1){ params = new java.util.HashMap(); for(i=1; i < joinPoint.getArgs().length;i++){ if(joinPoint.getArgs()[i]!=null){ if(joinPoint.getArgs()[i].class.getName().equals("[Ljava.lang.Object;")){ for(j=0; j < joinPoint.getArgs()[i].length;j++){ if( (joinPoint.getArgs()[i])[j] !=null){ params.put(i+"."+j,(joinPoint.getArgs()[i])[j].toString()); } } } else { params.put(i,joinPoint.getArgs()[i].toString()); } } } log.put("params", params); } } log.put("host", reportHost); log.put("pid", pid); log.put("@version", 1); localDate = new java.util.Date(); lock.lock(); log.put("@timestamp", dateFormat.format(localDate)); index = "logstash-" + logstashFormat.format(localDate); lock.unlock(); logSource = gson.toJson(log); client.index(client.prepareIndex(index, "logs").setSource(logSource).request()); res; </expression></process> </aspects> <globalContext> <artifacts> <artifact>com.google.code.gson:gson:2.3.1</artifact> <classRefs> <variable>GsonBuilder</variable> <className>com.google.gson.GsonBuilder</className> </classRefs> </artifacts> <artifacts> <artifact>org.elasticsearch:elasticsearch:1.1.1</artifact> <classRefs> <variable>NodeBuilder</variable> <className>org.elasticsearch.node.NodeBuilder</className> </classRefs> </artifacts> <init> <expression> import java.text.SimpleDateFormat; import java.util.TimeZone; import java.util.concurrent.locks.ReentrantLock; reportHost = java.net.InetAddress.getLocalHost().getHostName(); pid = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().split("@")[0]; gson = new GsonBuilder().create(); dateFormat = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"); dateFormat.setTimeZone(TimeZone.getTimeZone("UTC")); logstashFormat = new SimpleDateFormat("yyyy.MM.dd"); logstashFormat.setTimeZone(TimeZone.getTimeZone("UTC")); lock = new ReentrantLock(); client = NodeBuilder.nodeBuilder().clusterName("distributed_app").data(false).client(true).build().client(); </expression> </init> </globalContext> </configuration> For all call points from the program of the error, warn, info, debug, org.slf4j.Logger interface trace, an aspect is called in which we create a HashMap log and fill in the call context parameters: the srcf class file and the srcl lines in it , specify the logging level “level” , host name “host” , process identifier “pid” , time for calling the logger "@timestamp" , as well as the message text template and save its parameters separately in the Map "params" . All this synchronously with the call is serialized in json and sent to the index with the name "logstash-" + the date of the call. Classes for formatting dates and times, as well as the client for elasticsearch, are created when the application starts in the global initialization block of aspects of globalContext.
The elasticsearch classes are loaded from the maven repository at the coordinates of org.elasticsearch: elasticsearch: 1.1.1 , and the json serializer at the coordinates com.google.code.gson: gson: 2.3.1 .
The client from the aspect at the start of the multicast protocol is trying to find an elasticsearch cluster with the name "distributed_app"
Before launching our client, we will definitely launch a server elasticsearch cluster consisting of one process:
package org.github.suhorukov; import org.elasticsearch.common.settings.ImmutableSettings; import org.elasticsearch.node.Node; import org.elasticsearch.node.NodeBuilder; import java.io.InputStream; import java.net.URL; import java.util.concurrent.TimeUnit; public class ElasticsearchServer { public static void main(String[] args) throws Exception{ String template; try(InputStream templateStream = new URL("https://raw.githubusercontent.com/logstash-plugins/logstash-output-elasticsearch/master/lib/logstash/outputs/elasticsearch/elasticsearch-template.json").openStream()){ template = new String(sun.misc.IOUtils.readFully(templateStream, -1, true)); } Node elasticsearchServer = NodeBuilder.nodeBuilder().settings(ImmutableSettings.settingsBuilder().put("http.cors.enabled","true")).clusterName("distributed_app").data(true).build(); Node node = elasticsearchServer.start(); node.client().admin().indices().preparePutTemplate("logstash").setSource(template).get(); Thread.sleep(TimeUnit.HOURS.toMillis(5)); } } To compile and work this class, a dependency is required:
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>1.1.1</version> </dependency> To view the logs, download the old kibana 3.1.3 build, which can work without a web server. Edit the config.js file
elasticsearch: "http://127.0.0.1:9200" so that kibana can connect to the elasticsearch server (for this we specified “http.cors.enabled” = true )Start the sonar
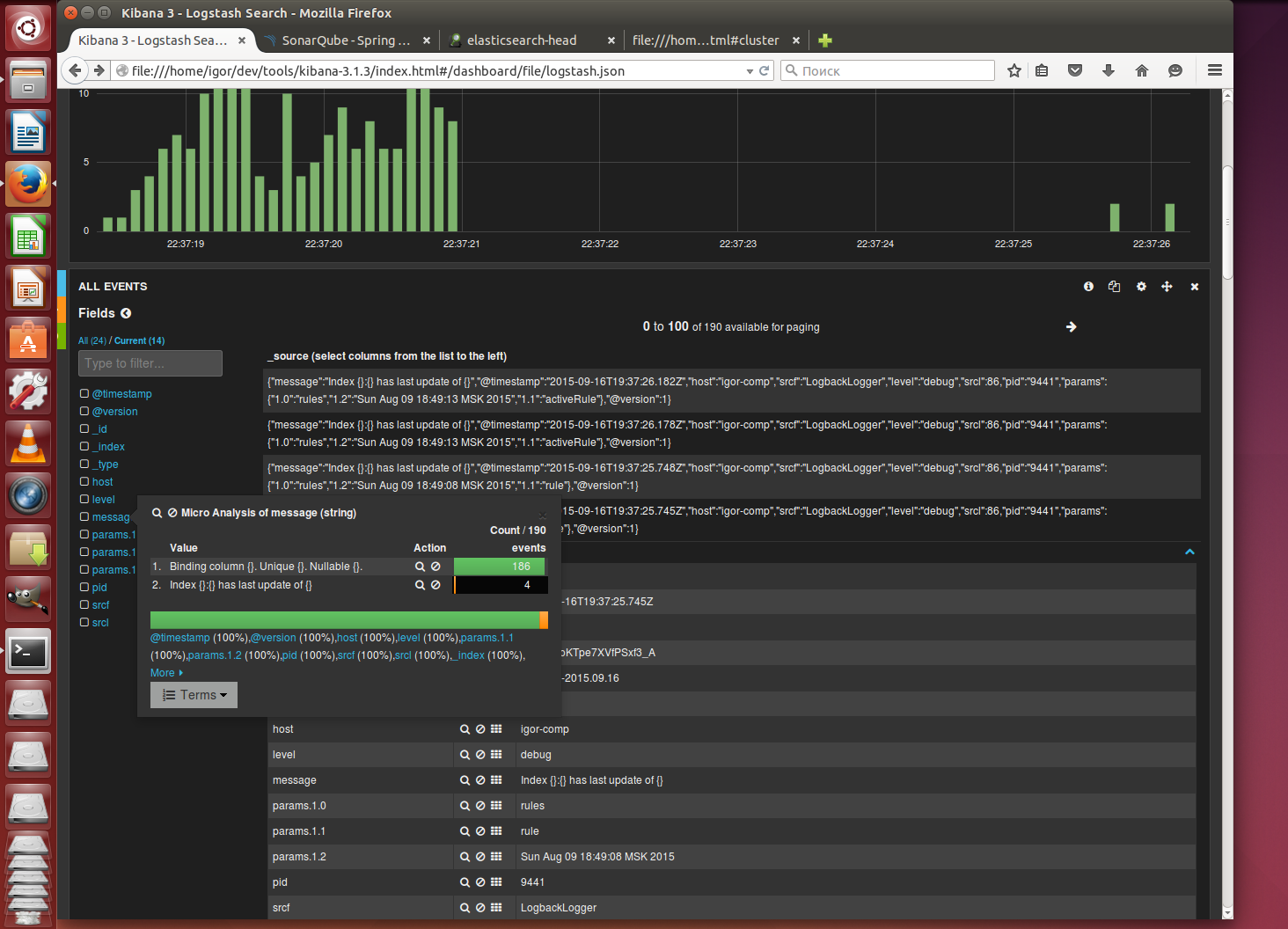
./bin/linux-x86-64/sonar.sh start and observe in the browser how the events of this system are displayed during the operation of SonarQube in kibana
What kind of examples with the use of aspects would you be interested to read? Offer!
Source: https://habr.com/ru/post/267009/
All Articles