Design unification from the backend: JavaScript on the server

In early 2014, the task of unifying the design came to our content projects department. Designers wanted a single style of projects and principles of the interfaces. It will be convenient for users, will facilitate the launch of new projects and the redesign of existing ones (Yura Vetrov wrote about this in more detail). The frontend team will be able to use similar layout components on different projects, which will reduce the development time and support for existing functionality. For the backend team, the task turned out to be non-trivial: most of our projects are written in Perl (Template Toolkit), Real Estate in PHP, Children and Health use Django. But we were required to implement not only the support of a single template, but also to agree on a single format of the data sent to the templates. The abundance of loadable AJAX blocks required the support of client standardization as well.
Thus, the task of unifying the design has become the task of choosing a single template for Perl, Python, PHP and JS.
The first steps
The task seemed difficult and not fully solved, we began to look for different options. We started with ready-made solutions. The first idea was to port the Django Dotiac :: DTL template engine to Perl or the template toolkit to Python. Template toolkit allows you to write software logic in templates, this makes them non-portable to other languages. Django templates significantly limit programming in templates, but you will also have to refuse extensions in the form of filters and your tags, or duplicate Perl and JS logic. In addition, it is not known how functional the ported versions are. Thus, this idea was reduced to the use of the basic constructs of the template engine (blocks of if / else conditions, for loops, include inclusions). For this, a full port is not needed. And the functionality that you want to use, but not for one reason or another (for example, not implemented in another language, or implemented differently), will only interfere with the overall process. Therefore, to performance testing, we have not reached. This idea was postponed.
')
The second idea was to use Mustache . This template engine is available in a variety of languages from popular on the web (PHP, Python, Perl, Ruby, JS) to very far from it (R, Bash, Delphi). At first, the lack of logic in the templates even attracted: the process of preparing data for templating completely controls the backend, no logic in the templates themselves. But this turned out to be an unnecessary extreme. Data preparation seemed too laborious, the mechanism of partials was inconvenient, the template collector was required. Together with the phrase "in my opinion, this is a piece of hell on earth" we stopped to consider a mustache.
There was also the idea to write your simple template engine in all necessary languages, or a meta description from which you can create the necessary templates. The task looked time consuming, we continued to look for options.
Fest
Fest is a template engine that compiles XML templates in JavaScript functions. At that time, we already had the experience of using the fest in mobile versions. The main difference from the large versions was that at that time, search robots paid little attention to the mobile versions, and we could afford to standardize entirely on the client, while saving server resources. It looked like this in the HTML page:
<script> document.write(fest['news.xml'], context) </script> Where context is the data serialized in JSON. Rendered HTML was output to the page via document.write.
Using fest solves the problem of templating on the client, we needed to learn how to execute this JS on the server. The frontend team also supported this option. For the execution of JavaScript on the server, we chose the popular V8 from Google. V8 evolves rapidly, but persistent "Performance and stability improvements" often break backward compatibility even in minor versions. This is understandable, the V8 is being developed primarily for Chrome, a browser whose new versions come instead of the old. We started using V8, adopting the experience of our colleagues from Mail.
V8
First of all, we began to look for ready-made solutions - bindings for Python and Perl . Having a little tormented with the assembly of packages (V8 are significantly ahead of their binding, and finding compatible versions was not easy), we began to try them. Immediately noticed expensive raising the context: creating the context takes about 10 ms, rendering the template - 20 ms. Thus, the context should be created 1 time per request, and, ideally, reused later. Therefore, it was not a question of embedding the rendering of common components at the fest into the native template engine (TemplateToolkit or Django). At the fest you have to go completely.
These binding quite inspired confidence, projects developed, examples of use were published on the Internet. And we began to use them. At that time, there was a redesign of Auto (Perl) and Health (Python) projects, we tested new technology on them. In the controllers, we formed the context, serialized it into JSON, and sent it to the loaded template:
ctx = PyV8.JSContext() with ctx: ctx.eval(template) ctx.eval('fest["%s"](%s)' % (fest_template_name, json_context) It was a working version, but it was not so rosy. In addition to, in fact, templates, there are common utilities, helpers. They should be uploaded to V8 once and used when rendering pages. Wrappers over V8 allowed to load such code, but it was necessary to do it strictly once. A reload resulted in a memory leak. The same thing happened with the template code. As a result, the context was created for each request, and then it was killed. Templating took place slowly, CPU resources were significantly wasted, but the memory was not running. But everything worked more or less stable. As a result, Auto started on this scheme.
Wrappers over V8 allow you to use language objects in the context of JavaScript. But in the case of PyV8, this does not work at all. All the versions I tried either quickly leaked or cleared the memory, but fell into segfault. The use of binders has been reduced purely to the execution of JavaScript with some overhead, since the banding honestly checks the type of transferred objects. On Health, we did not begin to try PyV8 in battle.
Meanwhile, colleagues from the post office shared their decision. This is a separate living daemon, which receives the name of the template and the context (JSON-string), in return gives HTML, which we give to the user. In many ways, he solves our problems. The daemon can load common helpers at the start, cache templates into memory, works stably in speed and in memory. But it was still not the perfect solution. This tool Mail developed for their tasks that are different from ours. Their templates are much smaller and lighter than ours and are executed faster. Earlier, Andrei Sumin wrote about 1 ms for templating ( JavaScript on the server, 1ms for transformation ), we have an average of 15-20 ms.
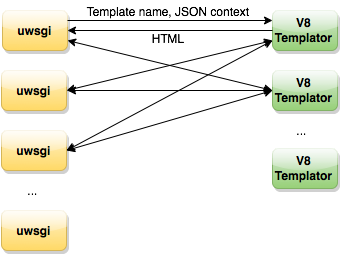
Their solution involves a single daemon template process per server, we cannot afford it. Although colleagues made a multiprocessor version for us, the problems to be solved remained:
- A standalone demon requires stable operation. His work needs to be monitored, to be able to quickly switch to a backup server.
- Logs with errors are not associated with the address of the page on which they occur.
- Logs are written to a file, and not to the general statistics collection system.
- To avoid delays, you need to have the same number of back-end workers and a daemon template engine.
We also had an interesting case. Once in the templates, an eternal cycle appeared by mistake, he completely occupied the worker, this led to disastrous consequences. Although there were no such cases in the future, we did not have protection against such errors. As a result, Health started with this scheme. But we did not stop there. The next step was to abandon the separate daemon, we decided to embed templating into the Perl and Python executable process. As a result, a common wrapper was written over V8 , which could read JS-files (helpers and templates), load the code into memory and execute (that is, render the templates in HTML).
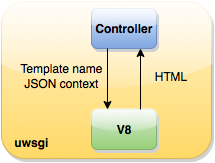
The module takes one V8 context to the process and conducts all further work within it. As a result of this approach, the name for the library was born - V8MonoContext. Then we wrote an XS Perl module and an extension for Python that uses these functions in the context of the language:
renderer = MonoContext() renderer.load_file(utils_file) append_str = 'fest["{}.xml"]( JSON.parse(__dataFetch()) );'.format(bundle) html, errors = renderer.execute_file(template_file, append_str, json_str) Helpers are loaded once at the start of the process using the load_file method. The execute_file method loads the template, calls the template function, to which JSON is transmitted with the data for the template. As a result, we get HTML and a list of possible errors that can be logged through the standard means of the backend itself. Now this solution suits us completely:
- Standardization is an integral part of processing a user's request within a single worker. We can measure how long it takes, log possible errors.
- The V8 context is raised once at the start of the worker.
- JS-code is loaded once, server resources are spent optimally.
- V8 consumes more memory than native language templating engines. The resident memory of workers increased an average of 200 MB, a maximum of 300 MB.
- Also, the thread mode is not supported, which may be relevant for Python projects. Within one process only one context can be executed, the rest should be inactive at this time. This is how V8 works in Chrome. But this does not bother us, we are working in the prefork-mode.
There are other features of the work V8 associated with the GC. V8 starts its garbage collector at the time it sees fit, as a rule, if the memory begins to run out. There are 2 methods to live with this:
- Stock up on RAM and fully trust the V8. The V8 context will die with the worker through the specified MaxRequest value.
- Starting a “handle” at some intervals is a signal of low memory LowMemoryNotification. A rare launch threatens with a lengthy cleanup, and frequent will consume extra processor resources. We call LowMemoryNotification every 500 requests for templating.
You can also limit the amount of memory allocated for V8 ( Memory management flags in V8 ). In this case, the GC will be launched more often, but it will work faster. If there is a shortage of memory, the server may postpone part of the heap to the swap, and this leads to additional delays. As a result, the poster was launched on this scheme, we were completely satisfied with the results. Soon, PHP learned to work with V8MonoContext, PHP followed our other projects - Auto, Horoscopes, Health, Lady, Real Estate, Weather, Hi-Tech.
Performance comparison
It should be noted that the speed of the template engine on the V8 (as well as any other active template engine) depends on how much data it works with and what logic is applied to it. Net rendering time can be determined only on synthetic tests, which may not always reflect the real picture. In our case, the transition from V8 occurred with the redesign, so we do not have accurate measurements. Indirectly comparing metrics, we got the winnings up to 2 times.
Development approach
With the transition to the fest, the approach to development has changed:
- Common template components should have a single interface for projects that use it. This requires a certain order and consistency of all participants in the process. We began to describe in the documentation the format of the data transmitted to the front and follow it. In addition, we develop common system solutions for different backends (Perl, Python, PHP), for example, working with CSRF tokens.
- Common components diverge across all projects, so it is especially important that they work quickly and efficiently.
- We have a clean MVC scheme in which the backend gives data and does not touch the patterns at all. If there is not enough data on the front, you need to wait for the backend.
findings
We have solved the task of switching to a single template for Perl, Python, PHP. Now common components (for example, comments, galleries, polls) can quickly be implemented and diverge across all our projects. Client standardization has become a big plus for us: now it is almost worthless to transfer logic to the client side. Next in this series will be an article from the frontend, which my colleagues are already preparing.
Source: https://habr.com/ru/post/266713/
All Articles