How security holes are arranged: buffer overflow
Note translator: This is a translation of the article by Peter Bright (Peter Bright) "How security flaws work: The buffer overflow" on how buffer overflow works and how vulnerabilities and protection methods have developed .
Starting from the 1988 Morris Worm (Morris Worm), this problem has hit everyone, both Linux and Windows.

Buffer overflow has long been known in the field of computer security. Even the first self-propagating Internet worm, the 1988 Morris Worm, used a Unix daemon buffer overflow to spread between machines. Twenty-seven years later, buffer overflow remains a source of problems. Windows developers have changed their approach to security after two buffer-based exploit overflows at the beginning of the two thousandth. And the buffer overflow in the Linux driver discovered in May of this (potentially) puts millions of home and SMB routers at risk.
')
At its core, buffer overflow is an incredibly simple bug originating from common practice. Computer programs often work with blocks of data read from a disk, from a network, or even from a keyboard. To accommodate this data, programs allocate finite-size memory blocks — buffers. Buffer overflow occurs when writing or reading data is larger than the buffer.
On the surface, it looks like a very stupid mistake. In the end, the program knows the size of the buffer, which means it should be easy to make sure that the program will never try to buffer more than the known size. And you would be right in this way. However, buffer overflows continue to occur, and the results often represent a security catastrophe.
To understand why a buffer overflow occurs — and why the results are so pitiable — we need to consider how programs use memory, and how programmers write code.
(Author's note: we consider, first of all, stack buffer overflow (stack buffer overflow). This is not the only type of overflow, but it is the classic and most studied type)
We stack
Buffer overflow creates problems only in native code - i.e. in such programs that use a set of processor instructions directly, without intermediaries like Java or Python. Overflows are related to the way the processor and native programs manage memory. Different operating systems have their own characteristics, but all modern common platforms follow the general rules. In order to understand how attacks work, and what methods of counteraction there are, first we will look a little at the use of memory.
The most important concept is the address in memory. Each individual byte of memory has a corresponding numeric address. When the processor reads or writes data to main memory (RAM, RAM), it uses the memory address of the place from which the reading occurs or where it is written. System memory is not only used for data; it is also used to host the executable code that makes up the program. This means that each of the functions of the running program also has an address.
Initially, processors and operating systems used physical memory addresses: each memory address was directly related to the address of a particular piece of RAM. Although some parts of modern operating systems still use physical addresses, all modern operating systems use a scheme called virtual memory.
When using virtual memory, there is no direct correspondence between the memory address and the physical portion of RAM. Instead, the programs and the processor operate in the virtual address space. The operating system and processor together support mapping between virtual and physical memory addresses.
This virtualization allows you to use several important functions. The first and most important is protected memory . Each individual process gets its own set of addresses. For a 32-bit process, addresses start from zero (the first byte) and go to 4,294,967,295 (in hexadecimal form, 0xffff'ffff; 2 ^ 32 - 1). For a 64-bit process, addresses continue to 18,446,744,073,709,551,615 (0xffff'ffff'ffff'ffff, 2 ^ 64 - 1). Thus, each process has its own address 0, followed by its address 1, its address 2, and so on.
(Author's note: Further in the article I will talk about 32-bit systems, unless otherwise indicated. In this aspect, the difference between 32-bit and 64-bit systems is not essential; for clarity, I will stick to the same bitness)
Since each process gets its own set of addresses, this scheme is a simple way to prevent the memory damage of one process by another: all addresses to which the process can apply belong only to it. It is much easier for the process itself; physical memory addresses, although they also work broadly (they are just numbers starting from zero), have features that make them somewhat inconvenient to use. For example, they are usually non-continuous; for example, the address 0x1ff8'0000 is used for the memory of the system control mode of the processor - a small piece of memory that is inaccessible to ordinary programs. PCIe memory is also located in this space. There are no such inconveniences with virtual memory addresses.
What is in the process address space? Generally speaking, there are four common objects, three of which are of interest to us. The block uninteresting for us, in most operating systems, is the “core of the operating system”. In the interests of performance, the address space is usually divided into two halves, the lower of which is used by the program, and the upper one is occupied by the address space of the kernel. The half given to the kernel is not accessible from half of the occupied program, however the kernel itself can read the program memory. This is one of the ways to transfer data to kernel functions.
First of all, let's deal with the executable part and the libraries that make up the program. The main executable file (main executable) and all its libraries are loaded into the address space of the process, and all the functions that make them up, thus, have an address in memory.
The second part of the memory used by the program is used to store the data being processed and is usually called a heap . This area, for example, is used to store the document being edited, or the web page you are viewing (with all its JavaScrit objects, CSS, etc.), or maps of the game you are playing.
The third and most important part is the call stack, usually called just the stack. This is the most difficult aspect. Each thread in the process has its own stack. This is a memory area used for simultaneous tracking of both the current function being executed in the stream and all previous functions - those that were called to get into the current function. For example, if function a calls function b , and function b calls function c , the stack will contain information about a , b, and c , in that order.
The call stack is a specialized version of the data structure called the “stack”. Stacks are variable length structures for storing objects. New objects can be added (pushed) to the end of the stack (usually called the "top" of the stack) and objects can be removed (popped) from the stack. Only the top of the stack is subject to change using push and pop, so the stack establishes a strict sorting order: the object that was last put onto the stack will be the one that will be removed next.
The most important object stored on the call stack is the return address. In most cases, when a program calls a function, this function does what it should (including calling other functions), and then returns control to the function that called it. To return to the calling function, it is necessary to keep a record of it: the execution should continue with the instruction following the call instruction. The address of this instruction is called the return address. The stack is used to store these return addresses: each time the function is called, the return address is placed on the stack. With each return, the address is removed from the stack and the processor begins to execute instructions at that address.
The stack functionality is so basic and necessary that most, if not all processors have built-in support for these concepts. Take for example x86 processors. Among the registers (small memory areas in the processor that are available for instructions) defined in the x86 specification, two of the most important are eip (instruction pointer) and esp (stack pointer).
ESP always contains the address of the top of the stack. Every time something is added to the stack, the esp value decreases. Every time something is removed from the stack, the esp value increases. This means that the stack grows "down"; as you add objects to the stack, the address stored in esp becomes less and less. Despite this, the memory area pointed to by esp is called “the top of the stack.
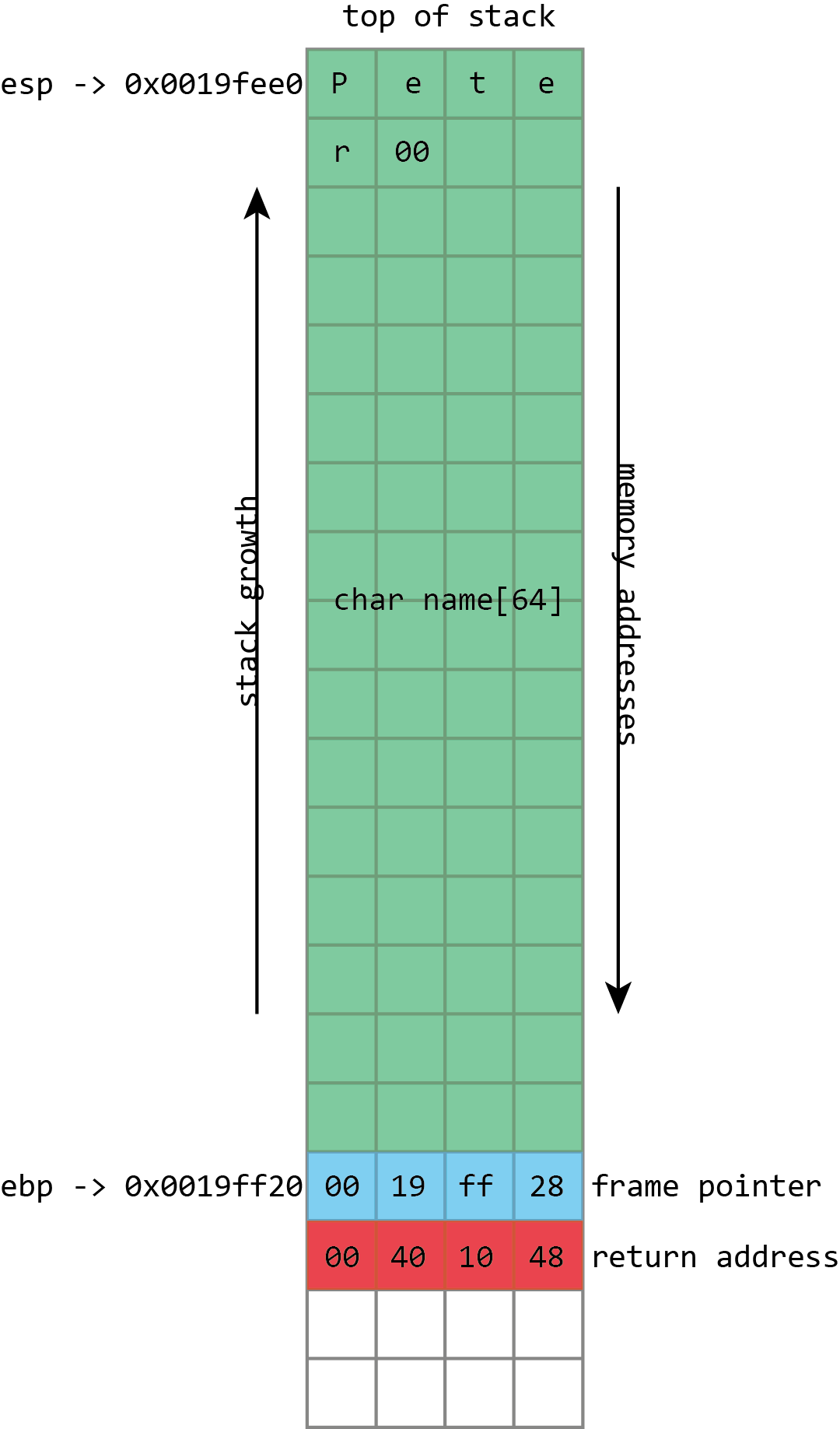
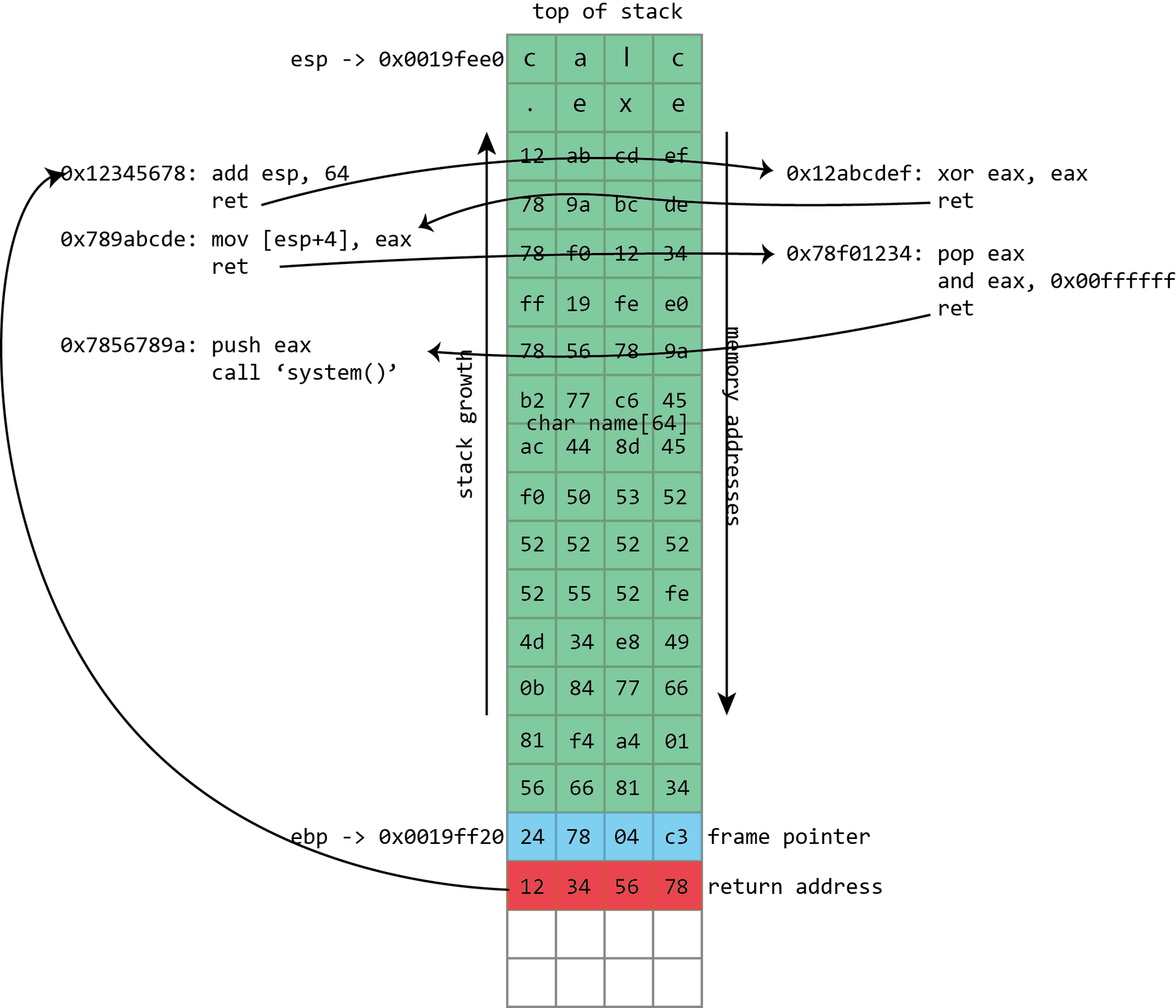
Here we see a simple scan of the stack with a 64-character buffer named name , followed by a frame pointer, then the return address. The esp register contains the vertex address, and ebp contains the frame pointer address.

The EIP contains the address of the current instruction. The processor maintains the eip value on its own. It reads a stream of instructions from memory and changes the value of eip accordingly, so that it always contains the address of the instruction. Within x86, there is an instruction for calling functions, call , and also an instruction for returning - ret .
CALL accepts one operand, the address of the function being called (although there are several ways to pass it). When a call is executed, the esp stack pointer is reduced by 4 bytes (32 bits), and the instruction address following the call — the return address — is placed in the memory area, which esp now points to. In other words, the return address is pushed onto the stack. Then, the value of eip is set equal to the address passed as the call operand, and execution continues from this point.
RET performs the reverse operation. A simple ret does not accept operands. The processor first reads the value of the memory address stored in esp, then increases esp by 4 bytes - removes the return address from the stack. The value is placed in the eip, and execution continues from this address.
(Translator's note: in this place in the author's text is a video with a demonstration of call and ret. )
If the call stack stored only a set of return addresses, there would be no problem . The real problem comes with everything else that is pushed onto the stack. So it turns out that the stack is a fast and efficient storage location. Storing data in a heap is relatively difficult: the program must keep track of the space available in the heap, how much each object takes and so on. At the same time, working with the stack is simple: to place some data, it is enough just to reduce the pointer value. And in order to clean up after itself, it is enough to increase the value of the pointer.
This convenience makes the stack a logical place to put the variables used by the function. Does the function need 256 bytes of buffer to accept user input? Easy, just subtract 256 from the stack pointer - and the buffer is ready. At the end of the function, simply add 256 to the pointer, and the buffer is dropped.
However, this approach has limitations. The stack is not suitable for storing very large objects: the total amount of available memory is usually fixed when creating a thread and, often, is about 1MB in size. Therefore, large objects should be placed in a heap. The stack is also not applicable to objects that need to exist for longer than a single function is executed. Since all placements in the stack are removed when the function leaves, the lifetime of any of the objects in the stack does not exceed the execution time of the corresponding function. Objects in the heap do not apply this restriction; they can exist forever.
When we use the program correctly, keyboard input is stored in the name buffer, closed by a null (null, zero) byte. The frame pointer and return address are not changed.
Stacking storage is used not only for variables explicitly defined by the programmer; The stack is also used to store any values the program needs. This is especially acute in x86. X86-based processors are not distinguished by a large number of registers (there are a total of 8 integer registers, and some of them, as already mentioned eip and esp, are already occupied), so functions rarely have the ability to store all the values they need in registers. To make room in registers, and at the same time save the value for later use, the compiler will put the register value on the stack. The value can later be removed from the register and placed back into the register. In compiler jargon, the process of saving registers with the possibility of subsequent use is called spilling .
Finally, the stack is often used to pass arguments to functions. The calling function pushes each of the arguments in turn onto the stack; The called function can remove them from the stack. This is not the only way to pass arguments - you can use registers, for example - but it is one of the most flexible.
A set of objects stored by a function on the stack — its own variables, saved registers, any arguments prepared for passing to other functions — are called “nested frame”. Since the data in the nested frame are actively used, it is useful to have a simple way of addressing it.
This can be done using the stack pointer, but this is somewhat inconvenient: the stack pointer always points to the vertex, and its value changes as objects are placed and removed. For example, a variable may first be located at the esp + 4 position. After two more values were pushed onto the stack, the variable became located at esp + 12. If one of the values is removed from the stack, the variable will be on esp + 8.
The described is not a heavy task, and compilers are able to cope with it. However, this makes use of the stack pointer to access anything other than the vertex “dumb”, especially when writing in assembler manually.
To simplify the task, it is usual to keep the second pointer, which stores the address of the “bottom” (ie, the beginning) of each frame — a value known as the pointer of the nested frame (frame pointer). And on x86 there is even a register, which is usually used for this, ebp . Since its value is constant within a function, a way to unambiguously address variable functions appears: the value lying at ebp-4 will remain accessible through ebp-4 the entire lifetime of the function. And this is useful not only for people - debuggers find it easier to figure out what is going on.
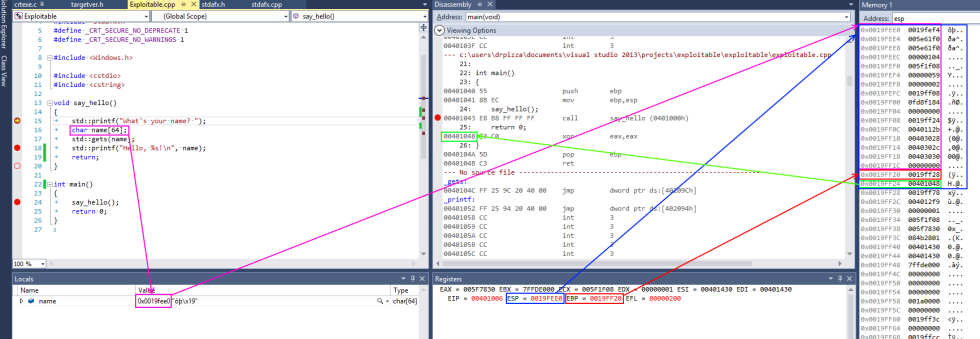
A screenshot from Visual Studio demonstrates all this in action using the example of a simple x86 program. On x86 processors, the esp register contains the address of the top of the stack, in this case, 0x0019fee0 (highlighted in blue). ( Author's note: on the x86 platform, the stack grows down towards the memory address 0, but this point still retains the name "top of the stack" ). The shown function stores only the name variable in the stack, highlighted in pink. This is a fixed buffer 64 bytes long. Since this is the only variable, its address is also 0x0019fee0 , the same as at the top of the stack.
The x86 also has an ebp register, highlighted in red, which is (usually) allocated to hold the frame pointer. The frame pointer is placed immediately after the stack variables. Immediately after the frame pointer is the return address highlighted in green. The return address refers to the code snippet at 0x00401048 . This instruction immediately follows the call, demonstrating how the return address is used to continue execution where the program left the calling function.
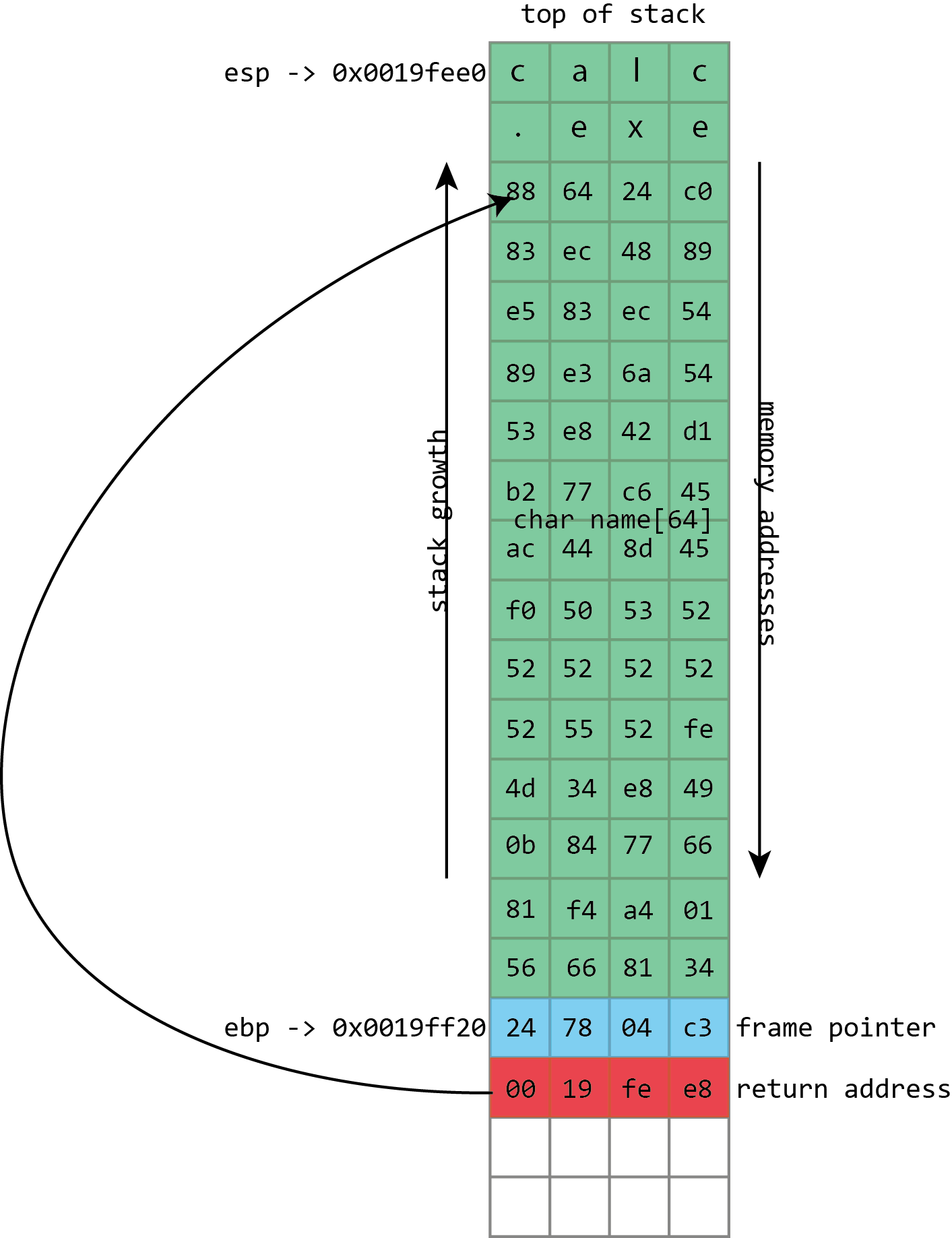
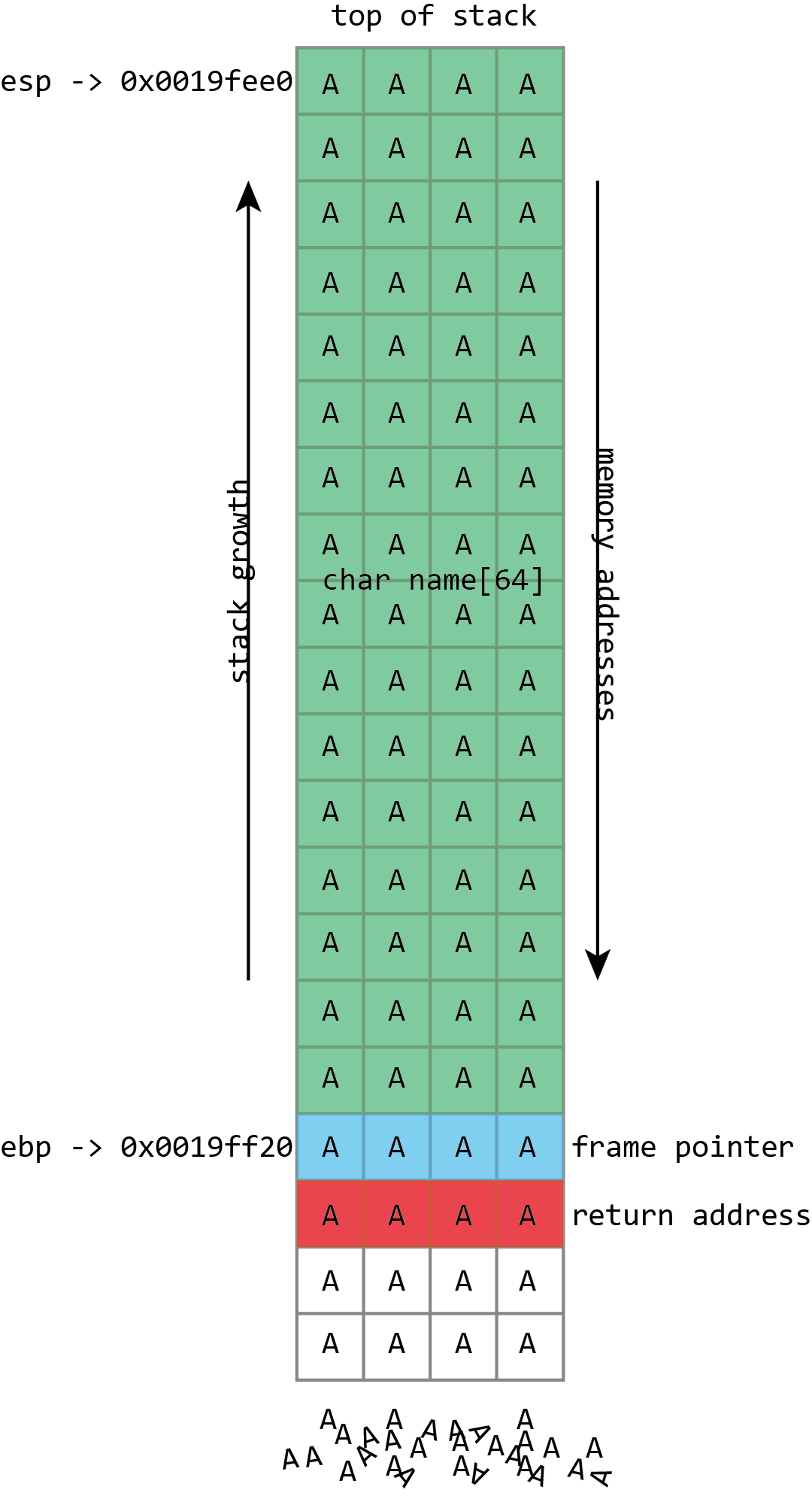
NAME in the illustration above refers to the kind of buffers that regularly overflow. Its size is fixed and is 64 bytes. In this case, it is filled with a set of numbers and ends with zero. It can be seen from the illustration that if more than 64 bytes are written to the name buffer, other values in the stack will be damaged. If you write four bytes more, the frame pointer will be destroyed. If you write eight bytes more, then both the frame pointer and the return address will be overwritten.
Obviously, this leads to corruption of program data, but the problem with buffer overflow is much more serious: they lead to the execution of [arbitrary] code. This is because a full buffer does not just overwrite the data. It may also be overwritten more important things stored in the stack - return addresses. The return address controls which instructions the processor will execute when finished with the current function; this is supposed to be some address inside the calling function, but if this value is overwritten by a buffer overflow, it can point anywhere. If attackers can control buffer overflows, then they can control the return address as well. If they control the return address, they can tell the processor what to do next.
The processor, most likely, does not have the beautiful convenient function “to compromise the machine” that the attacker would launch, but this is not too important. The same buffer that is used to change the return address can be used to store a small piece of executable code (shellcode, shellcode), which, in turn, will download a malicious executable file, or open a network connection, or perform any other attacker's wishes.
Traditionally, this was trivially simple, for the reason that many people are surprised: usually, each program will use the same addresses in memory every time it starts up, even if you restart the machine. This means that the position of the buffer on the stack will be the same every time, and therefore the value used to distort the return address will be the same every time. An attacker needs only to find out this address once, and the attack will work on any computer executing the vulnerable code.
Attacker toolkit
In an ideal world — from an attacker's point of view — the rewritten return address may simply be the buffer address. And it is quite possible when the program reads data from a file or from the network.
In other cases, the attacker must go for tricks. In functions that process human-readable text, a null byte (null) often has a special meaning; such a byte indicates the end of a line, and the functions used for manipulating strings — copying, comparing, combining — stop. when they meet this symbol. This means that if the shellcode contains zero, these procedures will break it.
(Translator's note: in this place in the author's text is a video showing the overflow. In it, the shellcode is placed in the buffer and the return address is rewritten. The shellcode starts the standard Windows calculator.)
To get around this, the attacker can use a variety of techniques. Small code snippets for converting shellcode with zeros to an equivalent sequence that avoids the problem byte. So it is possible to climb through even very strict restrictions; for example, the vulnerable function takes as input only data that can be typed from a standard keyboard.
The actual stack address often contains zeros, and there is a similar problem here: this means that the return address cannot be written to the address from the stack buffer. Sometimes this is not a problem, because some of the functions used to fill (and, potentially, overflow) buffers themselves write zeros. By taking some care, they can be used to put the zero byte at exactly the right place by setting the stack address in the return address.
But even when this is not possible, the situation is managed in a roundabout way (indirection). Actually the program with all its libraries keeps a huge amount of executable code in memory. Most of this code will have a “safe” address, i.e. will not have zeros in the address.
Then, the attacker needs to find a suitable address containing instructions like call esp (x86), , . call esp ; , . „“.
, , : , . , .
, , — . , , , call esp . , ( , 0xff 0xd4 ) --. - , ; x86 . x86 ( 15 !) . — , — , , . .
, , . , , . , , IP-, , . , , .
, „ “ (NOP sled, . „ NOP“ ( Halt — ..)). , , NOP ( „no-op“, .. — ), , . , - NOP. NOP, .
. , - ( ). .

C
, — , — -, . ( ) C, , C++ Objective C. C , , . , , C , .
C , gets() . — — (, , „“), . , gets () does not include the buffer size parameter, and as a fun C design fact, there is no way for the gets () function to determine the size of the buffer itself. This is because for gets () it is simply not important: the function will read from the standard input until the person behind the keyboard presses the Enter key; then the function will try to stuff it all into the buffer, even if this person has entered a lot more than is placed in the buffer.
This is a function that literally cannot be used safely. Since there is no way to limit the amount of text typed from the keyboard, there is no way to prevent the buffer overflow with the gets () function. The creators of the C standard quickly understood the problem; The 1999 version of the C specification removed gets () from circulation, and the 2011 update completely removes it. But its existence — and its periodic use — shows what kind of traps C prepares for its users.
The Morris worm, the first self-propagating malware that sprawled across the early Internet in a couple of days in 1988, exploited this feature. The fingerd program in BSD 4.3 listens on network port 79, the finger port . Finger Unix , , . : , , , .
, gets() . , name. , , , .
finger, — gets() — 512 . , fingerd finger, ( ). finger . Fingerd finger.
, „“ , 512 . . , gets(). 512 fingerd . (Robert Morris): fingerd 537 (536 , gets() ), . .
The executable load of the Morris worm was simple. It started with 400 NOP instructions, in case the stack layout is slightly different, then a short piece of code. This code called the shell, / bin / sh . This is a typical attack load; The fingerd program was launched under the root, so when it launched a shell during an attack, the shell also started under the root. Fingerd was connected to the network by accepting “keyboard input” and similarly sending the output back to the network. Both inherited the shell caused by the exploit, and this meant that the rueta shell was now accessible to the attacker remotely.
, gets() — fingerd gets() — C , . C. , — — C. C, , . C . , strcpy() , , strcat()that inserts the source line after the destination. None of these functions has a destination buffer size parameter. Both will happily read endlessly from the source until they meet a NULL, filling the destination buffer and carelessly overfilling it.
Even if the string function in C has a buffer size parameter, it implements it in a way leading to errors and overflows. In the C language, there are a couple of functions related to strcat () and strcpy (), called strncat () and strncpy () . Letter nin the names of these functions it means that they, in some way, take the size as a parameter. However, n, although many naive programmers think differently, is not the size of the buffer to which it is written - this is the number of characters to be read from the source. If the source has run out of characters (i.e., zero byte is reached), then strncpy () and strncat () will fill the remainder with zeros. Nothing in these functions checks the true size of the destination.
Unlike gets (), it is possible to use these functions in a safe manner, only this is not easy. C ++ and Objective-C have better alternatives to these C functions, which makes working with strings easier and safer, but C functions are also supported for backward compatibility.
, C: , , . Heartbleed OpenSSL. , , C OpenSSL , .
, , . , Mozilla Rust, Java .NET, Python, JavaScript, Lua Perl ( .NET , ).
, , C. , , . C, , OpenSSL. , C#, , C.
Performance is another reason for the continued use of C, although the meaning of this approach is not always clear. It's true that compiled C and C ++ usually produce fast executable code, and in some cases this is really very important. But many of us processors idle most of the time; if we could sacrifice, say, ten percent of the performance of our browsers, but at the same time get an iron guarantee of the impossibility of buffer overflow - and other typical holes, we could be decided that this is not a bad exchange. Only no one rushes to create such a browser.
In spite of everything, the C companions are not going anywhere; as well as buffer overflow.
. , , , . , AddressSanitizer , Valgrind .
, , , . , , , . , , .
. Linux , , , , ; C.
. - . , „“ (canary) . , . ( ), .
, W^X (»write exclusive-or execute"), DEP («data execution prevention»), NX («No Xecute»), XD («eXecute Disable»), EVP («Enhanced Virus Protection,» AMD ), XN («eXecute Never»), , , . . ( ) ( ), . , , .
No matter how you name it, this is also an important mechanism because it does not require investments. This approach uses protective measures built into the processor, since it is part of the hardware mechanism for supporting virtual memory.
As mentioned earlier, in virtual memory mode, each process gets its own set of private memory addresses. The operating system and processor together maintain the ratio of virtual addresses to something else ; sometimes, a virtual address is mapped to physical memory, sometimes to a portion of a file on disk, and sometimes to nowhere, simply because it is not distributed. This correlation is granular and usually occurs in parts of 4096 bytes called pages .
, , ( , , ) ; , : , . , , , , .
One of the interesting points about NX is that it can be applied to existing programs in hindsight, simply by upgrading the operating system to one that supports protection. Sometimes programs fly into trouble. JIT (Just-in-time) compilers used in Java and .NET generate executable code in memory at runtime, and therefore require memory, which can both be written and executed (although the simultaneity of these properties is not required). When NX was not yet available, you could execute code from any memory you could read, so such JIT compilers did not have problems with special read / write buffers. With the advent of NX, they are required to ensure that the memory protection is changed from read-write to read-executable.
The need for something like NX was clear, especially for Microsoft. In the early 2000s, a pair of worms showed that the company had serious code security issues: Code Red, which infected at least 359,000 systems running Windows 2000 with the Microsoft IIS Web server in July 2001, and SQL Slammer, which infected more than 75,000 systems with Microsoft SQL Server in January 2003. These cases hit the reputation well.
, , , , . ( , . , , .).
, . Code Red ; - DoS-. SQL Slammer — , ; — . , , , .
— — . Windows , . Microsoft . Windows XP Service Pack 2 . , , Internet Explorer, , — NX.
NX - 2004 , Intel Prescott Pentium 4, Windows XP SP2. Windows 8 , , NX.
NX
Despite the proliferation of NX support, buffer overflow remains an important information security issue. The reason for this is the development of a number of ways to circumvent the NX.
The first one was similar to the above described springboard, transferring control to the shellcode in the stack buffer via an instruction located in another library or executable file. Instead of looking for a piece of executable code that would transfer control directly to the stack, the attacker finds a piece that does something useful.
Perhaps the best candidate for this role is the Unix function system ().. It takes one parameter: the address of the string that represents the command to be executed - and usually this parameter is passed through the stack. The attacker can create the desired command and place it in an overflow buffer, and since (traditionally) the location of objects in memory is constant, the address of this string will be known and can be pushed onto the stack during the attack. The rewritten return address in this case does not indicate the address in the buffer; it points to the system () function . When the overflow function terminates, instead of returning to the calling function, it will start system () , which will execute the command given by the attacker.
That's how you can get around NX. System () function , , . ; . «return-to-libc» ( libc, Unix, , system(), Unix-, ) 1997 Solar Designer .
, . , . , , . , . — — , - .
, . - . , .
Over the years, return-to-libc has been generalized to circumvent these limitations. At the end of 2001, several options for extending this method were documented: the possibility of several calls and a solution to the problem of zero bytes. A more complex way, which solved most of these problems, was formally described in 2007 : return-oriented programming (ROP, return-oriented programming).
It uses the same principle as in return-to-libc and springboard, but is more general. Where the springboard uses a single piece of code to transfer the execution of the shellcode in the buffer, ROP uses many code fragments, called “gadgets” in the original publication. Each gadget follows a specific pattern: it performs an operation (writing a value to a register, writing to memory, adding registers, etc.), followed by a return command. The very property that makes x86 suitable for springboard works here too; The system libraries loaded into the process memory contain hundreds of sequences that can be interpreted as “action and return,” which means they can be used for ROP attacks.
To combine the gadgets into a single whole, a long sequence of return addresses (as well as any useful and necessary data) written onto the stack during a buffer overflow is used. Return instructions jump from a gadget to a gadget, while the processor rarely (or never) calls functions, but only returns from them. Interestingly, at least on x86, the number and variety of useful gadgets is such that the attacker literally can do anything ; This x86 subset, used in a special way, is often Turing-complete (although the full range of possibilities will depend on the libraries loaded by the program, and therefore the list of available gadgets).
As in the case of return-to-libc, all really executable code is taken from the system libraries, and as a result, protection like NX is useless. The greater flexibility of this approach means that exploits can do things that are difficult to organize by return-to-libc, for example, by calling functions that take arguments through registers, use the return values of some functions in others, and so on.
The load in the ROP attacks can be different. Sometimes this is a simple code to get a shell (access to the command interpreter). Another common option is to use ROP to call a system function to change the NX parameters of a memory page, changing them from writeable to executable. By doing this, the attacker can use the normal, non-ROP load.
Randomization
This weakness of NX has long been known, and exploits of this type are patterns: the attacker knows in advance the address of the stack and the system libraries in memory. Everything is based on this knowledge, and therefore the obvious solution is to deprive the attacker of this knowledge. This is exactly what ASLR (Address Space Layout Randomization) does: it randomizes the stack position and the location of the libraries and executable code in memory. Usually they change each time you start the program, reboot, or some combination of them.
This circumstance significantly complicates the operation, since, quite unexpectedly, the attacker does not know where the fragments of instructions necessary for the ROP lie, or at least where the stack is full.
ASLR largely accompanies NX, closing such large holes as a return to libc or ROP. Unfortunately, it is somewhat less transparent than NX. Apart from JIT compilers and a number of other specific cases, NX can be safely embedded into existing programs. ASLR is more problematic: with it, programs and libraries cannot rely in their work on the value of the address into which they are loaded.
In Windows, for example, this should not be a big problem for a DLL. In Windows, the DLL always supported loading in different addresses, but for EXE it can be a problem. Before ASLR, EXEs were always downloaded to 0x0040000 and could rely on this fact. With the introduction of ASLR, this is no longer the case. To prevent possible problems, Windows by default requires programs to explicitly indicate support for ASLR. Security-minded people, however, can change this default behavior, forcing Windows to enable ASLR for all programs and libraries. It almost never causes problems.
The situation is probably worse in Linux on x86, since the approach to implementing ASLR on this platform results in a performance loss of up to 26 percent. Moreover, this approach requires the compilation of programs and libraries with ASLR support. There is no way for an administrator to make ASLR enforced, as in Windows (on x64, the performance loss doesn’t go away at all, but is significantly reduced)
When ASLR is active, it provides strong protection against simple hacking. However, it is not perfect. For example, one of the limitations is the degree of randomness that can be obtained, which is especially noticeable on 32-bit systems. Although there are 4 billion different addresses in the address space, not all of them are available for loading libraries or stacking.
There are many limitations to this. Some of them are the breadth of goals. In general, the operating system prefers to load libraries close to each other, at one end of the process address space, so that as much uninterrupted space as possible is available to the application. You do not want to get one library every 256MB of memory, because then the possible largest unitary memory allocation will be less than 256MB, which limits the ability of the application to work with large data.
Executable files and libraries typically need to be loaded so that they start at least on the page border. Usually, this means that they must be loaded into an address divisible by 4096. Different platforms may have similar stack constraints; Linux, for example, will start a stack on an address divisible by 16. Systems with limited memory sometimes have to limit randomness even more in order to be able to place everything.
The results are different, but sometimes the attacker can guess the right address, with a high probability of hitting. Even a low chance — say, one out of 256 — may be enough in some situations. When you attack a web server that automatically restarts the crashed process, it doesn't matter that 255 of the 256 attacks will crash the process. It will be restarted and you can try again.
But on 64-bit systems, the address space is so large that such an approach does not help. An attacker can only have one chance in a million, or even one in a billion, and this is small enough that it doesn’t matter.
Guessing and falling is not a good strategy for attacking, say, browsers; no user will restart the browser 256 times in a row just to give the attacker a chance. As a result, the exploitation of such a vulnerability in a system with active NX and ASLR cannot be performed without assistance.
Such assistance may be of several types. In a browser, you can use JavaScript or Flash — both of which contain JIT compilers that generate executable code — to fill the memory with neatly constructed executable code. This creates something like a large landing strip, a technique called “heap spraying” (“spraying a heap”). Another approach may be to find a secondary bug that allows you to open the library or stack addresses in memory, giving the attacker enough information to create a specific set of return addresses for the ROP.
The third approach was also popular in browsers: use libraries that cannot ASLR. Older versions, such as Adobe PDF or Microsoft Office plug-ins, did not support ASLR, and Windows does not force ASLR by default. If an attacker can cause the download of such a library (for example, by downloading PDF in a hidden browser frame), then you should not worry about ASLR, but use this library for ROP purposes.
War without end
There is a constant arms race between those who exploit vulnerabilities and those who protect. Powerful defenses, such as ASLR and NX, raise the bar, complicating the use of flaws, and thanks to them we have left the times of a simple buffer overflow behind, but smart attackers can find a combination of holes and circumvent these defensive measures.
Escalation continues. The Microsoft EMET kit (“Enhanced Mitigation Experience Toolkit”, “Enhanced Mitigation Toolkit”) includes a series of semi-experimental protections that can detect heap spraying or attempts to call certain critical functions in ROP exploits. But in a continuous digital war, even some of these techniques have already been defeated. This does not make them useless - the complexity (and hence the price) of exploiting vulnerabilities increases with every countermeasure used — but this is a reminder of the need for constant vigilance.
Source: https://habr.com/ru/post/266591/
All Articles