The way of writing parsers in c ++
This article describes how to write parsers using this small C ++ library.
Usually, the text in the machine language consists of sentences, those from subproposals, and those in turn from subproposals, and so on up to symbols.
For example, an xml element consists of an opening tag, a content, and a closing tag. -> The opening tag consists of '<', the name of the tag, perhaps an empty attribute list and '>'. -> The closing tag consists of '</', the tag name and '>'. -> Attribute consists of name, '=', '"' characters, character strings and again '"'. -> Content in turn may also contain elements. -> Etc. Thus, after parsing, a syntax tree is obtained.
')
Such languages are conveniently described by the Backus-Naur form (BNF), where each non-terminal corresponds to a certain sentence of the language. When we write programs, we usually break them down into functions and subfunctions, and since we are going to write a parser, let each non-terminal BNF have one function of our analyzer, and let each such function:
For example, for a BNF of the form
And for the BNF clause of the form
(I think this is called parsing with returns)
Not every text satisfying the BNF may suit us. For example, an element of the xml language can be described as:
Terminal functions may look like this:
So far we have been doing the parsing of the string. But note that for all types of the above functions, iterator forward is sufficient.
Let us set ourselves the goal of creating a stream class providing forward iterators and storing the file in memory not entirely but in small pieces. Then, if you make the parsing functions template, then they can be used with strings and with threads. (Which is done in “base_parse.h” for terminal (and so) functions.) But first, we will make some clarifications to the unix ideology “everything is a file”: There are files located on the disk - they can be read several times and from any position ( let's call them random-access files). And there are streams redirected from other programs, going over the network or from the user from the keyboard (let's call them forward streams). Such streams can only be read in one pass. (fixme) Therefore, in order to work with both, we set ourselves the goal of creating a stream class reading a file in one pass, providing forward iterators, and storing the file in memory not entirely but in small pieces.
For input iterators, such streams are implemented for a very long time; in fact, they contain only one input iterator, and inside they contain one buffer through which this iterator moves, and when it comes to the end of the buffer, the next piece of the file is loaded into this buffer, and the iterator starts moving from the beginning of the updated buffer.
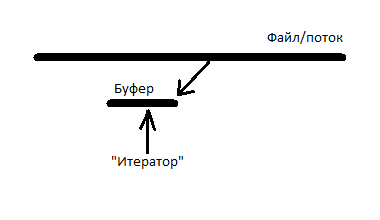
Forward iterators differ from input iterators in that they can be copied. For a stream with forward iterators, the solution will be a list of buffers. As soon as any iterator goes beyond the limits of the rightmost buffer, a new buffer is added to the list, and populated directly from the file with a data block. But gradually, the whole file will be loaded into memory, but we don’t want it. Let's make it so that all buffers are deleted, which are to the left of the buffer on which the leftmost (lagging) iterator is located. But we will not compare the list of iterators on it to each buffer, but we will only compare their number (iterator counting). As soon as any buffer finds out that there are 0 iterators left on it and that it is the leftmost one, then it and all neighboring buffers are deleted to the right of it, on which there are also 0 iterators.
It turns out that each iterator should contain:
When the iterator reaches the buffer boundary, it looks to see whether the next buffer is in the list of buffers; if it does not exist, it loads it, decrements the iterator count in the previous buffer, and increases it in the next one. If the previous buffer contains 0 iterators, it is deleted. If the iterator has reached the end of the file, it only decouples from the previous buffer and goes to the “end of file” state. When copying an iterator, the iterator count on the buffer on which it is located increases, and when the iterator destructor is called, the counter decreases, and again, if there are 0 iterators on the buffer, then it and the adjacent buffers, on which also 0 iterators, are deleted . For implementation details, see forward_ht.h .
Such iterators have some features of use that distinguish them from ordinary iterators. So, for example, before a flow is destroyed (destructor) (which stores a list of buffers and some additional information) all iterators should be destroyed, since when destroyed, they will access buffers regardless of whether they are destroyed in turn or not. If we once received the first iterator as a result of calling the begin () method (and created the first buffer), and it left so much that the first buffer has already been deleted, we will not be able to get the iterator again using the begin () method. Also (as will be seen in the next paragraph) the stream does not have the end () method. As a result, I decided to make an internal iterator in the stream, which is initialized when the entire stream is initialized, and a link to which can be obtained using the iter () method. Also, when used in algorithms, it is not worth once again to copy iterators, since buffers are stored in memory from the leftmost to the rightmost iterator, and in the case of large files this can lead to a large memory footprint.
As a bonus, there are various types of buffers: simple (basic_simple_buffer), with the calculation of a column row by iterator (basic_adressed_buffer), it is planned to make a buffer that performs the conversion between different encodings. In this connection, the stream is parameterized by the type of buffer.
The end of the string is defined by a null character. This means that while we are moving along a line in order to detect its end, we need not compare the pointer with another pointer (as is traditionally done in STL), but rather check the value indicated by our pointer. With files, the situation is approximately the same: when character chars are entered character by character, we get ints, and since they have a greater range of values, again we test each symbol for equality EOF. The fact that the forward end position of the file is unknown in advance adds fuel to the fire.
This information can be generalized by making the function atend (it), which for pointers on a line will look like this:
And for iterators over the stream, it will return true when the iterator points to the end of the file.
Block buffering is not suitable for interactive user interaction (via stdin), since In a block, several lines most often fit, and after entering one line, the program continues to wait for input from the user, since the block is still empty. This requires string buffering, when the buffer is filled with characters up to the line feed character. In this library, you can select the type of buffering by choosing the type of file from which the stream is initialized (basic_block_file_on_FILE or string_file_on_FILE).
strin is an internal stream iterator over stdin with string buffering.
For non-interactive files when creating a stream, an iterator is created that points to the first character, which means that the first buffer is loaded. For strin'a this is not permissible, because the programmer may want to do something or display something before the program goes into standby mode.
Therefore, when filling the first buffer, string files produce a dummy string "\ n". To read it, there is a function start_read_line (it), after which the program goes into standby mode for entering a string, after which it is possible to parse this string without outputting iterators beyond the next '\ n' character.
The programmer's field of analysis may want to display something again, and if after that he again needs data from the user, then start_read_line (strin) should be called again before receiving it.
So a cycle is obtained:
Of course, this is a crutch, and it would be possible to make iterators that require loading the buffer only during dereferencing, but this would lead to additional checks when unfolding and simply complicating the entire system ...
So that the user does not have to re-write terminal functions every time, they are already implemented in “base_parse.h” . Now they are implemented (except for handling floating numbers) in general, it is further planned to specialize them using string functions (such as strcmp, strstr, strchr, strspn, strcspn) for pointers in rows and for thread iterators. They also allow the user to almost not think about the end of the file, and simply set the style of the code.
Below is a brief summary of the basic functions of parsing, the returned values and the statistics of their use in the implementation of two test parsers.
Since it is convenient to return an error code or an error message through the function name, so that the text of the parsers would look more obvious, I made special macros:
Although it is possible to make some class that stores this information and is converted to bool accordingly.
In general, I am opposed to non-constant references, and I believe that the arguments that the function should change should be passed to it by pointer and not by reference, so that when calling it it would be visible, but due to the fact that operators for pointers to anything it was impossible to overload, especially for compatibility with operator >> () (a couple of these are defined in "strin.h") I pass iterators everywhere by reference (and return values from the pointer).
At the moment there are two examples of using these functions: calc.cpp and winreg.cpp .
Thus, writing a parser does not require the ability to handle other parser generation programs. Each non-terminal BNF translates into a function that, of course, is cumbersome compared to the description in the BNF (this can be further corrected by making a function that parses the regular expression, similarly as in <boost / xpressive>), but add any validation and data processing. All this can be done both with strings and with threads in the same form. The default input stream is ready for default input, and the >> operators, similar to those from the standard library, allow using this library instead of the standard input library.
How to do tokenization using forward_stream, I will try to tell and show in the next article.
Usually, the text in the machine language consists of sentences, those from subproposals, and those in turn from subproposals, and so on up to symbols.
For example, an xml element consists of an opening tag, a content, and a closing tag. -> The opening tag consists of '<', the name of the tag, perhaps an empty attribute list and '>'. -> The closing tag consists of '</', the tag name and '>'. -> Attribute consists of name, '=', '"' characters, character strings and again '"'. -> Content in turn may also contain elements. -> Etc. Thus, after parsing, a syntax tree is obtained.
')
Such languages are conveniently described by the Backus-Naur form (BNF), where each non-terminal corresponds to a certain sentence of the language. When we write programs, we usually break them down into functions and subfunctions, and since we are going to write a parser, let each non-terminal BNF have one function of our analyzer, and let each such function:
- trying to parse this sentence from a given position
- returns, did she manage to do it
- returns the position where the parsing ended or an error occurred
- and also, perhaps, returns some additional data that we want to receive as a result of parsing
For example, for a BNF of the form
expr ::= expr1 expr2 expr3 we will write the following function: bool read_expr(char *& p, ....){ if(!read_expr1(p, ....)) return false; // read_expr1() p , expr1 // p if(!read_expr2(p, ....)) return false; if(!read_expr3(p, ....)) return false; /* */ return true; } And for the BNF clause of the form
expr ::= expr1 | expr2 | expr3 expr ::= expr1 | expr2 | expr3 expr ::= expr1 | expr2 | expr3 - function: bool read_expr(const char *& p, ....){ const char * l = p; if(read_expr1(p, ....)) return true; //p , expr1 p = l; if(read_expr2(p, ....)) return true; p = l; if(read_expr3(p, ....)) return true; return false; /* */ } (I think this is called parsing with returns)
Not every text satisfying the BNF may suit us. For example, an element of the xml language can be described as:
element ::= '<'identifier'>'some_data'</'identifier'>' , but this clause will only be an element if the identifiers match. Such (or similar) checks can be easily added to parsing functions.Terminal functions may look like this:
bool read_fix_char(const char *& it, char c){ if(!*it) return false;// if(*it!=c) return false;// // it++; // return true; } bool read_fix_str(const char * & it, const ch_t * s){ while(*it)// if(!*s) return true; else if(*it!=*s) return false; // else it++, s++; if(!*s) return true; return false;// } So far we have been doing the parsing of the string. But note that for all types of the above functions, iterator forward is sufficient.
forward stream
Let us set ourselves the goal of creating a stream class providing forward iterators and storing the file in memory not entirely but in small pieces. Then, if you make the parsing functions template, then they can be used with strings and with threads. (Which is done in “base_parse.h” for terminal (and so) functions.) But first, we will make some clarifications to the unix ideology “everything is a file”: There are files located on the disk - they can be read several times and from any position ( let's call them random-access files). And there are streams redirected from other programs, going over the network or from the user from the keyboard (let's call them forward streams). Such streams can only be read in one pass. (fixme) Therefore, in order to work with both, we set ourselves the goal of creating a stream class reading a file in one pass, providing forward iterators, and storing the file in memory not entirely but in small pieces.
For input iterators, such streams are implemented for a very long time; in fact, they contain only one input iterator, and inside they contain one buffer through which this iterator moves, and when it comes to the end of the buffer, the next piece of the file is loaded into this buffer, and the iterator starts moving from the beginning of the updated buffer.
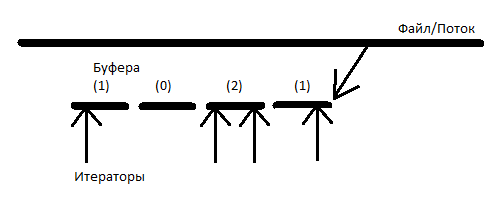
Forward iterators differ from input iterators in that they can be copied. For a stream with forward iterators, the solution will be a list of buffers. As soon as any iterator goes beyond the limits of the rightmost buffer, a new buffer is added to the list, and populated directly from the file with a data block. But gradually, the whole file will be loaded into memory, but we don’t want it. Let's make it so that all buffers are deleted, which are to the left of the buffer on which the leftmost (lagging) iterator is located. But we will not compare the list of iterators on it to each buffer, but we will only compare their number (iterator counting). As soon as any buffer finds out that there are 0 iterators left on it and that it is the leftmost one, then it and all neighboring buffers are deleted to the right of it, on which there are also 0 iterators.
It turns out that each iterator should contain:
- pointer to character (which will be returned when dereference)
- pointer to the end of the array of characters in the buffer (it is compared when the iterator is moved)
- iterator over the list of buffers (to access the buffer data, and through them to the data of the entire stream).
When the iterator reaches the buffer boundary, it looks to see whether the next buffer is in the list of buffers; if it does not exist, it loads it, decrements the iterator count in the previous buffer, and increases it in the next one. If the previous buffer contains 0 iterators, it is deleted. If the iterator has reached the end of the file, it only decouples from the previous buffer and goes to the “end of file” state. When copying an iterator, the iterator count on the buffer on which it is located increases, and when the iterator destructor is called, the counter decreases, and again, if there are 0 iterators on the buffer, then it and the adjacent buffers, on which also 0 iterators, are deleted . For implementation details, see forward_ht.h .
Such iterators have some features of use that distinguish them from ordinary iterators. So, for example, before a flow is destroyed (destructor) (which stores a list of buffers and some additional information) all iterators should be destroyed, since when destroyed, they will access buffers regardless of whether they are destroyed in turn or not. If we once received the first iterator as a result of calling the begin () method (and created the first buffer), and it left so much that the first buffer has already been deleted, we will not be able to get the iterator again using the begin () method. Also (as will be seen in the next paragraph) the stream does not have the end () method. As a result, I decided to make an internal iterator in the stream, which is initialized when the entire stream is initialized, and a link to which can be obtained using the iter () method. Also, when used in algorithms, it is not worth once again to copy iterators, since buffers are stored in memory from the leftmost to the rightmost iterator, and in the case of large files this can lead to a large memory footprint.
As a bonus, there are various types of buffers: simple (basic_simple_buffer), with the calculation of a column row by iterator (basic_adressed_buffer), it is planned to make a buffer that performs the conversion between different encodings. In this connection, the stream is parameterized by the type of buffer.
atend ()
The end of the string is defined by a null character. This means that while we are moving along a line in order to detect its end, we need not compare the pointer with another pointer (as is traditionally done in STL), but rather check the value indicated by our pointer. With files, the situation is approximately the same: when character chars are entered character by character, we get ints, and since they have a greater range of values, again we test each symbol for equality EOF. The fact that the forward end position of the file is unknown in advance adds fuel to the fire.
This information can be generalized by making the function atend (it), which for pointers on a line will look like this:
bool atend(const char * p) { return !*p; } And for iterators over the stream, it will return true when the iterator points to the end of the file.
strin
Block buffering is not suitable for interactive user interaction (via stdin), since In a block, several lines most often fit, and after entering one line, the program continues to wait for input from the user, since the block is still empty. This requires string buffering, when the buffer is filled with characters up to the line feed character. In this library, you can select the type of buffering by choosing the type of file from which the stream is initialized (basic_block_file_on_FILE or string_file_on_FILE).
strin is an internal stream iterator over stdin with string buffering.
For non-interactive files when creating a stream, an iterator is created that points to the first character, which means that the first buffer is loaded. For strin'a this is not permissible, because the programmer may want to do something or display something before the program goes into standby mode.
Therefore, when filling the first buffer, string files produce a dummy string "\ n". To read it, there is a function start_read_line (it), after which the program goes into standby mode for entering a string, after which it is possible to parse this string without outputting iterators beyond the next '\ n' character.
The programmer's field of analysis may want to display something again, and if after that he again needs data from the user, then start_read_line (strin) should be called again before receiving it.
So a cycle is obtained:
while(true){ cout << "" <<endl; start_read_line(strin); // analys(strin); } Of course, this is a crutch, and it would be possible to make iterators that require loading the buffer only during dereferencing, but this would lead to additional checks when unfolding and simply complicating the entire system ...
Basic parsing functions
So that the user does not have to re-write terminal functions every time, they are already implemented in “base_parse.h” . Now they are implemented (except for handling floating numbers) in general, it is further planned to specialize them using string functions (such as strcmp, strstr, strchr, strspn, strcspn) for pointers in rows and for thread iterators. They also allow the user to almost not think about the end of the file, and simply set the style of the code.
Below is a brief summary of the basic functions of parsing, the returned values and the statistics of their use in the implementation of two test parsers.
size_t n ch_t c ch_t * s func_obj bool is(c) // bool isspace(c) span spn // bispan bspn // func_obj err pf(it*) // int read_spc(it*) func_obj err pf(it*, rez*) len - - , *pstr . .. EOF EOF int read_until_eof (it&) .*$ 0 0 1 OK int read_until_eof (it&, pstr*) .*$ len len OK int read_fix_length (it&, n) .{n} -1 0 OK int read_fix_length (it&, n, pstr*) .{n} -(1+len) 0 2 OK int read_fix_str (it&, s) str -(1+len) 0 (1+len) 9 OK int read_fix_char (it&, c) c -1 0 1 11 OK int read_charclass (it&, is) [ ] -1 0 1 OK int read_charclass (it&, spn) [ ] -1 0 1 OK int read_charclass (it&, bspn) [ ] -1 0 1 OK int read_charclass_s (it&, is, pstr*) [ ] -1 0 1 OK int read_charclass_s (it&, spn, pstr*) [ ] -1 0 1 1 OK int read_charclass_s (it&, bspn, pstr*) [ ] -1 0 1 5 OK int read_charclass_c (it&, is, ch*) [ ] -1 0 1 OK int read_charclass_c (it&, spn, ch*) [ ] -1 0 1 1 OK int read_charclass_c (it&, bspn, ch*) [ ] -1 0 1 OK int read_c (it&, ch*) . -1 0 5 OK int read_while_charclass (it&, is) [ ]* -(1+len) len OK int read_while_charclass (it&, spn) [ ]* -(1+len) len 2 OK int read_while_charclass (it&, bspn) [ ]* -(1+len) len OK int read_while_charclass (it&, is, pstr*) [ ]* -(1+len) len OK int read_while_charclass (it&, spn, pstr*) [ ]* -(1+len) len OK int read_while_charclass (it&, bspn, pstr*) [ ]* -(1+len) len 1 OK int read_until_charclass (it&, is) .*[ ]<- -(1+len) len OK int read_until_charclass (it&, spn) .*[ ]<- -(1+len) len 1 OK int read_until_charclass (it&, bspn) .*[ ]<- -(1+len) len OK int read_until_charclass (it&, is, pstr*) .*[ ]<- -(1+len) len OK int read_until_charclass (it&, spn, pstr*) .*[ ]<- -(1+len) len 2 OK int read_until_charclass (it&, bspn, pstr*) .*[ ]<- -(1+len) len OK int read_until_char (it&, c) .*c -(1+len) len OK int read_until_char (it&, c, pstr*) .*c -(1+len) len OK <- - , int read_until_str (it&, s) .*str -(1+len) len 2 OK int read_until_str (it&, s, pstr*) .*str -(1+len) len 1 OK int read_until_pattern (it&, pf) .*( ) -(1+len) len OK int read_until_pattern (it&, pf, rez*) .*( ) -(1+len) len OK int read_until_pattern_s (it&, pf, pstr*) .*( ) -(1+len) len OK int read_until_pattern_s (it&, pf, pstr*, rez*) .*( ) -(1+len) len OK ch_t c ch_t * s func_obj bool is(c) // bool isspace(c) span spn // bispan bspn // func_obj err pf(it*) // int read_spc(it*) func_obj err pf(it*, rez*) len - - , *pstr . .. EOF EOF int read_line (it&, s) .*[\r\n]<- -1 len len OK int read_line (it&) .*[\r\n]<- -1 len len 1 OK int start_read_line (it&) .*(\n|\r\n?) -1 0 1 8 OK <- - , int read_spc (it&) [:space:] -(1+len) len OK int read_spcs (it&) [:space:]* -(1+len) len 5 OK int read_s_fix_str (it&, s) [:space:]*str -(1+len) 0 len 1 OK int read_s_fix_char (it&, c) [:space:]*c -1 0 1 8 OK int read_s_charclass (it&, is) [:space:][ ] -1 0 1 OK int read_s_charclass_s (it&, is, pstr*) [:space:][ ] -1 0 1 OK int read_s_charclass_c (it&, is, pc*) [:space:][ ] -1 0 1 2 OK int read_bln (it&) [:blank:] -(1+len) len OK int read_blns (it&) [:blank:]* -(1+len) len 1 OK int read_b_fix_str (it&, s) [:blank:]*str -(1+len) 0 len OK int read_b_fix_char (it&, c) [:blank:]*c -1 0 1 OK int read_b_charclass (it&, is) [:blank:][ ] -1 0 1 OK int read_b_charclass_s (it&, is, pstr*) [:blank:][ ] -1 0 1 OK int read_b_charclass_c (it&, is, pc*) [:blank:][ ] -1 0 1 OK int_t : long, long long, unsigned long, unsigned long long - [:digit:] ::= [0-"$(($ss-1))"] sign ::= ('+'|'-') int ::= spcs[sign]spcs[:digit:]+ . . [w]char char16/32 stream_string . .. int read_digit (it&, int ss, int_t*) [:digit:] 1 -1(EOF) 1 OK int read_uint (it&, int ss, int_t*) [:digit:]+ 1 -1 1 OK int read_sign_uint (it&, int ss, int_t*) [sign][:digit:]+ 1 -1 OK int read_sign_s_uint (it&, int ss, int_t*) [sign]spcs[:digit:]+ 1 -1 1 OK int read_int (it&, int ss, int_t*) spcs[sign]spcs[:digit:]+ 1 -1 1 OK OK int read_dec (it&, int_t*) int#[:digit:]=[0-9] 1 -1 1 OK OK int read_hex (it&, int_t*) int#[:digit:]=[:xdigit:] 1 -1 OK OK int read_oct (it&, int_t*) int#[:digit:]=[0-7] 1 -1 OK OK int read_bin (it&, int_t*) int#[:digit:]=[01] 1 -1 OK OK Since it is convenient to return an error code or an error message through the function name, so that the text of the parsers would look more obvious, I made special macros:
#define r_if(expr) if((expr)==0) #define r_while(expr) while((expr)==0) #define r_ifnot(expr) if(expr) #define r_whilenot(expr) while(expr) /* r_ifnot(err=read_smth(it))// - return err; */ // read_while_sm read_until #define rm_if(expr) if((expr)>=0) // . . '.*' * - multiple -> m #define rm_while(expr) while((expr)>=0) #define rm_ifnot(expr) if((expr)<0) #define rm_whilenot(expr) while((expr)<0) #define rp_if(expr) if((expr)>0) // . . '.+' + - plus -> p #define rp_while(expr) while((expr)>0) #define rp_ifnot(expr) if((expr)<=0) #define rp_whilenot(expr) while((expr)<=0) /* rm_if(read_until_char(it,'\n'))// 0 \n rp_if(read_until_char(it,'\n'))// 1 \n */ Although it is possible to make some class that stores this information and is converted to bool accordingly.
In general, I am opposed to non-constant references, and I believe that the arguments that the function should change should be passed to it by pointer and not by reference, so that when calling it it would be visible, but due to the fact that operators for pointers to anything it was impossible to overload, especially for compatibility with operator >> () (a couple of these are defined in "strin.h") I pass iterators everywhere by reference (and return values from the pointer).
At the moment there are two examples of using these functions: calc.cpp and winreg.cpp .
Thus, writing a parser does not require the ability to handle other parser generation programs. Each non-terminal BNF translates into a function that, of course, is cumbersome compared to the description in the BNF (this can be further corrected by making a function that parses the regular expression, similarly as in <boost / xpressive>), but add any validation and data processing. All this can be done both with strings and with threads in the same form. The default input stream is ready for default input, and the >> operators, similar to those from the standard library, allow using this library instead of the standard input library.
How to do tokenization using forward_stream, I will try to tell and show in the next article.
Source: https://habr.com/ru/post/266589/
All Articles