How I stopped worrying and started committing to GIT on a big 1C-Bitrix project

I had the opportunity to work for a long time as an admin manager (a kind of playing trainer) on a large 1C-Bitrix web project: over 40 sites for various holding organizations from different countries, Oracle DB, Web Cluster editorial, more than 100 GB of files, several years of history , more than 20 edits of the kernel that survived many updates of the Kernel, paranoid security mode and ... direct changes in the functionality of the "hands" on the battle server without any hints of version control ...
Very sad picture, causing many "accidents at work", which after the next incident was ordered to be corrected.
This article describes my experience, but it will be useful primarily for owners of small Internet projects who have never used a version control system and do not know where to start.
Actually all our troubles were due to 2 main reasons:
- The big project was running at full speed along its narrow gauge railway into a bright future, and it was a bit difficult to change the rails under it at that moment.
- Despite the huge amount of literature devoted to version control systems and GIT in particular, almost all of it suffers from a lack of scripts and clear guidelines. For example, the magnificent Pro Git perfectly describes each individual function and operation, but almost does not give an idea of which end to start using this wealth.
Captain obvious
My most important advice to anyone who wants to start using GIT is to start.
Just take and start at least with something.
And then complicate.
Personally, I was very helped to put scripts and instructions on the shelves.
Just take and start at least with something.
And then complicate.
Personally, I was very helped to put scripts and instructions on the shelves.
')
The narration will be divided into parts:
- Description of the situation
- Instruments
- Instructions
- 3.1 Initializing the Repository
- 3.2 Nakat task update
- 3.3 Committing daily changes (at the end of the day)
- 3.4 Roll back changes
- Conclusion
- FAQ
Part 1 - Description of the situation
I am directly on the territory of the Customer and serve as a kind of bridge between him and the Developer.
Good security guards of the Customer limit access to everything that can be at least something replaced.
Probably, this article would never have appeared (and the problems hiding behind it would be much less) if both I and the Developer had SSH / FTP access.
However, there was no such access, no, and probably it will not, since a purely formal introduction of changes is possible in 2 ways:
- Remotely through the admin panel 1C-Bitrix
- Directly on the territory of the Customer (under the strict supervision)
Therefore, when rolling out some tasks, I occasionally received a call from the Developer Manager:
Alexey, we want to roll out task XXX here. Zabekapte please init.php, but it is not enough ...
Naturally, “you never know,” it sometimes came, and the request to restore the specified file went all along the chain, and the site was unavailable at that time
Similarly, access to the Central Repository (GitLab), when it was created, was limited entirely to the territory of the Customer. This leads to important restrictions on the implementation of GIT:
- The developer cannot get a repo from the Customer’s servers (only if he copies the .git folder by hand)
- The developer can not roll the update using GIT. Roll forward manually.
The version control systems of the Customer and the Developer are actually isolated from each other (the message occurs exclusively in manual mode through the 1C-Bitrix admin panel).
And also administrative access (1 group 1C-Bitrix) is limited in time. There is a special script that, at the DB level (Oracle), distributes the rights to me and the Developer at 9.00 and selects at 17.50 in Moscow.
I know this is a nightmare. Do not remind me of this in the comments. =)
Part 2 - Tools
2.1 Servers
Prod - the main battle server.
At the direction of the authorities were created in addition to the Battle Server 2 copies:
- Test - can be recreated upon request (the process is long, since it requires the involvement of people from other departments, the estimated implementation period is 24 hours). The server is accessible only from the Customer’s and Developer’s networks.
- Prelive - automatically re-created 1 time per day (at night), erasing all the changes made, takes the version of the Battle Server that is current at the time of creation. The server is accessible only from the Customer’s and Developer’s networks.
Access to all 3 servers, both for me and for the Developer, is only via https (an automatic authorization in 1C-Bitrix takes place according to the certificate).
SSH / FTP access only from my immediate superior . = (
GitLab is a separate server for deploying GitLab, used as the Central Repository. The server is accessible only from the Customer’s network by direct IP (suppose that 172. ***. ***. 61 is for the specifics of this article, but in fact it can be any IP or domain, in your case, for example, github.com) .
All 3 web servers (Prod / Test / Prelive) have ssh access to GitLab.
I only have access to GitLab via http (in fact, I can only create / delete repositories and watch a beautiful picture with branches).
DEV - The symbol for the segment of servers and workstations of the Developer. This article is not considered. All changes from the segment are transferred to the Customer’s server by hand through the 1C-Bitrix admin panel by me or by the Developer.
The initial task reloading scheme assumed the passage of the entire chain:
DEV → TEST → PRELIVE → PROD
The final test was supposed to be on the “most relevant” Prelaive before rolling the task into battle. The scheme naturally turned out to be very dreary and of little use.
At the moment, I abandoned it in favor of using 2 servers for checking Tasks (on Test, requiring long checks, on Prelive, they are quickly checked):
DEV → TEST / PRELIVE → PROD
The transfer of code from one server to another in the Customer segment occurs ONLY through the Central Repository (GitLab), so that the run-up scheme can be represented as follows:
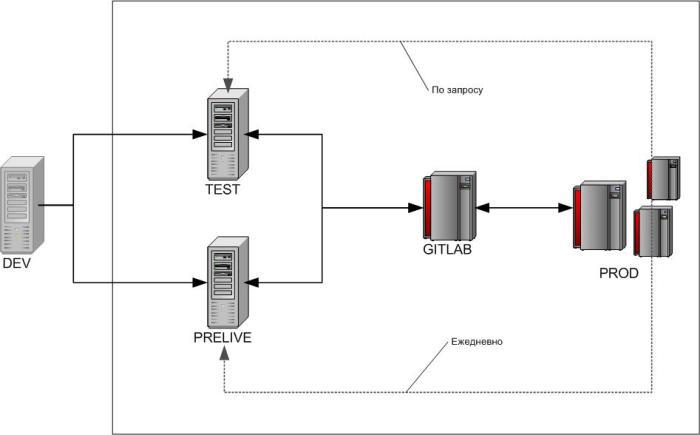
2.1.1 GIT on the server
Installed by the system administrator. Unfortunately, I can’t tell anything really useful on this topic (the question goes beyond my competence).
No special manipulations other than generating SSH keys (for communication between servers and Central Repository (GitLab)).
The instruction is easily googled, or is in the help section of GitLab.
2.1.2 Web console on the server (git_console.php)
As mentioned above, neither I nor the Developer have SSH access to the servers, so to transfer the GIT commands I had to install a separate script that implements the console in the browser.
Thanks for it Elfet ( article about the console on Habré )
We made very minor changes:
- They put the console itself in a directory inaccessible to the Developer in the server's depths (so that neither the Developer, nor I
, nor “the potential Malicious usercould make changes to the console code). At the same time, in the kernel we put the git_console.php file available to administrators, which simply connects the script from the depths; - In the settings of the script put a restriction on the execution of commands (only git, pwd and cd);
- Changed the console background color (Test - green, Prelive - gray, Prod - black). This was done after I was glad to start the task “not there” =)
- Added access restriction by certificate (i.e. not every Admin has access to the console. During the test period, only I had access, after transferring to commercial operation, access was given to 1 Developer programmer).
An important advantage of this solution is console autonomy! Those. even if the Developer puts an unsuccessful
2.1.3 Repository Structure
Unfortunately, not all sites in the system are under the version control system, but only the “heads” of the holding. This causes certain inconveniences and problems (for example, when the Developer makes an amendment to the Kernel for some of the Daughters), but this is mainly a problem for the owners of these sites “on the ground”. Perhaps in the future, despite the overheads and they will be added to the GIT.
Scheme of the real repository structure (names and addresses partially erased):
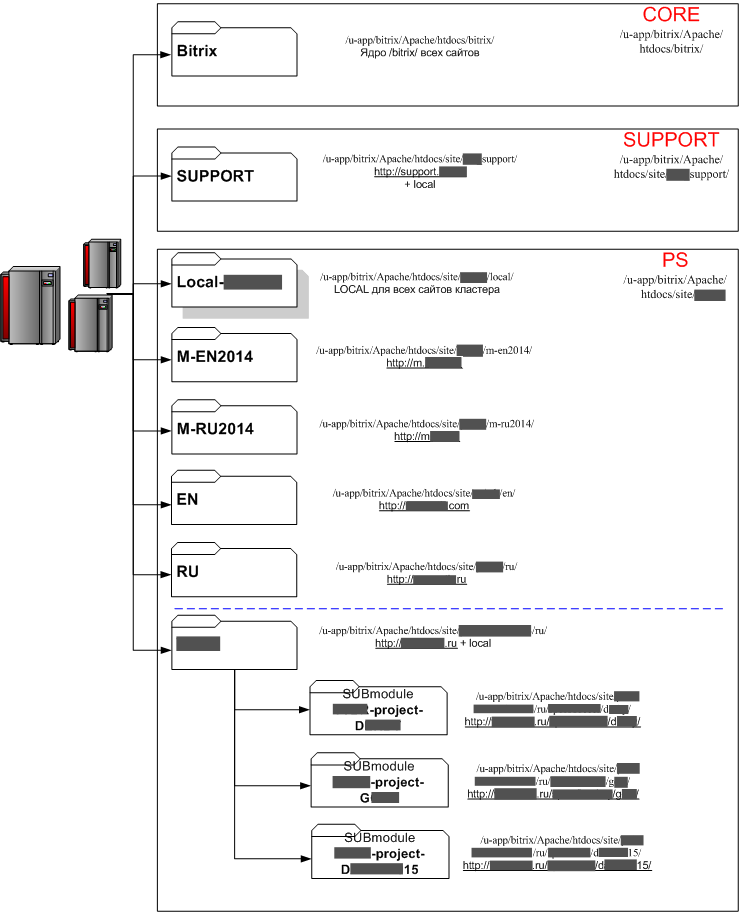
As we see in our structure:
- The kernel is in a separate directory.
- Folders of some sites are grouped in separate directories "by meaning"
- Some sites have their own personal directory / local /
- Some sites have a group directory / local /
- Some repositories have submodules (repositories within the repository) - these are usually special projects that are rarely updated after completion, but have serious differences in both logic and content (they are often subject to seriously different rules for .gitignore). Therefore, they are taken out separately, so as not to create a mess.
Not a single repository (even in its worst times) exceeded 300MB.
This is achieved by a political decision not to include certain types of content (binary files like PDF, avi, jpg, etc.) into such repositories unnecessarily and with the corresponding ban in .gitignore.
2.1.4 Documentation
All pictures (except for KdPV of course) for this article are taken from the Documentation, which is located on a special resource available to the Customer, me and the Developer.
Initially (for the period of test operation) drafts of the documentation were stored on my machine, but now all the documentation has been published for the entire team to access.
Part 3 - Instructions
So we got to the most interesting.
If everything that is written in Part 1 is purely for creating context (in order to gain condescension from experienced users), and in Part 2 it’s more to go into the question (just for those who have a big project that is rapidly approaching Horizon). Events), then part 3 - these are just those basic examples of instructions that I personally did not have enough for a start.
I hope that those who have not used GIT, but want to start (even if they have a small online store on a shared hosting) will be able to ask for GIT technical support, and use GitHub or BitBucket as the Central repository and using the scripts described below will start work. And in the process they will already be able to start studying the Pro Git documentation and adapt their working methods, make them more flexible and perfect.
All of the above was not born on the same day. But even when it finally appeared, the question remained how to use all this wealth.
All the instructions below were written in
3.1 Initializing the Repository
3.1.1 Initializing the Repository to the Prod (and Re-creating the Prod / Prelive)
The most simple and correct method.
It means that you create a repository in the Battle, and then copy the entire site (including the repository) from Battle to Test and Prelay.
On example of directory / local / (common for several sites)
Web console (on PROD) - https: //********.ru: 1119 / bitrix / admin / git_console.phpcd /u-app/bitrix/Apache/htdocs/site/******/local/(go to the directory / local / common for sites Press Services from any other place)pwd- we define the current directory (we check the location)git status- check GIT status (should show no repository)
Put .gitignore (see sample in appendix)git initgit config user.name "Zadoiny Alexey"git config user.email "aleksey.zadoiny@******.ru"git add -A .git commit -m 'initital'
Create if repo was not created in GitLab (with the name local - ******)git remote add origin git@172.***.***.61:Alexey.Zadoiny/local-******.gitgit push -u origin master
Example .gitignore for repository in / local /
/.htaccess
* .log
* .tar
* .gz
* .sql
# *. flv
# *. mp4
# *. pdf
avi
# *. png
jpg
gif
bmp
* .rar
* .zip
* .7z
* .webm
# *. mp3
wav
# *. swf
/log.txt
* ._ log
/ mail_log /
/_log.txt
* sitemap _ *. xml
.htaccess
urlrewrite.php
* .log
* .tar
* .gz
* .sql
# *. flv
# *. mp4
avi
# *. png
jpg
gif
bmp
* .rar
* .zip
* .7z
* .webm
# *. mp3
wav
# *. swf
/log.txt
* ._ log
/ mail_log /
/_log.txt
* sitemap _ *. xml
.htaccess
urlrewrite.php
After creating the repository in the folder. Git, you must put the file. Htaccess with
following content:
deny from all
3.1.2 Initialization of the Repository to the Prod (and transfer to an empty TEST / PRELIVE)
Why do you need it? For example, test and combat servers have already been created and configured, and synchronization between them is not possible in the near future.
It is important that there are only a small number of files that are not subject to synchronization, but are necessary (that is, the method is suitable for the kernel, because only the database connection files are not synchronized there, but not suitable for the public part if there is a lot of content in as binary files that are excluded from the repository, otherwise see clause 3.1.3)
On the example of the kernel / bitrix / common for all sites
On the Battle:
Example .gitignore:
on Test / Prelayv:
After creating the repository in the folder. Git, you must put the file. Htaccess with
following content:
Web console (on PROD) - https: //*******.ru: 1119 / bitrix / admin / git_console.phpcd /u-app/bitrix/Apache/htdocs/bitrix/(go to the directory / bitrix / common for all sites from any other place)pwd- we define the current directory (we check the location)git status- check GIT status (should show no repository)
Put .gitignore (see sample in appendix)git initgit config user.name "Zadoiny Alexey"git config user.email "aleksey.zadoiny@********.com"git add -A .git commit -m 'initital'
Create if repo was not created in GitLab (named bitrix)git remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.gitgit push -u origin master
Example .gitignore:
* .log
* .tar
* .gz
* .sql
* .flv
* .mp4
* .avi
* .rar
* .zip
* .7z
* .webm
* .mp3
* .wav
* .swf
cache
stack_cache
managed_cache
tmp
php_interface / dbconn.php
.settings.php
on Test / Prelayv:
Backing up the files /bitrix/.settings.php and /bitrix/php_interface/dbconn.php (any other vital files that will not be synchronized by GIT)
Delete the contents of the folder / bitrix /
Web console does not work. Go to the usual console!cd /u-app/bitrix/Apache/htdocs/bitrix/(go to the directory / bitrix / from any other place)pwd- we define the current directory (we check the location)git initgit remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.gitgit pull origin master
Restoring a backup of the files /bitrix/.settings.php and /bitrix/php_interface/dbconn.php
After creating the repository in the folder. Git, you must put the file. Htaccess with
following content:
deny from all
3.1.3 Initialization of the Repository to the Prod (and transfer to a non-empty TEST / PRELIVE)
Why do you need it? For example, test and combat servers have already been created and configured, and synchronization between them is not possible in the near future, and the directory contains a large amount of content that is not synchronized using a version control system (for example, binary content files: pdf, jpg, swf, avi and etc.)
On the example of the mobile version of one of the sites
On the Battle:
The last command (

We will need it if there are any GIT-controlled files on the Test / Prelaive (then we roll back to this commit, considering that we have the most current server status in battle and actually synchronize)
Example .gitignore:
Now let's copy the entire .git folder from the battlefield, which appeared in the bark of the mobile version directory (it is better to archive it first, because there are many small files inside) and transfer it to Test / Prelay.
There we will unpack and check the status of the repository:
After creating the repository in the folder. Git, you must put the file. Htaccess with
following content:
Web console (on PROD) - https: //*******.ru: 1119 / bitrix / admin / git_console.phpcd /u-app/bitrix/Apache/htdocs/site/******/m-ru/(go to the directory Mobile RU from any other place)pwd- we define the current directory (we check the location)git status- check GIT status (should show no repository)
Put .gitignore (see sample in appendix)git initgit config user.name "Zadoiny Alexey"git config user.email "aleksey.zadoiny@******.ru"git add -A .git commit -m 'MOBILE RU 2014 initital'
Create if repo was not created in GitLab (with the name m-ru2014)git remote add origin git@172.***.***.61:Alexey.Zadoiny/m-ru2014.gitgit push -u origin mastergit log
The last command (
git log ) is executed to find out the commit hash:We will need it if there are any GIT-controlled files on the Test / Prelaive (then we roll back to this commit, considering that we have the most current server status in battle and actually synchronize)
Example .gitignore:
bitrix
local
upload
docs
/.htaccess
* .log
* .tar
* .gz
* .sql
* .flv
* .mp4
* .avi
* .png
* .jpg
* .gif
* .bmp
* .rar
* .zip
* .7z
* .webm
* .mp3
* .wav
* .swf
/log.txt
* ._ log
/ mail_log /
/_log.txt
* sitemap _ *. xml
.htaccess
urlrewrite.php
Now let's copy the entire .git folder from the battlefield, which appeared in the bark of the mobile version directory (it is better to archive it first, because there are many small files inside) and transfer it to Test / Prelay.
There we will unpack and check the status of the repository:
Web console (on TEST / PRELIVE) - https: //*******.ru: 1119 / bitrix / admin / git_console.phpcd /u-app/bitrix/Apache/htdocs/site/******/m-ru/(go to the directory Mobile RU from any other place)pwd- we define the current directory (we check the location)git status- check GIT status (must show no changes)
If there are any changes:git reset --hard #HASH#where # HASH # is the first 4-5 characters from the commit hash that we received in battle (more is possible, but usually quite a small number)
After creating the repository in the folder. Git, you must put the file. Htaccess with
following content:
deny from all
3.1.4 Initialization of the Submodule Repository on the Prod (and porting to a Non-Empty TEST / PRELIVE)
The difficulty with the submodule lies in the fact that you need to edit the already existing ecosystem (Ie, the repository already exists, and suddenly you want to tell him “ uh, not, dear, here there will be a fence, and Vasya will live behind the fence! “)
In particular, if you first deploy some functionality, commit it, then in order to create a submodule at this point, you will have to delete all created files / directories ( TOSTER question on this topic ).
Creating a submodule d **** within the existing repository
Create in the Central Repository (GitLab) a new empty repository (with the name **** - project-d ****)
We check on Boy and if there is - delete the folder / u-app / bitrix / Apache / htdocs / site / ********** / en / ***** / ****** / d * *** /
Go to the web console - https: //********.ru: 1119 / bitrix / admin / git_console.php
If we now do git status, we will see:
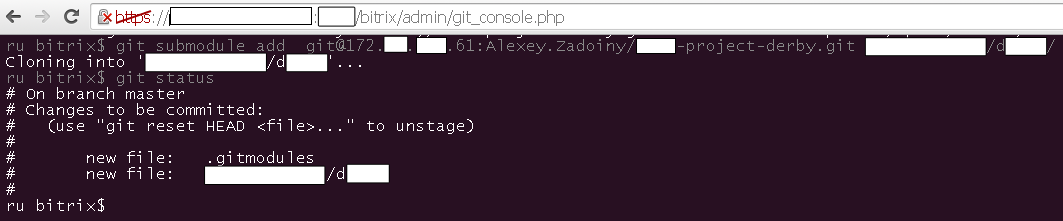
We check on Boy and if there is - delete the folder / u-app / bitrix / Apache / htdocs / site / ********** / en / ***** / ****** / d * *** /
Go to the web console - https: //********.ru: 1119 / bitrix / admin / git_console.php
cd /u-app/bitrix/Apache/htdocs/site/*********/ru/(go to the Repository directory from any other location)pwd- we define the current directory (we check the location)git status- check the status of GIT (should show the presence of the root repository)git submodule add git@172.***.251.61:Alexey.Zadoiny/****-project-d****.git *****/****/d****/
If we now do git status, we will see:
git add -A .git commit -m 'INIT SUBmodule D****
- Now we can work with the submodule as an independent repository (commit its state, change it via GitLab with the Prod / Test / Prelive server, etc.)
- When updating the state of the main repository on Test / Prelive, a new submodule will be automatically installed there!
3.2 Nakat task update
Let me remind you that initially this process was supposed to follow the scheme:
DEV → TEST → PRELIVE → PROD
Therefore, the update scheme contained 11 main and 4 additional steps and had several branches:
Spawn of hell
The horizontal version of this nightmare still hangs in my workplace ( I should probably remove it, but it is really funny to look at the thoughtful shaking of the head of people who first worked with me, for example, representatives of the new Contractor who came to roll a special project )

The horizontal version of this nightmare still hangs in my workplace ( I should probably remove it, but it is really funny to look at the thoughtful shaking of the head of people who first worked with me, for example, representatives of the new Contractor who came to roll a special project )
Now the scheme is simplified to
DEV → TEST / PRELIVE → PROD
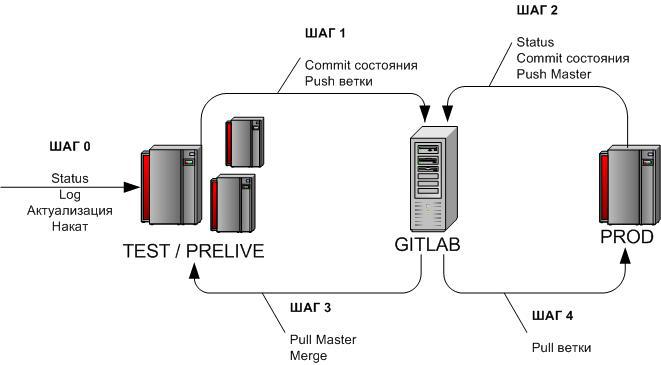
Note. In fact, in all instructions I have not 1 address (cd ), but a sign with a list of all addresses. Those. When executing the action, you can select 1 any and copy it entirely (and not recall, let to the directory of this or that repo)
an example of how it looks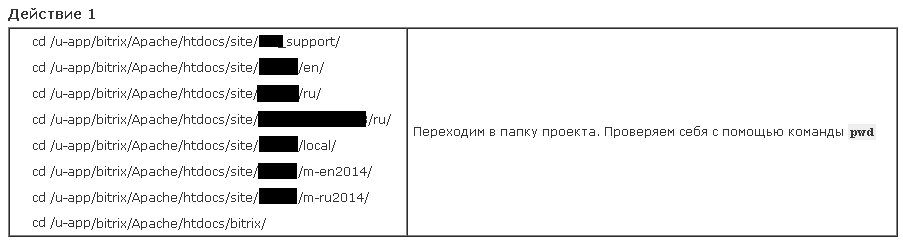
For the sake of this article, for brevity, I will use 1 address everywhere (since I suppose that most novice GIT users will not have to immediately work with many repositories at once.
Each step is considered as independent and autonomous , therefore it begins with the transition to the repository directory. If the process is not interrupted, then this item instructions can simply be ignored.
3.2.0 Run Upgrade Task - Step 0
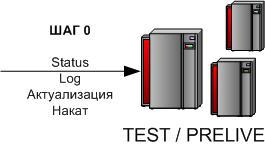
cd /u-app/bitrix/Apache/htdocs/bitrix/ - go to the project folder. We check ourselves with the pwdgit status - there should not be any uncommitted changes.git log - the last commit should correspond to the last commit of the Master branch of the central GitLab repositoryIf
git log did not show the last commit, go to steps 3.4 and after rolling up the current state from the battlefield to the test / prelaw we start the procedure from the beginning.Nakat - we transfer to the test / preraiv functional of the task by any means (FTP, admin).
3.2.1 Nakat task update - Step 1
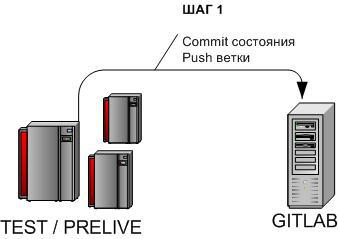
cd /u-app/bitrix/Apache/htdocs/bitrix/git add -A .git commit -m 'TIKET ######'git push origin master:TIKET_######We commit the changes, send them from the development branch (master on the test / pre-server) to the branch in the central repository.
Alternative option
In case git status shows changes not only in the task files to be entered into the GIT, it is recommended to use:
or
For all directories and files that need to be added to the version control system. Point instead of the path indexes All changed (as well as created and deleted) files.
git add -A /puth/or
git add -A /puth/file.phpFor all directories and files that need to be added to the version control system. Point instead of the path indexes All changed (as well as created and deleted) files.
3.2.2 Nakat task update - Step 2
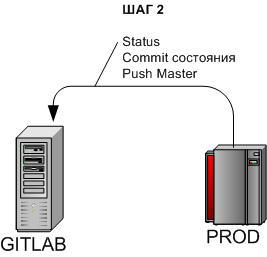
cd /u-app/bitrix/Apache/htdocs/bitrix/git statusgit add -A .git commit -m 'Prod changes ##'git push origin masterCheck the status of the battle.
If the state of the battle has changed (and the test / head is in a more irrelevant state), then commit the change and send it to the central repository for synchronization.
If there are no changes → go to Step 4.
3.2.3 Nakat task update - Step 3
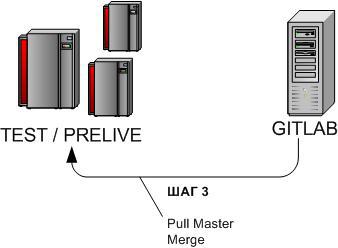
cd /u-app/bitrix/Apache/htdocs/bitrix/git pull origin masterIf, during the roll forward of the task to Test / Prelay, the Fight has changed (see Step 2), you should roll changes from the battlefield (through the central repository) to Test / Prelay and change the changes.
If GIT fails to merge branches independently (conflicts arise, for example, due to changes in the same files), you should manually resolve the conflicts.
At the end of step → return to Step 1.
3.2.4 Nakat task update - Step 4
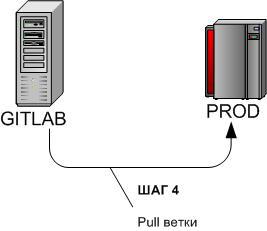
cd /u-app/bitrix/Apache/htdocs/bitrix/git pull origin TIKET_######We roll the update task to Fight from the central repository
3.3 Committing daily changes (at the end of the day)
Unfortunately, despite the process described above, we are constantly having changes right in the fight due to 2 main reasons:
- There are many content editors who have access to change files in the public part of the combat server (of course, with limited rights, without access to editing php code, but with the ability to change the html markup)
- There are tasks for the Daughters, which often affect the kernel / bitrix / (as a rule, templates and components appear or change)
Therefore, every day at the end of the working day (and as you remember from the beginning of the article after 17.50 Moscow, the Developer and I lose the opportunity to edit php on Boy), I summarize and commit all the edits made outside of my tasks.
Why not in the morning?
If for some reason I am forced to leave work early, then usually I just do it the next day before the work process begins (while the Developers are sleeping in their warm beds).
However, this adds complexity, since Prelive and Prod are synchronized at night! Those. The unfixed changes in the morning will be not only in battle, but also on prewater!
This means that you either have to abandon the deployment of tasks for pre-development during the day, or synchronize files using GIT:
However, this adds complexity, since Prelive and Prod are synchronized at night! Those. The unfixed changes in the morning will be not only in battle, but also on prewater!
This means that you either have to abandon the deployment of tasks for pre-development during the day, or synchronize files using GIT:
- Roll back the state of Prelaive to the last commit (see 3.4.1)
- Roll up the current status on Prelaive from GitLab (git pull, see 3.1.3)
The process is completely identical to the fixation of changes in combat (see 3.1.2):
cd /u-app/bitrix/Apache/htdocs/bitrix/git statusgit add -A .git commit -m 'Prod changes ##'git push origin master3.4 Roll back changes
- There are 3 types of situations when it is necessary to roll back changes (as the situation worsens):
- Rollback on Test / Prelive (it doesn’t matter if a mistake was made or the task was successfully checked - you need to “free up the site”, no edits on the Test / Prelaive are foreseen)
- Rollback to the Battle of a minor error that came through GIT (the keyword is insignificant. Version history is valuable for example for analysis in GitLab, but you need to return to the battle a stable version. It is practiced only for FRESH edits)
- Rollback of critical error to the Battle (situation from the series “ Chief, everything is lost !!!! 1111one ”, when the performance of the project is more critical than a beautiful story in GitLab)
3.4.1 Test - Rollback to the last stable state
There is no work done on test servers with tasks to “bring to mind”. For this, developers have a Dev environment, we only come here to test before handing over to the Customer, which is why sterile conditions are more critical than history (this is why the hard flag, and exactly reset, not checkout or something else).
git reset --hard HEADIf you need to rollback not to 1 commit, then take the hash of a specific commit from GitLab and roll back to it:
git reset --hard #HASH#
3.4.2 Fight - The inflated task introduces an error (came through GIT)
If the edit did not put the server and 100% came with the last commit, and was not made 2 months ago and was already assimilated, creating a dependency with some other task, then you can make a counter commit canceling the edit.
The advantage is that you save the history of this edit in GitLab and the Developer (if you have access) can once again examine the commit and brainstorm. And if the commit has already hit the master branch of GitLab there are no problems.
If the edit was made right away in a battle (who's going to tear off their hands?), Then for this strategy you will have to first make a commit, which is clearly not rational.
git revert HEAD
Creates a counter commit that cancels changes from the last one.
3.4.3 Fight - Edit broke the fight (completely)
If everything is very bad (the server is down, or it suddenly turned out that “very important functionality” was broken a long time ago, then there is nowhere to go:
git reset --hard HEADIf you need to rollback not to 1 commit, then take the hash of a specific commit from GitLab and roll back to it:
git reset --hard #HASH#If as a result of such a rollback it turns out that the destroyed commit has already got into the master branch on GitLab, then to restore order it is often easier to delete the entire repo on GitLab and re-create it. =)
Conclusion
The scripts I have described are very simple. This is their advantage and disadvantage at the same time.
- Advantage - they allow even a novice GIT user to work with the version control system (tested on my boss for 2 weeks of my vacation)
- The disadvantage is that an experienced user sees some more flexible and interesting scenarios that are difficult to formalize as a set of simple rules of application. That is why I recommend reading their Pro Git book after successfully mastering and implementing them.
However, even such a limited toolkit allows you to observe such wonderful pictures in GitLab:
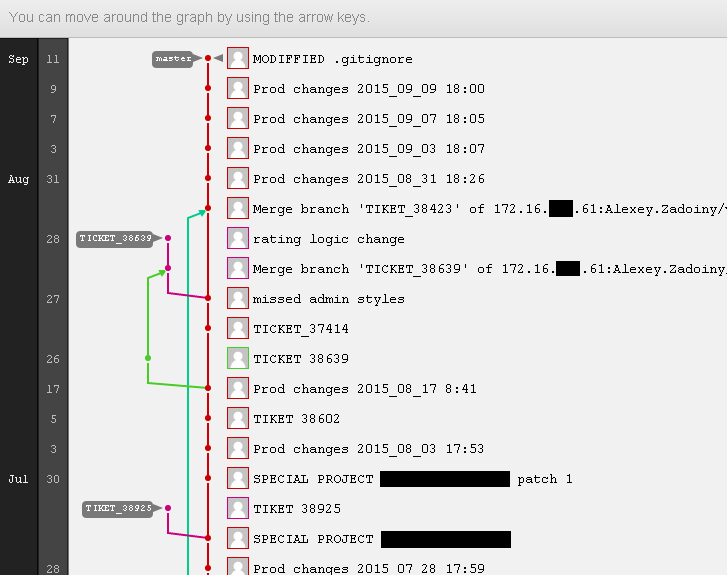
Several commits are not named according to my rules - this is the result of the developer quickly setting up the functionality on the Test / Prelive server when the task is rolled up. In such cases, I wrote TIKET _ ###### Patch _ ## (Ticket number and patch sequence number) in order to more easily identify to which task in the tracker this or that edit belongs.
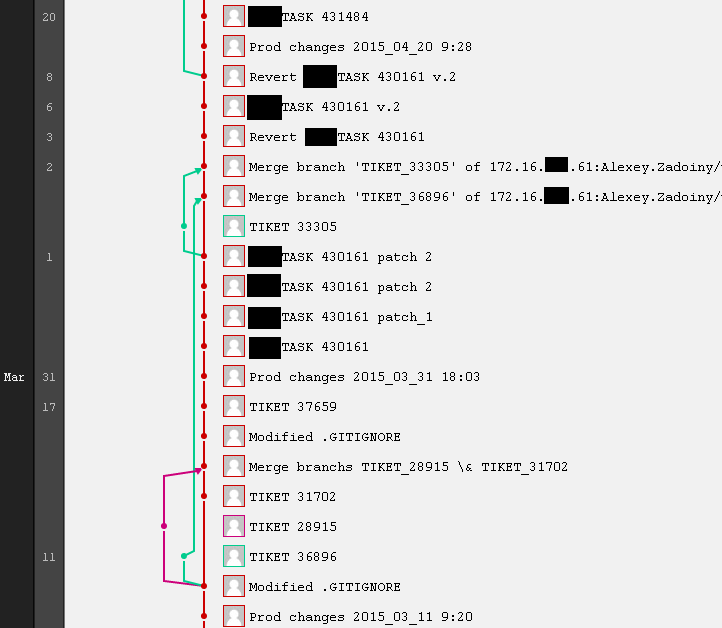
Some tasks are implemented directly by me, not by the Developer. In this case, I call from Task and not Tiket and indicate the ID of the related task in another account system.
In fact, such branching and intersection is not at all good. It looks cool, but in reality, each task postponed for a week or a month for testing creates hemorrhoids to the one who then all this will be merdzhit.
It’s not that something broke (although there were conflicts a couple of times that the GIT couldn’t be corrected and I had to resolve them). But makes you nervous.
FAQ
Q: Not too many branches work?
A: As a rule, each server has only 1 branch - master. Many branches exist only in the Central Repository (GitLab). It is rarely necessary to download a separate branch from there (this scenario is not described, since it is not a model one due to its rarity). Naturally unnecessary branches (whose commits have joined the master) have to be periodically cleaned. I understand that it is very similar to SVN, but it works for us and helps a lot.
Q: Not described merge. How to do it?
A: As a rule, merge is automatically executed by GIT. In rare cases, conflict resolution is required. In this case, you receive a notification that the automatic merge has failed.
If at this moment to make git status, the list of files with conflicts will be received. On them it is necessary to go through and resolve all conflicts (a special marker has allocated pieces of code from different commits).
However, it is easier for us to avoid merge conflicts by organizational methods than to resolve them. In any case, often this can only be done by an experienced programmer.
Well, the chapter on merge in Pro Git is very useful, if that.
Q: Is it possible to remove the asterisks from the code samples and the filled places in the pictures?
A: I apologize to the reader for this monstrous product of conspiracy.
This is a minimal distortion of our actual instructions to which, for security reasons, the representative of the Customer agreed, coordinating the draft article.
A: As a rule, each server has only 1 branch - master. Many branches exist only in the Central Repository (GitLab). It is rarely necessary to download a separate branch from there (this scenario is not described, since it is not a model one due to its rarity). Naturally unnecessary branches (whose commits have joined the master) have to be periodically cleaned. I understand that it is very similar to SVN, but it works for us and helps a lot.
Q: Not described merge. How to do it?
A: As a rule, merge is automatically executed by GIT. In rare cases, conflict resolution is required. In this case, you receive a notification that the automatic merge has failed.
If at this moment to make git status, the list of files with conflicts will be received. On them it is necessary to go through and resolve all conflicts (a special marker has allocated pieces of code from different commits).
However, it is easier for us to avoid merge conflicts by organizational methods than to resolve them. In any case, often this can only be done by an experienced programmer.
Well, the chapter on merge in Pro Git is very useful, if that.
Q: Is it possible to remove the asterisks from the code samples and the filled places in the pictures?
A: I apologize to the reader for this monstrous product of conspiracy.
This is a minimal distortion of our actual instructions to which, for security reasons, the representative of the Customer agreed, coordinating the draft article.
Source: https://habr.com/ru/post/266573/
All Articles