Developing a metamodel using the Eclipse Modeling Framework (and a little about data modeling)

This is the second article in a model-driven development cycle. Today we will create a metamodel based on the metametamodel Ecore. We briefly touch on data modeling, namely Anchor, 6NF and conceptual modeling.
Introduction
You can browse the previous article about OCL and metamodeling , but this is not necessary. Just these abstracts are enough:
- There are various objects of the real world (people, organizations, events, buildings, bank accounts, stars, planets, trees, music, etc.).
- In some information system we can process various information about these objects.
- The information corresponds to a certain model. A model can be more or less formalized, explicit or implicit, it can describe various aspects of objects in the real world, it is itself an object of the real world. For example, some UML class diagram is a model.
- The model is built in accordance with a metamodel, a modeling language (for example, UML).
- Metamodels are built in accordance with metametamodels (for example, Ecore, MOF).
More extensively, these abstracts were described by the OMG (Object Management Group) consortium in Model-driven architecture .
')
After reading this article, you will learn how to create your own metamodel (modeling languages).
Choosing a metamodel for implementation
First you need to decide which metamodel we will implement.
Artificial metamodels created solely for example are too useless.
Entity-relationship models, Petri nets, etc. too simple and uninteresting.
Some PMML is interesting, but too complex.
It would be possible to implement Charity using EMF. It would probably be very interesting (imagine a programming language in which everything is described using commutative diagrams ), but it is useless.
In my opinion, the golden mean is Anchor . Using the example of this language, we will catch a lot of birds with one stone:
- Learn to create metamodels.
- Let's get acquainted with one of the alternatives to the entity-relationship diagrams.
- Maybe break some stereotypes about data normalization.
- Let's touch on the conceptual modeling.
A retreat about why we need some other data modeling languages
When I got the last job, at the interview I told what a wonderful repository and the cubes I had done at the previous work, said that it almost completely saved people from manual calculations. And I was asked: what will happen to this storage and cubes, if the data scheme changes? After all, if we change the storage structure and cubes at the same time, we will not be able to receive reports for past periods based on the old data scheme. I answered something like the fact that we very carefully thought through the data scheme and there will be no significant changes in it, the maximum will be something added to it, well, and if there are more serious changes, then there's nothing to be done about it.
After some time, I realized that this task of painlessly changing the data scheme is completely trivial. Simply select the correct data modeling technique. If you build a storage based on 3NF-5NF, then, indeed, the slightest changes in the data scheme all break. If we normalize the data to 6NF, then no changes will affect the data already stored in the database.
Data Vault and Anchor are based on the ideas of data normalization to 6NF in varying degrees. I hope this digression is enough to interest you in Anchor.
Note
In fact, and this is not the top of data modeling, there are some things that are not taken into account in these approaches. But they are taken into account, for example, in our modeling methodology, but you will find out about this if you work with us ;-)
A retreat about the history of data modeling
Before finally turning to Anchor for a bit of history (please treat it critically and with irony).
In the 1970s, there was a lot of research in data modeling. One of the not bad approaches that was invented in those years is object-role modeling . It was the alpha and omega data modeling, practically the pinnacle, after which the history of degradation in this area began. I will not describe this approach in detail. In a nutshell, the data there is described as facts, but not as “subject-predicate-object” as in RDF, but as tuples with an arbitrary number of objects.
Unfortunately, not all those years realized the genius of OR-modeling, so in 1976 Peter Chen published an article in which he described the entity-relationship model. ER-models differ from OR-models in that there are no facts in them, but there are attributes. This is a very significant difference.
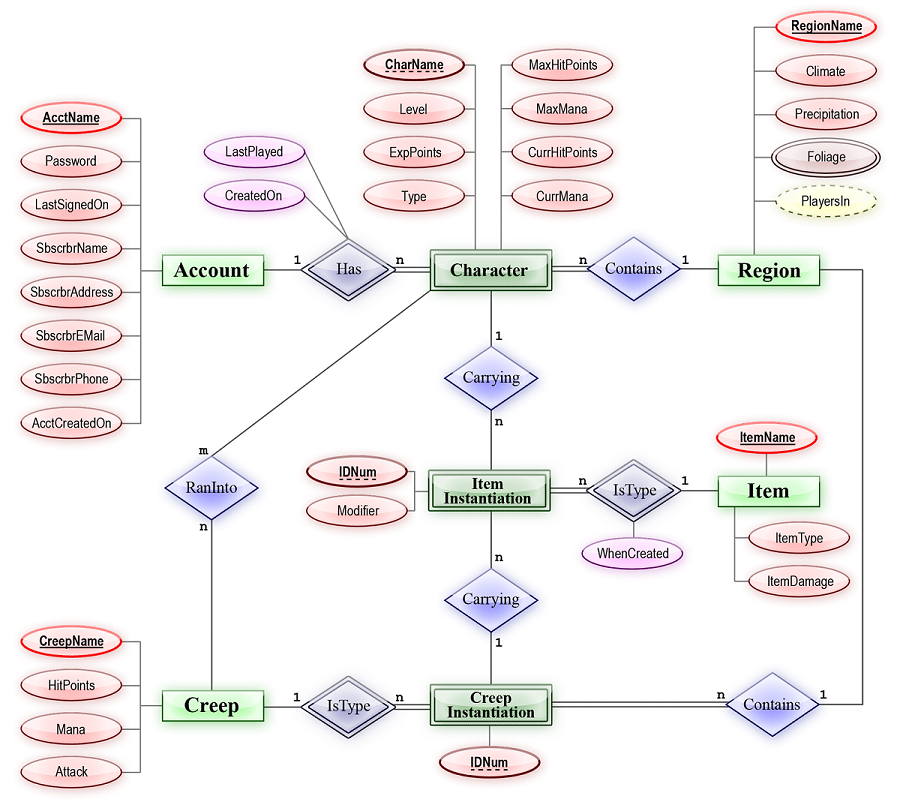
" ER Diagram MMORPG " by TheMattrix at English Wikipedia . Licensed under CC BY-SA 3.0 via Commons .
In the OR-model, the set of facts relating to an object can be quite arbitrary. For example, we can formulate the facts "Employee number 1 - has a name - Ivan" or "Employee number 1 - was born in - 1990". Or even more complex: “Employee No. 1 - received a degree - Doctor of Science - in - 2010”. But this does not mean at all that we should always indicate for the employee the name and year of birth, and in this order, just as it does not mean that we cannot formulate any other facts about the employee.
In the ER-model, when moving from facts to attributes, such flexibility / openness of the model disappears, we begin to model fixed structures describing a fixed set of facts, wired into attributes ordered in a certain way.
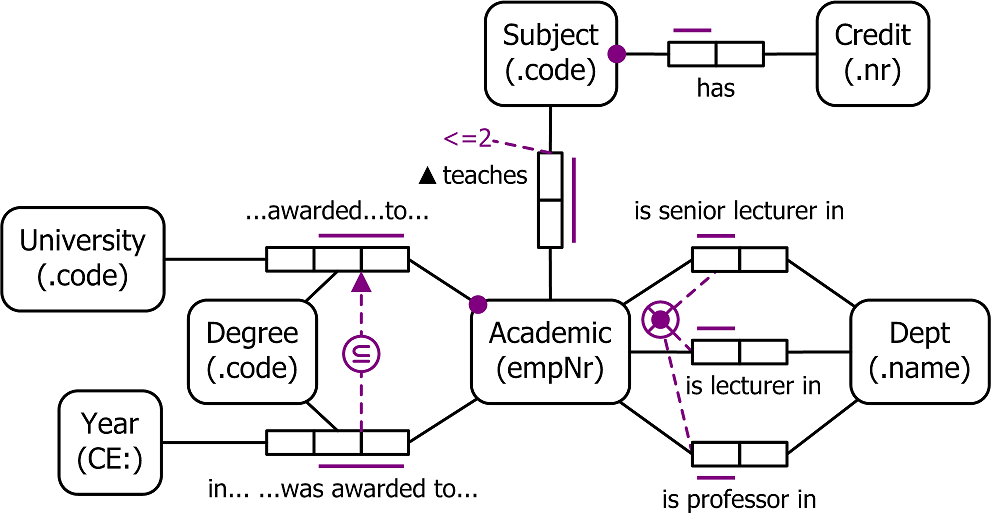
Notice that in the ER-models in Peter Chen's notation, communications are depicted as diamonds and attributes as ovals. Moreover, connections can be not only binary.
In 1981, as part of a program for the
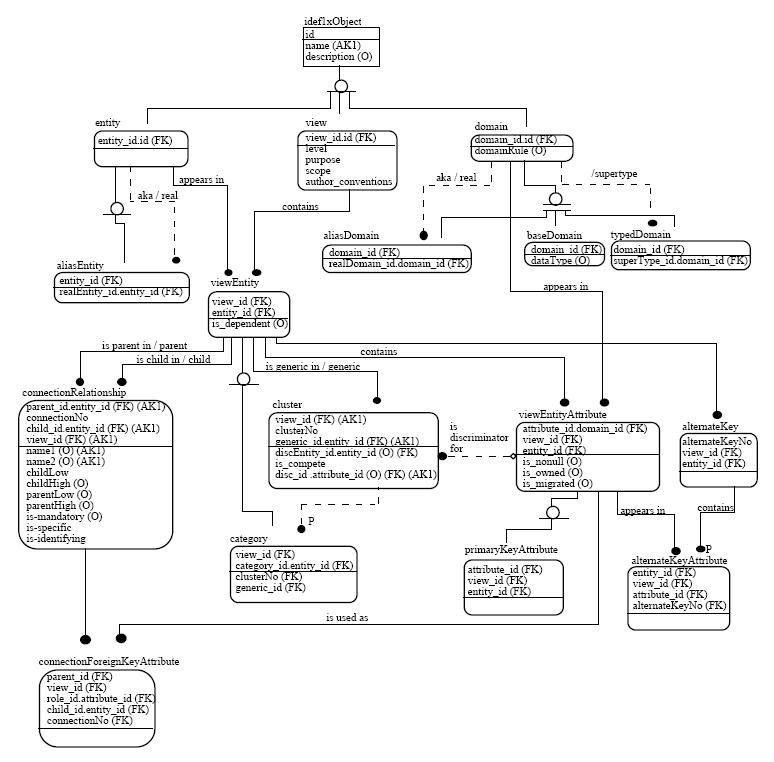
" B 5 1 IDEF1X Diagram " by itl.nist.gov - Integration Definition for Information Modeling (IDEFIX) - 93 Dec 21 . Licensed under Public Domain via Commons .
Later, many more languages and methods appeared that allow to model data, including UML, RDF, XSD, Anchor, all kinds of NoSQL. But there is nothing revolutionary in all this. This, by the way, is a good example of the fact that in IT you don’t need to chase some fashionable whistles, most of the things have been invented for a long time and simply turn into a new wrapper for marketers.
Anchor retreat
So, we have reached Anchor . Although this language is different from the usual IDEF1X or UML class diagrams, in fact it’s just tracing from the older ER model of Peter Chen, which many may have already forgotten. We list the main differences.
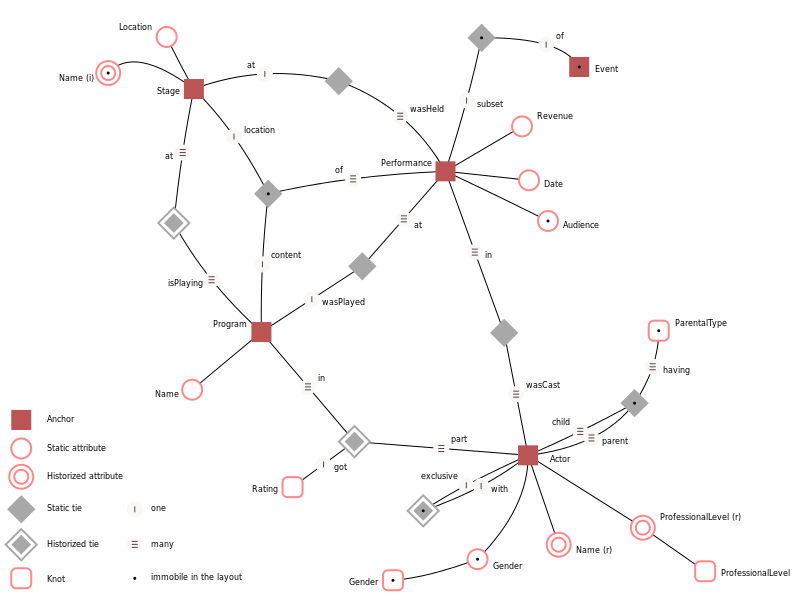
" Anchor Modeling Example " by Lars Rönnbäck - http://www.anchormodeling.com . Licensed under MIT via Commons .
In Anchor, entities are renamed to anchors (anchor), relationships (relationships) are renamed to clamps (tie — they can probably also be called links, but the word “claps” adds this charm model), attributes (attribute) are left unchanged.
In the ER model, attributes have representations (representation). In Anchor they are called more familiar - the data type (data type).
In the ER model, representations can further limit the range of allowable values (allowable values). In Anchor, you can also limit the range of values, but not arbitrarily, but by listing valid values. Such enumerated types in Anchor are called nodes (knot). Looking ahead, then we will develop a little Anchor in this regard.
It is unlikely that these differences between the ER-model and Anchor can be considered significant. For now, Anchor is reminiscent of a 40-year-old rebranded idea.
Perhaps the more significant difference is the attributes and links with historical preservation (historized attribute and historized tie). Although they are absent in the ER model, in general there is also nothing fundamentally new in them.
The question may arise: if the Anchor is so much secondary, then why is it needed at all, what are its advantages over other approaches?
The answer is very simple. Anchor allows a slightly different look at data normalization. Previously, normal forms were considered mainly in terms of anomalies in the data. At the same time, 6NF looked like some kind of spherical horse in a vacuum, which may be of interest from a theoretical point of view, but practically useless. With the advent of approaches such as Anchor or Data Vault, it became clear that data normalization is important not only in terms of eliminating anomalies, but also in terms of the evolution of the data scheme. It is easier to make changes to such schemes without breaking anything.
Project creation
The site has a wonderful editor Anchor-models. We will try to make a similar editor based on the Eclipse Modeling Framework.
Note
More precisely, in this article we will make a simplified (tree) editor. In the next article we will make a full-fledged diagram editor. And from the following articles it will become clear why we are doing all this. Of course, to learn how to create modeling languages, but not only.
So, if you want to try everything in practice, download and unpack the Eclipse Modeling Tools .
Create a new “Ecore Modeling Project”. Call it "anchor". On the Select viewpoints tab, select Design.
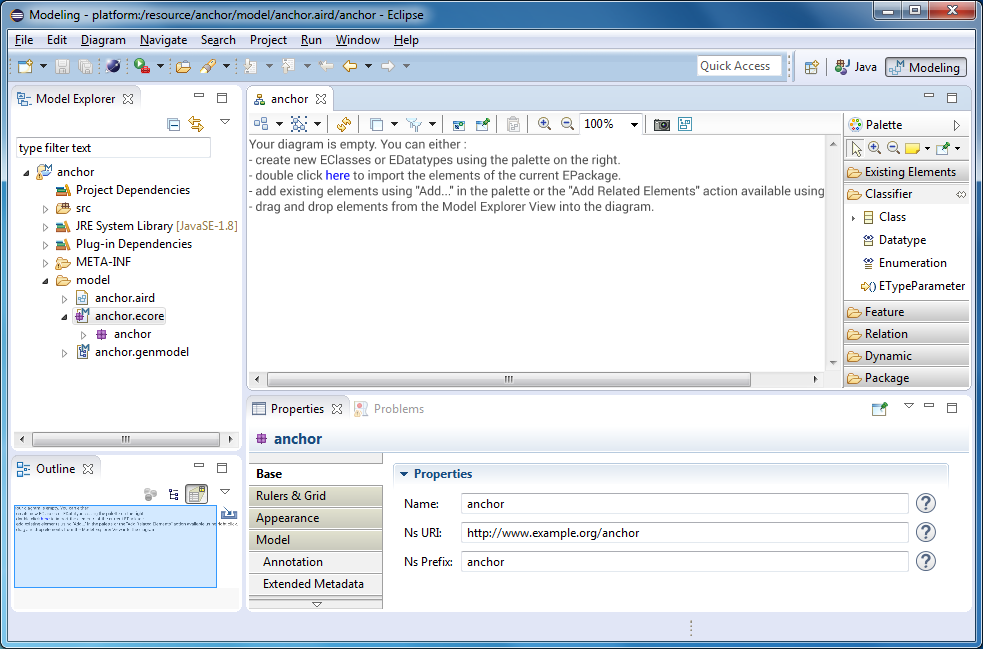
The ecore file will store our metamodel. The chart for the metamodel will be stored in the aird-file. If you read the previous article , you should understand that the model and the model diagram are two different things. Finally, the genmodel file contains the model for generating source code from our metamodel. It sets various rules for generating code, in particular, in which folder it should be added, etc.
Note
Hereinafter I will sometimes call the meta model a model. There is no contradiction in this; the meta model itself is a model. As well as metaclasses are classes from the point of view of the metametamodel.
If you are too lazy to create a project, you can take it ready .
Creating basic metaclasses
Now it is necessary to describe metaclasses (types of entities that may be in our Anchor-models). Add a class to the diagram and name it Anchor. Add to it the name attribute with the EString data type. In the Lower Bound field, enter 1.
Add another class, name it Attribute. Copy the name attribute to it.
In Anchor models, anchors and attributes can be linked together. Therefore, in our metamodel, we need to create a link between the anchor and the attribute. A link must be a composition, because attributes cannot exist on their own, they always belong to an anchor and moreover to one.
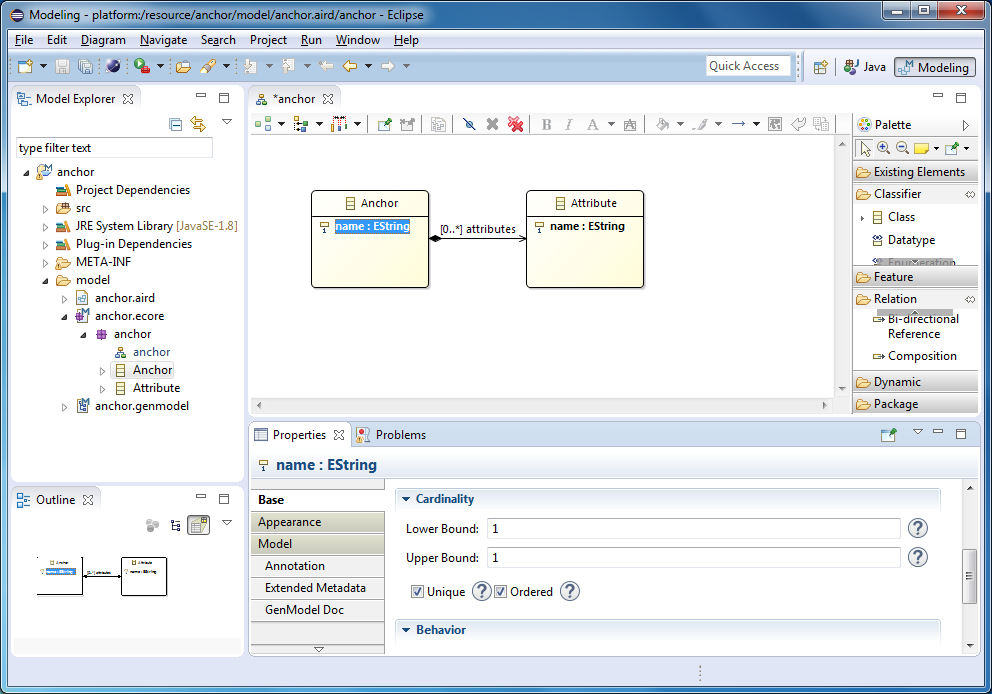
Note
There are different approaches to the naming of relationships. This relationship between anchor and attribute can be called: attribute, attributes, ownedAttribute or ownedAttributes. The one-to-one relationship must be uniquely called in the singular. The one-to-many relationship is sometimes called in the singular, sometimes in the plural. If the relation is a composition, then sometimes the prefix added is added to the name. This means that the attribute belongs to the anchor.
It is important that the model uses one naming scheme. I will use the second one.
Generating the model editor
So, we already have a simplified sketch of the meta model. Now we will create a model in accordance with this metamodel. To do this, you need to generate the source code for the plugin, which we will run in Eclipse and which will allow us to work with the model.
Open anchor.genmodel. In the properties of many different settings. You can leave them unchanged, but usually the folder for the generated code is changed from src to src-gen, in order to separate the code written by hand from the generated one. By the way, there will be no hand-written code in our project at all.
In the context menu, select “Generate Model Code”, after which the Java API will appear in the src folder (or src-gen) for working with our Anchor models. In this and subsequent articles, we will not need to look into this code or edit it.
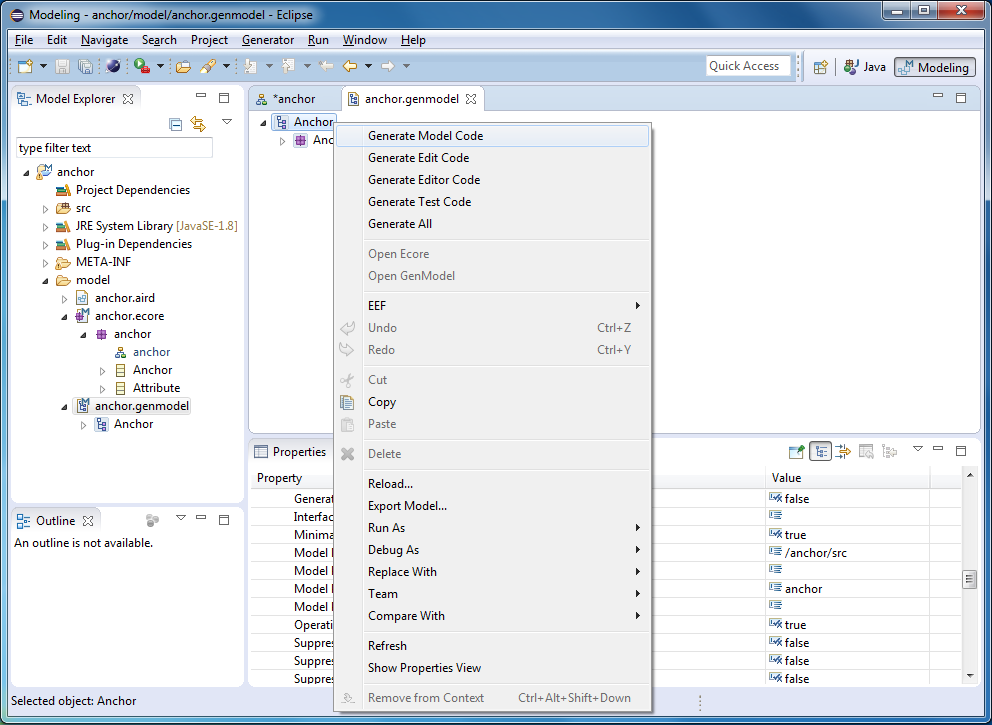
Run "Generate Edit Code" and "Generate Editor Code". Thus, you will create two additional projects: 1) some layer between the object model of our modeling language and the editor, and 2) the tree-like model editor.
Before the heap, create a test project using the Generate Test Code command. We will not write unit tests, however in this project you can see examples of using the API generated for our metamodel. Also in this project we will create test models.
Switch to the Java perspective (Window -> Perspective -> Open Perspective).
Select Run -> Run Configurations ... In the Eclipse Application section, create a new configuration and launch it.
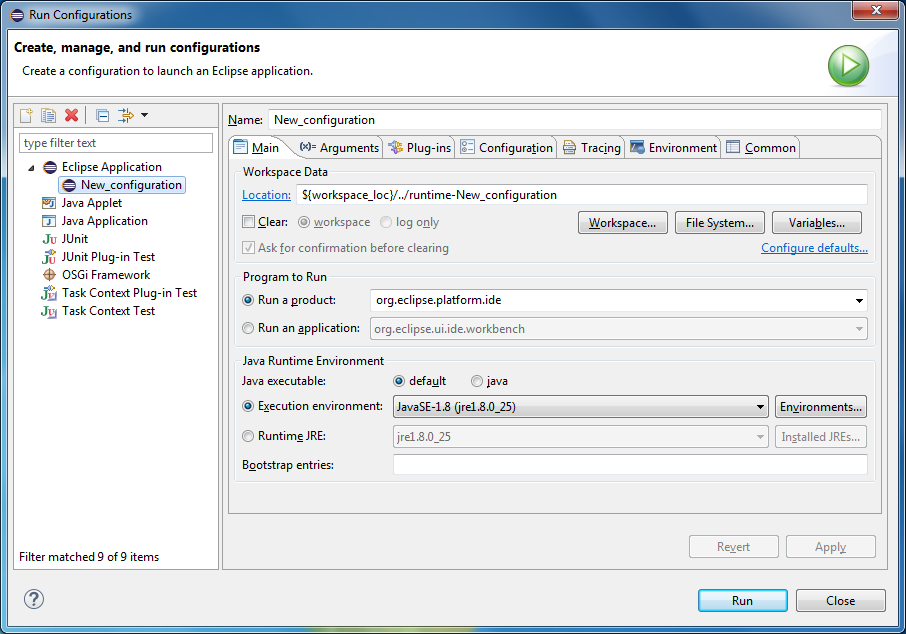
Import the anchor.tests project into the running instance of Eclipse (File -> Import ... -> General -> Existing Projects into Workspace). Open the modeling perspective (Window -> Perspective -> Open Perspective -> Modeling). Create a new model folder in the project (File -> New -> Folder). Create an Anchor-model in the folder (File -> New -> Other ...).

On the last tab, the model creation wizard will ask which object to use as the root (the Model Object field). We have not created the root object yet, so select Anchor.
On the property tab, specify some anchor name, add attributes.

Creating a root model object
So far our editor allows to describe only one anchor with attributes. So that the model could have several anchors, do the following.
Close the second instance of Eclipse; in the first instance, open the Modeling perspective. Open the file anchor.ecore. Add a metaclass to Model metamodel.

Add an EReference metaclass named anchors. In the EType field, select Anchor. Lower Bound, set to 1, Upper Bound, set to -1 (an arbitrary number). In the Containment field, specify the true value (this means that the anchors will belong to the model).
Now create a back link from the anchor to the model. This is not necessary, but will be needed in the next article. To do this, in the Anchor metaclass, create a link with the name model and the type Model. In the EOpposite field, select the back link anchors. In the Lower Bound field, enter 1.
Note
You probably noticed that the tree editor of the metamodel is very similar to the editor you just generated. Is that looks a little prettier thanks to the icons. The default icons are in the anchor.edit project in the icons folder. Other icons can be taken from here . They are a bit curved because they are generated from svg , but you get the idea.
Save the metamodel. Open the chart in the anchor.aird file. Add a metaclass Model to the diagram (in the tool palette on the right, in the Existing Elements section, select Add). Notice that the diagram also added a bidirectional link to the Anchor metaclass that you created in the tree editor.
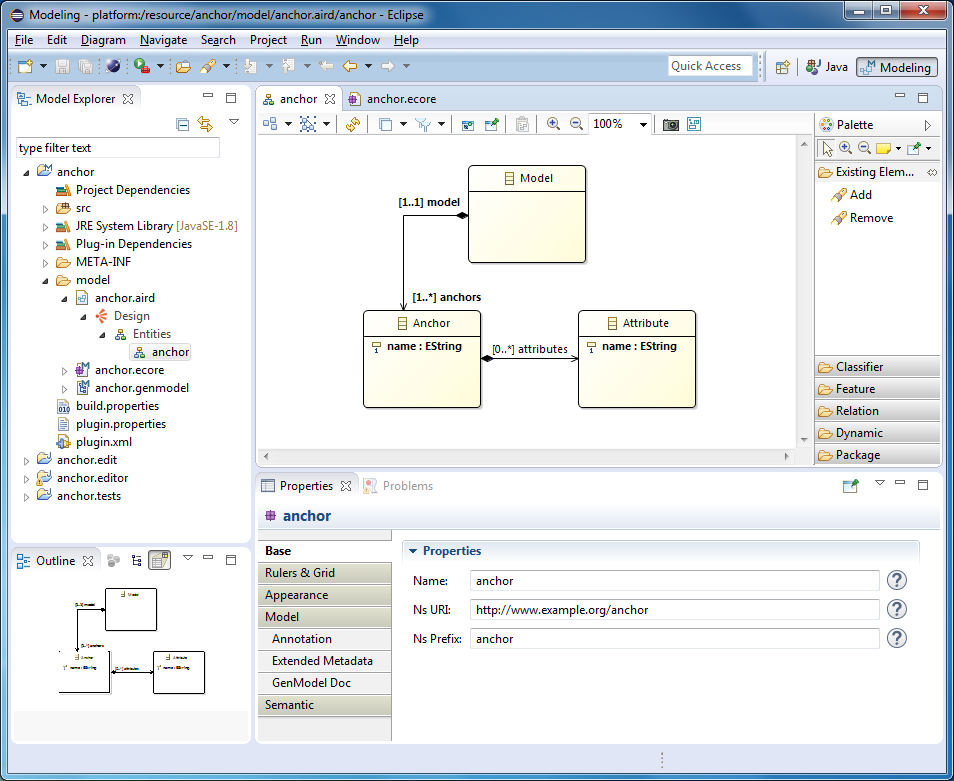
Plugin generation
After changing the metamodel, do not forget to regenerate the source code in all projects. Now, instead of starting the second instance of Eclipse, do the following. In the menu, select File -> Export ... -> Deployable plugin-ins and fragments.
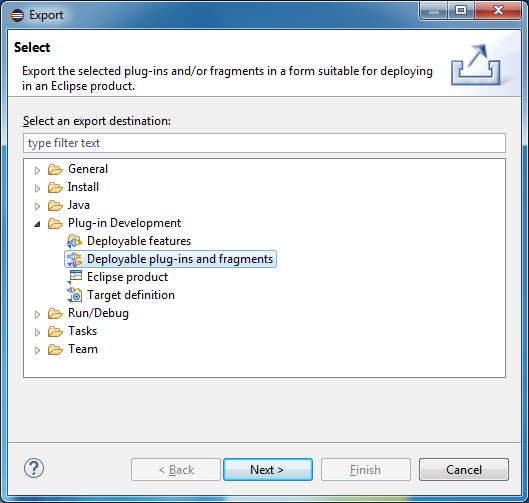
Mark all created projects (at least, all but anchor.tests). Select Install into host. Repository. After deploying the plugin, restart Eclipse. Now the editor of the Anchor-model will be available in this workspace without starting the second instance of Eclipse.
You can also export the plugin to a folder. Then the resulting jar files can be copied to the $ ECLIPSE_HOME / dropins folder. After restarting Eclipse, your plugin will be available in it.
Completing the creation of a metamodel
In general, this is all you need to know about EMF to create your metamodel. Now it only remains to add the missing metaclasses.
You can find out what other metaclasses you need either by simply looking at examples of Anchor models, or from M. Bergholtz, P. Johannesson, P. Wohed article "Anchor Modeling - Agile Information Modeling in Evolving Data Environments" .
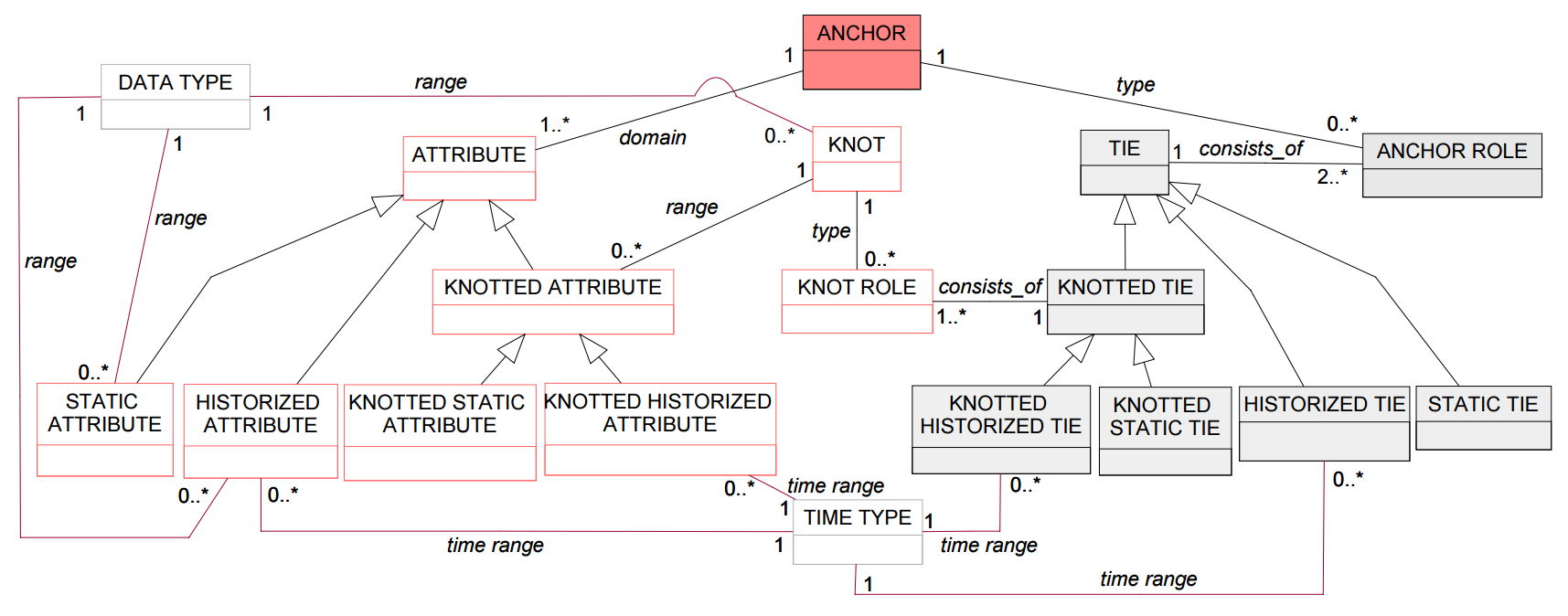
If you try to implement this metamodel, you will see that some things in it can be done more optimally than shown in the figure. We will improve two things:
- Duplicate properties and relationships will be rendered into separate classes.
- Let's a little improve the type system.
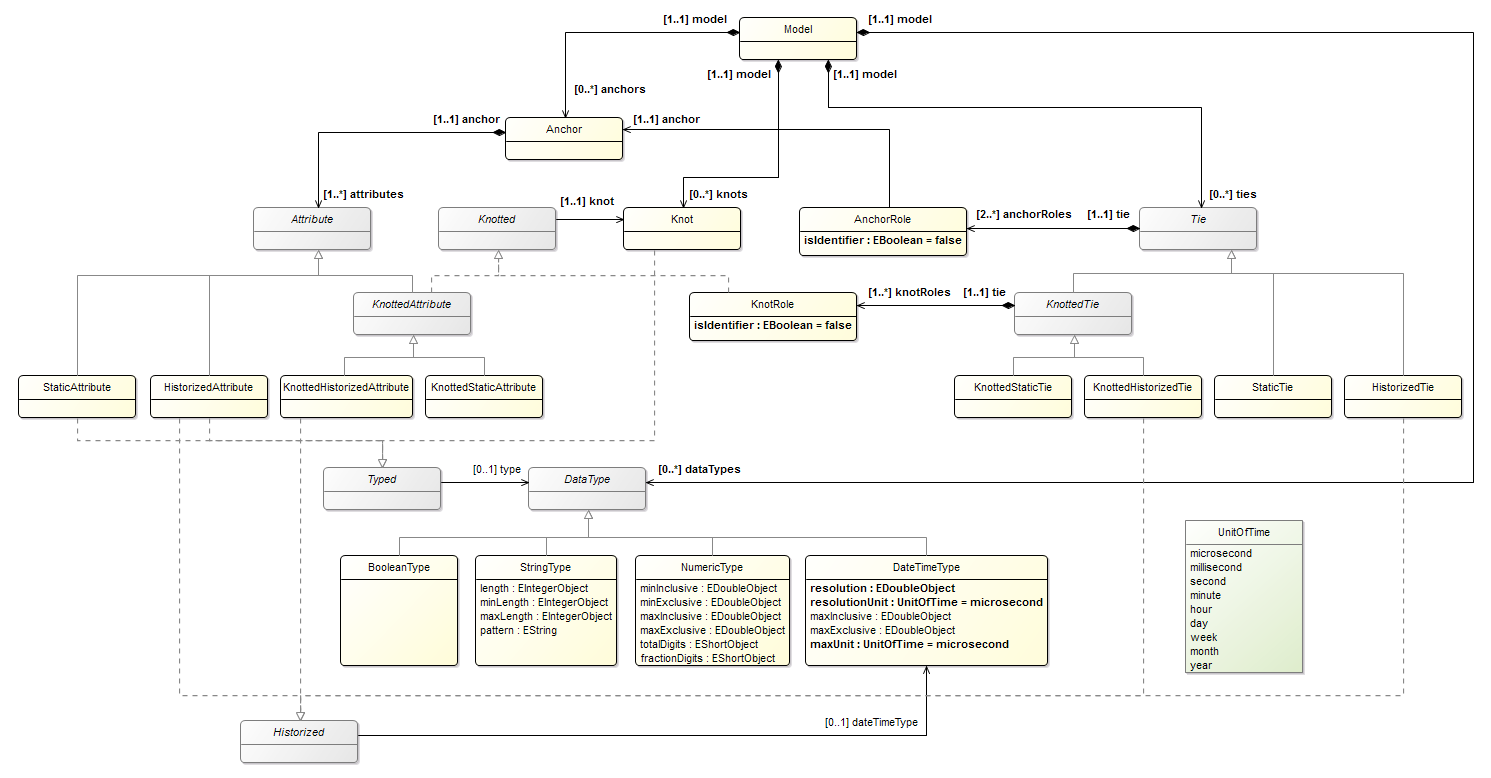
Note
The figure does not show the Named interface, because with it the diagram will become completely unreadable.
Some properties use the EDoubleObject type, and not just EDouble, because these properties are optional. If you specify the data type EDouble for them, then by default they will be set to 0, and it will be impossible to understand whether they are set to 0 or they are simply not specified.
Consider our improvements in more detail.
Supplement about abstract classes and interfaces
In the initial class diagram above, it can be seen that for all attributes and scrap with preservation of history, the relationship with the metaclass TIME TYPE is defined. Some metaclasses have a similar relationship with the metaclass DATA TYPE. Also many metaclasses have a name attribute, although it is not shown in the figure.
All these identical properties and relationships can be put into the corresponding metaclasses Historized, Typed, Named, etc. In Anchor models, instances of these metaclasses cannot exist, so they should be noted as abstract.
Ecore allows multiple inheritance. And, for example, the HistorizedAttribute may well be inherited from the Attribute, Typed and Historized metaclasses. However, if you look at the Java API that is generated for Ecore-metamodels using multiple inheritance, you will see that only one of the basic metaclasses will be implemented as a Java class, and the rest will be implemented as Java interfaces (because Java does not support multiple inheritance). Therefore, for uniqueness, it is desirable to immediately mark some metaclasses as interfaces in the Ecore-metamodel.
Addition about data types
If you look at examples of Anchor-models on the site , you will find data types of the type varchar (42), money, etc. there. See that the data types for the keys are explicitly set in the model. Personally, I was very surprised by this connection to physics. Initially, Anchor made an impression of a rather conceptual modeling language, but it turned out that the models were tied to a specific DBMS.
We will eliminate this flaw by adding several abstract data types (you can see them in the figure above), which in subsequent articles will be translated into data types of a specific DBMS. Well, in general, looking ahead, we created this metamodel in order to show the possibility of transforming models in the following articles. And even in the comments on the Anchor site I even read some hell about generating SQL queries using XSLT - this is bad.
Conclusion
After reading this article, you should be able to create modeling languages using the Eclipse Modeling Framework. You may also have learned something interesting from data modeling.
In the next article I will describe how to do not just a tree editor, but a diagram editor .
Source: https://habr.com/ru/post/266433/
All Articles