Profiling of hybrid cluster applications MPI + OpenMP

Libraries that implement the MPI standard (Message Passing Interface) are the most popular mechanism for organizing computations on a cluster. MPI allows you to transfer messages between nodes (servers), but no one bothers to run multiple MPI processes on one node, realizing the potential of several cores. So often HPC applications are written, it's easier. And while the number of cores on one node was small, there were no problems with the “pure MPI” approach. But today the number of cores goes to dozens, if not hundreds, for co-processors Intel Xeon-Phi. And in such a situation, the launch of dozens of processes on one machine becomes not entirely effective.
The fact is that MPI processes communicate through a network interface (albeit implemented through shared memory on the same machine). This entails excessive copying of data through multiple buffers and increased memory consumption.
')
For parallel computing inside a single machine with shared memory, threads and task distribution between them are much better suited. Here the most popular in the world of HPC is the OpenMP standard.
It would seem - well, we use OpenMP inside the node, and MPI for inter-node communications. But not everything is so simple. Using two frameworks (MPI and OpenMP) instead of one not only carries the additional complexity of programming, but also does not always give the desired performance gain — at least not immediately. We still have to decide how to distribute the calculations between MPI and OpenMP, and, perhaps, solve problems specific to each level.
In this article I will not describe the creation of hybrid applications - information is not difficult to find. We will look at how you can analyze hybrid applications using Intel Parallel Studio tools, choosing the optimal configuration and eliminating bottlenecks at different levels.
For the tests, we will use NASA Parallel Benchmark:
- CPU: Intel Xeon processor E5-2697 v2 @ 2.70GHz, 2 sockets, 12 cores in each.
- OS: RHEL 7.0 x64
- Intel Parallel Studio XE 2016 Cluster Edition
- Compiler: Intel Compiler 16.0
- MPI: Intel MPI library 5.1.1.109
- Workload: NPB 3.3.1, “CG - Conjugate Gradient, irregular memory access and communication” module, class B
The benchmark is already implemented hybrid and allows you to configure the number of MPI processes and OpenMP streams. It is clear that for inter-node communications there is no alternative to MPI (within our application). The intrigue is that run on one node - MPI or OpenMP.
MPI Performance Snapshot
We have 24 cores at our disposal. Let's start with the traditional approach - only MPI. 24 MPI process, 1 thread each. To analyze the program, we will use the new tool released in the latest version of Intel Parallel Studio - MPI Performance Snapshot. Just add the “-mps” key to the mpirun startup line:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh source /opt/intel/itac/9.1.1.017/intel64/bin/mpsvars.sh --vtune mpirun -mps –n 24 ./bt-mz.B.24 mps -g stats.txt app_stat.txt _mps The first two lines set the right environment, the third runs the program with MPS profiling. The last line forms the report in html format. Without -g, the report will be displayed on the console - convenient for viewing directly on the cluster, but more beautiful in HTML:


MPS provides top-level performance evaluation. The overhead of its launch is extremely small, you can quickly make an assessment of the application, even on a large scale (32000 processes tested).
First we look at the shares of MPI time and Computation time. We have 32% of the time spent on MPI, almost all due to the imbalance of the load - some processes wait while others count. In the blocks on the right, an estimate is given - MPI time is labeled HIGH - too much to spend on communication. There is also a reference to another tool - Intel Trace Analyzer and Collector (ITAC), for detailed analysis of MPI problems. About OpenMP no problems highlighted, which is not surprising, because we actually turned it off.
MPS also considers hardware performance metrics: GFPLOS, CPI and the “Memory Bound” metric - an overall assessment of memory performance. And still memory consumption (for one MPI process) - maximum and average.
Intel Trace Analyzer and Collector
MPS showed that the main problem in the “24x1” configuration in MPI. To find out the reasons, we collect the ITAC profile:
source /opt/intel/itac/9.1.1.017/intel64/bin/itacvars.sh mpirun -trace -n 24 ./bt-mz.B.24 Open the track in ITAC GUI - I used the Windows version. The graph of the Quantitative Timeline clearly shows that the proportion of MPI is large, and communications are distributed with some cyclical nature. The uppermost graph shows periodic bursts of MPI activity:
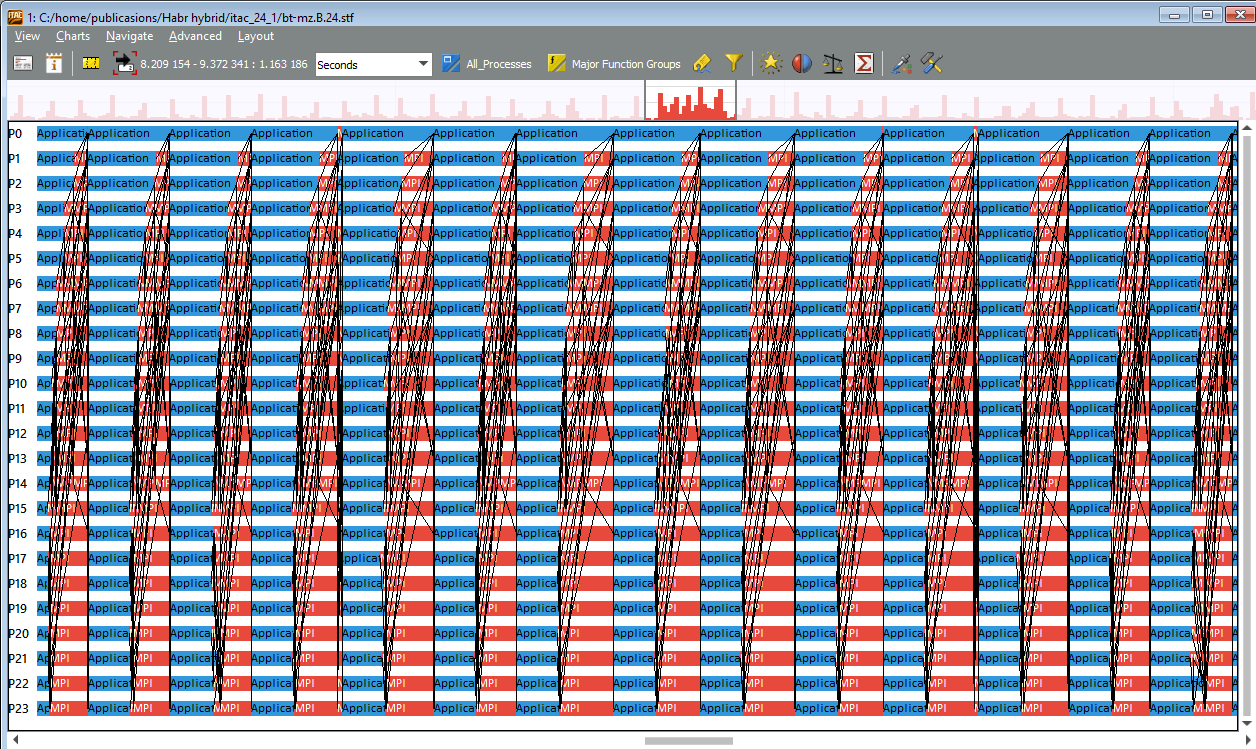
If you select several such bursts on the Event Timeline scale, you can observe that the communications are unevenly distributed. Processes with ranks 0-4 are considered more, and those with ranks 15-23 are waiting more. Load imbalance is evident:
On the Message Profile graph, you can evaluate which processes are exchanging messages and where communication is the longest:
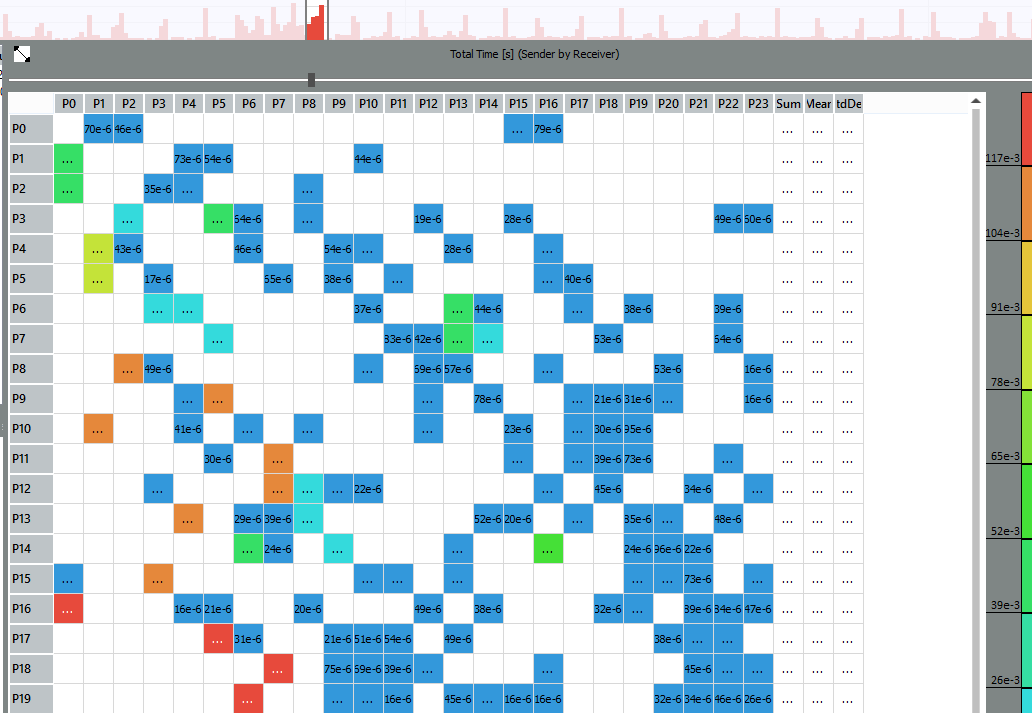
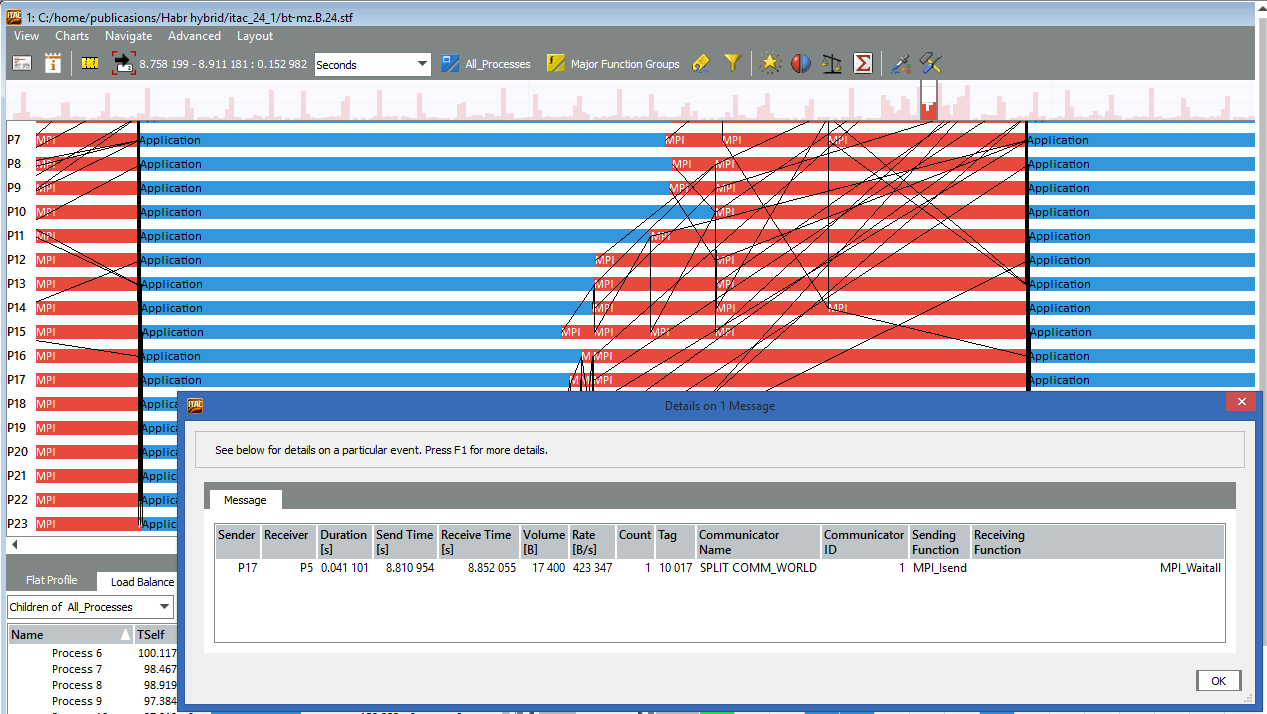
For example, messages between processes with ranks 17 and 5, 16 and 0, 18 and 7, and so on pass longer than others. By increasing the Event Timeline even more, you can click on the black line at rank 17 and see the transfer details - from whom to whom, message size, send and receive calls:
The Performance Assistant panel describes specific problems found by the tool in a selected region. For example, "late reference":
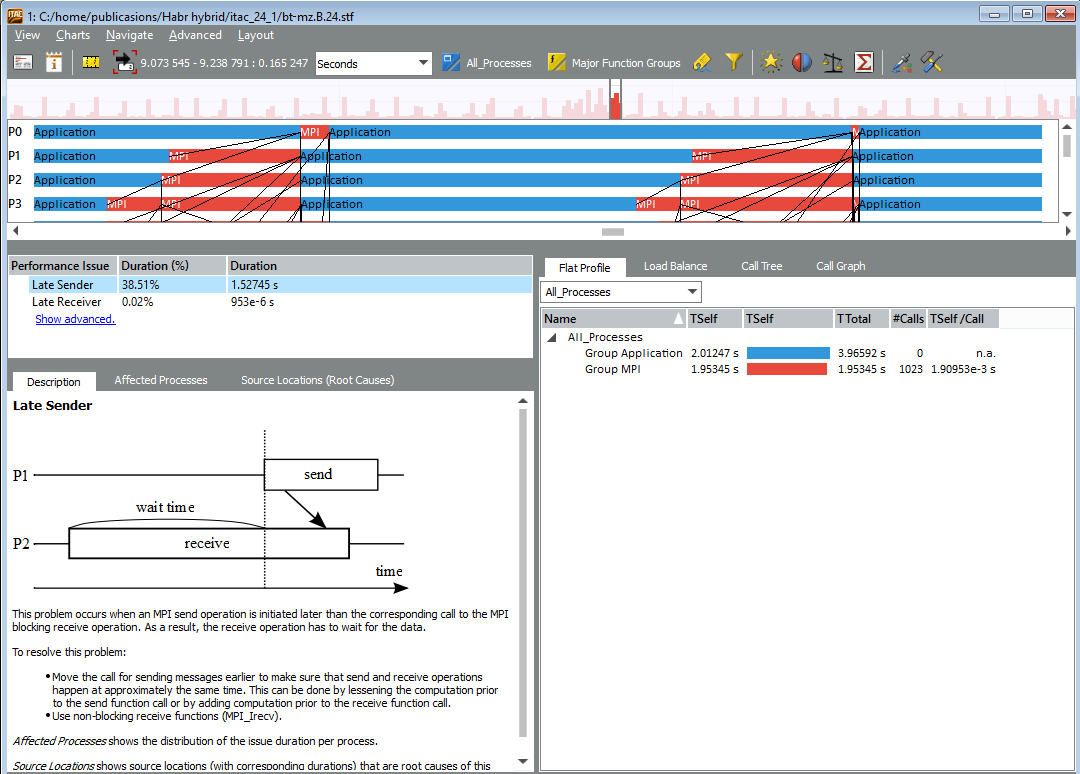
The imbalance in MPI can be caused not only by shortcomings in the communication scheme, but also by problems in useful calculations — when some processes are considered slower than others. If we are interested in what this application is spending time inside of any of the processes, and what the problem may be, ITAC can generate a command line to run Intel VTune Amplifier for this rank (for example, on the 2nd):

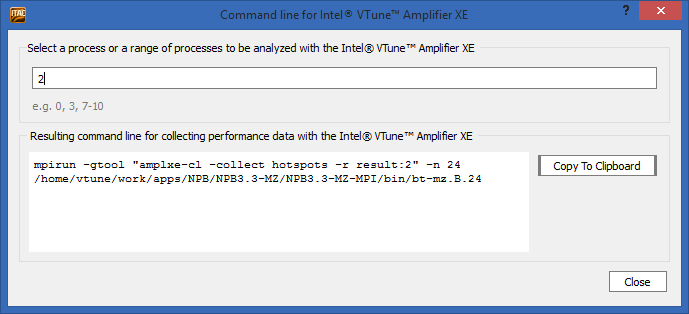
But back to the VTune Amplifier later. And in general, ITAC gives a lot of opportunities for a detailed study of MPI communications, but our task now is to choose the optimal balance between OpenMP and MPI. And for this, it is not necessary to immediately correct the MPI communication at 24 ranks - you can try other options first.
Other options
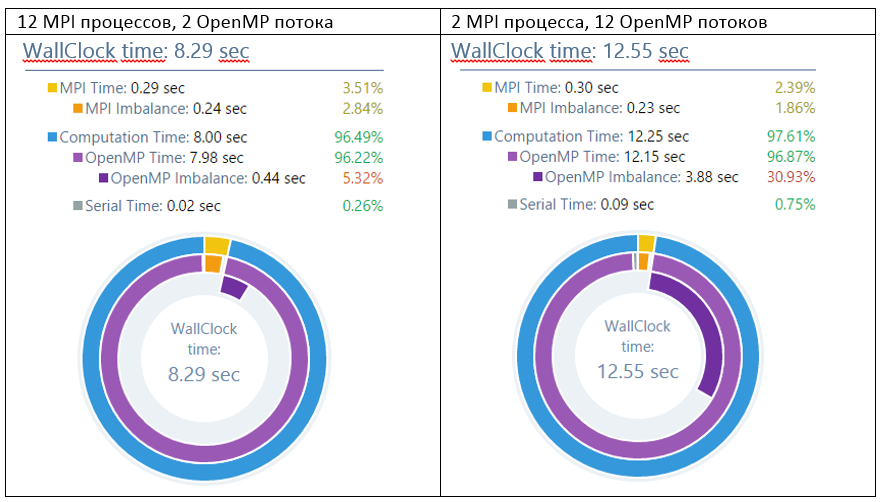

So, in an empirical way, it turned out that 12x2 and 6x4 distributions work better than others. Even 2 OpenMP threads per process are significantly faster than 2 MPI processes. However, with an increase in the number of threads, the running time starts to grow again: 2x12 is even worse than “pure MPI”, and 1x24 makes no sense even to give. And the blame for the imbalance of work, which is poorly distributed over a large number of OpenMP streams. Option 2x12 has as much as 30% imbalance.
Here we may well stop, because A compromise of 12x2 or 6x4 is quite acceptable. But you can dig deeper - to investigate what the problem with OpenMP scaling.
VTune Amplifier
Intel VTune Amplifier XE is perfect for a detailed analysis of OpenMP problems, which we have already written in detail about.
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh mpirun -gtool "amplxe-cl -c advanced_hotspots -r my_result:1" -n 24 ./bt-mz.B.24 To run analyzers such as VTune Amplifier and Intel Advisor XE, it has become very convenient to use the gtool option syntax (only in Intel MPI). It is embedded in the launch line of the MPI application, allowing you to run the analysis only on selected processes - in our example, only for rank 1.
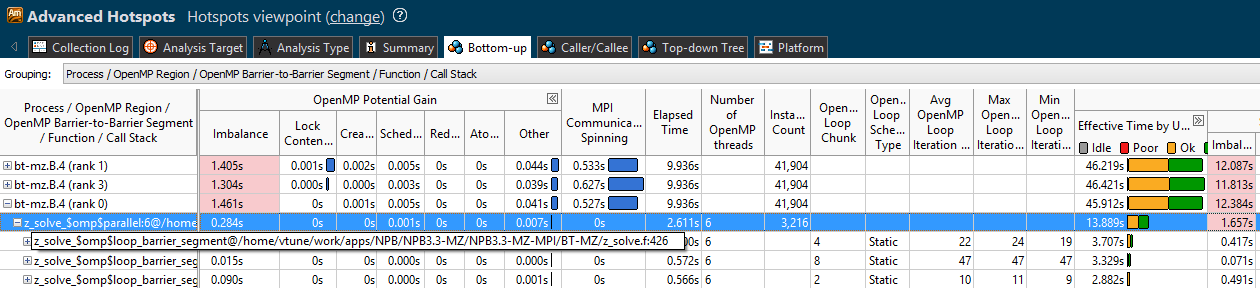
Let's look at the profile of option “2 MPI processes, 12 OpenMP streams”. In one of the most costly parallel cycles, 0.23 seconds out of 1.5 goes to imbalance. Further in the table it can be seen that the type of dispatch is static, the work is not redistributed. In addition, there are only 41 iterations in the loop, and 10-20 iterations in adjacent cycles. Those. with 12 threads, each will get only 3-4 iterations. Apparently, this is not enough for effective load balancing.
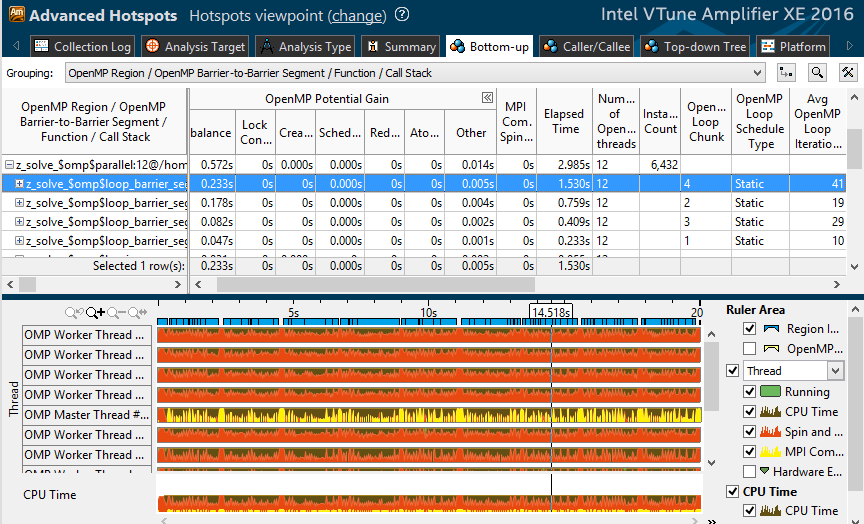
With 2-4 streams, each of them gets more work, and the relative time of active waiting caused by imbalance is reduced. As evidenced by the “6x4” profile - imbalance is much lower:
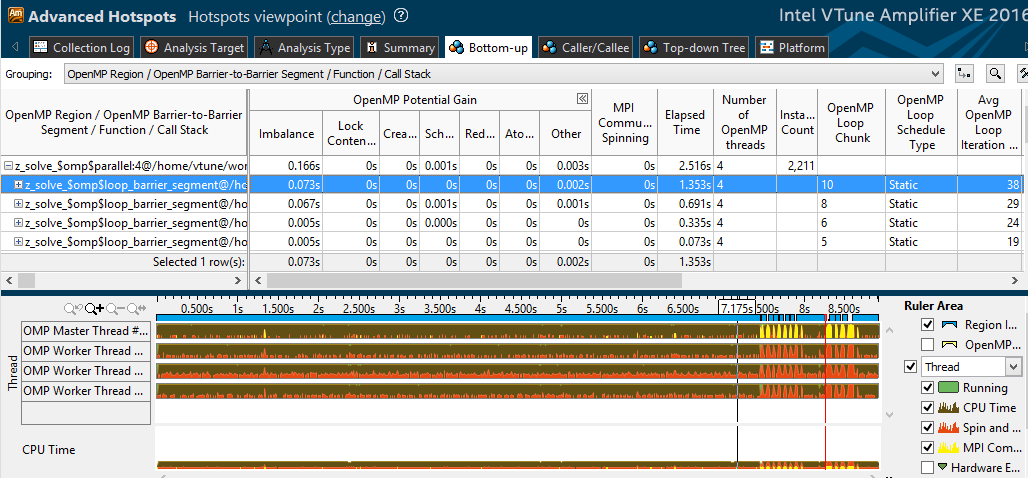
In addition, the MPI version appeared in the Intel VTune Amplifier 2016 version - the “MPI Communication Spinning” column and the yellow marking on the timeline. You can run the VTune profile for several processes at once on one node, and watch MPI spinning along with OpenMP metrics in each of them:

Intel Advisor XE
Going down through parallelism levels, from cluster scale (MPI), to single node streams (OpenMP) we get to parallelism on data within one stream - vectorization based on SIMD instructions. Here, too, there can be serious potential for optimization, however, it was not for nothing that we got to it last - first you need to solve problems at the MPI and OpenMP levels, since there is potentially more to win. About Advisor not so long ago there were two posts (the first and the second ), so here I will limit myself to the launch line:
source /opt/intel/advisor_xe/advixe-vars.sh mpirun -gtool "advixe-cl -collect survey --project-dir ./my_proj:1" -n 2 ./bt-mz.2 Then we analyze the vectorization of the code, as we wrote earlier. Advisor is an important part of the ecosystem analysis of cluster MPI programs. In addition to a deep study of code vectorization, Advisor helps to prototype multi-threaded execution and checks memory access patterns.
Summary
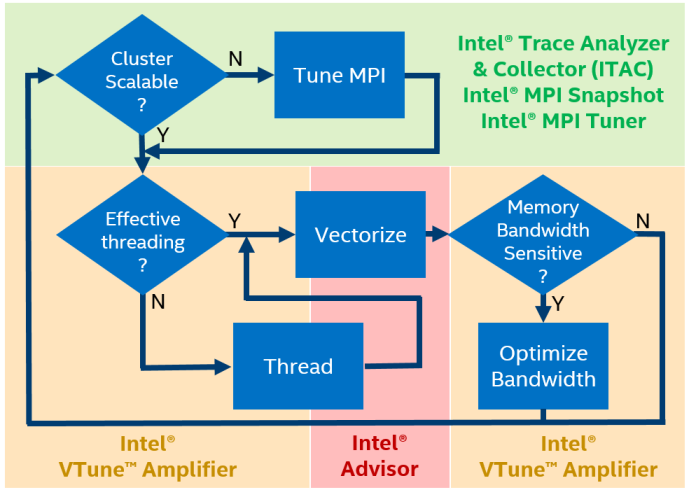
Intel Parallel Studio offers four tools to analyze the performance of hybrid HPC applications:
- MPI Performance Snapshot (cluster level) - quick assessment of efficiency, minimum overhead, profiling up to 32000 MPI processes, quick assessment of MPI and OpenMP imbalance, overall performance evaluation (GFLOPS, CPI).
- Intel Trace Analyzer and Collector (cluster level) - a detailed study of MPI, identification of communication patterns, localization of specific bottlenecks.
- Intel VTune Amplifier XE (single node level) - a detailed profile with source code and stacks, imbalances and other OpenMP problems, analysis of cache and memory usage, and much more.
- Intel Advisor XE (single node level) - analysis of the use of vector instructions and identifying the causes of their inefficiency, prototyping of multi-threaded execution, analysis of memory access patterns.
Source: https://habr.com/ru/post/266409/
All Articles