Techniques for using mask registers in the AVX512 code
In Intel processors, AVX2 replaces AVX512 instructions, in which the concept of mask registers has appeared. The author of this article has been developing the version of the Intel Integrated Performance Primitives library optimized for AVX512 for several years and has gained quite a lot of experience using AVX512 instructions with masks, which was decided to be combined into one separate article, since the use of such instructions with masks allows you to simplify and speed up code in addition to acceleration from double increasing the width of registers.
Consider the addition function of two images.
The function code is very simple and in principle the icl compiler is quite capable of vectorizing this code. However, our goal is to demonstrate the use of masked avx512 registers, so we will write the first and obvious version of the avx512 code.
In this code, a loop is added, which adds up to 16 elements at a time per iteration. Since the width of the image can be arbitrary and not a multiple of 16, then in the next cycle the elements remaining until the end of the line are added. The number of such elements can reach 15, and the effect of this cycle on the overall performance can be quite large. Using the same mask registers can significantly accelerate the processing of the "tail".
The array len2mask is used to convert the number to the corresponding number of bits in a row. And instead of a scalar loop, we get only one if, which in principle is also not necessary, since in the case of a mask consisting of only zeros, reading and writing will not be performed.
In order to achieve maximum performance, it is recommended to align the data with the width of the cache line, and downloads to the address aligned to the register width. In Skylake, the width of the cache line is still 64 bytes, therefore, in our code, we can add this alignment with pDst again using mask operations, but only before the main loop.
The code began to look shorter, and with a sufficiently long sequence of calculations, the cost of calculating the mask in each iteration against such a background may be insignificant.
In various image processing algorithms, a binary mask may be one of the input parameters. For example, such a mask is used in image morphology operations.
The function searches for the smallest pixel inside a 3x3 square. The pMask input mask is an array of 3x3 = 9 bytes. If the value of the byte is not zero, then the input pixel from the 3x3 square participates in the search; if it is equal, it does not participate.
')
We write avx512 code.
First, an array of masks __mmask msk [9] is formed. Each mask is obtained by replacing a byte from pMask with a bit (0 with 0, all other values with 1) and this bit is multiplied by 16 elements. The main loop loads 16 elements on this mask. Moreover, if the item is not involved in the search, then it will not be loaded. In this code, the tail is also processed using masks, we simply perform the & operation on the mask of the morphology operation and the tail mask.
Of course, the demonstrated code is not entirely optimal, but it demonstrates the idea itself, and complicating the code would lead to a loss of clarity.
Even in the first 256-bit instruction set AVX, the registers were divided by a barrier into 2 parts, called lane. Most vector instructions independently process these parts. It looks like 2 parallel SSE instructions. In avx512, the register is already divided into four 128-bit parts of four float / int elements. And in many image processing algorithms three channels are used and combining them in 4 is quite problematic. In this case, you can consider using the instructions of the form expand / compress
__m512 _mm512_mask_expandloadu_ps (__m512 src, __mmask16 k, void const * mem_addr)
void _mm512_mask_compressstoreu_ps (void * base_addr, __mmask16 k, __m512 a)
The _mm512_mask_expandloadu_ps instruction loads from memory a continuous block of data float length equal to the number of 1 bits in the mask. Thus a block with a length of 0 to 16 elements can be loaded. In the register-receiver data is placed as follows. Since the least significant bit of the mask is checked, if the bit is 1, then the memory element is written to the register, if 0, then we proceed to consider the next bit and the same element, fig. 3.1
Fig. 3.1 Demonstration of _mm512_mask_expandloadu_ps
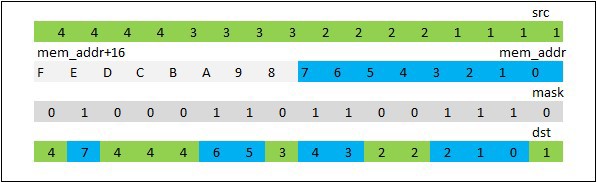
It can be seen that the memory region is “stretched” (expand) over the entire 512-bit register. The _mm512_mask_compressstoreu_ps instruction works in the opposite direction - it “compresses” (compress) the register by mask and writes it into a continuous memory area.
So, let's say we need to go from the RGB color space to XYZ.
Using the expand / compress avx512 code may look like this.
With the help of _mm512_mask_expandloadu_ps we put 4 pixels in different lane, after which we consistently form r3r3r3r3 ... r0r0r0, ... g0g0g0, b0b0b0 and multiply by the conversion factors. To check the overflow, mask operations _mm512_mask_max / min_ps are also used. Writing the converted data back to memory is done with the _mm512_mask_compressstoreu_ps command. In this function, masks can also be used for tail processing, depending on the length of the tail.
If you have read this far, then you are already prepared for the most interesting, in my opinion, area of application of mask registers. This is a vectoring of cycles with conditions. We are talking about some kind of predicate register, available in processors of the Itanium family. Consider a simple function that has an if inside a for loop.
The function interpolates in adjacent horizontal or vertical elements, between which the difference is minimal. The main thing here is that inside the cycle there is a division into two branches, when the if-condition is true, and when not. But, we can calculate the values on avx512 registers in either case, and then combine them by mask.
There can be several such if in the implemented algorithm, for them it is possible to start new masks as long as the code is faster than the scalar.
In fact, the icc compiler is quite capable of vectorizing code 4.1. To do this, it suffices to add the restrict keyword to the pointers pSrc1 and pDst and the –Qrestrict key.
Recall that the restrict modifier indicates to the compiler that access to the object is carried out only through this pointer, and thus the pSrc1 and pDst vectors do not overlap, which makes vectorization possible.
Measurements on the internal CPU simulator with avx512 support show that the performance is almost equal to the performance of our avx512 code. Ie the compiler also knows how to effectively use masks
It would seem that this is all. But let's see what happens if we slightly modify our function and add the dependency between iterations to it.
The function also performs interpolation on neighboring pixels, and if the difference in vertical and horizontal is the same, then the interpolation direction used in the previous iteration is used. On algorithms of this kind, the effect of the out of order mechanism implemented in modern cpu is reduced due to the fact that a long sequence of dependent operations is formed. The compiler also now can not vectorize the cycle and performance is 17 times slower. Those. just about the width of 16 float elements in the AVX512 register. Now let's try to somehow modify our avx512 code to get at least some kind of acceleration.
We introduce the following binary variable masks
mskV (n) - the difference is minimal for the nth element of V
mskE (n) - for the n-th element of V and H the differences are the same
mskD (n) - V interpolation is used for the nth element.
Now we will build a truth table, how mskD (n) is formed depending on mskV (n), mskE (n) and the previous mask used - mskD (n-1)
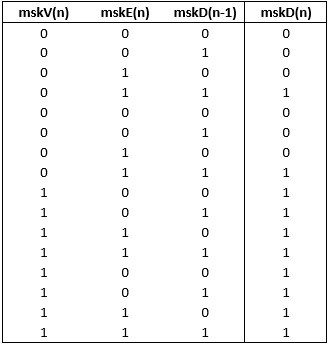
From the table it follows that
mskD (n) = mskV (n) | (mskE (n) & mskD (n-1)),
which in general was so obvious. So our avx512 code will look like this.
In it all 16 bits of the mask are sequentially sorted. At 64x64, it works ~ 1.7X times faster than C-shny. Well, at least I managed to get something. The next possible optimization is that you can pre-calculate all the combinations of masks. At each iteration of 16 elements, we have 16 bits mskV, 16 bits mskE, and 1 bit from the previous iteration. Total 2 ^ 33 degrees of options for mskD. It's a lot. And what if we process not by 16, but by 8 elements per iteration? We get 2 ^ (8 + 8 + 1) = 128kbyte table. And this is quite sane size. Create an initialization function.
Rewrite the code.
The code began to work ~ 4.1X times faster. You can add processing for 16 elements, but the table will have to turn twice for the iteration.
Now the acceleration is ~ 5.6X compared to the original C code, which is very good for the algorithm with feedback. Thus, the combination of a mask register and a pre-computed table allows for a significant performance increase. Code of this kind is not specifically selected for the article and is found for example in photo processing algorithms, when converting images from a RAW format. True, integer values are used there, but such a table method can also be applied to them.
This article shows only some of the ways to apply the AVX 512's mask instructions. You can use them in your applications or invent your own tricks. Or you can use the IPP library, which already contains code optimized specifically for Intel processors with avx512 support, an important part of which is the instructions with mask registers.
Example 1. We apply instructions with masks "before and after" the main loop
Consider the addition function of two images.
Sheet 1.1
void add_ref( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { for( i = 0; i < width; i++ ) { pDst[i] = pSrc1[i] + pSrc2[i]; } pSrc1 = pSrc1 + src1Step; pSrc2 = pSrc2 + src2Step; pDst = pDst + dstStep; } } The function code is very simple and in principle the icl compiler is quite capable of vectorizing this code. However, our goal is to demonstrate the use of masked avx512 registers, so we will write the first and obvious version of the avx512 code.
Sheet 1.2
void add_avx512( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h<height; h++ ) { i = 0; __m512 zmm0, zmm1; for(i=i; i < (width&(~15)); i+=16 ) { zmm0 = _mm512_loadu_ps(pSrc1+i ); zmm1 = _mm512_loadu_ps(pSrc2+i ); zmm0 = _mm512_add_ps(zmm0, zmm1); _mm512_storeu_ps (pDst+i, zmm0 ); } for(i=i; i < width; i++ ) { pDst[i] = pSrc1[i] + pSrc2[i]; } pSrc1 = pSrc1 + src1Step; pSrc2 = pSrc2 + src2Step; pDst = pDst + dstStep; } } In this code, a loop is added, which adds up to 16 elements at a time per iteration. Since the width of the image can be arbitrary and not a multiple of 16, then in the next cycle the elements remaining until the end of the line are added. The number of such elements can reach 15, and the effect of this cycle on the overall performance can be quite large. Using the same mask registers can significantly accelerate the processing of the "tail".
Sheet 1.3
__mmask16 len2mask[] = { 0x0000, 0x0001, 0x0003, 0x0007, 0x000F, 0x001F, 0x003F, 0x007F, 0x00FF, 0x01FF, 0x03FF, 0x07FF, 0x0FFF, 0x1FFF, 0x3FFF, 0x7FFF, 0xFFFF }; void add_avx512_2( float* pSrc1, int src1Step, const float* pSrc2, int src2Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { i = 0; __m512 zmm0, zmm1; __mmask16 msk; for(i=i; i < (width&(~15)); i+=16 ) { zmm0 = _mm512_loadu_ps(pSrc1+i ); zmm1 = _mm512_loadu_ps(pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); _mm512_storeu_ps (pDst+i, zmm0 ); } msk = len2mask[width - i]; if(msk){ zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i ); zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); _mm512_mask_storeu_ps (pDst+i, msk, zmm0 ); } pSrc1 = pSrc1 + src1Step; pSrc2 = pSrc2 + src2Step; pDst = pDst + dstStep; } } The array len2mask is used to convert the number to the corresponding number of bits in a row. And instead of a scalar loop, we get only one if, which in principle is also not necessary, since in the case of a mask consisting of only zeros, reading and writing will not be performed.
In order to achieve maximum performance, it is recommended to align the data with the width of the cache line, and downloads to the address aligned to the register width. In Skylake, the width of the cache line is still 64 bytes, therefore, in our code, we can add this alignment with pDst again using mask operations, but only before the main loop.
Sheet 1.4
void add_avx512_3(float* pSrc1, int src1Step, const float* pSrc2, int src2Step, float* pDst, int dstStep, int width, int height) { int h, i, t; for( h = 0; h < height; h++ ) { i = 0; __m512 zmm0, zmm1; __mmask16 msk; t = ((((int)pDst) & (63)) >> 2); msk = len2mask[t]; if(msk){ zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i ); zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); _mm512_mask_storeu_ps (pDst+i, msk, zmm0 ); } i += t; for(i=i; i < (width&(~15)); i+=16 ) { zmm0 = _mm512_loadu_ps(pSrc1+i ); zmm1 = _mm512_loadu_ps(pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); _mm512_storeu_ps (pDst+i, zmm0 ); } msk = len2mask[width - i]; if(msk){ zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i ); zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); _mm512_mask_storeu_ps (pDst+i, msk, zmm0 ); } pSrc1 = pSrc1 + src1Step; pSrc2 = pSrc2 + src2Step; pDst = pDst + dstStep; } } <source> </spoiler> add . , , . . . . 1.5 <spoiler title=" 1.5"> <source lang="C++"> #define min(a,b) ((a)<(b)?(a):(b)) void add_avx512_4( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { i = 0; __m512 zmm0, zmm1; __mmask16 msk; for(i=i; i < width; i+=16 ) { msk = len2mask[min(16, width - i)]; zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i ); zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i ); zmm0 = _mm512_add_ps (zmm0, zmm1); /*THE LONG PIPELINE HERE*/ _mm512_mask_storeu_ps (pDst+i, msk, zmm0 ); } pSrc1 = pSrc1 + src1Step; pSrc2 = pSrc2 + src2Step; pDst = pDst + dstStep; } } The code began to look shorter, and with a sufficiently long sequence of calculations, the cost of calculating the mask in each iteration against such a background may be insignificant.
Example 2. Mask as an immediate part of the implemented algorithm.
In various image processing algorithms, a binary mask may be one of the input parameters. For example, such a mask is used in image morphology operations.
Sheet 2.1
void morph_3x3_ref( const float* pSrc1, int src1Step, char* pMask, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { for(i=0; i < width; i++ ) { int x, y; char* pm = pMask; /*we assume that pMask is not zero total*/ float m = 3.402823466e+38f; float val = 0.0; for (y = 0; y < 3;y++){ for (x = 0; x < 3; x++){ if (*pm){ val = pSrc1[i + src1Step*y + x]; if (val < m) { m = val; } } pm++; } } pDst[i] = m; } pSrc1 = pSrc1 + src1Step; pDst = pDst + dstStep; } } The function searches for the smallest pixel inside a 3x3 square. The pMask input mask is an array of 3x3 = 9 bytes. If the value of the byte is not zero, then the input pixel from the 3x3 square participates in the search; if it is equal, it does not participate.
')
We write avx512 code.
Sheet 2.2
void morph_3x3_avx512( const float* pSrc1, int src1Step, char* pMask, float* pDst, int dstStep, int width, int height) { int h, i; __mmask msk[9], tail_msk; for ( i = 0; i < 9; i++){ msk[i] = (!pMask[i]) ? 0 : 0xFFFF;//create load mask } tail_msk = len2mask[width & 15]; //tail mask for( h = 0; h < height; h++ ) { __m512 zmm0, zmmM; int x, y; i = 0; for(i=i; i < (width&(~15)); i+=16 ) { zmmM = _mm512_set1_ps(3.402823466e+38f); for (y = 0; y < 3;y++){ for (x = 0; x < 3; x++){ zmm0 = _mm512_mask_loadu_ps(zmmM, msk[3*y+x], &pSrc1[i + src1Step*y + x]); zmmM = _mm512_min_ps(zmm0, zmmM); } } _mm512_storeu_ps (pDst+i, zmmM ); } if(tail_msk) { zmmM = _mm512_set1_ps(3.402823466e+38f); for (y = 0; y < 3;y++){ for (x = 0; x < 3; x++){ zmm0=_mm512_mask_loadu_ps(zmmM,msk[3*y+x]&tail_msk,&pSrc1[i+src1Step*y+x]); zmmM=_mm512_min_ps(zmm0, zmmM); } } _mm512_mask_storeu_ps (pDst+i, tail_msk, zmmM ); } pSrc1 = pSrc1 + src1Step; pDst = pDst + dstStep; } } First, an array of masks __mmask msk [9] is formed. Each mask is obtained by replacing a byte from pMask with a bit (0 with 0, all other values with 1) and this bit is multiplied by 16 elements. The main loop loads 16 elements on this mask. Moreover, if the item is not involved in the search, then it will not be loaded. In this code, the tail is also processed using masks, we simply perform the & operation on the mask of the morphology operation and the tail mask.
Of course, the demonstrated code is not entirely optimal, but it demonstrates the idea itself, and complicating the code would lead to a loss of clarity.
Example 3. Expand / compress family instructions
Even in the first 256-bit instruction set AVX, the registers were divided by a barrier into 2 parts, called lane. Most vector instructions independently process these parts. It looks like 2 parallel SSE instructions. In avx512, the register is already divided into four 128-bit parts of four float / int elements. And in many image processing algorithms three channels are used and combining them in 4 is quite problematic. In this case, you can consider using the instructions of the form expand / compress
__m512 _mm512_mask_expandloadu_ps (__m512 src, __mmask16 k, void const * mem_addr)
void _mm512_mask_compressstoreu_ps (void * base_addr, __mmask16 k, __m512 a)
The _mm512_mask_expandloadu_ps instruction loads from memory a continuous block of data float length equal to the number of 1 bits in the mask. Thus a block with a length of 0 to 16 elements can be loaded. In the register-receiver data is placed as follows. Since the least significant bit of the mask is checked, if the bit is 1, then the memory element is written to the register, if 0, then we proceed to consider the next bit and the same element, fig. 3.1
Fig. 3.1 Demonstration of _mm512_mask_expandloadu_ps
It can be seen that the memory region is “stretched” (expand) over the entire 512-bit register. The _mm512_mask_compressstoreu_ps instruction works in the opposite direction - it “compresses” (compress) the register by mask and writes it into a continuous memory area.
So, let's say we need to go from the RGB color space to XYZ.
Sheet 3.1
void rgb_ref( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { for(i=0; i < width; i++ ) { pDst[3*i+0]=(0.412f*pSrc1[3*i]+0.357f*pSrc1[3*i+1]+0.180f*pSrc1[3*i+2]); pDst[3*i+1]=(0.212f*pSrc1[3*i]+0.715f*pSrc1[3*i+1]+0.072f*pSrc1[3*i+2]); pDst[3*i+2]=(0.019f*pSrc1[3*i]+0.119f*pSrc1[3*i+1]+0.950f*pSrc1[3*i+2]); if (pDst[3 * i + 2] < 0.0){ pDst[3 * i + 2] = 0.0; } if (pDst[3 * i + 2] > 1.0){ pDst[3 * i + 2] = 1.0; } } pSrc1 = pSrc1 + src1Step; pDst = pDst + dstStep; } } Using the expand / compress avx512 code may look like this.
Sheet 3.2
void rgb_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { __m512 zmm0, zmm1, zmm2, zmm3; i = 0; for(i=i; i < (width&(~3)); i+=4 ) { zmm0 = _mm512_mask_expandloadu_ps(_mm512_setzero_ps(), 0x7777, &pSrc1[3*i ]); zmm1 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.019f, 0.212f, 0.412f), _mm512_shuffle_ps(zmm0, zmm0, 0x00)); zmm2 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.119f, 0.715f, 0.357f), _mm512_shuffle_ps(zmm0, zmm0, 0x55)); zmm3 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.950f, 0.072f, 0.180f), _mm512_shuffle_ps(zmm0, zmm0, 0xAA)); zmm0 = _mm512_add_ps(zmm1, zmm2); zmm0 = _mm512_add_ps(zmm0, zmm3); zmm0 = _mm512_mask_max_ps(zmm0, 0x4444,_mm512_set1_ps(0.0f), zmm0); zmm0 = _mm512_mask_min_ps(zmm0, 0x4444,_mm512_set1_ps(1.0f), zmm0); _mm512_mask_compressstoreu_ps (pDst+3*i, 0x7777, zmm0 ); } pSrc1 = pSrc1 + src1Step; pDst = pDst + dstStep; } } With the help of _mm512_mask_expandloadu_ps we put 4 pixels in different lane, after which we consistently form r3r3r3r3 ... r0r0r0, ... g0g0g0, b0b0b0 and multiply by the conversion factors. To check the overflow, mask operations _mm512_mask_max / min_ps are also used. Writing the converted data back to memory is done with the _mm512_mask_compressstoreu_ps command. In this function, masks can also be used for tail processing, depending on the length of the tail.
Example 4. Branching vectorization
If you have read this far, then you are already prepared for the most interesting, in my opinion, area of application of mask registers. This is a vectoring of cycles with conditions. We are talking about some kind of predicate register, available in processors of the Itanium family. Consider a simple function that has an if inside a for loop.
Sheet 4.1
#define ABS(A) (A)>=0.0f?(A):(-(A)) void avg_ref( float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { for(i=0; i < width; i++ ) { float dv, dh; float valU = pSrc1[src1Step*(h - 1) + i ]; float valD = pSrc1[src1Step*(h + 1) + i ]; float valL = pSrc1[src1Step*( h ) + (i-1)]; float valR = pSrc1[src1Step*( h ) + (i+1)]; dv = ABS(valU - valD); dh = ABS(valL - valR); if(dv<=dh){ pDst[i] = (valU + valD) * 0.5f; //A branch } else { pDst[i] = (valL + valR) * 0.5f; //B branch } } pDst = pDst + dstStep; } } The function interpolates in adjacent horizontal or vertical elements, between which the difference is minimal. The main thing here is that inside the cycle there is a division into two branches, when the if-condition is true, and when not. But, we can calculate the values on avx512 registers in either case, and then combine them by mask.
Sheet 4.2
void avg_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { i = 0; for(i=i; i < (width&(~15)); i+=16 ) { __m512 zvU, zvD, zvL, zvR; __m512 zdV, zdH; __m512 zavgV, zavgH, zavg; __mmask16 mskV; zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i ); zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i ); zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1)); zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1)); zdV = _mm512_sub_ps(zvU, zvD); zdH = _mm512_sub_ps(zvL, zvR); zdV = _mm512_abs_ps(zdV); zdH = _mm512_abs_ps(zdH); mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LE_OS); zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD)); zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR)); zavg = _mm512_mask_or_ps(zavgH, mskV, zavgV, zavgV); _mm512_storeu_ps(pDst + i, zavg); } //remainder skipped pDst = pDst + dstStep; } } There can be several such if in the implemented algorithm, for them it is possible to start new masks as long as the code is faster than the scalar.
In fact, the icc compiler is quite capable of vectorizing code 4.1. To do this, it suffices to add the restrict keyword to the pointers pSrc1 and pDst and the –Qrestrict key.
void avg_ref( float* restrict pSrc1, int src1Step, float* restrict pDst, int dstStep, int width, int height) Recall that the restrict modifier indicates to the compiler that access to the object is carried out only through this pointer, and thus the pSrc1 and pDst vectors do not overlap, which makes vectorization possible.
Measurements on the internal CPU simulator with avx512 support show that the performance is almost equal to the performance of our avx512 code. Ie the compiler also knows how to effectively use masks
It would seem that this is all. But let's see what happens if we slightly modify our function and add the dependency between iterations to it.
Sheet 4.3
void avg_ref( float* restrict pSrc1, int src1Step, float* restrict pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { int t = 1; for(i=0; i < width; i++ ) { float dv, dh; float valU = pSrc1[src1Step*(h - 1) + i ]; float valD = pSrc1[src1Step*(h + 1) + i ]; float valL = pSrc1[src1Step*( h ) + (i-1)]; float valR = pSrc1[src1Step*( h ) + (i+1)]; dv = ABS(valU - valD); dh = ABS(valL - valR); if(dv<dh){ pDst[i] = (valU + valD) * 0.5f; t = 1; } else if (dv>dh){ pDst[i] = (valL + valR) * 0.5f; t = 0; } else if (t == 1) { pDst[i] = (valU + valD) * 0.5f; } else { pDst[i] = (valL + valR) * 0.5f; } } pDst = pDst + dstStep; } } The function also performs interpolation on neighboring pixels, and if the difference in vertical and horizontal is the same, then the interpolation direction used in the previous iteration is used. On algorithms of this kind, the effect of the out of order mechanism implemented in modern cpu is reduced due to the fact that a long sequence of dependent operations is formed. The compiler also now can not vectorize the cycle and performance is 17 times slower. Those. just about the width of 16 float elements in the AVX512 register. Now let's try to somehow modify our avx512 code to get at least some kind of acceleration.
We introduce the following binary variable masks
mskV (n) - the difference is minimal for the nth element of V
mskE (n) - for the n-th element of V and H the differences are the same
mskD (n) - V interpolation is used for the nth element.
Now we will build a truth table, how mskD (n) is formed depending on mskV (n), mskE (n) and the previous mask used - mskD (n-1)
From the table it follows that
mskD (n) = mskV (n) | (mskE (n) & mskD (n-1)),
which in general was so obvious. So our avx512 code will look like this.
Sheet 4.4
void avg_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { __mmask16 mskD = 0xFFFF; i = 0; for(i=i; i < (width&(~15)); i+=16 ) { __m512 zvU, zvD, zvL, zvR; __m512 zdV, zdH; __m512 zavgV, zavgH, zavg; __mmask16 mskV, mskE; zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i ); zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i ); zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1)); zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1)); zdV = _mm512_sub_ps(zvU, zvD); zdH = _mm512_sub_ps(zvL, zvR); zdV = _mm512_abs_ps(zdV); zdH = _mm512_abs_ps(zdH); mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS); mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS); mskD = mskV | (mskE & (mskD >>15) & (1<<0)); // 0 bit mskD = mskD | (mskE & (mskD << 1) & (1<<1)); // 1 bit mskD = mskD | (mskE & (mskD << 1) & (1<<2)); // 2 bit mskD = mskD | (mskE & (mskD << 1) & (1<<3)); // 3 bit mskD = mskD | (mskE & (mskD << 1) & (1<<4)); // 4 bit mskD = mskD | (mskE & (mskD << 1) & (1<<5)); // 5 bit mskD = mskD | (mskE & (mskD << 1) & (1<<6)); // 6 bit mskD = mskD | (mskE & (mskD << 1) & (1<<7)); // 7 bit mskD = mskD | (mskE & (mskD << 1) & (1<<8)); // 8 bit mskD = mskD | (mskE & (mskD << 1) & (1<<9)); // 9 bit mskD = mskD | (mskE & (mskD << 1) & (1<<10)); // 10 bit mskD = mskD | (mskE & (mskD << 1) & (1<<11)); // 11 bit mskD = mskD | (mskE & (mskD << 1) & (1<<12)); // 12 bit mskD = mskD | (mskE & (mskD << 1) & (1<<13)); // 13 bit mskD = mskD | (mskE & (mskD << 1) & (1<<14)); // 14 bit mskD = mskD | (mskE & (mskD << 1) & (1 << 15)); // 15 bit zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD)); zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR)); zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV); _mm512_storeu_ps(pDst + i, zavg); } pDst = pDst + dstStep; } } In it all 16 bits of the mask are sequentially sorted. At 64x64, it works ~ 1.7X times faster than C-shny. Well, at least I managed to get something. The next possible optimization is that you can pre-calculate all the combinations of masks. At each iteration of 16 elements, we have 16 bits mskV, 16 bits mskE, and 1 bit from the previous iteration. Total 2 ^ 33 degrees of options for mskD. It's a lot. And what if we process not by 16, but by 8 elements per iteration? We get 2 ^ (8 + 8 + 1) = 128kbyte table. And this is quite sane size. Create an initialization function.
Sheet 4.5
unsigned char table[2*256 * 256]; extern init_table_mask() { int mskV, mskE, mskD=0; for (mskD = 0; mskD < 2; mskD++){ for (mskV = 0; mskV < 256; mskV++){ for (mskE = 0; mskE < 256; mskE++){ int msk; msk = mskV | (mskE & (mskD ) & (1 << 0)); // 0 bit msk = msk | (mskE & (msk << 1) & (1 << 1)); // 1 bit msk = msk | (mskE & (msk << 1) & (1 << 2)); // 2 bit msk = msk | (mskE & (msk << 1) & (1 << 3)); // 3 bit msk = msk | (mskE & (msk << 1) & (1 << 4)); // 4 bit msk = msk | (mskE & (msk << 1) & (1 << 5)); // 5 bit msk = msk | (mskE & (msk << 1) & (1 << 6)); // 6 bit msk = msk | (mskE & (msk << 1) & (1 << 7)); // 7 bit table[256*256*mskD+256 * mskE + mskV] = (unsigned char)msk; } } } } Rewrite the code.
Sheet 4.6
void avg_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { __mmask16 mskD = 0xFFFF; i = 0; mskD = 0x00FF; for(i=i; i < (width&(~7)); i+=8 ) { __m512 Z = _mm512_setzero_ps(); __m512 zvU, zvD, zvL, zvR; __m512 zdV, zdH; __m512 zavgV, zavgH, zavg; __mmask16 mskV, mskE; zvU = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*(h - 1) + i ); zvD = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*(h + 1) + i ); zvL = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*( h ) + (i-1)); zvR = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*( h ) + (i+1)); zdV = _mm512_sub_ps(zvU, zvD); zdH = _mm512_sub_ps(zvL, zvR); zdV = _mm512_abs_ps(zdV); zdH = _mm512_abs_ps(zdH); mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS)&0xFF; mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS)&0xFF; mskD = table[256 * 256 * (mskD >> 7) + 256 * mskE + mskV]; zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD)); zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR)); zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV); _mm512_mask_storeu_ps(pDst + i, 0xFF, zavg); } pDst = pDst + dstStep; } } The code began to work ~ 4.1X times faster. You can add processing for 16 elements, but the table will have to turn twice for the iteration.
Sheet 4.7
void avg_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height) { int h, i; for( h = 0; h < height; h++ ) { __mmask16 mskD = 0xFFFF; i = 0; for(i=i; i < (width&(~15)); i+=16 ) { __m512 zvU, zvD, zvL, zvR; __m512 zdV, zdH; __m512 zavgV, zavgH, zavg; __mmask16 mskV, mskE; ushort mskD_0_7=0, mskD_8_15=0; zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i ); zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i ); zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1)); zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1)); zdV = _mm512_sub_ps(zvU, zvD); zdH = _mm512_sub_ps(zvL, zvR); zdV = _mm512_abs_ps(zdV); zdH = _mm512_abs_ps(zdH); mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS); mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS); mskD_0_7 = table[256 * 256 * (((ushort)mskD) >> 15) + 256 * (((ushort)mskE) & 0xFF) + (((ushort)mskV) & 0xFF)]; mskD_8_15 = table[256 * 256 * (((ushort)mskD_0_7) >> 7) + 256 * (((ushort)mskE)>> 8 ) + (((ushort)mskV) >>8 )]; mskD = (mskD_8_15 << 8) | mskD_0_7; zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD)); zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR)); zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV); _mm512_storeu_ps(pDst + i, zavg); } pDst = pDst + dstStep; } } Now the acceleration is ~ 5.6X compared to the original C code, which is very good for the algorithm with feedback. Thus, the combination of a mask register and a pre-computed table allows for a significant performance increase. Code of this kind is not specifically selected for the article and is found for example in photo processing algorithms, when converting images from a RAW format. True, integer values are used there, but such a table method can also be applied to them.
Total
This article shows only some of the ways to apply the AVX 512's mask instructions. You can use them in your applications or invent your own tricks. Or you can use the IPP library, which already contains code optimized specifically for Intel processors with avx512 support, an important part of which is the instructions with mask registers.
Source: https://habr.com/ru/post/266055/
All Articles