Centrifuge + Go = Centrifugo - harder, better, faster, stronger

Last September, the last article on Centrifuge, an open source server for real-time messaging, was published . Now Go is on the list of hubs to which this post is published. And for good reason, as you can already understand from the title, the centrifuge was ported from Python to Go - this is how Centrifugo appeared. About the reasons for migration, about the pros and cons of Go, as well as how the project has evolved since the previous publication - read under the cut.
In the post (and, apparently, later in life) I will call the server in general Centrifuge, and if you want to emphasize the difference between implementations in different languages, I will use the English name - Centrifuge for the Python version, Centrifugo - for the Go version.
Very briefly about what a centrifuge is. This is the server that runs next to the backend of your application. Application users connect to Centrifuge using the Websocket protocol or the SockJS polyfill library. Having connected and authorized, they subscribe to the channels of interest to them. As soon as the application backend learns about a new event, it sends it to the desired channel in Centrifuge (using a queue in Redis or HTTP API), which, in turn, sends a message to all connected interested users.
')
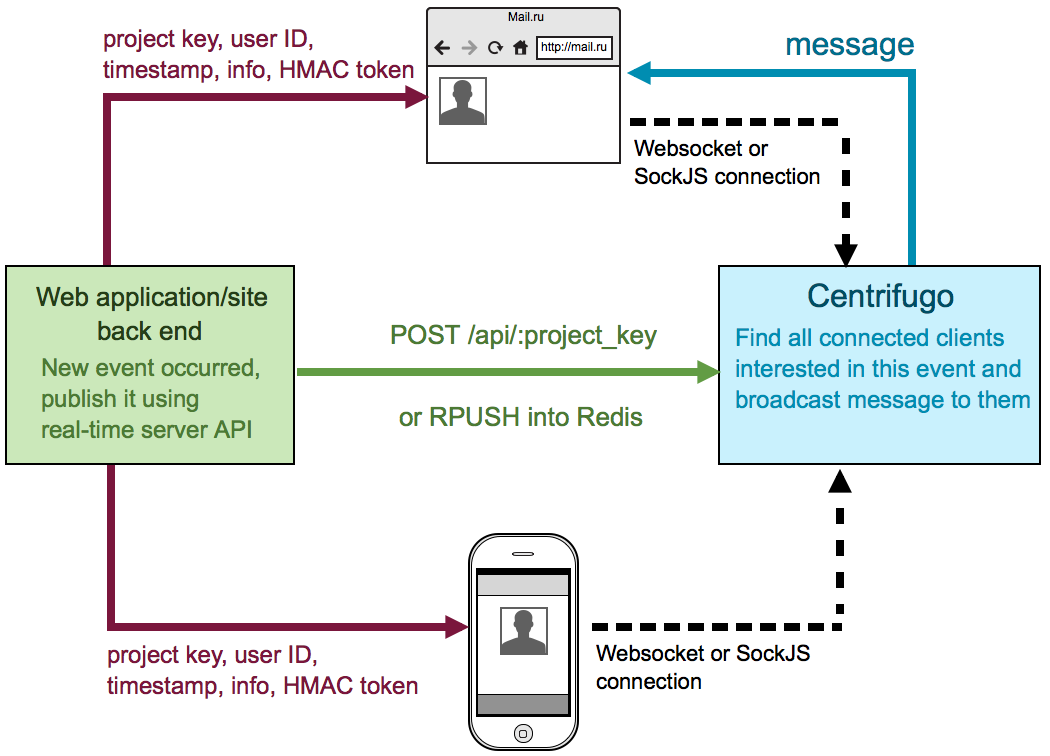
Thus, Centrifuge solves the problems of a number of modern common frameworks (such as Django, Ruby on Rails, Laravel, etc.), with which the backend of many web applications is written. When the backend is not able to work asynchronously, and the pool of workers that process requests is limited, then processing of persistent connections from clients instantly leads to the exhaustion of this pool. Of course, nothing prevents you from using Centrifuge and paired with your asynchronous backend, just to reduce the amount of work that needs to be done for development.
There are a lot of solutions like Centrifuge, and I mentioned some of them in previous articles. The main features are several things:
- independence of the language in which the application backend is written;
- using SockJS: allows all users whose browsers for one reason or another cannot establish a Websocket connection, receive new messages via fallback transport (eventsource, xhr-streaming, xhr-polling, etc.);
- user authorization based on the use of a signed token (HMAC SHA-256);
- the ability to run several processes associated with radishes;
- information about current users in the channel, history of messages in the channels, messages about subscription to the channel by the user or unsubscribing from the channel; Most PUB / SUB solutions can only send new messages;
- full deployment readiness: rpm, Dockerfile, Nginx config; and now releases in the form of a binary file for all platforms.
Previously, I focused on the fact that the main purpose of a centrifuge is instant messages in web applications. Perhaps the “web” prefix slightly hides the potential of the project: you can also connect to the Centrifuge from mobile applications using the Websocket-protocol. This has been confirmed by some users in the opensource community. But unfortunately, there are no clients for mobile devices, that is, in Java or Objective-C / Swift. Migrating to Go is another small step towards adapting a server for use from different environments. But first things first. So why go? There were several reasons for this.

Pros of migrating to Go
Performance
It's no secret that Go is much faster than CPython. And the centrifuge on Go has become much faster. I will give examples. The centrifuge allows you to send multiple commands in a single HTTP request to the API. I sent a request containing 1000 new messages to be posted to the channel. Let's look at the results.
Centrifuge: 2.0 , Centrifuge: 17.2 , 100 Centrifugo: 30 , (x15) Centrifugo: 350 , 100 (x49) Still, 1000 messages are a non-standard situation, here are the results of sending one new message to the channel, in which there are 1000 active clients:
Centrifuge: 3 , 0 Centrifuge: 160 1000 Centrifugo: 200 , 0 (x15) Centrifugo: 2.0 1000 (x80) The figures were obtained on Macbook Air 2011. It is also worth noting that client connections were artificially created from the same machine, and the completed answer does not mean that the messages have already arrived to customers. By the way, here is the code that was used to post messages:
from cent.core import generate_api_sign import requests import json command = { "method": "publish", "params": {"channel": "test", "data": {"json": True}} } n = 1000 url = "http://localhost:8000/api/development" commands = [] for i in range(n): commands.append(command) encoded_data = json.dumps(commands) sign = generate_api_sign("secret", "development", encoded_data) r = requests.post(url, data={"sign": sign, "data": encoded_data}) Of course, this performance increase is not observed in all components of the server, but absolutely everything has become faster. The Centrifuge repository also has a benchmark script that creates a large number of connections subscribed to one channel. After the subscription, a message is sent to the channel and the time is calculated until all customers receive the message. If we take the upper limit of such time for 200 ms, then the number of simultaneous connections that a server can normally serve with this distribution of channels / clients has increased by ~ 4 times (on my laptop from 4000 to 14000). Again, since all clients are created within the same script from the same machine, there is the possibility of this evaluation being biased.
Multicore
Go allows you to run a single process that will use multiple cores at the same time. In the case of Tornado, we had to start several Centrifuge processes and use Nginx as a balancer in front of them. It works, but Go makes it much easier to do this: write a program that takes care of how to utilize the available power of the machine. But there is no magic, the program code must be such that the Go runtime can distribute the work between the processor cores ( https://golang.org/doc/faq#Why_GOMAXPROCS ).
Spread
An application on Go is easier to distribute, since at the output Go allows you to get one statically linked executable file for a program. Downloaded, launched - works! Without any dependencies and dragging the Pythonic virtualenv on the combat machine. In Mail.Ru Group we, of course, don’t just copy files to battle, but create rpm for each of our applications. But creating rpm is also much more transparent, easier and faster. In addition to the above, Go allows cross-compiling code for different platforms - this is an amazing and convenient feature. All that is needed in most cases is to specify for which platform and architecture you need a binary file.
Built-in language concurrency-model
The default built-in language Go concurrency allows you to write non-blocking code using all available libraries and language tools, there is no need to search for non-blocking libraries, as is the case with Tornado. One of the headaches, for example, was an asynchronous client for Radish. About the official redis-py you can immediately forget. Of the more or less alive and adapted for Tornado there were two: tornado-redis and toredis . Initially, I planned to use tornado-redis, but it turned out that it was completely inappropriate for me because of the bug . As a result, toredis is used in the Python version. He is very good, but the path to it was thorny.
In Go, asynchronous work with network and system calls is the basis of the language. The runtime scheduler switches the context between the gorutines on blocking calls or after a certain maximum time allowed for the gorutina to work. In general, all this seems to work for Gevent, and Tornado to some extent, but to have it out of the box is a great happiness.
Static typing
Please note that in this paragraph I do not claim that static typing is better than dynamic typing. But! Due to static typing, it is much easier to make changes to the code. For me, it must be admitted, this was one of the most striking discoveries after Python - refactoring is greatly simplified. There is an additional assurance that if the code is compiled after making the changes, it will work correctly.
It seems to me that these points are enough to make sure that the migration is reasonable. There were other advantages found in the process. Go-code is easy to test, version 1.5 opens the way to creating a shared library for use from Java or Objective-C, built-in utilities allow you to track leaks of gorutin.

Migrations to Go
It was necessary, of course, to evaluate the disadvantages of such a migration. For example, what to do with the Python version: write a fully compatible Go version and replace the code in the repository or make it a separate project? It was tempting to substitute, after all the links on the Internet to the project and the name meant quite a lot. Common sense prompted what to do separately. As a result, now there are Centrifuge and Centrifugo. And I would not say that it is very good, it causes confusion.
The second point: it is much easier to find developers of users of an opensource-solution, if they themselves use the same programming language in which it is written this opensource-application. Still, whatever one may say, but the Python community is bigger than the Go community. I had to sacrifice it.
Further, the language for me is new, so there was a chance (and even still is) to step on the old rake again or find new ones. But has it ever stopped programmers? On the contrary!
There are downsides to the Go language itself. Let's go through the main ones that usually complain about:
- Lack of generics. Yes, they are not. As a result, I have 2 data structures in the repository, which theoretically, if Go support for generics, I could reuse in other projects (and maybe even take already prepared from another repository). This is an in-memory fifo queue and priority heap queue , able to work only with strings. Perhaps there would be generics - it would be better. But at the same time, I would not say that it confuses me very much. As I understand it, the authors of the Go language consider this question open. Perhaps in the future they will be able to find the right way to add generics to the language.
- Error processing. There are no exceptions in Go, and it is customary to explicitly return an error from functions / methods. In my opinion, this is a very subjective minus. For example, I like it. For some personal reasons, I did it in Tornado as well, as a result of doing coruntine instead of causing an exception. It's convenient for me! But if in Python it seems unnatural in relation to the practices of the language, then there simply cannot be done without it.
Migration
Python centrifuge is based on several main libraries: Tornado , Toredis , Sockjs-Tornado . Accordingly, it was necessary to find analogues in Go. Instead of Tornado, the language itself appears directly, Redigo is used to work with Redis, and a wonderful implementation of the SockJS server was found . In general, the decision to migrate from Python to Go was made, and rewriting the main code base took about 3 months of work in the evenings after work. It just so happened that the migration process coincided with my desire to get rid of the backend storage of project settings and namespaces. If you read the previous articles about the project, then you probably know: previously, these settings were stored for selection in a JSON file, SQLite, MongoDB or PostgreSQL with the ability to write and use your backend. SQLite was the default choice. This, perhaps, was a mistake. Settings change so rarely that keeping a database for them is, well, completely pointless. As a result, I reworked everything to use only the configuration file, getting rid of all sorts of backends.
The configuration file can now be created in JSON, YAML or TOML formats - thanks to the wonderful Go Viper library. In general, Viper is good not only for supporting several formats, its main task is to collect configuration options from different places with the correct priority:
- default values;
- values from the configuration file;
- from environment variables;
- from remote configuration sources (Etcd, Consul);
- from command line arguments;
- set explicitly in the process of the application itself.
Thus, the library allows very flexible configuration of the application.
Among the difficulties of migration that have arisen, I would note the following:
- Frequent use of interface {} and map [string] interface {}, which I applied here and there. Not immediately, but gradually, we managed to get rid of this, using strictly typed structures instead. By the way, it helped to bring the internal protocol of communication between the nodes and the protocol of communication with the client in order. It is clear what type will come or should be sent.
- Possible race conditions when accessing data from different gorutin. Most of them were found using the Go race-detector, which prints to the console all the observed cases of unprotected by any means of synchronizing access to data from various Gorutin. Channels are available from the synchronization tools in Go, as well as primitives from the sync and atomic packages.
Mr Klaus Post , who found several race conditions, pointed out some style flaws in the code, and also made some extremely useful pull requests.
There is another interesting opportunity Go, which has already opened in the course of rewriting. This is the support for creating a shared library in Go 1.5 version for working with a public library API from Java and Objective-C. Perhaps this is the road to creating clients for iOS and Android? During the migration process, the documentation was completely rewritten. She now embraces and binds together all projects related to Centrifugo. This is the server itself, a javascript client, HTTP API clients, a web interface. By the way, the web interface, previously written on Tornado and located directly in the repository along with the server code, is now separated and is a one-page application on ReactJS ( https://github.com/centrifugal/web ). Attention gif:

The Python version of the Centrifuge is currently almost completely compatible with the Go version. The differences are insignificant, but in the future the discrepancy will be stronger, I do not plan to add new features in Centrifuge, only fixes for found bugs.
For almost 2 months we have been using Centrifugo on the Mail.Ru Group intranet, and there have been no problems so far. We have a small load: 550 simultaneously connected users on average per day, about 50 active channels on average, and about 30 messages per minute. To launch and try Centrifugo, you can download a binary release for your system ( https://github.com/centrifugal/centrifugo/releases ), there is a spec for RPM and Docker image.
I am often asked two questions. First, why should I use a Centrifuge if I have Radishes? Second, how many users can a single centrifuge instance withstand? The first question is strange, and the answer to it: of course, you can not use a centrifuge, but then from scratch you have to realize a lot of things that are out of the box are available in the project. At first glance, this may seem simple, but the devil is in the details. And these little things decently, starting with the code of the browser client and ending with deployment. In Centrifuge, many problems of real use are already solved. It has already been successfully tested in battle. For example, it allowed us at Mail.Ru Group to conduct an interactive game for employees: about 50 participants came with their mobile devices - laptops, tablets and phones. Absolutely everyone was able to connect to the game and in real time received questions on the screens, the results of the round and game statistics. At the same time, the presenter saw who was really online, which helped to organize people at the beginning of the game. The answer to the second question: I do not know. I do not know, because you can connect tens of thousands of simultaneous connections, and everything will work fine. But at the same time, a lot of factors influence the overall performance and throughput: iron, number of connections, number of channels, number of messages in channels. The answer to this question can only give a sound assessment and monitoring.
Further goals are:
- Clients for use on Android and iOS - by and large hope here on opensource-community or on shared library on Go as I don’t know either Objective-C / Swift or Java.
- Metrics.
- Sharding? Redis Cluster? Tarantool?
And a few links in conclusion:
- demo instance with web interface to Heroku (password demo) centrifugo.herokuapp.com
- repository with examples github.com/centrifugal/examples
- documentation fzambia.gitbooks.io/centrifugal/content
PS Pictures from the gophers in the article from the repository on Github: github.com/hackraft/gophericons
PSS I would also like to thank habrap merchants and sl4mmer , which made a significant contribution to the development of the project.
Source: https://habr.com/ru/post/266017/
All Articles