Apache Spark or the return of the prodigal user
We continue the series of articles about DMP and the technological stack of Targetix .
This time it will be a question of using Apache Spark in our practice and a tool that allows you to create remarketing audiences.
It is thanks to this tool, once you see a jigsaw, you will see it in all corners of the Internet until the end of your life.
This is where we stuffed the first bumps in Apache Spark.
')
Architecture and Spark-code under the cut.

For understanding of the purposes we will explain terminology and the initial data.
What is remarketing? You will find the answer to this question on the wiki ), and in short, remarketing (also known as retargeting) is an advertising mechanism that allows you to return the user to the advertiser's site to perform a targeted action.
To do this, we need data from the advertiser himself, the so-called first party data , which we collect automatically from sites that set up our code - SmartPixel . This is information about the user agent, the pages visited and the actions taken. We then process this data using Apache Spark and get audiences to show ads.
It was originally planned to write on pure Hadoop using MapReduce tasks and we even succeeded. However, writing this type of application required a large amount of code, which is very difficult to understand and debug.
For an example of three different approaches, we present the audience_id grouping code by visitor_id.
Then Pig caught sight of us. A language based on Pig Latin, which interpreted the code in the MapReduce task. Now it took much less code to write, and from an aesthetic point of view it was much better.
That was just a problem with saving. I had to write my own modules to save, because most database developers did not support Pig.
Here Spark came to the rescue.
Here, both brevity and convenience, as well as the presence of many OutputFormat , which make it easier to write to the database. In addition, in this tool we were interested in the possibility of stream processing.
The process as a whole is as follows:
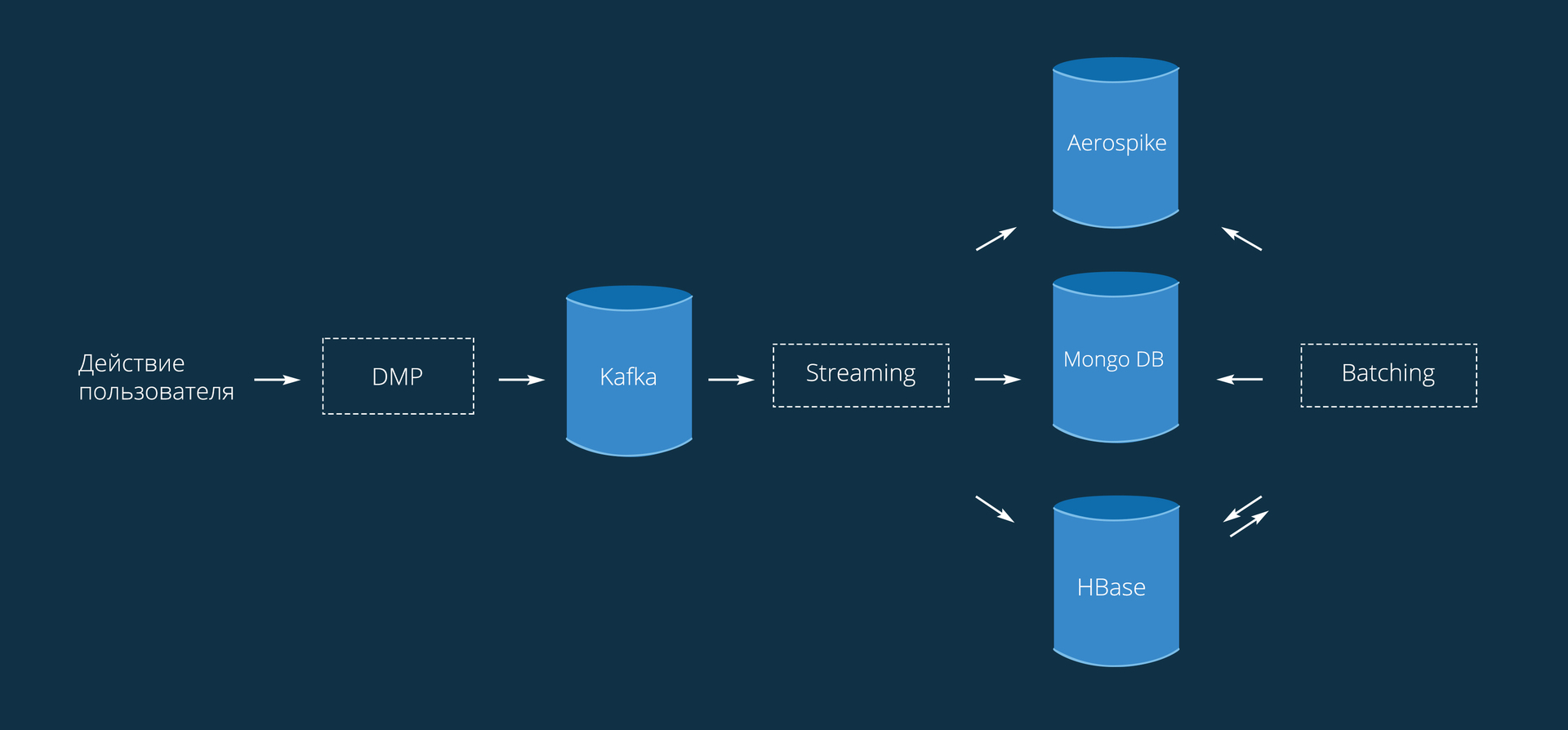
The data comes to us with SmartPixel'e, installed on the sites. We will not give the code, it is very simple and similar to any external metric. From here, data comes in the form of {Visitor_Id: Action} . Here Action can be understood as any target action: viewing a page / product, adding to the cart, buying, or any custom action set by the advertiser.
Remarketing processing consists of 2 main modules:
Allows you to add users to the audience in real time. We use Spark Streaming with a processing interval of 10 seconds. The user is added to the audience almost immediately after the committed action (within those 10 seconds). It is important to note that in streaming mode, data can be lost in small quantities due to pinging to databases or for any other reason.
The main thing is the balance between response time and throughput. The less batchInterval , the faster the data will be processed, but a lot of time will be spent on connection initialization and other overhead costs, so not so much can be processed at once. On the other hand, a large interval allows you to process more data at a time, but then more precious time is spent from the moment of the action to the addition to the right audience.
Once a day, it rebuilds all audiences, which solves the problems of obsolete and lost data. Remarketing has one unpleasant feature for the user - advertising hype. Here comes the lookback window . For each user, the date of his addition to the audience is stored, so we can control the relevance of information to the user.
It takes 1.5-2 hours - it all depends on the load on the network. And most of the time it is saving across databases: loading, processing and recording in Aerospike 75 minutes (performed in one pipeline), the rest of the time is saving in HBase and Mongo (35 minutes).
Saving from Kafka to HBase was originally sewn into a streaming service, but due to possible failures and failures, it was decided to put it into a separate application. To implement fault tolerance, Kafka Reliable Receiver was used , which allows not to lose data. Uses Checkpoint to save meta information and current data.
The number of entries in HBase is currently about 400 million. All events are stored in the database for 180 days and are deleted by TTL.
Saving to Aerospike takes place using a self-written OutputFormat and a Lua script. To use an asynchronous client, I had to add two classes to the official connector ( fork ).
As an example, the function of adding new values to the list is presented.
This script adds new entries in the audience list like “audience_id, timestamp”. If the entry exists, then the timestamp remains the same.
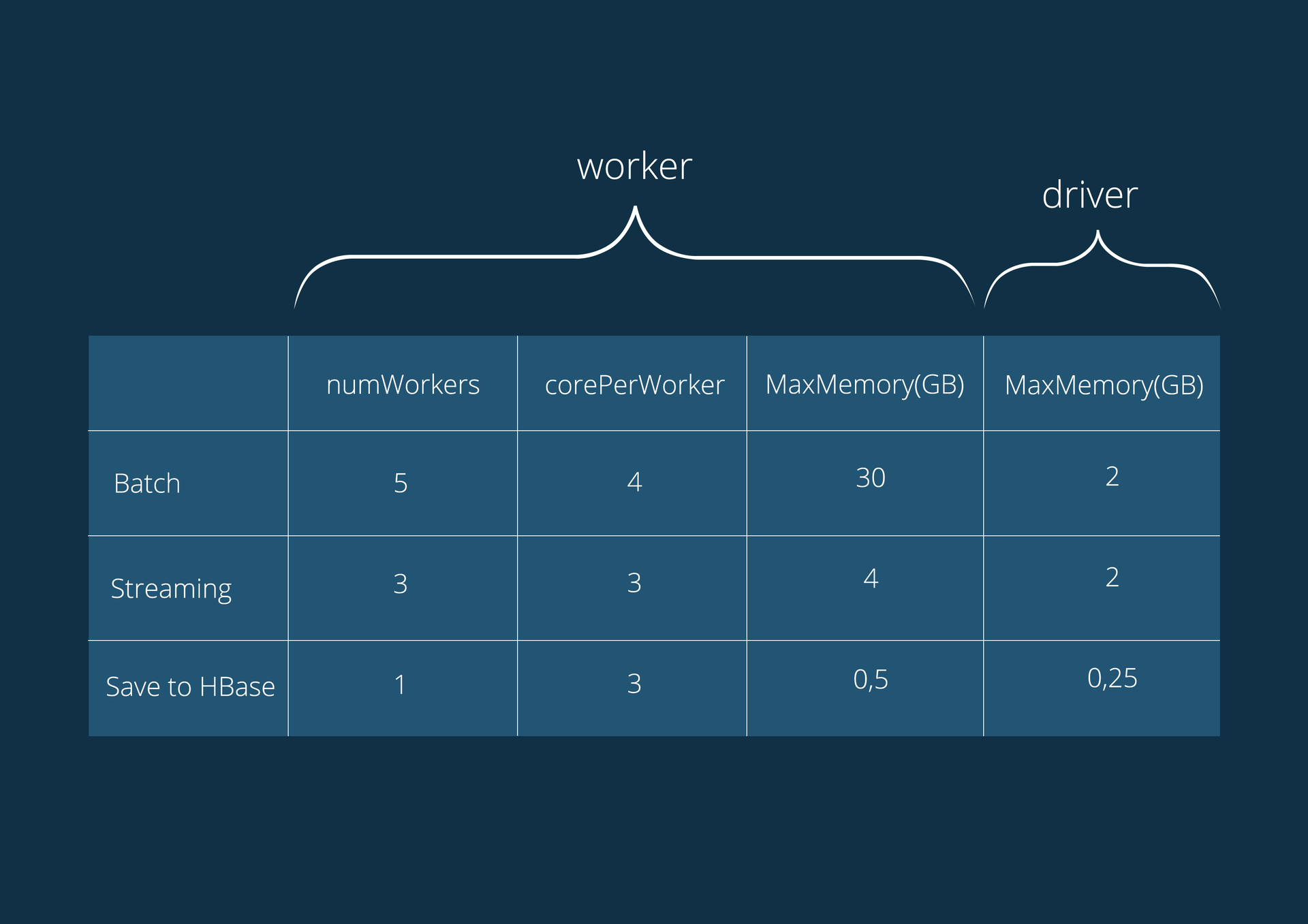
Characteristics of servers running applications:
Intel Xeon E5-1650 6-core 3.50 GHz (HT), 64GB DDR3 1600;
CentOS 6 operating system;
CDH version 5.4.0.
Application Configuration:
On the way to this implementation, we tried several options (C #, Hadoop MapReduce and Spark) and got a tool that performs equally well with the tasks of stream processing and recalculation of huge data arrays. Due to the partial introduction of lambda architecture, the reuse of the code has increased. The time for complete restructuring of the classroom channels has decreased from ten hours to ten minutes. And horizontal scalability has never been easier.
You can always try our technologies on our Hybrid platform.
Special thanks are expressed to DanilaPerepechin for their invaluable assistance in writing the article.
This time it will be a question of using Apache Spark in our practice and a tool that allows you to create remarketing audiences.
It is thanks to this tool, once you see a jigsaw, you will see it in all corners of the Internet until the end of your life.
This is where we stuffed the first bumps in Apache Spark.
')
Architecture and Spark-code under the cut.
Introduction
For understanding of the purposes we will explain terminology and the initial data.
What is remarketing? You will find the answer to this question on the wiki ), and in short, remarketing (also known as retargeting) is an advertising mechanism that allows you to return the user to the advertiser's site to perform a targeted action.
To do this, we need data from the advertiser himself, the so-called first party data , which we collect automatically from sites that set up our code - SmartPixel . This is information about the user agent, the pages visited and the actions taken. We then process this data using Apache Spark and get audiences to show ads.
Decision
A bit of history
It was originally planned to write on pure Hadoop using MapReduce tasks and we even succeeded. However, writing this type of application required a large amount of code, which is very difficult to understand and debug.
For an example of three different approaches, we present the audience_id grouping code by visitor_id.
Sample MapReduce code:
public static class Map extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String s = value.toString(); String[] split = s.split(" "); context.write(new Text(split[0]), new Text(split[1])); } } public static class Reduce extends Reducer<Text, Text, Text, ArrayWritable> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { HashSet<Text> set = new HashSet<>(); values.forEach(t -> set.add(t)); ArrayWritable array = new ArrayWritable(Text.class); array.set(set.toArray(new Text[set.size()])); context.write(key, array); } } public static class Run { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(); job.setJarByClass(Run.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(ArrayWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } Then Pig caught sight of us. A language based on Pig Latin, which interpreted the code in the MapReduce task. Now it took much less code to write, and from an aesthetic point of view it was much better.
Pig code example:
A = LOAD '/data/input' USING PigStorage(' ') AS (visitor_id:chararray, audience_id:chararray); B = DISTINCT A; C = GROUP B BY visitor_id; D = FOREACH C GENERATE group AS visitor_id, B.audience_id AS audience_id; STORE D INTO '/data/output' USING PigStorage(); That was just a problem with saving. I had to write my own modules to save, because most database developers did not support Pig.
Here Spark came to the rescue.
Spark code example:
SparkConf sparkConf = new SparkConf().setAppName("Test"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); jsc.textFile(args[0]) .mapToPair(str -> { String[] split = str.split(" "); return new Tuple2<>(split[0], split[1]); }) .distinct() .groupByKey() .saveAsTextFile(args[1]); Here, both brevity and convenience, as well as the presence of many OutputFormat , which make it easier to write to the database. In addition, in this tool we were interested in the possibility of stream processing.
Current implementation
The process as a whole is as follows:
The data comes to us with SmartPixel'e, installed on the sites. We will not give the code, it is very simple and similar to any external metric. From here, data comes in the form of {Visitor_Id: Action} . Here Action can be understood as any target action: viewing a page / product, adding to the cart, buying, or any custom action set by the advertiser.
Remarketing processing consists of 2 main modules:
- Stream processing.
- Batch processing ( batching ).
Stream processing
Allows you to add users to the audience in real time. We use Spark Streaming with a processing interval of 10 seconds. The user is added to the audience almost immediately after the committed action (within those 10 seconds). It is important to note that in streaming mode, data can be lost in small quantities due to pinging to databases or for any other reason.
The main thing is the balance between response time and throughput. The less batchInterval , the faster the data will be processed, but a lot of time will be spent on connection initialization and other overhead costs, so not so much can be processed at once. On the other hand, a large interval allows you to process more data at a time, but then more precious time is spent from the moment of the action to the addition to the right audience.
Selection of events from Kafka:
To create a message flow, you need to pass the context, the necessary topics and the name of the group of recipients (jssc, topics and groupId, respectively). For each group its own message queue shift is formed for each topic. You can also create multiple recipients for load balancing between servers. All transformations on the data are specified in the transformFunction and are performed in the same stream as the recipients.
public class StreamUtil { private static final Function<JavaPairRDD<String, byte[]>, JavaRDD<Event>> eventTransformFunction = rdd -> rdd.map(t -> Event.parseFromMsgPack(t._2())).filter(e -> e != null); public static JavaPairReceiverInputDStream<String, byte[]> createStream(JavaStreamingContext jsc, String groupId, Map<String, Integer> topics) { HashMap prop = new HashMap() {{ put("zookeeper.connect", BaseUtil.KAFKA_ZK_QUORUM); put("group.id", groupId); }}; return KafkaUtils.createStream(jsc, String.class, byte[].class, StringDecoder.class, DefaultDecoder.class, prop, topics, StorageLevel.MEMORY_ONLY_SER()); } public static JavaDStream<Event> getEventsStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map, int count) { return getStream(jssc, groupName, map, count, eventTransformFunction); } public static <T> JavaDStream<T> getStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map, Function<JavaPairRDD<String, byte[]>, JavaRDD<T>> transformFunction) { return createStream(jssc, groupName, map).transform(transformFunction); } public static <T> JavaDStream<T> getStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map, int count, Function<JavaPairRDD<String, byte[]>, JavaRDD<T>> transformFunction) { if (count < 2) return getStream(jssc, groupName, map, transformFunction); ArrayList<JavaDStream<T>> list = new ArrayList<>(); for (int i = 0; i < count; i++) { list.add(getStream(jssc, groupName, map, transformFunction)); } return jssc.union(list.get(0), list.subList(1, count)); } } To create a message flow, you need to pass the context, the necessary topics and the name of the group of recipients (jssc, topics and groupId, respectively). For each group its own message queue shift is formed for each topic. You can also create multiple recipients for load balancing between servers. All transformations on the data are specified in the transformFunction and are performed in the same stream as the recipients.
Event handling:
Creating context
Here, to join two (events and conditions) RDD (Resilient Distributed Dataset), use join by pixel_id. The save method is fake. This is done in order to unload the submitted code. In its place should be several transformations and saves.
Launch
First, the context is created and launched. Parallel to this, 2 timers are started to update the conditions and save the HyperLogLog. It is mandatory that awaitTermination () is specified at the end, otherwise the processing will end without starting.
public JavaPairRDD<String, Condition> conditions; private JavaStreamingContext jssc; private Map<Object, HyperLogLog> hlls; public JavaStreamingContext create() { sparkConf.setAppName("UniversalStreamingBuilder"); sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); sparkConf.set("spark.storage.memoryFraction", "0.125"); jssc = new JavaStreamingContext(sparkConf, batchInterval); HashMap map = new HashMap(); map.put(topicName, 1); // Kafka topic name and number partitions JavaDStream<Event> events = StreamUtil.getEventsStream(jssc, groupName, map, numReceivers).repartition(numWorkCores); updateConditions(); events.foreachRDD(ev -> { // Compute audiences JavaPairRDD<String, Object> rawva = conditions.join(ev.keyBy(t -> t.pixelId)) .mapToPair(t -> t._2()) .filter(t -> EventActionUtil.checkEvent(t._2(), t._1().condition)) .mapToPair(t -> new Tuple2<>(t._2().visitorId, t._1().id)) .distinct() .persist(StorageLevel.MEMORY_ONLY_SER()) .setName("RawVisitorAudience"); // Update HyperLogLog`s rawva.mapToPair(t -> t.swap()).groupByKey() .mapToPair(t -> { HyperLogLog hll = new HyperLogLog(); t._2().forEach(v -> hll.offer(v)); return new Tuple2<>(t._1(), hll); }).collectAsMap().forEach((k, v) -> hlls.merge(k, v, (h1, h2) -> HyperLogLog.merge(h1, h2))); // Save to Aerospike and HBase save(rawva); return null; }); return jssc; } Here, to join two (events and conditions) RDD (Resilient Distributed Dataset), use join by pixel_id. The save method is fake. This is done in order to unload the submitted code. In its place should be several transformations and saves.
Launch
public void run() { create(); jssc.start(); long millis = TimeUnit.MINUTES.toMillis(CONDITION_UPDATE_PERIOD_MINUTES); new Timer(true).schedule(new TimerTask() { @Override public void run() { updateConditions(); } }, millis, millis); new Timer(false).scheduleAtFixedRate(new TimerTask() { @Override public void run() { flushHlls(); } }, new Date(saveHllsStartTime), TimeUnit.MINUTES.toMillis(HLLS_UPDATE_PERIOD_MINUTES)); jssc.awaitTermination(); } First, the context is created and launched. Parallel to this, 2 timers are started to update the conditions and save the HyperLogLog. It is mandatory that awaitTermination () is specified at the end, otherwise the processing will end without starting.
Batch processing
Once a day, it rebuilds all audiences, which solves the problems of obsolete and lost data. Remarketing has one unpleasant feature for the user - advertising hype. Here comes the lookback window . For each user, the date of his addition to the audience is stored, so we can control the relevance of information to the user.
It takes 1.5-2 hours - it all depends on the load on the network. And most of the time it is saving across databases: loading, processing and recording in Aerospike 75 minutes (performed in one pipeline), the rest of the time is saving in HBase and Mongo (35 minutes).
Batch processing code:
Here is almost the same as in stream processing, but join is not used. Instead, it uses event check against the condition list with the same pixel_id. As it turned out, this design requires less memory and runs faster.
JavaRDD<Tuple3<Object, String, Long>> av = HbaseUtil.getEventsHbaseScanRdd(jsc, hbaseConf, new Scan()) .mapPartitions(it -> { ArrayList<Tuple3<Object, String, Long>> list = new ArrayList<>(); it.forEachRemaining(e -> { String pixelId = e.pixelId; String vid = e.visitorId; long dt = e.date.getTime(); List<Condition> cond = conditions.get(pixelId); if (cond != null) { cond.stream() .filter(condition -> e.date.getTime() > beginTime - TimeUnit.DAYS.toMillis(condition.daysInterval) && EventActionUtil.checkEvent(e, condition.condition)) .forEach(condition -> list.add(new Tuple3<>(condition.id, vid, dt))); } }); return list; }).persist(StorageLevel.DISK_ONLY()).setName("RawVisitorAudience"); Here is almost the same as in stream processing, but join is not used. Instead, it uses event check against the condition list with the same pixel_id. As it turned out, this design requires less memory and runs faster.
Save to base
Saving from Kafka to HBase was originally sewn into a streaming service, but due to possible failures and failures, it was decided to put it into a separate application. To implement fault tolerance, Kafka Reliable Receiver was used , which allows not to lose data. Uses Checkpoint to save meta information and current data.
The number of entries in HBase is currently about 400 million. All events are stored in the database for 180 days and are deleted by TTL.
Using Reliable Receiver:
First you need to implement the create () method of the JavaStreamingContextFactory interface and add the following lines when creating the context
Now instead of
use
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true"); jssc.checkpoint(checkpointDir); Now instead of
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, batchInterval); use
JavaStreamingContext jssc = JavaStreamingContext.getOrCreate(checkpointDir, new ()); Saving to Aerospike takes place using a self-written OutputFormat and a Lua script. To use an asynchronous client, I had to add two classes to the official connector ( fork ).
Running a Lua script:
Asynchronously executes a function from the specified package.
public class UpdateListOutputFormat extends com.aerospike.hadoop.mapreduce.AerospikeOutputFormat<String, Bin> { private static final Log LOG = LogFactory.getLog(UpdateListOutputFormat.class); public static class LuaUdfRecordWriter extends AsyncRecordWriter<String, Bin> { public LuaUdfRecordWriter(Configuration cfg, Progressable progressable) { super(cfg, progressable); } @Override public void writeAerospike(String key, Bin bin, AsyncClient client, WritePolicy policy, String ns, String sn) throws IOException { try { policy.sendKey = true; Key k = new Key(ns, sn, key); Value name = Value.get(bin.name); Value value = bin.value; Value[] args = new Value[]{name, value, Value.get(System.currentTimeMillis() / 1000)}; String packName = AeroUtil.getPackage(cfg); String funcName = AeroUtil.getFunction(cfg); // Execute lua script client.execute(policy, null, k, packName, funcName, args); } catch (Exception e) { LOG.error("Wrong put operation: \n" + e); } } } @Override public RecordWriter<String, Bin> getAerospikeRecordWriter(Configuration entries, Progressable progressable) { return new LuaUdfRecordWriter(entries, progressable); } } Asynchronously executes a function from the specified package.
As an example, the function of adding new values to the list is presented.
Lua script:
local split = function(str) local tbl = list() local start, fin = string.find(str, ",[^,]+$") list.append(tbl, string.sub(str, 1, start - 1)) list.append(tbl, string.sub(str, start + 1, fin)) return tbl end local save_record = function(rec, name, mp) local res = list() for k,v in map.pairs(mp) do list.append(res, k..","..v) end rec[name] = res if aerospike:exists(rec) then return aerospike:update(rec) else return aerospike:create(rec) end end function put_in_list_first_ts(rec, name, value, timestamp) local lst = rec[name] local mp = map() if value ~= nil then if list.size(value) > 0 then for i in list.iterator(value) do mp[i] = timestamp end end end if lst ~= nil then if list.size(lst) > 0 then for i in list.iterator(lst) do local sp = split(i) mp[sp[1]] = sp[2] end end end return save_record(rec, name, mp) end This script adds new entries in the audience list like “audience_id, timestamp”. If the entry exists, then the timestamp remains the same.
Characteristics of servers running applications:
Intel Xeon E5-1650 6-core 3.50 GHz (HT), 64GB DDR3 1600;
CentOS 6 operating system;
CDH version 5.4.0.
Application Configuration:
In custody
On the way to this implementation, we tried several options (C #, Hadoop MapReduce and Spark) and got a tool that performs equally well with the tasks of stream processing and recalculation of huge data arrays. Due to the partial introduction of lambda architecture, the reuse of the code has increased. The time for complete restructuring of the classroom channels has decreased from ten hours to ten minutes. And horizontal scalability has never been easier.
You can always try our technologies on our Hybrid platform.
PS
Special thanks are expressed to DanilaPerepechin for their invaluable assistance in writing the article.
Source: https://habr.com/ru/post/266009/
All Articles