The evolution of the cloud log collection and the log collector in open source
 Hello, my name is Yuri Nasretdinov, I work as a senior engineer in Badoo. Over the past year and a half, I have made several reports on how our cloud works. Slides and videos can be viewed here and here .
Hello, my name is Yuri Nasretdinov, I work as a senior engineer in Badoo. Over the past year and a half, I have made several reports on how our cloud works. Slides and videos can be viewed here and here .Today it is time to talk about another part of this system - about the log collector, which we, along with this article, post to open-source. The main part of the logic of our cloud is written in the Go language, and this subsystem is no exception.
System source codes: github.com/badoo/thunder
In this article, I will tell you about how we deliver application logs in our cloud, which we call simply a “scripting framework”.
Application logs
Our applications running in the cloud are classes in PHP, which in the simplest implementation have a run () method and receive input data for tasks, for example, a number from 1 to N, where N is the maximum number of instances for this class. Each task has its own unique id, and the ultimate goal is to deliver logs to some centralized repository, where you can easily find the logs of both a specific launch and all class logs at once.
<?php class ExampleScript extends ScriptSimple { public function run() { $this->getLogger()->info("Hello, world!"); return true; } } First implementation: by file on launch id
Since each task launch in the cloud is the launch of a separate PHP process, the easiest and most obvious way for us to collect the logs of each launch separately was to redirect the output of each process to separate files like <id>. <Out | err> .log, where out and err are used for standard output and error channels, respectively.
')
Thus, the task of the log collector was to regularly poll the directory with logs for changes and send new lines that appeared in the files. We used scribe as a means of delivering the logs to the central server, and the last offset sent was memorized directly in the file name (this works if you continue to write the log in the open file descriptor). The offset is the file size at the time of sending - the size will grow as new logs are written to the file, and we need to deliver new lines starting from the last delivered position in the file:
<?php // while (true) { foreach (glob("*.log") as $filename) { $filesize = filesize($filename); // 200 $read_offset = parseOffset($filename); // "id.out.log.100" -> 100 if ($filesize > $read_offset) { sendToScribe($filename, $read_offset); // scribe $read_offset rename($filename, replaceOffset($filename, $filesize); // "id.out.log.100" -> "id.out.log.200" } else if (finishedExecution($filename)) { unlink($filename); } } sleep(1); } This approach works fine as long as you have a small number of files in a directory, each of which is more or less actively written. Redirecting to separate files makes it easy to distinguish the output of each launch separately, even if the application does a simple echo instead of using the logger, which adds a launch ID to the beginning of the line. Compared to writing to the same file, in this case it is impossible to mix output from different application instances. It is also easy to understand that no one else writes to the file: if the process with the given id is already completed, then we can delete the corresponding file with the log when it is completely delivered to the scribe.
However, this scheme has many drawbacks. Here are the main ones:
- the file name does not contain information about the name of the class - this information must be requested from the cloud database;
- In scribe, you can easily “shove” a lot more data than the receiving server can manage. In such a situation, the scribe starts to buffer data locally into the file system, duplicating those logs that already exist on the disk;
- if the log collector doesn’t have time to delete the old files, they can accumulate a lot. We have several times accumulated a million files on the host, and to deliver the necessary logs by the time they were still relevant, there was no longer any possibility;
- the ext3 file system (and ext4 to a lesser extent) doesn't behave very well when you constantly create, rename and delete many files - we regularly saw our processes "stuck" for hundreds of milliseconds in the D-state when writing to files and creating them ;
- if you want to get rid of the constant polling of the stat () files and start using inotify, you will also have a nasty surprise. Due to the implementation features, especially well visible on multi-core systems with a large amount of free memory, when you call inotify_add_watch () in a directory in which files are regularly created and deleted, all processes that are written to files in this directory can be stuck, and it can last for tens of seconds.
If you are interested in the details about the reasons for the “bad” behavior of inotify in the conditions described in paragraph (5), read the spoiler below.
Reasons for very slow inotify_add_watch ()
As described in paragraph (5), we had a directory with logs. In this directory, a large number of files were constantly created, deleted and renamed. It is important that the files contained unique names, as they contained the startup id and read offsets.
It is easy enough to reproduce the problem even on a single-core system with a small amount of memory, albeit on a smaller scale. Those figures that are given in the article, obtained on a multi-core machine with dozens of gigabytes of memory.
Create an empty directory, let's call it, for example, tmp. After that, run a simple script:
All that this script does is execute stat () or access () 10 million times on non-existent files of the form fileN, where N is a number from 0 to 9,999,999.
Now we will execute the inotify_add_watch system call (we will start following the changes in the directory with the help of inotify):
The -TT flag for strace causes the system call to be printed at the end of the line in seconds. We received time in hundreds of milliseconds for a system call, which adds one empty directory to the list for notifications about new events. Within the framework of such a simple experiment, it is difficult to obtain tens of seconds that we observe on the production-system, but the problem is still there. Let's create a new empty tmp2 directory and check that everything works out for it instantly:
You can see that for the newly created empty directory nothing like this is observed: the system call runs almost instantly.
To find out why we have problems with a directory in which stat () was executed from non-existing files many times, let's modify the source program a little so that it does not exit, and see the result of the perf top command for this process:
You can see that almost 100% of the time passes in one call inside the kernel - __fsnotify_update_child_dentry_flags. Observations were made on the Linux kernel version 3.16, for other versions there may be slightly different results. The source of this function can be viewed at the following address: git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/fs/notify/fsnotify.c?id=v3.16 .
By adding printk debugs or looking at the results of perf you can see quite closely that the problem occurs in the following location:
In order to start following the changes in the files in the specified directory, the kernel is traversed through the structure of the dentry, which, roughly speaking, contains a cache of the form “filename” => inode data. This cache is filled even in the case when the requested file does not exist! In this case, the d_inode field will be zero, which is checked in the condition. Thus, when inotify_add_watch is called, the kernel is traversed in its own (in our case, huge) dentry cache for the specified directory and skips all the elements, since the directory is actually empty. Depending on the size of this cache and on the “concurrency for locks”, the system call can take a very long time, blocking the possibility of working with this directory and the files contained within.
Unfortunately, the problem is not easily solved and is an architectural problem of the VFS layer and the dentry subsystem. One of the obvious and simple solutions is to impose restrictions on the maximum cache size for non-existing entries, but this requires a serious rework of the VFS architecture and rewriting a large number of functions that rely on current behavior. The presence of counters for the cache of non-existent files will also certainly worsen the performance of the VFS subsystem as a whole. When we figured out the causes of this problem, we decided not to try to fix it, but to work around it: we no longer create files with unique names in the directories that we monitor with inotify, and thus do not kill the dentry cache. This method completely solves our problem and does not create significant inconvenience.
It is easy enough to reproduce the problem even on a single-core system with a small amount of memory, albeit on a smaller scale. Those figures that are given in the article, obtained on a multi-core machine with dozens of gigabytes of memory.
Create an empty directory, let's call it, for example, tmp. After that, run a simple script:
$ mkdir tmp $ cat flood.php <?php for ($i = 0; $i < $argv[1]; $i++) { file_exists("tmp/file$i"); } $ php flood.php 10000000 All that this script does is execute stat () or access () 10 million times on non-existent files of the form fileN, where N is a number from 0 to 9,999,999.
Now we will execute the inotify_add_watch system call (we will start following the changes in the directory with the help of inotify):
$ cat inotify_test.c #include <sys/inotify.h> void main(int argc, char *argv[]) { inotify_add_watch(inotify_init(), argv[1], IN_ALL_EVENTS); } $ gcc -o inotify_test inotify_test.c $ strace -TT -e inotify_add_watch ./inotify_test tmp inotify_add_watch(3, "tmp", …) = 1 <0.364838> The -TT flag for strace causes the system call to be printed at the end of the line in seconds. We received time in hundreds of milliseconds for a system call, which adds one empty directory to the list for notifications about new events. Within the framework of such a simple experiment, it is difficult to obtain tens of seconds that we observe on the production-system, but the problem is still there. Let's create a new empty tmp2 directory and check that everything works out for it instantly:
$ mkdir tmp2 $ strace -TT -e inotify_add_watch ./inotify_test tmp2 inotify_add_watch(3, "tmp2", …) = 1 <0.000014> You can see that for the newly created empty directory nothing like this is observed: the system call runs almost instantly.
To find out why we have problems with a directory in which stat () was executed from non-existing files many times, let's modify the source program a little so that it does not exit, and see the result of the perf top command for this process:
$ cat inotify_stress_test.c #include <sys/inotify.h> void main(int argc, char *argv[]) { int ifd = inotify_init(); int wd; for (;;) { wd = inotify_add_watch(ifd, argv[1], IN_ALL_EVENTS); inotify_rm_watch(ifd, wd); } } $ gcc -o inotify_stress_test inotify_stress_test.c $ strace -TT -e inotify_add_watch,inotify_rm_watch ./inotify_stress_test tmp inotify_add_watch(3, "tmp", …) = 1 <0.490447> inotify_rm_watch(3, 1) = 0 <0.000204> inotify_add_watch(3, "tmp", …) = 2 <0.547774> inotify_rm_watch(3, 2) = 0 <0.000015> inotify_add_watch(3, "tmp", …) = 3 <0.466199> inotify_rm_watch(3, 3) = 0 <0.000016> … $ sudo perf top -p <pid> 99.71% [kernel] [k] __fsnotify_update_child_dentry_flags … You can see that almost 100% of the time passes in one call inside the kernel - __fsnotify_update_child_dentry_flags. Observations were made on the Linux kernel version 3.16, for other versions there may be slightly different results. The source of this function can be viewed at the following address: git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/fs/notify/fsnotify.c?id=v3.16 .
By adding printk debugs or looking at the results of perf you can see quite closely that the problem occurs in the following location:
/* run all of the children of the original inode and fix their * d_flags to indicate parental interest (their parent is the * original inode) */ spin_lock(&alias->d_lock); list_for_each_entry(child, &alias->d_subdirs, d_u.d_child) { if (!child->d_inode) continue; In order to start following the changes in the files in the specified directory, the kernel is traversed through the structure of the dentry, which, roughly speaking, contains a cache of the form “filename” => inode data. This cache is filled even in the case when the requested file does not exist! In this case, the d_inode field will be zero, which is checked in the condition. Thus, when inotify_add_watch is called, the kernel is traversed in its own (in our case, huge) dentry cache for the specified directory and skips all the elements, since the directory is actually empty. Depending on the size of this cache and on the “concurrency for locks”, the system call can take a very long time, blocking the possibility of working with this directory and the files contained within.
Unfortunately, the problem is not easily solved and is an architectural problem of the VFS layer and the dentry subsystem. One of the obvious and simple solutions is to impose restrictions on the maximum cache size for non-existing entries, but this requires a serious rework of the VFS architecture and rewriting a large number of functions that rely on current behavior. The presence of counters for the cache of non-existent files will also certainly worsen the performance of the VFS subsystem as a whole. When we figured out the causes of this problem, we decided not to try to fix it, but to work around it: we no longer create files with unique names in the directories that we monitor with inotify, and thus do not kill the dentry cache. This method completely solves our problem and does not create significant inconvenience.
The problem with the need to make requests to the cloud database could be solved by adding the class name to the file, but with the rest it’s not so rosy. To keep the ability to separate the output from different instances of the same application, without forcing users to use our logger, you could redirect the output of applications not to files, but to unix pipes, but this creates a new problem - if you need to update proxy code (which runs PHP classes), the work of current tasks may be interrupted when you attempt to write to a “broken pipe” (broken pipe).
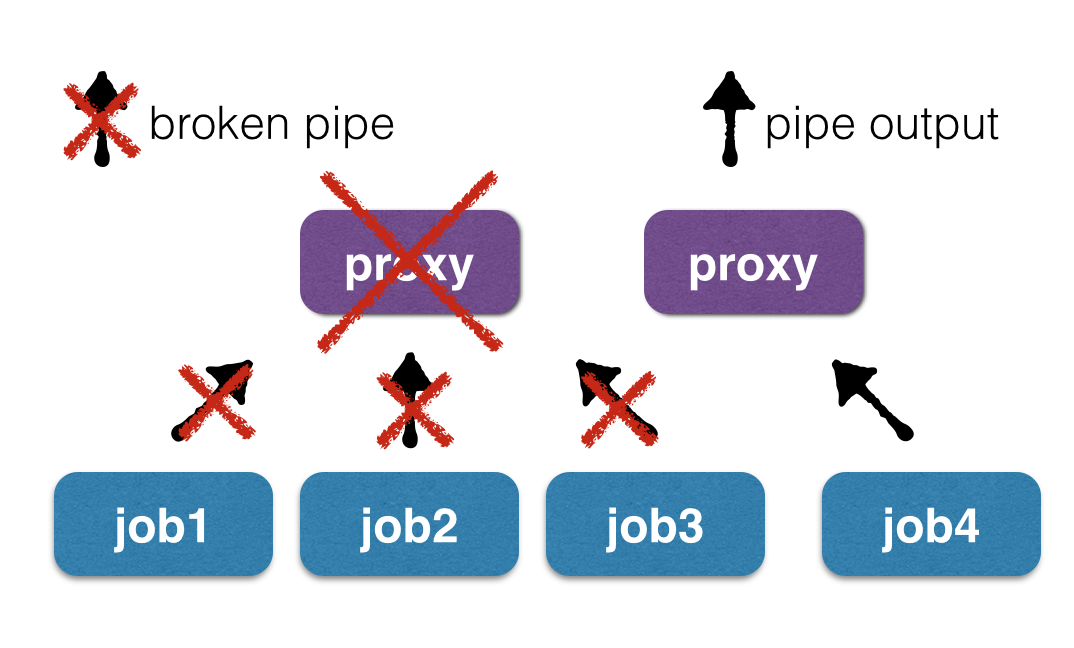
This happens because when the daemon restarts, all the descriptors corresponding to the reading side of the pipe are closed, and when attempting to write to them later, the processes will receive SIGPIPE, ending. By the way, it is on this mechanism that the work of chains of unix commands is based using the head utility and others: the cat some_file.txt | head does not lead to any error messages, because after reading the required number of lines, head simply exits, the corresponding pipe “breaks” and the cat process, which continues to write to its end “pipe”, receives a SIGPIPE signal, which simply completes its execution. If there were several processes in the chain, then the same situation will occur with each element of the chain, and all intermediate applications will safely exit at the SIGPIPE signal.
You can replace the "regular" unix pipes with "named" named pipes, that is, continue to write to files, only they will have a different type - named pipes. However, in order to be able to easily experience crashes and restarts of a proxy, you need to put somewhere the information about the correspondence of the file name and the launch id. One such option is the file name itself, which returns us to the original problem. Other options are to store it in a separate database, for example, in sqlite or rocksdb, but this seems too cumbersome for such a seemingly simple task, and at the same time adds the problems of a two-phase commit ( and the reading process at this time has died, the record in the database will not be updated, and the next incarnation of the reading process will assume that the startup id is still old).
Decision
What properties should have a new solution?
- Resistance to restarting and dropping any components - proxy, log collector and server receiver.
- If one of the classes writes so many logs that they do not have time to process, the logs of the other classes should still be delivered in a reasonable time and be available for viewing by the developers.
- If there are problems with logging, the situation should not be out of control and should be easily corrected manually (for example, millions of files should not be created).
- If possible, the system should be real-time and have a large supply of bandwidth.
Due to the problems described above with inotify and clogging the dentry cache, the new scheme should always write to files with the same names. As a simple and logical solution, it seems to write the output of applications to files of the form class_name.out.log and periodically rotate them, calling, for example, class_name.out.log.old. Unfortunately, writing logs from different instances to the same file requires modification of applications: if before it was possible to do a simple echo, then in the new scheme you will always have to use a logger that adds a tag with a launch ID to each line. Using flock () while simultaneously writing is also undesirable, since this greatly reduces performance and can cause a situation where one “stuck process” can block the execution of all other instances of this application on the current server. Instead of using flock (), you can simply open the file in O_APPEND mode (a flag) and write in blocks of no more than 4 KB (in Linux) so that each entry is atomic.
Thus, we have decided points 1 and 3 by simply writing to file-to-class instead of file-to-launch.
How to collect logs?
So, we have found a solution for problems with inotify, a large number of files and resistance to falling proxies. It remains to understand now how to collect these logs. The logical solution would be to simply leave the scribe or use its analogues, for example, syslog-ng and others. However, in fact, we already write logs to files, so we could instead write a simple stream stream of the contents of these files to a central server. The scheme will look like this:
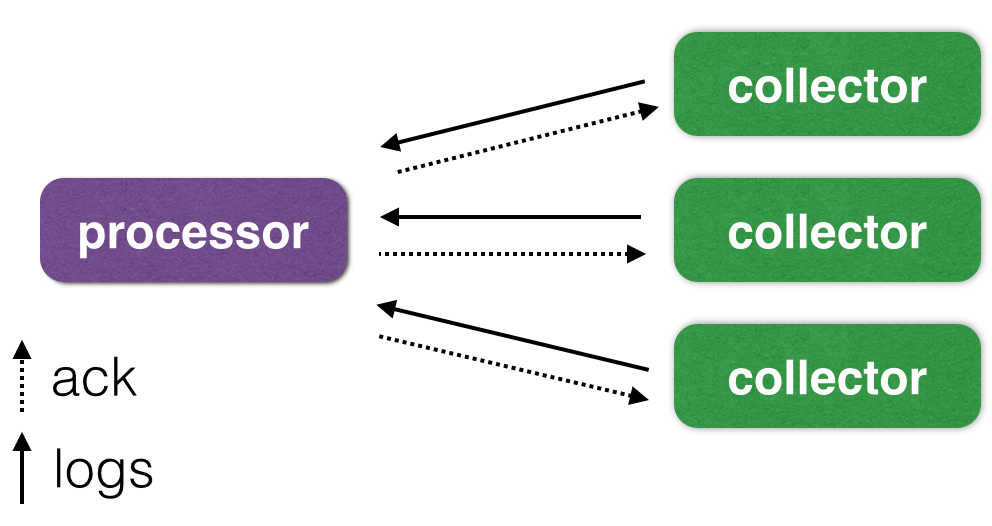
As you can see in the figure, we have 2 large subsystems: a server-receiver (processor) and log collectors on each machine (collector).
Communication between the receiver and collectors is carried out using a permanently established TCP / IP connection, and Google Protocol Buffers is used to package the packets. Collectors use inotify to track changes in files and send packets with new lines to the receiver. That, in turn, sends back the offsets received by it (and successfully recorded to the file with the log) in the files on the source server.
The receiver periodically (once a second in our implementation) resets the new offsets to a separate JSON file in the form of a list [{Inode: ..., Offset: ...}, ...]. This scheme allows you to be resistant to network failures, but does not protect against power failures and kernel panic on servers. This problem is irrelevant for us, so the receiver sends confirmation of the recorded data after a successful write () call, without waiting for a real data reset to disk. In case of network failures, the receiver and the collector, the last lines can be delivered 2 or more times, which also suits us. If you need not only guaranteed, but also one-time delivery, you can read about the much more complex system that Yandex built: habrahabr.ru/company/yandex/blog/239823 .
"Trotting" delivery of individual classes
As I have already said, we were not satisfied with the fact that one very “flooded” script could completely clog the bandwidth and slow down the processing of all other logs. This happened because you can write much faster in scribe than delivery to the receiver, and we had single-threaded processing of events from scribe because of the need to follow the order of the lines in the logs at least within one task.
The solution to this problem is quite simple: you need to make an analogue of "preemptive multitasking", i.e. in one pass, process no more than N lines in the file, and then proceed to the next. When all sent pieces for “normal” logs are received on the server, you can return to sending the “bold file” and act on the same algorithm. Thus, the delivery of the “large file” has a limited effect on the system: the logs of all remaining classes continue to be delivered with a fixed delay, which is regulated by the maximum packet size N. The rest of the delivery speed is not limited artificially - if the active recording goes only to one file, it will be delivered as fast as possible.

File rotation
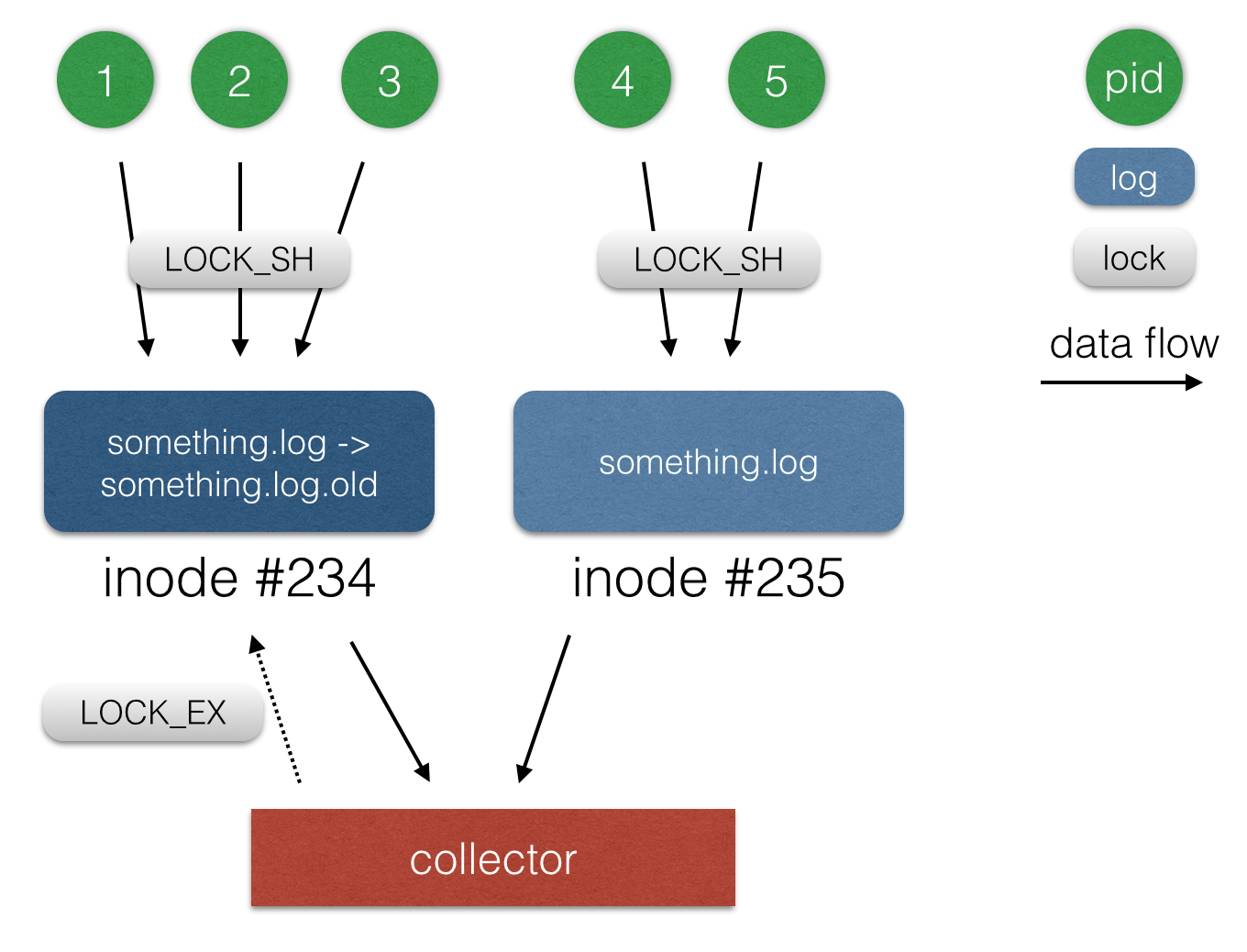
In order for the logs not to take up all the space on the server, it is necessary to rotate them. The rotation of the logs is the process of deleting the oldest file with the log and renaming more recent files to the “old” ones. In our case, rotation means deleting the old file with the log and renaming the current one (class_name.out.log -> class_name.out.log.old). When renaming a file, all processes that keep this file open can continue to work with it, in our case - to write. Therefore, we need to continue to send changes that have occurred both in the new and in the old file with the log. When renaming a file, the inode is also saved, so in the database we store successfully sent offsets in the files for the inode, and not for file names.
Another minor problem with rotation is that, before deleting a file, you need to somehow determine that no one else writes to it. Since all applications write to files using the O_APPEND flag without using flock (), we can use flock () for some other purpose. In our case, the application takes a shared lock (LOCK_SH) to the file descriptor it writes to before starting. To make sure that the file is no longer in use, it remains for us to try to take an exclusive lock (LOCK_EX). If the lock was able to get, then the file is no longer used, you can delete it. Otherwise, we need to wait for the log file to be released, and temporarily postpone its rotation.
Performance, conclusions
Since the previous version of the log collector worked in one thread and was written in PHP, the comparison will not be very fair. Nevertheless, I would like to give the results for both the old and the new architecture.
The old system (PHP, single stream) - 3 MiB / sec to the server is a good result for PHP.
The new system (Go, fully asynchronous and multi-threaded) - 100 MiB / s per server - rests on the network card and drives.
As a result of reworking the logging system, we solved all the problems that we had with it, and received a huge supply of speed of delivery, as well as resistance to the "flood" of individual classes - now one script cannot litter the entire system and cause many hours of delivery delays . , , Go , .
Links
Open-source : github.com/badoo/thunder
open-source : tech.badoo.com/open-source
youROCK
Lead PHP developer
Source: https://habr.com/ru/post/265875/
All Articles