Why not everything is so simple with MongoDB
 In the past few years, MongoDB has gained immense popularity among developers. Every now and then all kinds of articles appear on the Internet, as the regular young popular project threw the familiar RDBMSs to the dustbin of history, took MongoDB as the main database, built the infrastructure around it, and how everything turned out fine. Even new frameworks and libraries appear, which build their architecture entirely on Mongo ( Meteor.js for example).
In the past few years, MongoDB has gained immense popularity among developers. Every now and then all kinds of articles appear on the Internet, as the regular young popular project threw the familiar RDBMSs to the dustbin of history, took MongoDB as the main database, built the infrastructure around it, and how everything turned out fine. Even new frameworks and libraries appear, which build their architecture entirely on Mongo ( Meteor.js for example).I have been working for about 3 years on development and support of several projects that use MongoDB as the main database, and in this article I want to tell why in my opinion with MongoDB, not everything is as simple as it is written in the manuals, and why do you should be ready, if you suddenly decide to take MongoDB as the main database in your new fashionable startup :-)
Everything described below can be reproduced using the PyMongo library for working with MongoDB from the Python programming language. However, you will likely encounter similar situations when using other libraries for other programming languages.
PyMongo, problem with Failover and AutoReconnect exception
Almost in all manuals as well as in numerous articles on the Internet it is said that Mongo supports failover out of the box due to the built-in replication mechanism. In several articles, even in official courses from 10gen , a very popular example is given, such as if you deploy several mongod processes on one host and set up replication between them, and then kill one of the processes, the replication will not collapse, the new master will be re-elected and everything will be OK. And this is indeed how it works ... but only on localhost! In real conditions, everything is a little different.
')
Let's say let's experiment with virtual machines on Amazon. Let's raise 5t small machines - 3 for databases, and 2 for test processes writer and reader - one continuously writes values to the base, the other reads them.
We take CentOS 6.x, put mongodb on it from standard rep, set supervisor. The configuration of each of the mongod processes at the supervisor is as follows:
# touch /etc/supervisord.d/mongo.conf [program:mongo] directory=/mnt/mongo command=mongod --dbpath /mnt/mongo/ --logappend --logpath /mnt/mongo/log --port 27017 --replSet abc Configure replication:
# mongo --port 27017 > rs.initiate({ _id: 'abc', members: [ {_id: 0, host:'db1:27017'}, {_id: 1, host:'db2:27017'}, {_id: 2, host:'db3:27017'} ] }) The writer.py process looks like this:
import datetime, random, time, pymongo con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc') cl = con.test.entities while True: time.sleep(1) try: res = cl.insert({ 'time': time.time(), 'value': random.random(), 'title': random.choice(['python', 'php', 'ruby', 'java', 'cpp', 'javascript', 'go', 'erlang']), 'type': random.randint(1, 5) }) print '[', datetime.datetime.utcnow(), ']', 'wrote:', res except pymongo.errors.AutoReconnect, e: print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e except Exception, e: print '[', datetime.datetime.utcnow(), ']', 'error:', e As you can see from the listing, the above script every second tries to save the value to the database.But the reader.py process:
import datetime, time, random, pymongo con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc') cl = con.test.entities while True: time.sleep(1) try: res = cl.find_one({'type': random.randint(1, 5)}, sort=[("time", pymongo.DESCENDING)]) print '[', datetime.datetime.utcnow(), ']', 'read:', res except Exception, e: print '[', datetime.datetime.utcnow(), ']', 'error' print e And this script every second tries to read the value from the database.We start the processes writer.py and reader.py in parallel, and then we take a stop-aem machine with a Primary-node in the Amazon console.
What should happen logically? According to the MongoDB documentation, the 'abc' replica has to re-elect a new wizard and this should happen transparently for the writer.py and reader.py scripts , and if you are testing on the locale (i.e., deploying all three processes on the same host), then really and going on. In our case, the scripts writer.py and reader.py simply hang and remain so suspended until you send them an interrupt signal (even when the new primary is already selected and active).
[ 2015-08-28 21:57:44.694668 ] wrote: 55e0d958671709042a4918b5 [ 2015-08-28 21:57:45.696838 ] wrote: 55e0d959671709042a4918b6 [ 2015-08-28 21:57:46.698918 ] wrote: 55e0d95a671709042a4918b7 [ 2015-08-28 21:57:47.703834 ] wrote: 55e0d95b671709042a4918b8 [ 2015-08-28 21:57:48.712134 ] wrote: 55e0d95c671709042a4918b9 ^CTraceback (most recent call last): File "write.py", line 18, in <module> 'type': random.randint(1, 5) File "/usr/lib64/python2.6/site-packages/pymongo/collection.py", line 409, in insert gen(), check_keys, self.uuid_subtype, client) File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 393, in _do_batched_write_command results.append((idx_offset, send_message())) File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 345, in send_message command=True) File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1511, in _send_message response = self.__recv_msg(1, rqst_id, sock_info) File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1444, in __recv_msg header = self.__recv_data(16, sock) File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1432, in __recv_data chunk = sock_info.sock.recv(length) KeyboardInterrupt Agree that not a good situation for a system that positions itself as a fault-tolerant out of the box? Of course, the example is a bit exaggerated - for example, if you use PyMongo and MongoDB in your web project, then it is likely that all python facilities are running under uwsgi , and some harakiri mode is set up in uwsgi , which will beat the timeout scripts y ... But nevertheless, I would like to somehow intercept this kind of situation in the code. For this you need to modify the scripts. In reader.py script you need to replace:
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc') on con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000, read_preference=pymongo.ReadPreference.SECONDARY_PREFERRED) And in the script writer.py :
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc') on con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000) What in the end we get. Repeating the experiment with cutting the Primary node, the reader.py process will continue to work as if nothing had happened (since it refers to the Secondary node, which in our example remains unchanged), but the process writer.py will go to astral for about a minute while throwing AutoReconnect type errors:
[ 2015-08-28 21:49:06.303250 ] wrote: 55e0d75267170904208d3e01 [ 2015-08-28 21:49:07.306277 ] wrote: 55e0d75367170904208d3e02 [ 2015-08-28 21:49:13.313476 ] autoreconnect error: timed out [ 2015-08-28 21:49:24.315754 ] autoreconnect error: No primary available [ 2015-08-28 21:49:33.338286 ] autoreconnect error: No primary available [ 2015-08-28 21:49:44.340396 ] autoreconnect error: No primary available [ 2015-08-28 21:49:53.361185 ] autoreconnect error: No primary available [ 2015-08-28 21:50:04.363322 ] autoreconnect error: No primary available [ 2015-08-28 21:50:13.456355 ] wrote: 55e0d79267170904208d3e09 [ 2015-08-28 21:50:14.459553 ] wrote: 55e0d79667170904208d3e0a [ 2015-08-28 21:50:15.462317 ] wrote: 55e0d79767170904208d3e0b [ 2015-08-28 21:50:16.465371 ] wrote: 55e0d79867170904208d3e0c Again, it’s not too healthy for the system, which is positioned as fail-safe, to go down for a minute (I repeat that if you test on the locale, there are no timeouts - everything is smooth), but this is an inevitable evil and even written about this in the documentation :
It varies, but a replica set will select a new primary within a minute.But back to our example and to the errors AutoReconnect. As you probably guessed, we set a timeout of 5 seconds per socket. If after 5 seconds the PyMongo driver does not receive any response from the database, then it drops the connection and spits out an error. Not a great solution - suddenly the database is overloaded or the request is very heavy and takes more than 5 seconds to complete (some aggregate function that wools the entire base). The most important question is why the driver does not try to restart the request itself when it sees that AutoReconnect Error has occurred. The first reason - the driver does not know what really happened - all of a sudden, “not a single process”, but the whole replicat “lay down”. The second reason is duplicates! It turns out that in case of an AutoReconnect error, the driver does not know whether it managed to write data or failed. This sounds a bit strange for a base that claims to dominate the world, but this is true, and for our example to work correctly, the script writer.py needs to be rewritten as follows:
It can take 10-30 seconds to replica set to declare a primary inaccessible. This triggers an election. During the election, the cluster is unavailable for writes.
The election itself may take another 10-30 seconds.
import datetime, time, random, pymongo from pymongo.objectid import ObjectId con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000) cl = con.test.entities while True: time.sleep(1) data = { '_id': ObjectId(), …. } # Try for five minutes to recover from a failed primary for i in range(60): try: res = cl.insert(data) print '[', datetime.datetime.utcnow(), ']', 'wrote:', res break except pymongo.errors.AutoReconnect, e: print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e time.sleep(5) except pymongo.errors.DuplicateKeyError: break On this topic there is also an article in the blog of one of the PyMongo developers, as well as a small discussion in JIRA MongoDBGlobal lock problem
A huge MongoDB reef. Probably something for which Mongu is most criticized. Under attack are massive operations carried out on a group of documents. That is, roughly speaking, several heavy operations of updates on a large group of documents can create performance problems and block the execution of other requests. Of course, starting from version 2.2, the situation improved a little when they learned how to lock lock (lock yielding), and also transferred the lock from the level of the mongod process to the level of the selected database. In the new version 3.0, the creators claim that with the transition to the alternative WiredTiger engine, the situation should improve, since it uses locks at the document level, and does not block the entire database, as it was in the MMAPv1 engine.
I wrote a small benchmark to illustrate the global lock situation. If you wish, you can do git pull and play all these tests at your place.
- Consider 1 000 users (value can be changed via config)
- Each user has 5,000 documents. That is only 5,000,000 documents in the database. Each document contains a field that stores some boolean value.
- The testing process is the parallel execution of 1,000 tasks — one for each user. Each task is updating the boolean field of all 5,000 user documents.
- In the process of testing by incrementing from 1st to 30th (again, the value can be changed through the config), we increase the number of competitive processes that at a time pick up a pool of tasks.
- Save the execution time of each task. We build graphics. Compare test results for different versions of MongoDB.
- Alternatively, consider a similar task in MySQL 5.5 (InnoDB). And compare the results.
As a result of testing the following has turned out.
If we compare the version of MongoDB 2.6 and the version of MongoDB 3.0 (MMAPv1, not WiredTiger), the results do not differ much, although in the case of 30 simultaneous worker processes using MongoDB 3.0, the query execution time is still slightly smaller. By the way, during testing, if you look at the mongostat utility for the percentage of lock, it will go off scale:
Result of comparing MongoDB 2.6 and MongoDB 3.0 MMAPv1
In 15t parallel processes:
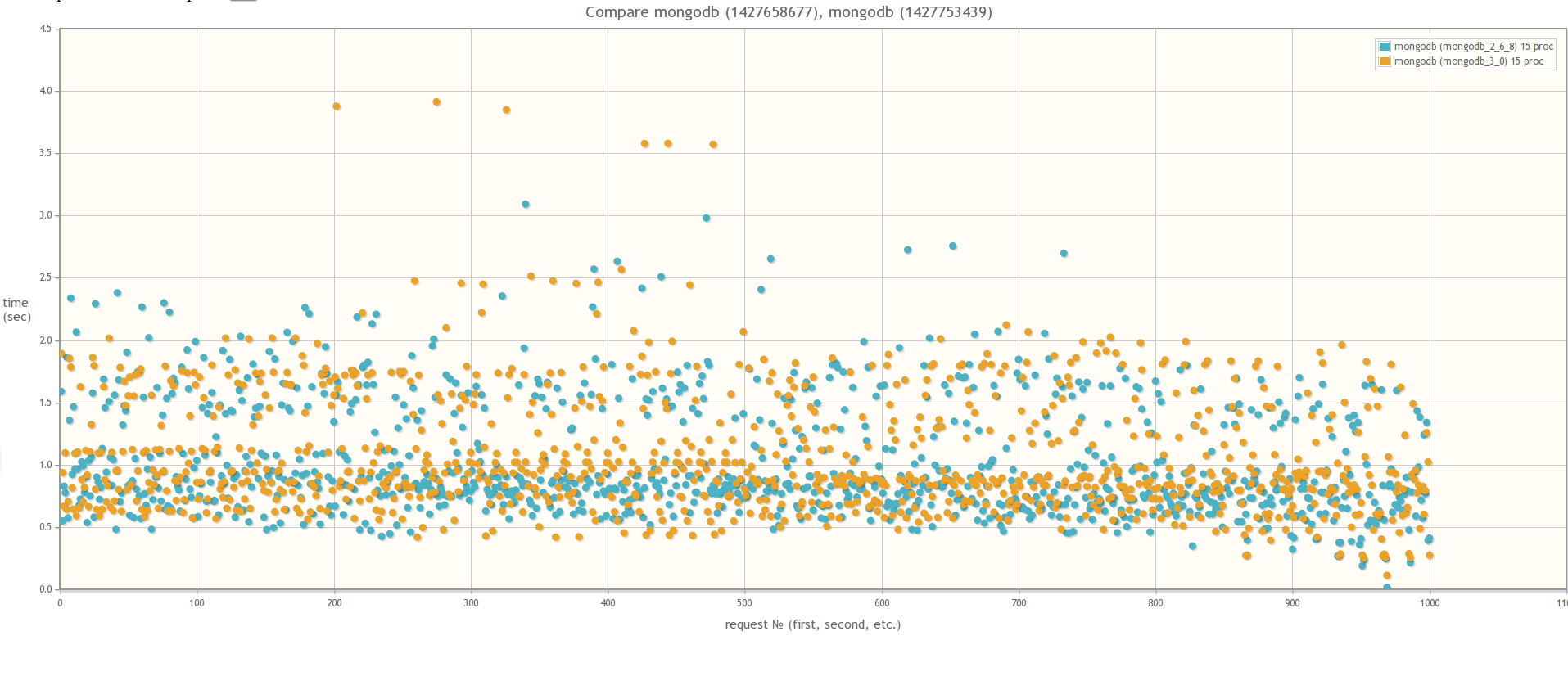
In 30 parallel processes:
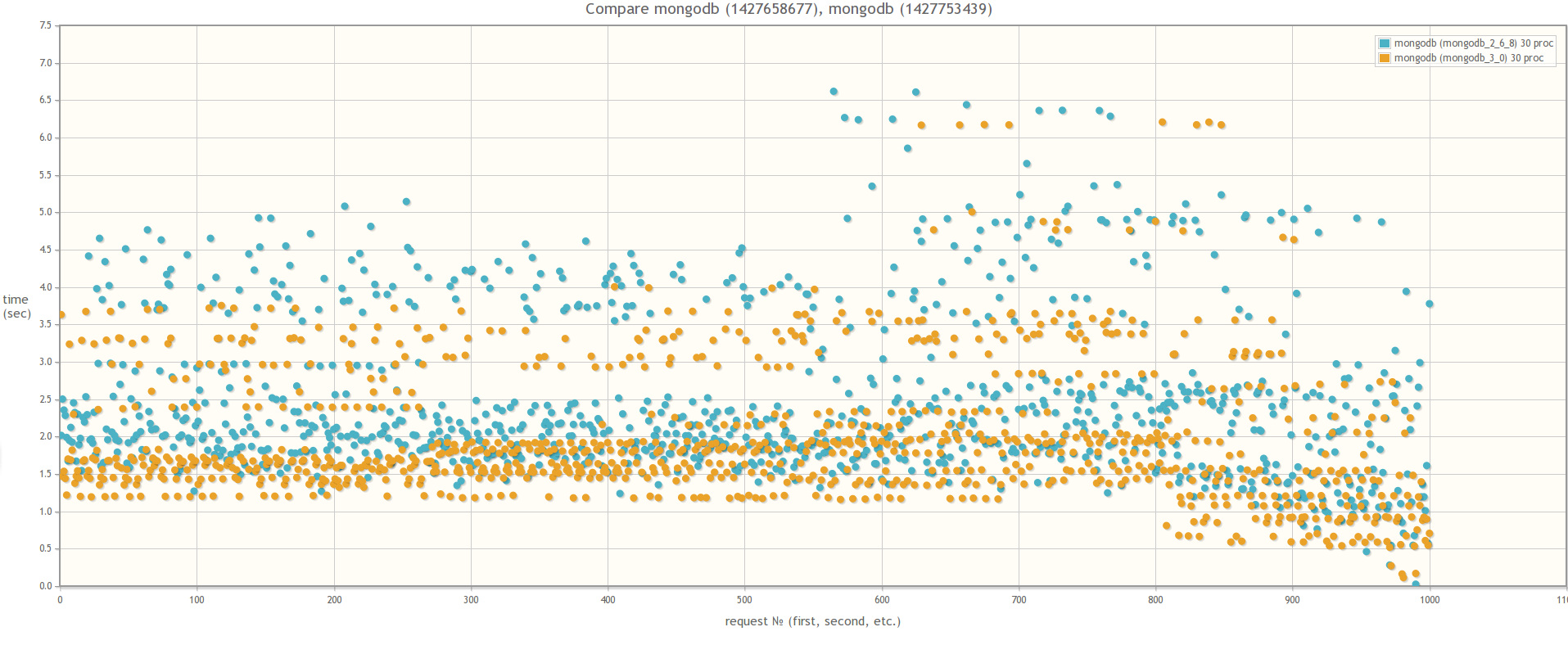
mongostat:
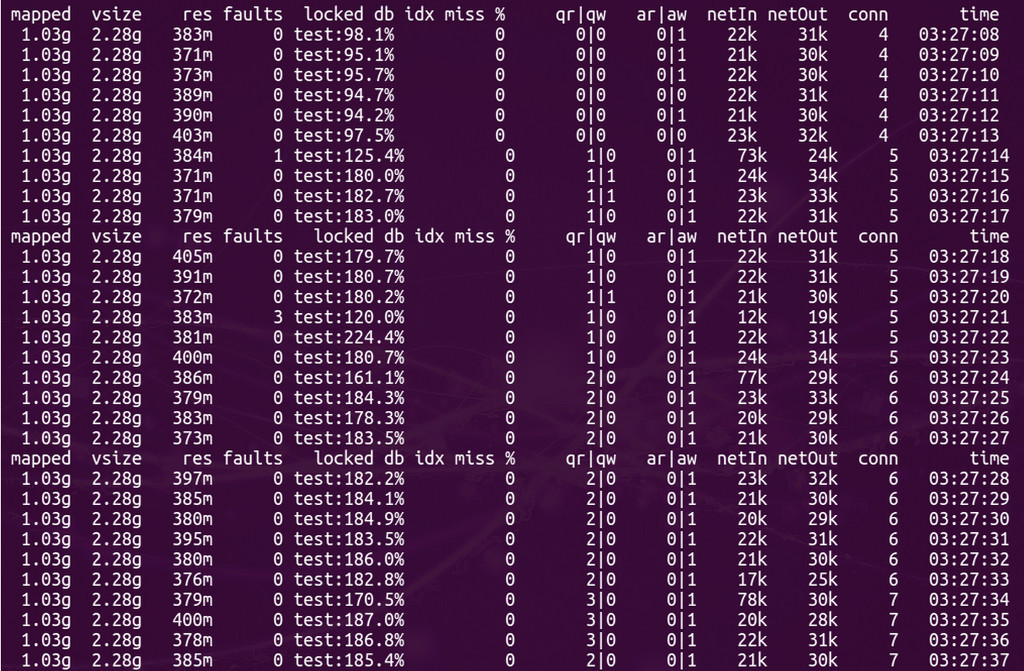
In 30 parallel processes:
mongostat:
When comparing MongoDB 3.0 MMAPv1 and MongoDB 3.0 WiredTiger, the results are strikingly different, which suggests that the effect of locks on the performance of bulk operations is indeed much less when using WiredTiger:
Result of comparing MongoDB 3.0 MMAPv1 and MongoDB 3.0 WiredTiger
In 15t parallel processes:
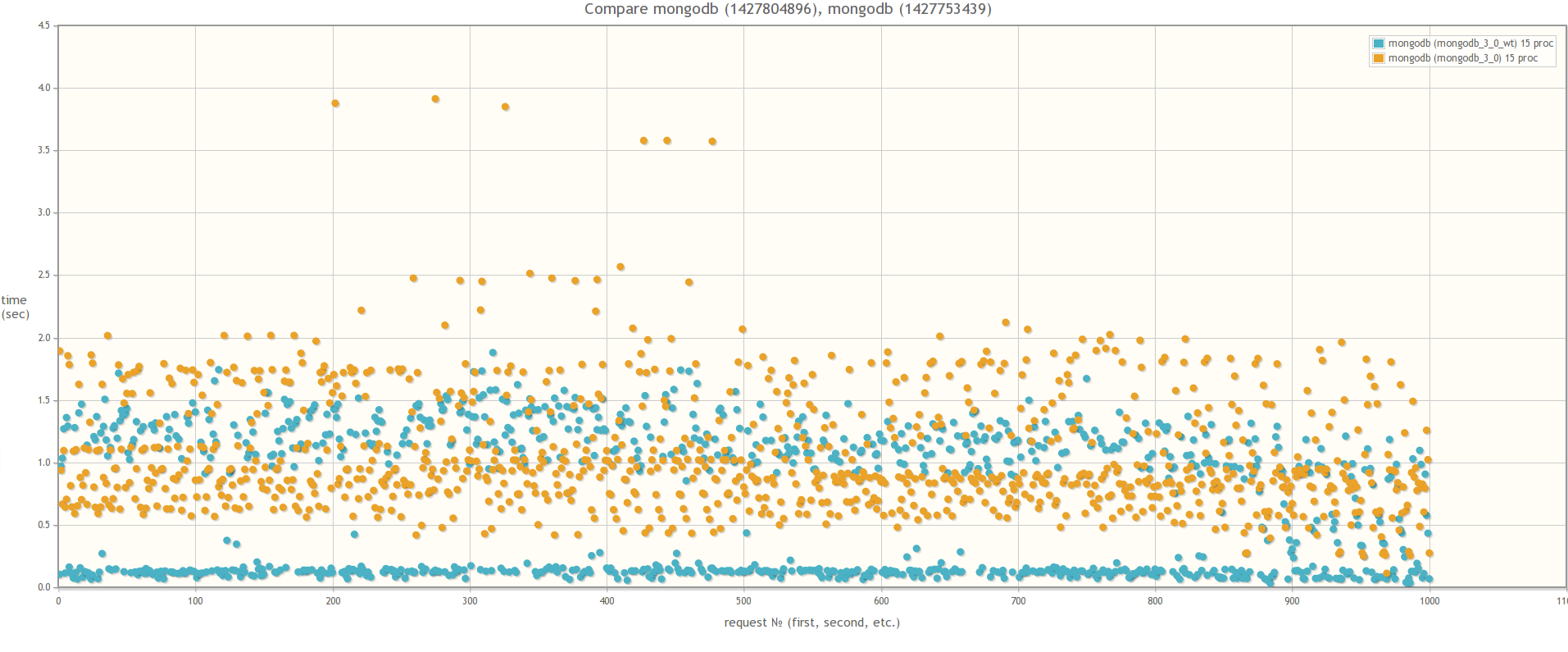
In 30 parallel processes:
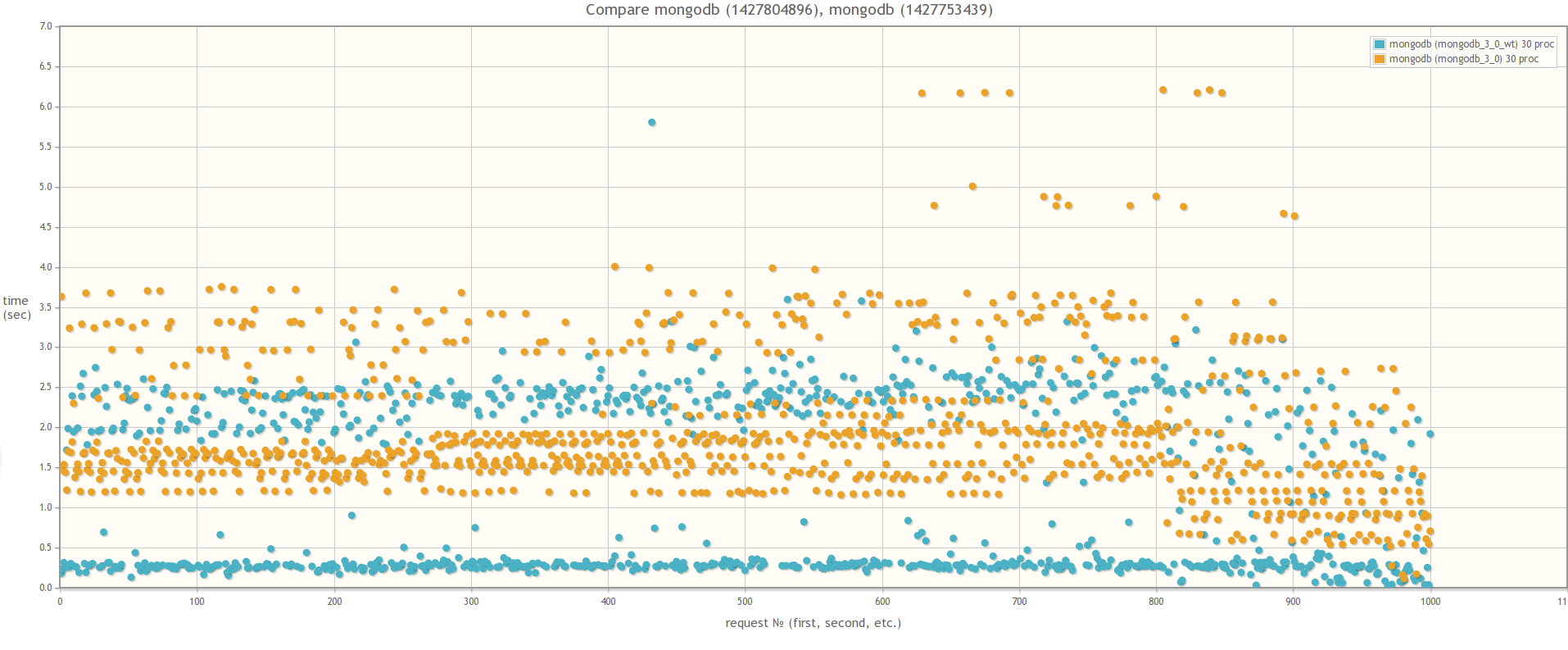
In 30 parallel processes:
Now compare MongoDB 3.0 WiredTiger and MySQL 5.5. MySQL database was selected solely from individual preferences. If someone has a desire, you can conduct a similar test on PostgreSQL. All the logic of working with the base is encapsulated with special adapters. So for this you only need to write a class, inheriting it from the abstract class AbstractDBAdapter and redefining all abstract methods for working with PostgreSQL.
As you know, testing a base out of the box is a thankless and meaningless exercise. As for MongoDB, alas, everything is bad here. The base is almost not tyunitsya, minimum settings. The main principle of MongoDB is to allocate a separate server as a base, and then the base will decide for itself which data to keep in memory and which to drop to disk. In several sources I heard the opinion that there should be at least enough free memory on the server so that the indexes fit into it. In the case of MySQL mass settings, and before starting the benchmark, the following setting was made:
max_connections = 10000 query_cache_limit = 32M query_cache_size = 1024M innodb_buffer_pool_size = 8192M innodb_log_file_size = 512M innodb_thread_concurrency = 16 innodb_flush_log_at_trx_commit = 2 thread_cache = 32 thread_cache_size = 16 And here are the results.The first thing that catches the eye when performing a test on MySQL is that the total time for the execution of all tasks with an increase in the number of processes — workers practically does not change:
... Run test with 5 proceses Test is finished! Save results Full time: 20.7063720226 Run test with 6 proceses Test is finished! Save results Full time: 19.1608040333 Run test with 7 proceses Test is finished! Save results Full time: 19.0062150955 … Run test with 15 proceses Test is finished! Save results Full time: 18.5613899231 Run test with 16 proceses Test is finished! Save results Full time: 18.4244360924 … Run test with 29 proceses Test is finished! Save results Full time: 16.8106219769 Run test with 30 proceses Test is finished! Save results Full time: 19.3497707844 The second is of course graphics. In the case of MySQL, the query execution time fluctuates around 0.001-0.5 seconds and is constant both with 15 handler processes and at 30, while in the case of MongoDB WiredTiger with 15 processes, the query execution time reaches 1.5 seconds, and at 30 - up to 2.5 seconds:Result of comparing MongoDB 3.0 WiredTiger and MySQL 5.5 InnoDB
In 15t parallel processes:

In 30 parallel processes:
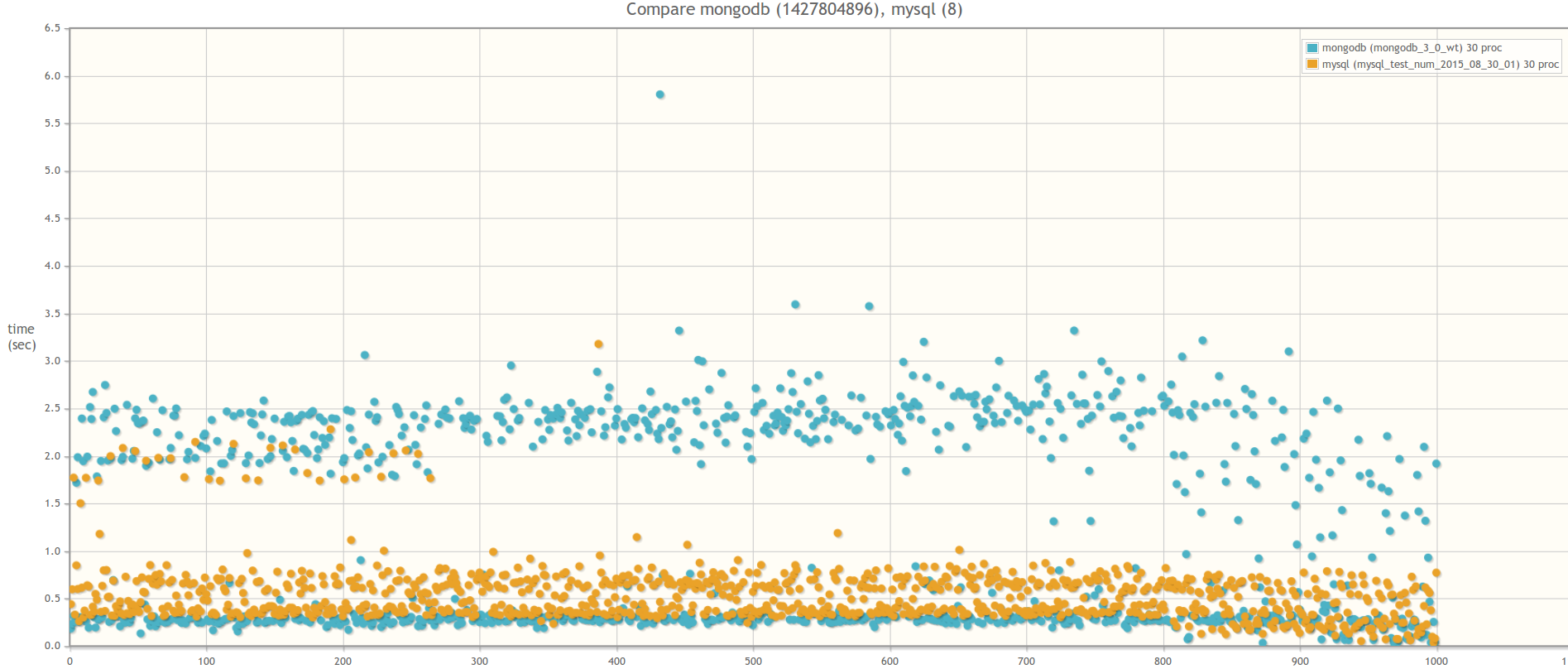
In 30 parallel processes:
What conclusions can be drawn from this?
Personally, I see the following pattern for myself when you can use MongoDB in a project:
- the data scheme fits well with the concept of “thick” weakly coherent documents
- the lack of transactions is compensated by the atomic nature of operations on documents
- The business logic of the application does not imply numerous bulk operations on documents.
It is also desirable that documents are not removed frequently. This is connected with another small problem (I decided not to take it to a separate point). When deleting documents, free disk space is not freed. MongoDB marks the block on the disk as free and, if convenient, uses this block for a new document. According to my observations before version 2.6, this strategy worked extremely inefficiently, because after performing repairDatabase on a long-lived database, it was possible to reduce the size of data and indexes by more than 2 times (!). Starting from version 2.6 for new collections, the new strategy began to be used to preallocate a disk for new documents ( usePowerOf2Sizes option) - as a result of its use, the size of the allocated space for new documents became slightly larger than before, but the space after deleting documents became more efficiently. And in version 3.0 for the MMAPv1 engine, we went even further and once again changed the preallocation strategy , but I haven’t yet been able to evaluate its production efficiency. What happens with the WiredTiger engine in terms of preallocating the disk, to be honest, I do not know either. If you have any information about this - write in the comments :-)
Source: https://habr.com/ru/post/265747/
All Articles