We check all pages of a site in the html validator

Intro
The goal is to create a
I heard that if perfectionism attacks, then you need to lie down, rest and it will pass.
Just think, the error in the validator ...
But if it still does not pass, then
We put docker and container with validator.
Previously, it was a chore to put a local validator.
Not that difficult, but time consuming.
With the arrival of the docker, it is installed in seconds.
We put the docker:
yum install docker After installing the docker, we take a ready-made image with the collected validator :
docker pull magnetikonline/html5validator When the image downloads, we launch it:
docker run -p 8080:80 -p 8888:8888 --name validator --restart=always -d magnetikonline/html5validator And we start:
docker start validator After launch, you can go to http: // localhost: 8888 and see:
')

Local validator works! It can be set on any site.
And check from the command line:
curl 'localhost:8888?doc=http://www.w3schools.com' And here is the result:
As you can see, the validator found 3 errors.
Spider

Now you need to write a script that would bypass all pages of the site.
As a basis, I took this Mojo based web crawler / scraper .
And changed a little:
#!/usr/bin/env perl use 5.010; use open qw(:locale); use strict; use utf8; use warnings qw(all); use Mojo::UserAgent; use List::MoreUtils 'true'; use Term::ANSIColor; # my $site_to_check = 'http://habrahabr.ru'; # my $local_validator = 'http://192.168.1.217:8888'; # FIFO queue my @urls = ( Mojo::URL->new($site_to_check) ); # User agent following up to 5 redirects my $ua = Mojo::UserAgent->new( max_redirects => 5 ); # Track accessed URLs my $active = 0; my %uniq; sub parse { my ($tx) = @_; # Request URL my $url = $tx->req->url; # Extract and enqueue URLs for my $e ( $tx->res->dom('a[href]')->each ) { # Validate href attribute my $link = Mojo::URL->new( $e->{href} ); next if 'Mojo::URL' ne ref $link; # "normalize" link $link = $link->to_abs( $tx->req->url )->fragment(undef); next unless $link->protocol =~ /^https?$/x; # Don't go deeper than /a/b/c next if @{ $link->path->parts } > 3; # Access every link only once next if ++$uniq{ $link->to_string } > 1; # Don't visit other hosts next if $link->host ne $url->host; push @urls, $link; my $get = $ua->get( $local_validator . "?doc=$link" )->res->body; my @answ = split / /, $get; my $count = true { /class="error"/ } @answ; print color("green"), $link, color("reset"); print " - : ", color("red"), "$count \n", color("reset"); } return; } sub get_callback { my ( undef, $tx ) = @_; # Parse only OK HTML responses $tx->res->code == 200 and $tx->res->headers->content_type =~ m{^text/html\b}ix and parse($tx); # Deactivate --$active; return; } Mojo::IOLoop->recurring( 0 => sub { # Keep up to 4 parallel crawlers sharing the same user agent for ( $active .. 4 - 1 ) { # Dequeue or halt if there are no active crawlers anymore return ( $active or Mojo::IOLoop->stop ) unless my $url = shift @urls; # Fetch non-blocking just by adding # a callback and marking as active ++$active; $ua->get( $url => \&get_callback ); } } ); # Start event loop if necessary Mojo::IOLoop->start unless Mojo::IOLoop->is_running; Github link
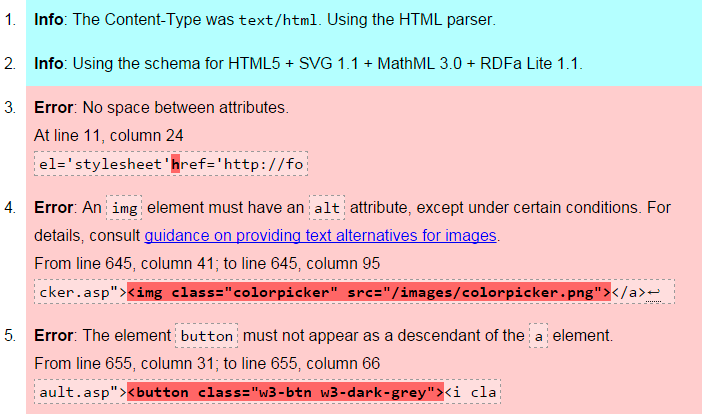
Result of work:

Source: https://habr.com/ru/post/265709/
All Articles