15 trivial facts about working correctly with the HTTP protocol
Attention! Advertising! Post paid for by Captain Obvious!
Below the cat you will find 15 items describing the proper organization of resources available via HTTP protocol - web sites, backend “handles”, API and so on. “Correct” here means “compliant with recommendations and specifications”. Most of the written below is almost literally translated from the official standards, recommendations and best practices from the IETF and W3C.

')
You will not find absolutely nothing obvious here. No, seriously, every web developer, theoretically, these 15 points should be mastered somewhere in the junior area of a developer and / or second or third year university.
However, in practice it turns out that a great many web developers have not yet learned these basics. You read the documentation for other APIs and weep. I am sure that every reader will still find something new for himself in this list.
1. URL identifies the resource - some shared entity. File is a resource. A pen that is looking for something is a resource. Calling a method is not a resource. If you want to shake the cannon across the moon, then don't do this:
Get a resource "sharahalka", and then everything will be logical:
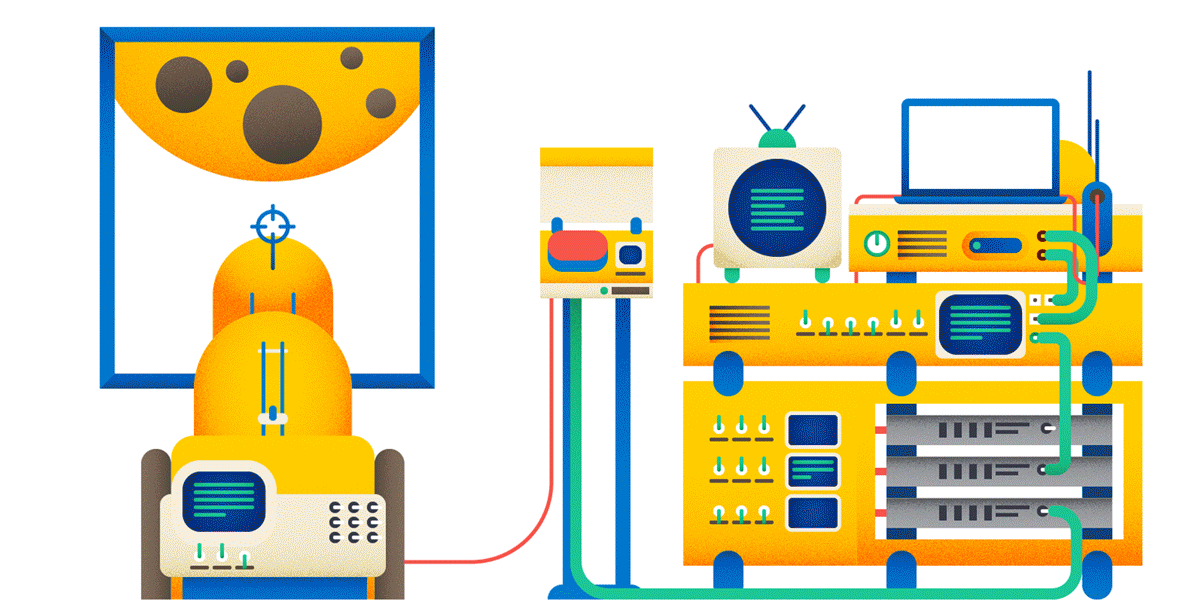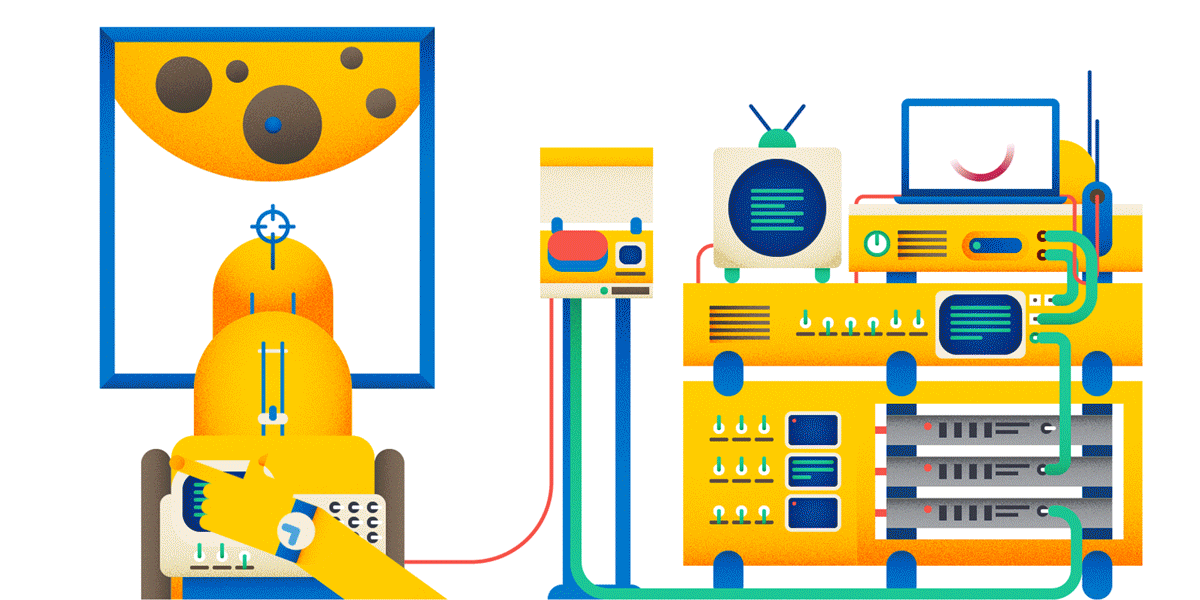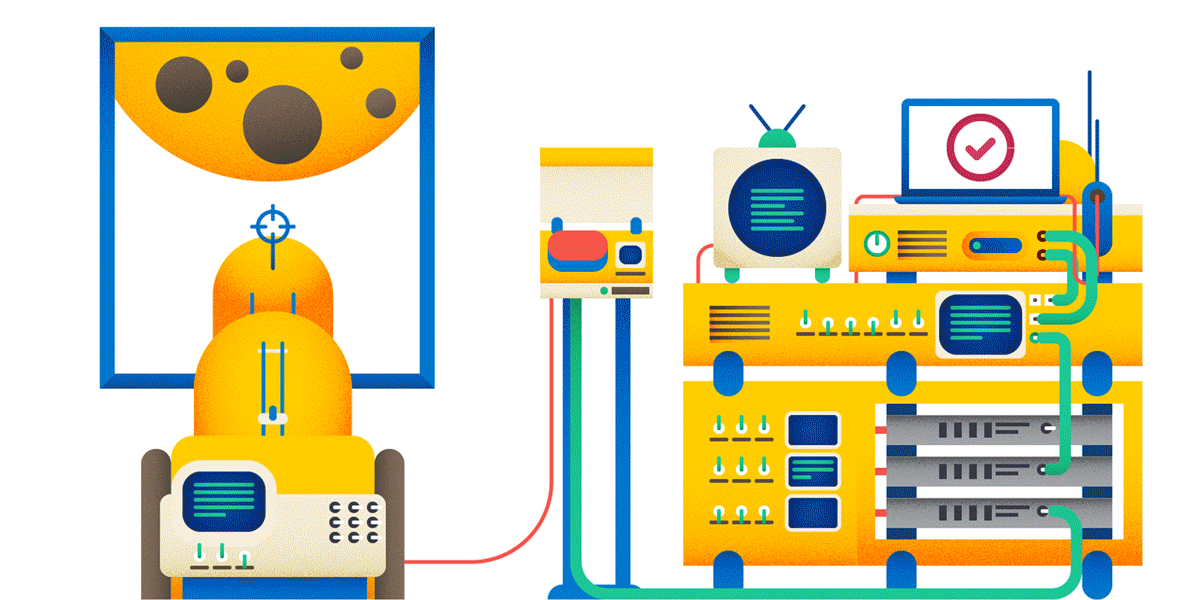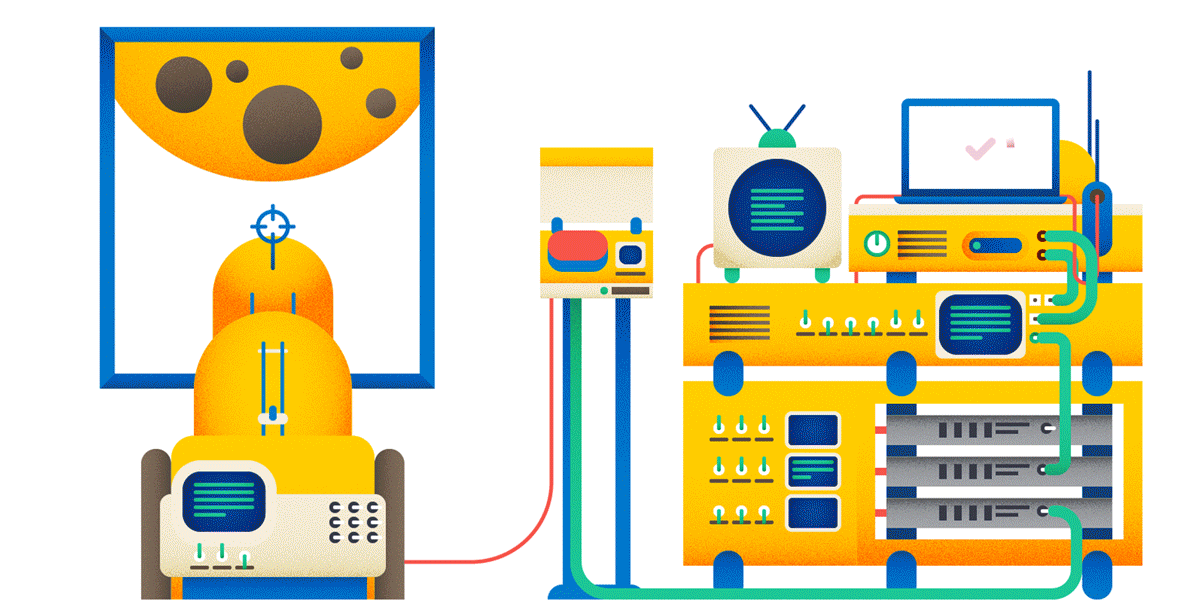
Why POST, not GET? Read below.
2. A URL consists of a schema (protocol), a host, a path (path), a query (query), and a fragment. The path is used to organize hierarchical resources, the query is used for non-hierarchical resources and for operation parameters. The fragment identifies a subordinate resource that does not have a direct URL.
If your site "Nyashnye Seals" has a catalog by breed, then it is quite logical to organize it as part of the path, since each cat belongs to exactly one breed. But you can deliver one cat in several cities, so the filter “with delivery to the city N” should be organized through a query.
3. An HTTP call consists of applying a method (verb) to a URL. The result of this application should be a surprise surprise! - what is written in the verb. That is, GET returns a resource representation, DELETE deletes, and so on.
4. GET, HEAD, OPTIONS methods are safe. It is assumed that calling these methods does not change the state of the resource. Therefore, many network agents - such as, for example, the prefetcher of links in the browser or instant messenger - consider themselves entitled to follow such links without the explicit will of the user. IChH, do not violate any standards.
5. By default, the GET and HEAD methods are cached, OPTIONS, POST, PUT, PATCH, DELETE are not. Therefore, if you hit the moon using the POST method, you can be (almost) sure that this request will be executed. If you shy away with the GET method, some intermediate proxy may SUDDENLY give you a response from the cache, and the balls will not happen in reality.
6. GET, PUT, DELETE operations are symmetrical. PUT puts something on the URL (by creating a new resource or overwriting the old one), GET on this URL returns the idea of what the PUT put, DELETE deletes the resource.
The HEAD method is synonymous for the GET method, but does not return the response body, but only its headers (meta information about the resource).
7. POST is used if you do not have a URL to which you want to apply the operation. For example, if a user writes a new message to a forum thread, he can calculate his id and do it himself:
If a client is not allowed to generate an id, he will have to make a POST to a resource higher in the hierarchy:
And this resource itself will create a new message.
Note, if you repeat the POST request by mistake or due to network problems, a second message will be created in the thread that is identical to the first one. PUT you can do at least 100,500 times, the result will not change. This property is called idempotency.
Okay, creating posts on the forum. Now, if you are doing a heavy and expensive operation on a user request, it is highly recommended to perform an idempotent query for this. And then it can turn out as in the picture:

Of course, the use of idempotent PUT raises its own problems - in particular, how to resolve conflicts. It is necessary to program more, but the result will be more reliable and safe.
8. PUT can be used both to create new resources and to update old ones. However, if PUT is used for rewriting, it is assumed that the entire encoded resource is transferred in the request body. If you want to modify a resource, i.e. change its internal representation without complete rewriting, then the PATCH method was invented for this. This method is non-cacheable, insecure, and nonidempotent.
9. Response codes are needed first of all so that the client can understand what to do next. 3xx says that for the successful execution of the request you need to perform an additional action. 4xx says that the client, while making the request, did something wrong and, usually, that it was useless to beg, the repeated execution of the request would still throw out the error. In 4xx it is highly recommended to include information about what exactly the client did wrong. 5xx says that the client did everything correctly - the problem is on the server side.
Usually, if the operation is successful, the server responds to GET - 200, to PUT - 201 Created (if the resource is created) or 200 (the resource is updated), to DELETE - 204 (the operation is successful, there is nothing to return), to POST - 200 or 201 (in the second case in the header, usually Location, the URL of the created resource is indicated).
10. When working with HTTP statuses, do not step on a popular rake:
11. There is a special subclass of URLs that encode both the resource and the action on it. In English literature, they are called Capability URLs. A classic example of such a URL is links to password recovery, as well as all sorts of “secret” direct links to all sorts of resources.
12. Since the main danger when working with the URL Capability is the possibility of their leakage, you should as much as possible close the possibility of accidentally finding or intercepting such URL:
13. Measures to minimize potential damage should be provided:
the user who created the Capability URL (for example, a shared document) must be able to do the reverse operation, i.e. withdraw URL;
Capability URLs must fade with time; the more dangerous the access provided, the shorter the URL should be.
14. Finally, the “secret” pages themselves should be protected from merging data with third-party agents:
15. Everything described above exists in the standards only in the form of a recommendation, and it is impossible to force anyone to strictly implement these recommendations. It is not the first time I've been telling about all this trivia, and I often hear in response “yes, I wanted to spit on all this, I invented some unnecessary nonsense; as all services only worked on GET for me, they will continue, suffer with your PUTs and DELETEs themselves. ”
Of course, you are free to write your service yourself. But please keep in mind that between your server and your client, even if they are physically next to each other in one DC, there are a huge number of other network agents - browsers, proxies, routers, HTTP protocol implementations in different programming languages and different OS , DPI-equipment providers and so on. All of these agents, plus or minus, implement the HTTP protocol with an eye to the RFC.
If suddenly the client browser zaprefetchit GET-link and bang on the moon - it will be your fault, it is useless to write to the manufacturer. If your money is transferred by a GET request, and the implementation of the HTTP protocol in your programming language, without waiting for a response from a neighboring router, decides to repeat the request and conducts the transaction twice - this will again be your fault.
But even this is not important. Let's say your HTTP packages are walking in a strictly controlled environment. How are you going to explain to other developers what recommendations you have broken and why? How should your colleague understand that this GET request cannot be repeated, and the status 400 does not mean a client error at all? Departing from the recommendations, you, in fact, each time create some kind of your own HTTP dialect with its own semantics. Do not forget to document it at least;)
Bibliography:
(Your obedient servant took a certain part in the development of the last document.)
Below the cat you will find 15 items describing the proper organization of resources available via HTTP protocol - web sites, backend “handles”, API and so on. “Correct” here means “compliant with recommendations and specifications”. Most of the written below is almost literally translated from the official standards, recommendations and best practices from the IETF and W3C.
')
You will not find absolutely nothing obvious here. No, seriously, every web developer, theoretically, these 15 points should be mastered somewhere in the junior area of a developer and / or second or third year university.
However, in practice it turns out that a great many web developers have not yet learned these basics. You read the documentation for other APIs and weep. I am sure that every reader will still find something new for himself in this list.
1. URL identifies the resource - some shared entity. File is a resource. A pen that is looking for something is a resource. Calling a method is not a resource. If you want to shake the cannon across the moon, then don't do this:
GET /?method=&to= Get a resource "sharahalka", and then everything will be logical:
POST //?to= Why POST, not GET? Read below.
2. A URL consists of a schema (protocol), a host, a path (path), a query (query), and a fragment. The path is used to organize hierarchical resources, the query is used for non-hierarchical resources and for operation parameters. The fragment identifies a subordinate resource that does not have a direct URL.
Scheme Host Path Query Fragment ↓ ↓ ↓ ↓ ↓ http://nyashnye-kotiki.xxx/breeds/maine-coon/?deliver_to=Moscow#photo
If your site "Nyashnye Seals" has a catalog by breed, then it is quite logical to organize it as part of the path, since each cat belongs to exactly one breed. But you can deliver one cat in several cities, so the filter “with delivery to the city N” should be organized through a query.
3. An HTTP call consists of applying a method (verb) to a URL. The result of this application should be a surprise surprise! - what is written in the verb. That is, GET returns a resource representation, DELETE deletes, and so on.
4. GET, HEAD, OPTIONS methods are safe. It is assumed that calling these methods does not change the state of the resource. Therefore, many network agents - such as, for example, the prefetcher of links in the browser or instant messenger - consider themselves entitled to follow such links without the explicit will of the user. IChH, do not violate any standards.
5. By default, the GET and HEAD methods are cached, OPTIONS, POST, PUT, PATCH, DELETE are not. Therefore, if you hit the moon using the POST method, you can be (almost) sure that this request will be executed. If you shy away with the GET method, some intermediate proxy may SUDDENLY give you a response from the cache, and the balls will not happen in reality.
6. GET, PUT, DELETE operations are symmetrical. PUT puts something on the URL (by creating a new resource or overwriting the old one), GET on this URL returns the idea of what the PUT put, DELETE deletes the resource.
The HEAD method is synonymous for the GET method, but does not return the response body, but only its headers (meta information about the resource).
7. POST is used if you do not have a URL to which you want to apply the operation. For example, if a user writes a new message to a forum thread, he can calculate his id and do it himself:
PUT /threads/php-rulezz/messages/100500 If a client is not allowed to generate an id, he will have to make a POST to a resource higher in the hierarchy:
POST /threads/php-rulezz/messages And this resource itself will create a new message.
Note, if you repeat the POST request by mistake or due to network problems, a second message will be created in the thread that is identical to the first one. PUT you can do at least 100,500 times, the result will not change. This property is called idempotency.
Okay, creating posts on the forum. Now, if you are doing a heavy and expensive operation on a user request, it is highly recommended to perform an idempotent query for this. And then it can turn out as in the picture:
Of course, the use of idempotent PUT raises its own problems - in particular, how to resolve conflicts. It is necessary to program more, but the result will be more reliable and safe.
8. PUT can be used both to create new resources and to update old ones. However, if PUT is used for rewriting, it is assumed that the entire encoded resource is transferred in the request body. If you want to modify a resource, i.e. change its internal representation without complete rewriting, then the PATCH method was invented for this. This method is non-cacheable, insecure, and nonidempotent.
9. Response codes are needed first of all so that the client can understand what to do next. 3xx says that for the successful execution of the request you need to perform an additional action. 4xx says that the client, while making the request, did something wrong and, usually, that it was useless to beg, the repeated execution of the request would still throw out the error. In 4xx it is highly recommended to include information about what exactly the client did wrong. 5xx says that the client did everything correctly - the problem is on the server side.
Usually, if the operation is successful, the server responds to GET - 200, to PUT - 201 Created (if the resource is created) or 200 (the resource is updated), to DELETE - 204 (the operation is successful, there is nothing to return), to POST - 200 or 201 (in the second case in the header, usually Location, the URL of the created resource is indicated).
10. When working with HTTP statuses, do not step on a popular rake:
- Unauthorized status 401 must be accompanied by a WWW-Authenticate header and, thus, is applicable only when the client is authenticated via HTTP authentication; in all other cases, use 403 Forbidden;
- 3xx statuses are not only redirects; they indicate that the client must perform an additional action, otherwise the request cannot be considered successful; for example, according to the 304 Not Modified status, the client must retrieve the current version of the resource from the cache;
- 404 status, oddly enough, one of the few 4xx statuses that the client has the right to repeat - it means that the resource is not there now, but it is quite possible that it will appear; in general, 404 is an uncertainty status that is used if the server does not want to disclose the mechanics of the error; in order to indicate to the client that the resource will not appear without additional actions on his part, you should use 410 Gone (the resource has been deleted) or the general status 400.
11. There is a special subclass of URLs that encode both the resource and the action on it. In English literature, they are called Capability URLs. A classic example of such a URL is links to password recovery, as well as all sorts of “secret” direct links to all sorts of resources.
12. Since the main danger when working with the URL Capability is the possibility of their leakage, you should as much as possible close the possibility of accidentally finding or intercepting such URL:
- to generate secret parts of the URL, a strong random string generator should be used (for example, UUID 4 ), which excludes the possibility of finding the Capability URL by enumeration; of course, the URL should not be generated in a deterministic way like md5 (username) and such URLs should not be passed through link shorteners;
- Capability URLs should work only on HTTPS;
- pages accessible via the URL Capability must be closed by wildcard from being indexed by robots.
13. Measures to minimize potential damage should be provided:
the user who created the Capability URL (for example, a shared document) must be able to do the reverse operation, i.e. withdraw URL;
Capability URLs must fade with time; the more dangerous the access provided, the shorter the URL should be.
14. Finally, the “secret” pages themselves should be protected from merging data with third-party agents:
- there should not be any third-party scripts and pictures on them, preferably at the CSP level;
- they should not be links to third-party sites; if they are necessary, then you need to hide referrer, for example, via rel = "noreferrer";
- in general it is desirable to set up referrer policy to hide the Referrer Policy;
- preferably immediately after the user logs in through the History API, change the URL in the address bar of the browser so that it cannot be peeped over his shoulder;
- if the link implies some action (for example, changing the password), then on the secret page there must be a form (button, script) that needs to be sent to perform the action, and this form must be signed by a CSRF token (otherwise the browser / mail prefetcher client / messenger will be able to recover the password for the user).
15. Everything described above exists in the standards only in the form of a recommendation, and it is impossible to force anyone to strictly implement these recommendations. It is not the first time I've been telling about all this trivia, and I often hear in response “yes, I wanted to spit on all this, I invented some unnecessary nonsense; as all services only worked on GET for me, they will continue, suffer with your PUTs and DELETEs themselves. ”
Of course, you are free to write your service yourself. But please keep in mind that between your server and your client, even if they are physically next to each other in one DC, there are a huge number of other network agents - browsers, proxies, routers, HTTP protocol implementations in different programming languages and different OS , DPI-equipment providers and so on. All of these agents, plus or minus, implement the HTTP protocol with an eye to the RFC.
If suddenly the client browser zaprefetchit GET-link and bang on the moon - it will be your fault, it is useless to write to the manufacturer. If your money is transferred by a GET request, and the implementation of the HTTP protocol in your programming language, without waiting for a response from a neighboring router, decides to repeat the request and conducts the transaction twice - this will again be your fault.
But even this is not important. Let's say your HTTP packages are walking in a strictly controlled environment. How are you going to explain to other developers what recommendations you have broken and why? How should your colleague understand that this GET request cannot be repeated, and the status 400 does not mean a client error at all? Departing from the recommendations, you, in fact, each time create some kind of your own HTTP dialect with its own semantics. Do not forget to document it at least;)
Bibliography:
- www.rfc-editor.org/rfc/rfc2616.txt
- tools.ietf.org/html/rfc5789
- www.w3.org/TR/webarch
- w3ctag.imtqy.com/capability-urls
(Your obedient servant took a certain part in the development of the last document.)
Source: https://habr.com/ru/post/265569/
All Articles