Primary key - GUID or autoincrement?
Often, when developers are faced with the creation of a data model, the type of the primary key is chosen "out of habit", and most often it is an auto-incrementing integer field. But in reality, this is not always the optimal solution, since for some situations a GUID may be preferable. In practice, other, more rare, key types are possible, but in this article we will not consider them.
The following are the advantages of each of the options.
Auto increment
GUID
The phrase “theoretically faster generation of a new value” sounds unconvincing. Such considerations are always better supported by practical examples. But before writing a program for testing, consider what options for the implementation of the primary key are with each of these two types.
')
GUID can be generated both on the client and the database itself - already two options. In addition, MS SQL has two functions for obtaining a unique identifier - NEWID and NEWSEQUENTIALID. Let's see what is the difference between them and whether it can be significant in practice.
The usual generation of unique identifiers in the same .NET through Guid.NewGuid () gives a set of values that are not related to each other by any regularity. If a series of GUIDs obtained from this function are kept in a sorted list, then each new value added can “fall” into any part of it. The NEWID () function in MS SQL works in a similar way - a number of its values are rather chaotic. In turn, NEWSEQUENTIALID () gives the same unique identifiers, only each new value of this function is greater than the previous one, while the identifier remains “globally unique”.
If you use the Entity Framework Code First, and declare the primary key in this way
A table with a primary cluster key will be created in the database, which has the default value NEWSEQUENTIALID (). This is done for performance reasons. Again, in theory, inserting a new value into the middle of the list is more costly than adding to the end. The database, of course, is not an array in memory, and inserting a new record into the middle of the list of strings will not result in a physical shift of all subsequent ones. However, additional overhead will be - page splitting. The result will also be a strong index fragmentation, which may affect the performance of the data sample. A good explanation of how data is inserted into a clustered table can be found in the forum responses to this link .
Thus, for a GUID, we have 4 options that should be analyzed in terms of performance: a sequential and non-sequential GUID with generation on the client, and the same pair of options, but with generation on the base side. The question remains, how to get consistent GUIDs on the client? Unfortunately, there is no standard function in .NET for this purpose, but it can be done using P / Invoke:
Please note that without a special permutation of bytes, the GUID cannot be returned. The identifiers will turn out to be correct, but from the point of view of the SQL server, they are inconsistent, therefore, theoretically, there will not be any gain in comparison with the “ordinary” GUID. Unfortunately, the erroneous code is given in many sources.
It remains to add the fifth option to the list - the auto-increment primary key. He has no other options, as it’s not possible to generate it on the client.
We have decided on the variants, but there is one more parameter that should be taken into account when writing a test - the physical size of the rows of the table. The data page size in MS SQL is 8 kilobytes. Records of close or even larger size may show a greater performance spread for each of the key options than an order of magnitude smaller records. To provide the ability to vary the size of the record, it is enough to add a field to each of the test tables of the NVARCHAR, which is then filled with the required number of characters (one character in the NVARCHAR field takes 2 bytes).
This link contains a project with a program that was developed taking into account the above considerations.
Below are the results of tests that were performed according to this scheme:
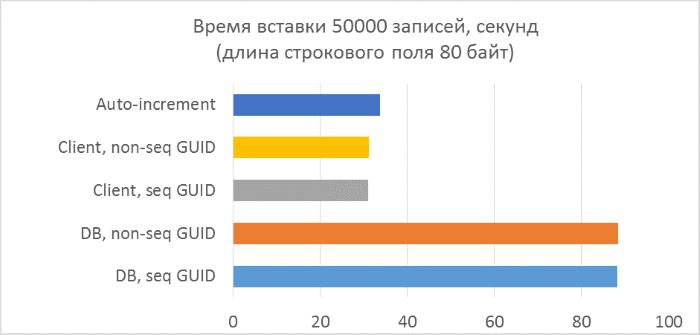
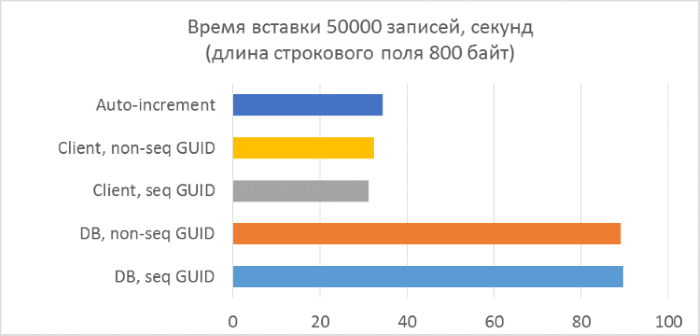
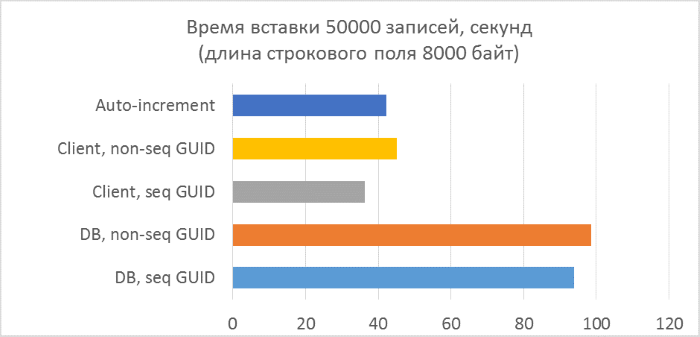
And the results are broken down by each launch:
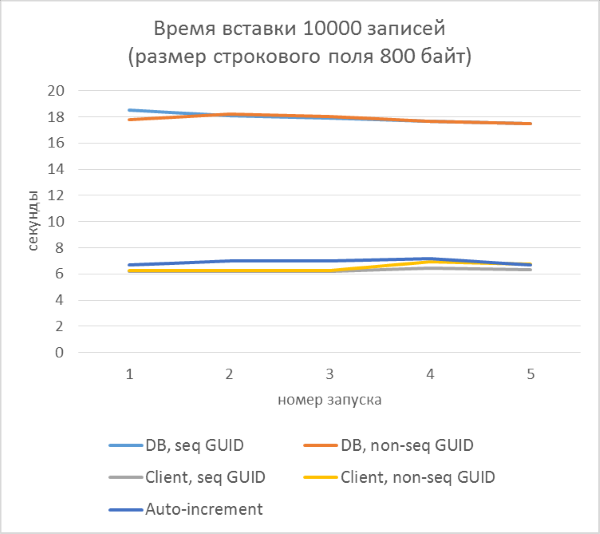
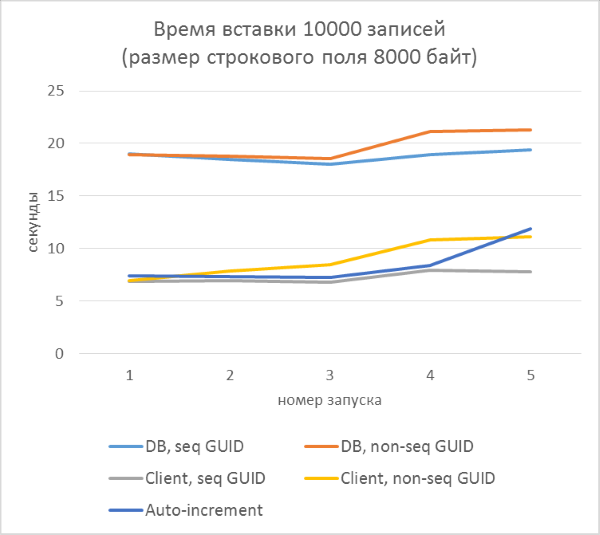
The results immediately show that:
Above the last point is worth considering. What can cause slowdowns when using non-sequential GUIDs, except for the frequent separation of pages? Most likely - due to the frequent reading of "random" pages from the disk. When using a sequential GUID, the desired page will always be in memory, as the addition only goes to the end of the index. With inconsistent there will be many inserts in arbitrary places of the index, and not in all cases the necessary pages will be in memory. To test how much this random reading affects the test results, we artificially limit the memory capacity of SQL Server so that no table can fit in memory completely.
A rough calculation shows that in a test with a line length of 4000 characters (8000 bytes) with the number of records 50,000 thousand, the size of the table will be at least 400 MB. Limit the allowable SQL Server memory to 256MB and repeat this test.
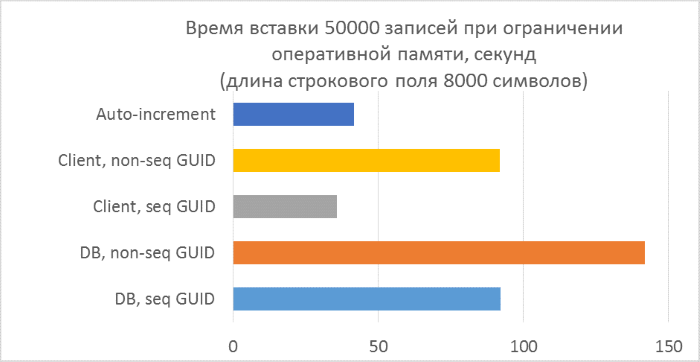
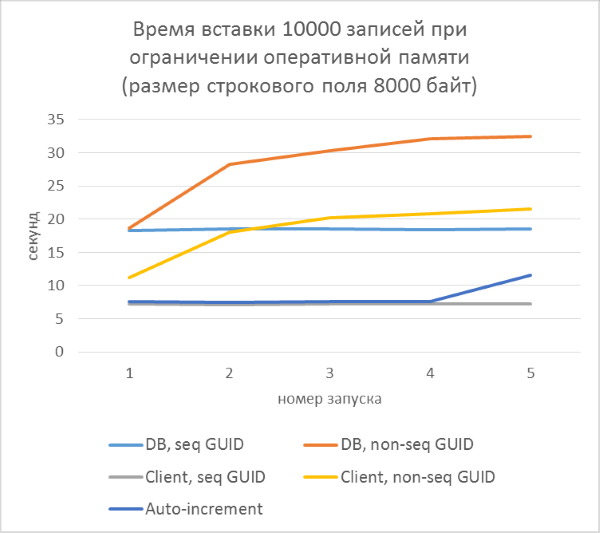
As one would expect, insertion into tables with inconsistent GUIDs in keys has noticeably slowed down, and the slowdown increases with the number of rows in the table. At the same time, insert performance for sequential GUIDs and auto-increment remains stable.
When the Entity Framework inserts into a table with an auto-increment key, the SQL commands look something like this:
In the case of a server-side GUID, we get a more complex option:
Thus, in order for the client to get the key of the newly added row, a table variable is created in which the key value is entered upon insertion, and then a sample is returned from this table variable to return the received value to the client.
A brief test shows that such a set of commands runs on average almost three times slower than just an INSERT on the same table. In the case of auto-increment, no additional table variables are used, therefore the overhead projector is smaller.
The following are the advantages of each of the options.
Auto increment
- Takes a smaller volume
- Theoretically, faster generation of new value
- Faster deserialization
- It is easier to operate when debugging, supporting, since the number is much easier to remember
GUID
- When replicating between multiple instances of the database, where the addition of new records occurs in more than one replica, the GUID guarantees no collisions.
- Allows you to generate a record ID on the client, before saving it to the database
- The generalization of the first item - ensures the uniqueness of identifiers not only within the same table, which may be important for some decisions
- It makes it almost impossible to “guess” the key in cases where the record can be obtained by passing its identifier to some public API
The phrase “theoretically faster generation of a new value” sounds unconvincing. Such considerations are always better supported by practical examples. But before writing a program for testing, consider what options for the implementation of the primary key are with each of these two types.
')
GUID can be generated both on the client and the database itself - already two options. In addition, MS SQL has two functions for obtaining a unique identifier - NEWID and NEWSEQUENTIALID. Let's see what is the difference between them and whether it can be significant in practice.
The usual generation of unique identifiers in the same .NET through Guid.NewGuid () gives a set of values that are not related to each other by any regularity. If a series of GUIDs obtained from this function are kept in a sorted list, then each new value added can “fall” into any part of it. The NEWID () function in MS SQL works in a similar way - a number of its values are rather chaotic. In turn, NEWSEQUENTIALID () gives the same unique identifiers, only each new value of this function is greater than the previous one, while the identifier remains “globally unique”.
If you use the Entity Framework Code First, and declare the primary key in this way
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)] public Guid Id { get; set; } A table with a primary cluster key will be created in the database, which has the default value NEWSEQUENTIALID (). This is done for performance reasons. Again, in theory, inserting a new value into the middle of the list is more costly than adding to the end. The database, of course, is not an array in memory, and inserting a new record into the middle of the list of strings will not result in a physical shift of all subsequent ones. However, additional overhead will be - page splitting. The result will also be a strong index fragmentation, which may affect the performance of the data sample. A good explanation of how data is inserted into a clustered table can be found in the forum responses to this link .
Thus, for a GUID, we have 4 options that should be analyzed in terms of performance: a sequential and non-sequential GUID with generation on the client, and the same pair of options, but with generation on the base side. The question remains, how to get consistent GUIDs on the client? Unfortunately, there is no standard function in .NET for this purpose, but it can be done using P / Invoke:
internal static class SequentialGuidUtils { public static Guid CreateGuid() { Guid guid; int result = NativeMethods.UuidCreateSequential(out guid); if (result == 0) { var bytes = guid.ToByteArray(); var indexes = new int[] { 3, 2, 1, 0, 5, 4, 7, 6, 8, 9, 10, 11, 12, 13, 14, 15 }; return new Guid(indexes.Select(i => bytes[i]).ToArray()); } else throw new Exception("Error generating sequential GUID"); } } internal static class NativeMethods { [DllImport("rpcrt4.dll", SetLastError = true)] public static extern int UuidCreateSequential(out Guid guid); } Please note that without a special permutation of bytes, the GUID cannot be returned. The identifiers will turn out to be correct, but from the point of view of the SQL server, they are inconsistent, therefore, theoretically, there will not be any gain in comparison with the “ordinary” GUID. Unfortunately, the erroneous code is given in many sources.
It remains to add the fifth option to the list - the auto-increment primary key. He has no other options, as it’s not possible to generate it on the client.
We have decided on the variants, but there is one more parameter that should be taken into account when writing a test - the physical size of the rows of the table. The data page size in MS SQL is 8 kilobytes. Records of close or even larger size may show a greater performance spread for each of the key options than an order of magnitude smaller records. To provide the ability to vary the size of the record, it is enough to add a field to each of the test tables of the NVARCHAR, which is then filled with the required number of characters (one character in the NVARCHAR field takes 2 bytes).
Testing
This link contains a project with a program that was developed taking into account the above considerations.
Below are the results of tests that were performed according to this scheme:
- There are only three test series with a text field length of 80, 800 and 8000 bytes, respectively (the number of characters in the test program will be two times less in each case, since one character in NVARCHAR takes two bytes).
- In each of the series - 5 launches, each of which adds 10,000 entries to each of the tables. According to the results of each of the launches, it will be possible to trace the dependence of the insertion time on the number of rows already in the table.
- Before the start of each series, the tables are completely cleared.
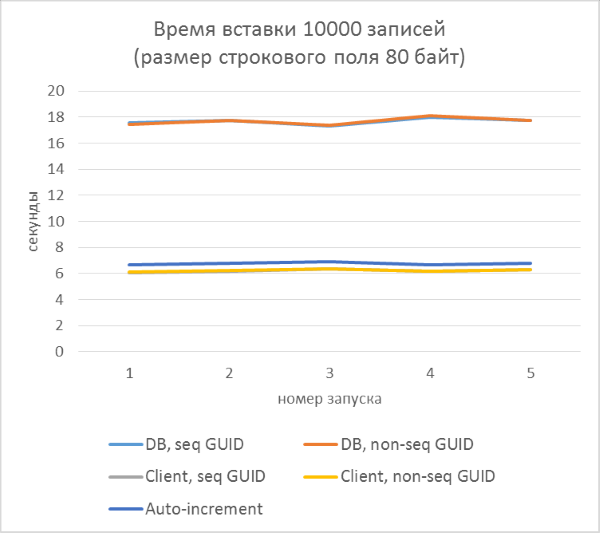
And the results are broken down by each launch:
The results immediately show that:
- Using GUID generation on the database side is much slower than generating on the client side. This is due to the cost of reading the identifier just added. Details of this problem are discussed at the end of the article.
- Inserting records with an auto-increment key is even slightly slower than with a GUID assigned to the client.
- The difference between a sequential and inconsistent GUID is almost invisible on small records. On large records, the difference appears with increasing number of rows in the table, but it does not look significant.
Above the last point is worth considering. What can cause slowdowns when using non-sequential GUIDs, except for the frequent separation of pages? Most likely - due to the frequent reading of "random" pages from the disk. When using a sequential GUID, the desired page will always be in memory, as the addition only goes to the end of the index. With inconsistent there will be many inserts in arbitrary places of the index, and not in all cases the necessary pages will be in memory. To test how much this random reading affects the test results, we artificially limit the memory capacity of SQL Server so that no table can fit in memory completely.
A rough calculation shows that in a test with a line length of 4000 characters (8000 bytes) with the number of records 50,000 thousand, the size of the table will be at least 400 MB. Limit the allowable SQL Server memory to 256MB and repeat this test.
As one would expect, insertion into tables with inconsistent GUIDs in keys has noticeably slowed down, and the slowdown increases with the number of rows in the table. At the same time, insert performance for sequential GUIDs and auto-increment remains stable.
findings
- If, according to any criteria specified at the beginning of the article, you need to use the GUID as the primary key - the best option in terms of performance would be a sequential GUID generated for each entry on the client.
- If creating a GUID on a client is unacceptable for any reason, you can use the generation of an identifier on the base side using NEWSEQUENTIALID (). The Entity Framework does this by default for the GUID of keys generated on the base side. But it should be noted that insertion performance will be noticeably lower compared to creating an identifier on the client side. For projects where the number of inserts in the tables is small, this difference will not be critical. Still, most likely, this overhead head can be avoided in scenarios where it is not necessary to immediately obtain the identifier of the inserted record, but such a solution will not be universal.
- If your project already uses inconsistent GUIDs, then you should think about the correction, if the number of inserts into the tables is large and the size of the database is much larger than the size of the available RAM.
- Other DBMS performance differences may be completely different, so the results can be viewed only in relation to Microsoft SQL Server. At the same time, the basic criteria indicated at the beginning of the article are valid regardless of the specific DBMS.
UPD: Why the option to generate a GUID key on the database side is slow
When the Entity Framework inserts into a table with an auto-increment key, the SQL commands look something like this:
INSERT [dbo].[AutoIncrementIntKeyEntities]([Name], [Count]) VALUES (@0, @1) SELECT [Id] FROM [dbo].[AutoIncrementIntKeyEntities] WHERE @@ROWCOUNT > 0 AND [Id] = scope_identity() In the case of a server-side GUID, we get a more complex option:
DECLARE @generated_keys table([Id] uniqueidentifier) INSERT [dbo].[GuidKeyDbNonSequentialEntities]([Name], [Count]) OUTPUT inserted.[Id] INTO @generated_keys VALUES (@name, @count) SELECT t.[Id] FROM @generated_keys AS g JOIN [dbo].[GuidKeyDbNonSequentialEntities] AS t ON g.[Id] = t.[Id] WHERE @@ROWCOUNT > 0 Thus, in order for the client to get the key of the newly added row, a table variable is created in which the key value is entered upon insertion, and then a sample is returned from this table variable to return the received value to the client.
A brief test shows that such a set of commands runs on average almost three times slower than just an INSERT on the same table. In the case of auto-increment, no additional table variables are used, therefore the overhead projector is smaller.
Source: https://habr.com/ru/post/265437/
All Articles