New Free Intel® DAAL Data Analytics Library

The first official release of Intel's new data analytics library, the Intel Data Analytics Acceleration Library , has been released today. The library is available as part of Parallel Studio XE packages, as well as an independent product with a commercial and free (community) license. What kind of animal is it and why is it needed? Let's figure it out.
Where is Intel DAAL?
To date, there is a whole science of data (data science), which studies the problems of processing, analyzing and presenting data. It includes many different areas, such as statistical methods, data mining methods, machine learning, pattern recognition theory, artificial intelligence applications (AI), and so on.

Moreover, all these areas of research have quite a lot of intersections, but there are also differences. So, statistics is based on a theory more than data mining, and focuses on testing hypotheses. Machine learning is more heuristic and concentrates on improving the performance of learning agents. And data mining represents the integration of theory and heuristics, concentrating on a single data analysis process, including data cleansing, training, integration and visualization of results. The Intel DAAL library will be of interest to everyone who is related to the science of data and its fields.
Data mining methods have their own standards, the most common of which is a cross-industry standard for data mining CRISP-DM (Cross Industry Standard Process for Data Mining). According to this standard, the data analysis process is iterative and includes 6 stages: business understanding, data understanding, data preparation, modeling (modeling), evaluation (evaluation), implementation ( deployment).
')
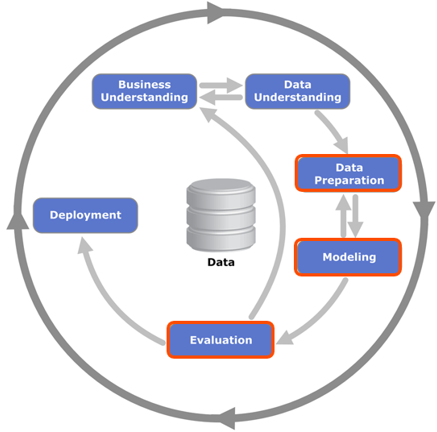
The DAAL library is intended mainly for the data preparation, modeling and evaluation of results, if we talk about the presentation of data mining methods within this standard. At the same time, it is optimized using the algorithms of the Intel Math Kernel Library and the Intel Integrated Performance Primitives.
Problems and Solutions
Why exactly DAAL and what this library should be liked by developers?
In the field of data analytics, there is now a huge amount of various technologies and tools. This is quite natural, given the growth rate of this industry:
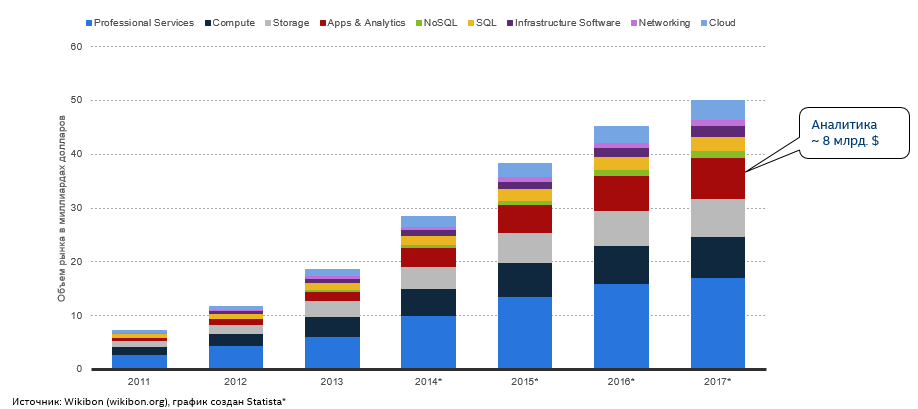
Interesting statistics from Wikibon: by 2017, the volume of the big data market will be about 50 billion American presidents, of which 8 are software and analytics.
The storage of data obtained from a large number of different sources is realized both by the means of traditional relational DBMS with data access by means of the SQL language, and not by traditional NoSQL (not only SQL). In addition, data can be immediately located in memory. To handle this data, large frameworks such as Hadoop, Spark, Cassandra and so on are now used.
There is one big problem with current solutions, namely performance. Consider as an example the open source framework Spark, more precisely the library of machine learning Spark MLLib.
Spark MLLib is written using the Scala language and uses another opensource package of linear algebra Breeze, which depends on Netlib-Java, which is a wrapper for Netlib for Java. In summary, Netlib BLAS is used, the implementation of which is usually consistent and not optimized. Obviously, we have the problem of too many dependencies, "layering" and poor performance.
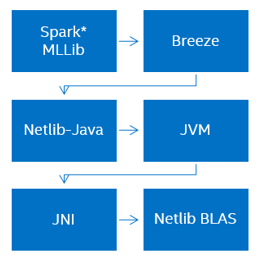
Intel's idea is to create a single library for work at all stages of data analytics, excluding such multi-layer implementations, while optimizing it for hardware:

Using this solution should give us a significant performance boost. If we compare the implementation of Intel DAAL with the same Spark MLlib using the example of using the principal component analysis method (PCA), the resulting acceleration can be 4 to 7 times, depending on the size of the data table:

Main components
Intel DAAL supports C ++ and Java, as well as Windows, Linux and OS X. It can be used with any platforms, such as Hadoop, Spark, R, Matlab and others, but is not tied to any of them. In addition, there is support for local and distributed data sources, including CSV in files and in memory, MySQL, HDFS, and Resilient Distributed Dataset (RDD) objects from Apache Spark *.
The library consists of three main components: Data Management, Algorithms and Services.
Data management
This includes classes and utilities for data acquisition, primary processing and normalization, as well as their conversion into numerical format. DAAL algorithms work with data in a special form - data tables. Therefore, the very first step in working with the library will be the conversion of data into these very tables.
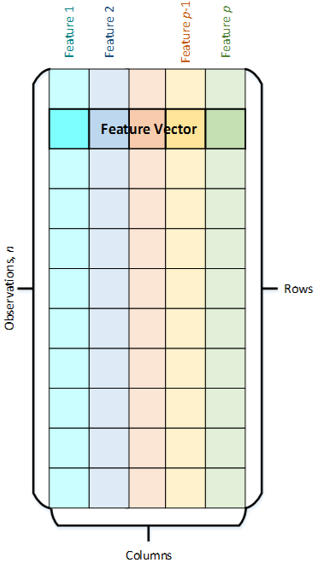
What are they like? Each object is characterized by a set of attributes (Features) - properties that characterize the object. For example, eye color, age, water temperature and so on. A set of attributes forms a vector of properties (Feature Vector) of size p. These vectors in turn form a set of observations (Observations) of size n. In DAAL, data is stored in the form of tables, in which the rows are observations (Observations) and the columns are properties (Features).
Algorithms
Algorithms consist of classes that implement data analysis and modeling. These include decomposition, clustering, classification and regression algorithms, as well as associative rules.
Algorithms can be executed in the following modes:
- Batch processing
Algorithms work with the entire data set at once and give the result. All library algorithms support this mode. - Online processing (online processing)
There are more complex cases in which all data is not immediately available in its entirety, or, for example, does not fit into memory. In this case, a mode can be used in which work with data occurs in blocks that are loaded into memory gradually. Not all library algorithms have an online implementation. - Distributed processing (distributed processing)
Data is distributed across multiple compute nodes. The intermediate result is calculated on each node, which are eventually combined on the main node. Just as in the case of online processing, not all library algorithms have a distributed implementation, but Intel engineers are working on it.
Services
Services contain classes and tools used in algorithms and data management. These include various classes for memory allocation, error handling, collection implementation, and general pointers.
Total
The Intel DAAL library has many different features, and it’s impossible to talk about them in one post. I just showed why it is needed, for what purpose it appeared on the market and considered its main components. I would like to hear the questions and comments of those who find this question interesting and continue the conversation about this interesting library. Plans to talk about DAAL algorithms, as well as show examples of code using it.
I note that today Intel DAAL is the only data analytics library optimized for Intel architecture.
Source: https://habr.com/ru/post/265347/
All Articles