ACM SIGIR 2015: Key Trends in the Development of Search Technologies


From August 9 to 13, the 38th International Scientific Conference on Information Retrieval ACM SIGIR was held in Santiago (Chile). We present to your attention the main events of this event and key trends in the development of the field of information retrieval, both in terms of the academic environment and industry.
ACM SIGIR is the main scientific forum of the year in which the leading researchers in the field of information retrieval present their results. All scientific papers undergo a rigorous competitive selection as part of the traditional review process (in this case, double blind, that is, authors and reviewers must observe anonymity). The conference was traditionally sponsored by the largest search engines and other companies interested in developing search technologies: Baidu, Microsoft, Google, Yahoo, eBay, Facebook, IBM, Yandex.
')
Location
The conference was held in the capital of Chile, Santiago, in the building of the Catholic University. The choice of such an exotic venue was due to the presence of a Yahoo! affiliate here. Labs, as well as the status of its head - the famous Chilean explorer Ricardo Baeza-Yeats .

Santiago is a city of contrasts: along with beautiful historical buildings, you can easily find antediluvian high-rises in the city center. Frequent earthquakes are a possible excuse for lacking style. There are in the capital and very disadvantaged areas in which there is a high risk of being robbed. Because of its natural features (the city is located in a valley surrounded by a mountain range), smog is a common occurrence in Santiago. Basic communication is necessary for comfortable communication, as knowledge of English is completely lacking. In souvenir shops - a wild hodgepodge of Indian attributes, moai figurines from Easter Island, portraits of communist Allende and Christian symbols. People are friendly and friendly. In general, does not leave the feeling that you are in a typical Latin America, sometimes charming, sometimes not very.

Tutorials
The conference opened nine short training courses on various topics of information retrieval. Quite interesting was the tutorial on long search queries ( Information Retrieval with Verbose Queries ), read by Manish Gupta (Bing) and Michael Bendersky (Google). The tutorial presented approaches to resolving long queries, which, as a rule, lead to null queries. These requests are not uncommon in question-answer systems (including CQA services, such as Quora or Responses@Mail.ru), enterprise search, e-commerce search, voice search applications (Cortana, Siri, Google Now).
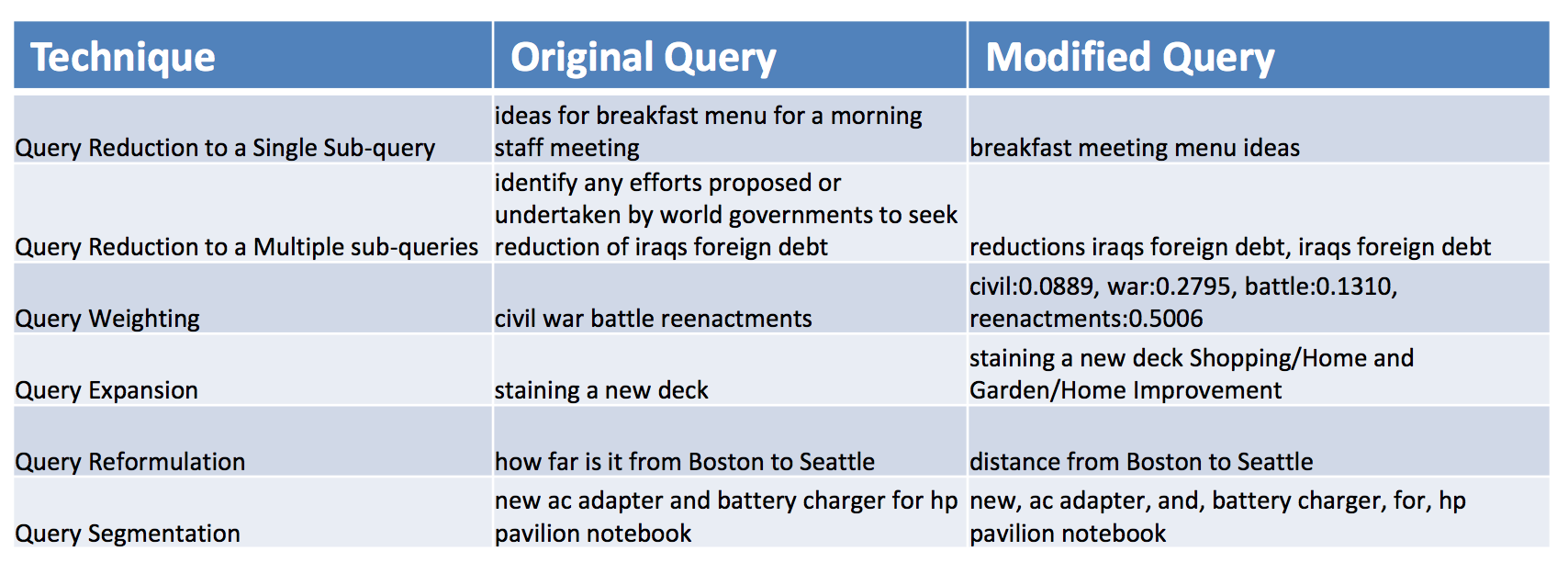
According to the authors of the tutorial, the main approaches include the following techniques:
- query reduction (reduction reduction) by reducing to one or more subqueries by: selecting individual words, combinations, nominal groups, named entities, words from personal logs of queries
- weighting of some terms or concepts (see WSD model)
- query expansion (see PCE model)
- request reformulation: based on probabilistic language models and query logs
- query segmentation: based on n-gram statistics.
Main program
The next three days were devoted to the reports of the main program of the conference. This year, the level of acceptance of articles in the main program was 20%, that is, every fifth article from those sent for review was adopted. This is the usual level for A + class conferences ( CORE rated).
By the way, the sponsors paid for free access to the full text of the articles , and anyone can get acquainted with the accepted works. As usual, there were a lot of high-quality articles, so in this review I’ll talk only about articles that received awards, and separately - in the deep learning section.

The prize for the best article was received by a team of scientists from ISTI – CNR, universities of Pisa and Venice. They proposed a QuickScorer algorithm that uses a special binary representation for trees and bitwise logical operations and, as a result, accelerates (in practice by more than 50%) the use of trained additive ensembles of regression trees. This is an important achievement, given the practical power of such models as the Lambda-MART and the Gradient Boosted Regression Trees (GBRT). The latest model, as you know, is the basis of Yandex MatrixNet.
The next prize is that nice! - went to Russia. The prize for the best article written by a student (Best Student Paper Award) was received by a team of authors from Yandex headed by Yevgeny Kharitonov (Yevgeny is a graduate student of the University of Glasgow and a staff member of Yandex). This work shows how to conduct experiments on the comparative assessment of the quality of a search in a short time using the apparatus of statistical tests. The approach is applicable both for A / B testing and for interleaving.
Finally, we will focus on a section devoted to such a trend nowadays as the application of deep neural networks (deep learning). It is worth noting that the breakthrough performance improvements achieved with the help of deep learning models objectively take place only in the areas of image recognition and speech, but the success of deep learning in natural language processing and information retrieval is still less convincing. At the same time, one of the main advantages of deep learning - getting rid of manual modeling of effective characteristics for data representation (feature engineering) - forces one to pay attention to these approaches both in search and in NLP. Moreover, as the following work shows, the improvements in these areas are becoming more significant.
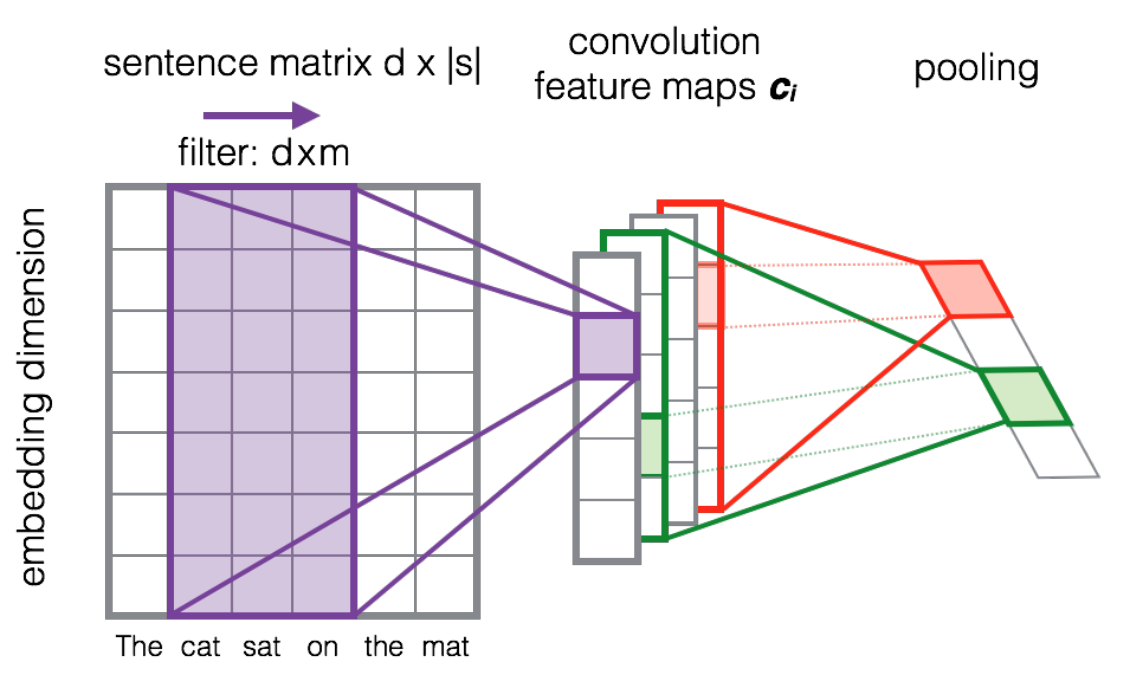
It turns out that convolutional neural nets, traditionally used for image recognition, received an unexpected development for word processing tasks (the first works appeared literally last year). They provide a way to represent the original sentences in a vector space of a smaller dimension while retaining syntactic and semantic characteristics. Thus, the input of the network (see figure) is the matrix composed of columns of vectors in the hidden space (embeddings) of words in the sentence. For the latter, you can take the word embeddings from word2vec . The next stage is the convolution of the matrix of sentences, i.e. the element-wise product of the vertical layers of the matrix of the sentence and the filtering matrix (in the case of deep learning, many filtering vectors are used) and aggregation of these results by summation. Further, the result is passed through a nonlinear activation function (in this case, ReLU). The pooling operation is the usual maximum.
Aliaxei Severin (Google) and Alessandro Moschitti (University of Trento, QCRI) in Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks showed how to extend this architecture for the task of ranking short texts in the question-answer system. In this case, both the request and the document are translated into a single representation (common vector), and the interactions of its components are modeled through an additional hidden layer in the neural network.
Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings show how to expand the word embeddings model in the case of leveled corps for the cross-language information retrieval task. Examples of such cases are Wikipedia articles in different languages. The main idea is to mix reference words and contexts from aligned documents for teaching the standard skip-gram model of Mikolov, which predicts the context of reference words in a sentence. The proposed relevance model is based on the cosine measure of proximity of the query vectors and documents, built on the principle of a linear combination of word embeddings.
A team of researchers from Yahoo! Labs proposed new word embeddings models adapted for the task of displaying advertisements in a sponsored search (the main problem is to match the advertisement with queries for which there is no exact match by the terms): context2vec, content2vec, context-content2vec. Context2vec uses the same skip-gram model, only requests are considered as words, and sentences are user sessions from search engine logs. In the case of content2vec, the authors return to a more traditional representation, when “words” are terms from the query, “sentences” are the query text. The latest model is a combination of these two. Examples of the models:
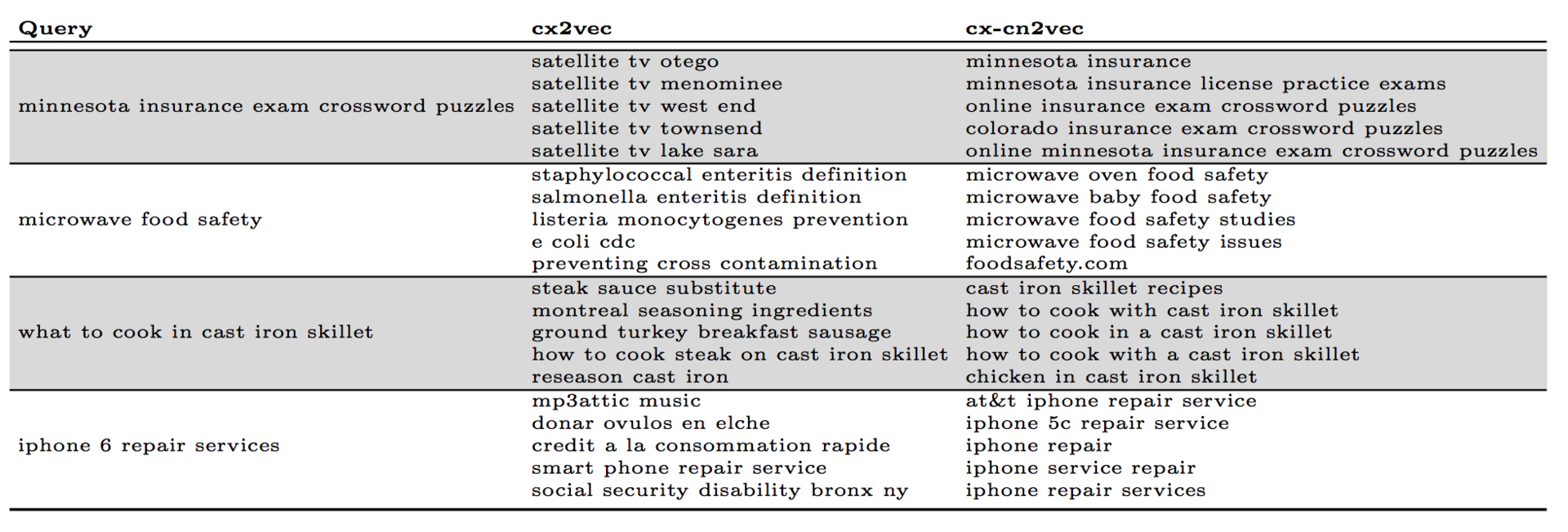
Finally, Guoying and Callan (Carnegie Mellon University) explored the use of word embeddings for the weighting of terms in classical models - language models, SDM and BM25. The shown increase in productivity is up to 9% (according to MAP) for BM25 and up to 22% for language models on standard TREC collections.
Of the tools used to implement deep neural networks, mostly use Theano for great flexibility. Torch is regarded as a higher-level library and is more suitable for the industry, although more difficult to customize.
Our scientific contribution
This is a joint work of a team of authors from Wayne University (USA), Kazan Federal University and Textocat . We presented a new ranking model for structured FSDM documents, which is a generalization of the well-known mixture model language (MLM) model that takes into account the weights of document fields, and the sequential dependence model (SDM) derived from Markov random field theory. The ranking formula is as follows:
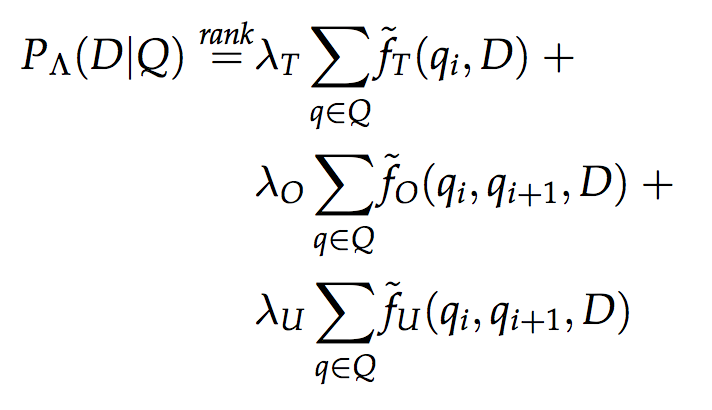
where the T mark is used to refer to terms that are consecutive to bigram (O) and bigram within the window (U) from the search query. And f - assessment of the appearance of terms (or bigram) from a query in a document based on a mixture of language models of document fields:
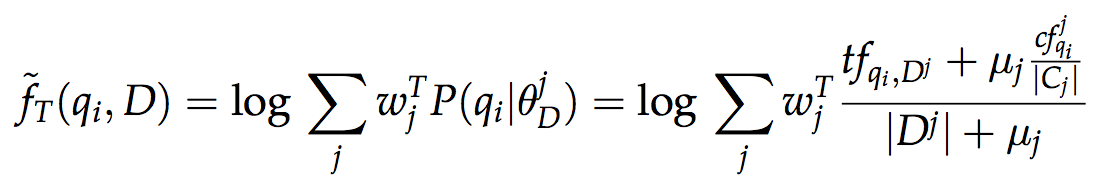
Model parameters (weights of fields w and weights λ) can be set manually (for example, in some document scheme of two fields: w (title) = 0.8, w (body) = 0.2, and standard weights for SDM: λ = (0.8, 0.1,0.1)), and in the presence of a training set, they can be trained with a simple two-step algorithm based on the coordinate ascent method, which optimizes directly the target measure of search quality evaluation (for example, MAP), as suggested in the article.
The new model has shown its effectiveness in the entity search scripts in the data web (including in comparison with the well-known model BM25F), and at the same time, its applicability extends to any search application on structured documents with several fields ( multi-fielded documents). Examples of such applications are email messages (header, letter body) and product descriptions in e-commerce (name, category, abstract, vendor). Open the full text of the article , the source code and launch files on GitHub and presentation slides .
Posters
Poster session is a separate interesting format for presenting results that have not yet been brought to the full article. And this year I can single out several memorable works at once. First of all, this is a continuation of the work of Karsten Ehoff (now - ETH, earlier - Delft University of Technology) on the use of copulas for information retrieval. In Modeling Term Dependence with Copulas, Carsten and his supervisor, Arjen de Vries, show that copulas can be effectively used to isolate dependencies in the appearance of terms in a document, which is useful in determining meaningful games from a search query. In addition, I will highlight the work of Twitter Sentiment Analysis with Deep Convolutional Neural Networks (mentioned Severin and Moschitti apply the considered convolutional neural networks to the problem of analyzing the tonality), Relevance-aware Filtering ranking by relevance when filtering by attribute is an important task for e-commerce search).
Industry
In the industrial track were reports from Microsoft on crowdsourcing and the use of geolocations in a commercial search; Yahoo on the difficulties of vertical search (news, e-commerce); Yandex on the aspects of online evaluation of search quality; Bloomberg on how the company applies natural language processing, machine learning ranking, crowdsourcing in the field of financial applications; Booking.com is about personalization when recommending travel destinations and LinkedIn about the search device in the largest professional social network.

Representatives of Microsoft Research demonstrated the capabilities of the Bing search engine on the contextualization of the search for entities (Microsoft has its own knowledge base - Satori) during a user session. The query chain looked like this: “Tom Cruise,” “Cruz Tom’s wife?”, “What is her height?” They also announced the WSDM Cup Challenge , a competition to assess the importance of scientific publications in the Microsoft Academic Graph column. The meaning of the problem is to offer more nontrivial characteristics than the usual number of quotes, using the available semantic information.
Conclusion
ACM SIGIR is becoming an increasingly industrial conference (this year 41% of articles from industry!). This has a significant impact on the distribution of research topics: there is a greater bias towards researching user behavior and evaluating the search. In addition, under the influence of the development of the theory and tools of deep learning, search models based on adapted word embeddings are becoming increasingly common. Finally, despite the development of knowledge bases (Wikidata, DBpedia, Freebase, Google Knowledge Graph, Satori, Facebook Graph), there is a shortage of work that offers new models of using knowledge bases to improve search quality.
Source: https://habr.com/ru/post/265113/
All Articles