Joint editing. Part 1
Good day. Last year I have been involved in the “MyOffice” project with joint editing (collaboration). Looking back, I can state that this is a difficult and very interesting task. Therefore, I would like to tell you in detail about her and give answers to the following questions:
In order to respond to them in detail and convincingly, it is necessary to write quite a lot of material, so there will be several articles, sit down comfortably, we begin.
As soon as we begin to store files on the server (in the cloud), there is a natural desire to ensure their editing by several people. This is especially true for office documents, on which several people work at once, and each of them makes edits.
')
But "you can not just take it and so ..." give everyone access to edit a single document. A mechanism is needed that will provide convenient and correct modification of a single file by several users. Let's look at options for how this can be done.
This is the most trivial method. The advantages of this solution are the ease of implementation and the ability to work with all types of data. This is where the advantages end and begin a continuous inconvenience for the user:
This option can often be found in solutions for corporate portals, ERP, EDS.
For a text document, a paragraph or a table can become such a unit of division. This improves the entire work process, namely:
But this approach cannot be called ideal:
Some readers may notice that the joint editing task is successfully solved in version control systems, with a consistent history (SVN or CVS) or with the possibility of branching (GIT, Mercurial). Yes, you are right, but there are some nuances that make it impossible to apply the same principle in our case:
We will proceed from the fact that, from the user's point of view, all work with the document should be reduced only to correct the text, insert the schedule promised to the colleagues, and finish there. Just as he did before with local documents. All complex processes to maintain the correct state of the document should be hidden from the user. At the same time, it is important to maintain responsiveness and functionality comparable to editing local files.
For us, this dictates additional requirements:
1. Use an optimistic change strategy. Edits should be applied immediately to a local copy of the document. And regardless of this, they are sent to the server, and from it to other clients, and how quickly they will be received and applied does not affect the speed of work with the local version.
It follows that the document status of the clients and on the server may differ. This forms the following requirement:
2. Convergence (convergence). When all users have finished their work and all notice of edits will be delivered, both on the server and the clients should have the same document state.
But that is not all. The first two requirements can be fulfilled with the help of a simple, but obviously unsuitable algorithm for users. If two competing changes come to the server, then you can simply ignore what came later, notifying clients accordingly. This will be enough to satisfy the first two requirements, but clearly not enough to make happy those whose changes have been thrown out. This means that you need to declare another requirement:
3. The principle of conservation intentions (intention preservation). We must ensure that the intentions of all users are maximally preserved, even if edits are made simultaneously and they compete with each other.
We declare that every edit from each of the users is important to us and we will not undo it unnecessarily. The need to cancel can still arise. For example, in such situations when one user edited a paragraph that was simultaneously deleted by someone else. In this case, the changes can no longer be applied, since the paragraph no longer exists.
The second point worth mentioning in the context of this principle is formalization. The concept of "intention" is rather abstract. Imagine that the text has the word "pharmacy", which is simultaneously corrected by two users, and in different ways: "pharmacy" and "optics". Most of the known algorithms (and ours too) work at the letter level, and the result is a “aptika”, which is not consistent with the “high-level” intentions of both authors. There are formalizations of users' intentions at the level of weak orders of letters (“I want to insert the letter“ and ”after the letter“ t ”, but before the“ k ””). For some algorithms, the preservation of intentions expressed in this way is an integral part of them (you can read about it here ).
In our case, we do not formalize the intentions of users and, moreover, do not give strict guarantees of their observance, but declare that we will adhere to this principle as much as possible.
There are two algorithms that meet all of our requirements: optimistic change, convergence and preservation of intentions.
The algorithm assumes a constant 3-way merge on the client and server side, which is accompanied by the sending of patches in both directions. The diagram shows the general idea.
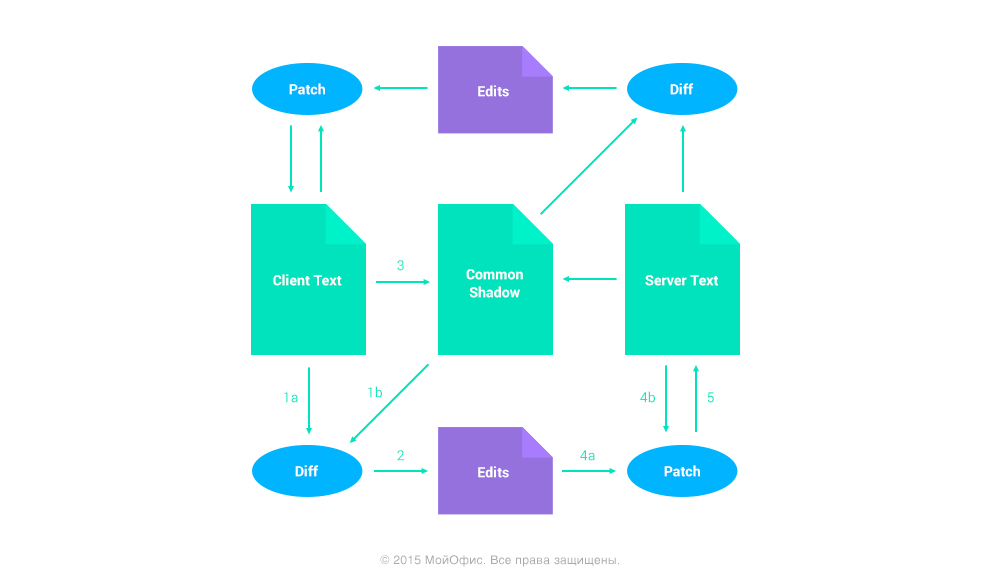
A more detailed description can be seen on the website of the author .
You probably already guessed why this algorithm does not suit us. Correctly, as already mentioned, a 3-way merge for a document with a complex structure is non-trivial. At the same time, it is necessary to have a formal guarantee that it will give the same results when merging in different orders and directions ... This puts an end to the prospect of applying this approach with us.
It is rather a general approach, on the basis of which various algorithms are developed.
OT is based on a fairly simple idea. We describe all data changes as operations that are sent and transformed relative to others without the document itself. When an operation comes from one user to another, we transform it so that it becomes valid regarding the difference between the documents of these two users, expressed in operations. It sounds abstruse, but in fact the principle is quite simple.
Let's look at another scheme that is popular in articles about OT.
Operation O2:
Operation O1:
Inclusion transformation is used here (exclusion transformation is used in some algorithms). In the future, I will use the designation Inc (O1, O2) for operation O1, taking into account the effects of operation O2, that is, briefly, we have included O2 in O1.
The basic requirement that inclusion transformations (known as Transition Property 1) must satisfy is:
Inc (O2, O1) * O1 = Inc (O1, O2) * O2,
where * is a sequential application, right to left. For ease of understanding, look at the image:
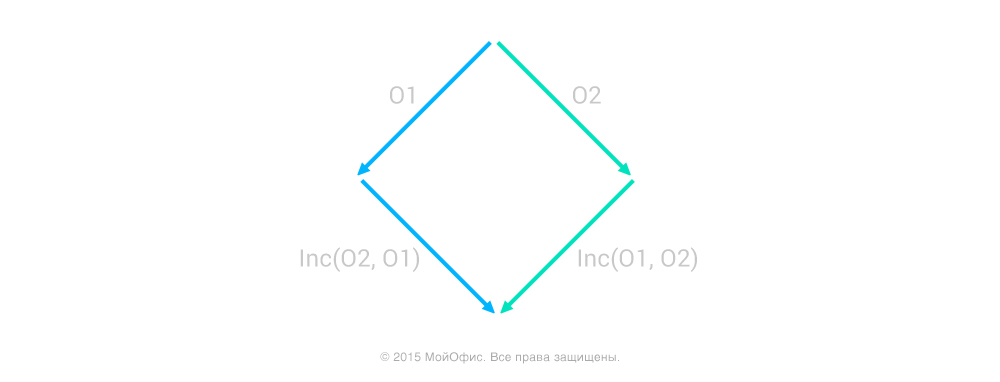
The above equality applied to this picture means that, starting from one document state and moving along the right or left branch, we get the same final state. The principal point is that we must begin the “movement” from the same state. If this condition is not met, the result will be the mismatched state of the documents or the transformed operation may simply not make sense. For example, inserting a character into an invalid or non-existent document position.
As I indicated above, there are several different OT-based algorithms. Their main difference is the solution of the key question: how to perform transformations so that any operations involved in the transformation are over the same state of the document, and if this is not possible, then what other transformations can be used to change the order of operations.
The fact is that the first OT-based algorithms did not provide for the use of a central server. All clients have contacted peer-to-peer. Accordingly, the current state of the document among users was expressed by the sequence of operations (O1, O2 ... N), while at each moment of time the number, composition and order of these operations can be different for each client. In this case, it is impossible to determine a single strict order among all the generated operations, you can enter only a weak order on what happens before the criterion. Operations between which there is no such relationship are considered competing or concurrent (concurrent).
This approach also brings with it certain difficulties:
Those interested in classic peer-to-peer algorithms can find a detailed review and comparison of them here .
The difficulties listed above can be resolved by abandoning the equality of all clients and peer-to-peer connections. When adding a central server, the state of the documents can be described by a simple revision and require no more than TP-1 execution ... But the next article will be devoted to this topic. I promise that for lovers of algorithms there will be more interesting.
The first article from the cycle, meanwhile, reached the final. I would be glad to see in the comments your questions and suggestions regarding the content of the following articles.
The second part can be found here .
Until!
- What are some approaches to collaborative editing?
- How difficult are they to implement?
- Can I take a ready-made library and use it in my project?
- Is it possible to develop without thinking about co-editing?
In order to respond to them in detail and convincingly, it is necessary to write quite a lot of material, so there will be several articles, sit down comfortably, we begin.
As soon as we begin to store files on the server (in the cloud), there is a natural desire to ensure their editing by several people. This is especially true for office documents, on which several people work at once, and each of them makes edits.
')
But "you can not just take it and so ..." give everyone access to edit a single document. A mechanism is needed that will provide convenient and correct modification of a single file by several users. Let's look at options for how this can be done.
Possible approaches
Lock the entire document while editing
This is the most trivial method. The advantages of this solution are the ease of implementation and the ability to work with all types of data. This is where the advantages end and begin a continuous inconvenience for the user:
- Only one user can make changes at a time. The more such a document will be and the more often it will be edited, the more obvious this inconvenience becomes. Imagine the TK for more than a hundred pages, with one user having to wait for his colleague to finish editing a section in another part of the document.
- Each change in the document leads to the need to fully transfer it to the server, and then download to all participants, which greatly impairs the speed of work and increases the amount of data sent.
- This solution cannot provide offline work, because in order to start editing a document, it is necessary to block it on the server from being modified by other users. And without a connection to the server this cannot be done.
- Unlocked lock. Imagine that one user forgot to remove the lock, and even went home or even went on vacation. Everyone else has to wait or look for a careless user. In part, this can be avoided by controlling the time of activity or by giving the administrator the ability to forcibly release the lock. However, neither is an ideal solution, since in the first case it is impossible to understand, on the basis of which it is possible to distinguish the missing Internet from the lack of discipline of the user, and in the second it is impossible to do without human intervention and someone’s changes may be lost.
This option can often be found in solutions for corporate portals, ERP, EDS.
Blocking part of the document
For a text document, a paragraph or a table can become such a unit of division. This improves the entire work process, namely:
- Now you can simultaneously edit one document, provided that the changes are made in different parts of it.
- Lock the document completely impossible. Despite the unlock, you can continue to work with the rest of the document.
But this approach cannot be called ideal:
- Still can not provide offline work. To block any part of the document, you must contact the server.
- The part of the document that was locked during editing may be significant. Indeed, a paragraph can be quite large and contain several hundred or thousand characters of text. Even more difficulties arise when working with tables. Without additional tweaks, you cannot simultaneously allow cell contents and table structure changes — insert and delete rows or columns. This means that any change in one of the cells requires blocking the entire table. In office documents, tables can be of different nesting levels or very large in size. This moment becomes especially unpleasant when working with tabular documents, where the worksheet consists of a single table at all, which means that with any changes it is necessary to block it completely.
- From the point of view of structure, the document can be simply presented as a sequence of paragraphs and tables. And when we insert or delete tables and paragraphs, we edit this sequence. And this means that the correctness of joint editing of such a sequence is also necessary to ensure (by the way, there is no fundamental difference between editing a list of paragraphs or a list of letters, except that the first happens less often). Without introducing a fundamentally different method of synchronization, this should again be a lock, only this time the lock object will be one for the entire document.
Some readers may notice that the joint editing task is successfully solved in version control systems, with a consistent history (SVN or CVS) or with the possibility of branching (GIT, Mercurial). Yes, you are right, but there are some nuances that make it impossible to apply the same principle in our case:
- Merge. First, for users of office suites, this concept is usually unfamiliar. Secondly, combining different versions of a document becomes fundamentally more difficult when moving from simple text to a document with a complex (usually hierarchical) structure, where there is text, nested tables, images and various formatting settings. Just imagine a similar 3-way merge.
- Even when using kdiff3 or winmerge errors occur, and in fact they work with plain text.
- An ordinary office user will find it difficult to penetrate the world of branching and merging. And having penetrated, it will not be very fast and convenient to use.
Sight from the other side
We will proceed from the fact that, from the user's point of view, all work with the document should be reduced only to correct the text, insert the schedule promised to the colleagues, and finish there. Just as he did before with local documents. All complex processes to maintain the correct state of the document should be hidden from the user. At the same time, it is important to maintain responsiveness and functionality comparable to editing local files.
For us, this dictates additional requirements:
1. Use an optimistic change strategy. Edits should be applied immediately to a local copy of the document. And regardless of this, they are sent to the server, and from it to other clients, and how quickly they will be received and applied does not affect the speed of work with the local version.
It follows that the document status of the clients and on the server may differ. This forms the following requirement:
2. Convergence (convergence). When all users have finished their work and all notice of edits will be delivered, both on the server and the clients should have the same document state.
But that is not all. The first two requirements can be fulfilled with the help of a simple, but obviously unsuitable algorithm for users. If two competing changes come to the server, then you can simply ignore what came later, notifying clients accordingly. This will be enough to satisfy the first two requirements, but clearly not enough to make happy those whose changes have been thrown out. This means that you need to declare another requirement:
3. The principle of conservation intentions (intention preservation). We must ensure that the intentions of all users are maximally preserved, even if edits are made simultaneously and they compete with each other.
We declare that every edit from each of the users is important to us and we will not undo it unnecessarily. The need to cancel can still arise. For example, in such situations when one user edited a paragraph that was simultaneously deleted by someone else. In this case, the changes can no longer be applied, since the paragraph no longer exists.
The second point worth mentioning in the context of this principle is formalization. The concept of "intention" is rather abstract. Imagine that the text has the word "pharmacy", which is simultaneously corrected by two users, and in different ways: "pharmacy" and "optics". Most of the known algorithms (and ours too) work at the letter level, and the result is a “aptika”, which is not consistent with the “high-level” intentions of both authors. There are formalizations of users' intentions at the level of weak orders of letters (“I want to insert the letter“ and ”after the letter“ t ”, but before the“ k ””). For some algorithms, the preservation of intentions expressed in this way is an integral part of them (you can read about it here ).
In our case, we do not formalize the intentions of users and, moreover, do not give strict guarantees of their observance, but declare that we will adhere to this principle as much as possible.
Selecting a non-blocking algorithm
There are two algorithms that meet all of our requirements: optimistic change, convergence and preservation of intentions.
The first. Differential synchronization. Which in the end we did not fit
The algorithm assumes a constant 3-way merge on the client and server side, which is accompanied by the sending of patches in both directions. The diagram shows the general idea.
A more detailed description can be seen on the website of the author .
You probably already guessed why this algorithm does not suit us. Correctly, as already mentioned, a 3-way merge for a document with a complex structure is non-trivial. At the same time, it is necessary to have a formal guarantee that it will give the same results when merging in different orders and directions ... This puts an end to the prospect of applying this approach with us.
Second. Operation Transformation (OT)
It is rather a general approach, on the basis of which various algorithms are developed.
OT is based on a fairly simple idea. We describe all data changes as operations that are sent and transformed relative to others without the document itself. When an operation comes from one user to another, we transform it so that it becomes valid regarding the difference between the documents of these two users, expressed in operations. It sounds abstruse, but in fact the principle is quite simple.
What is Operation Transformation
Let's look at another scheme that is popular in articles about OT.
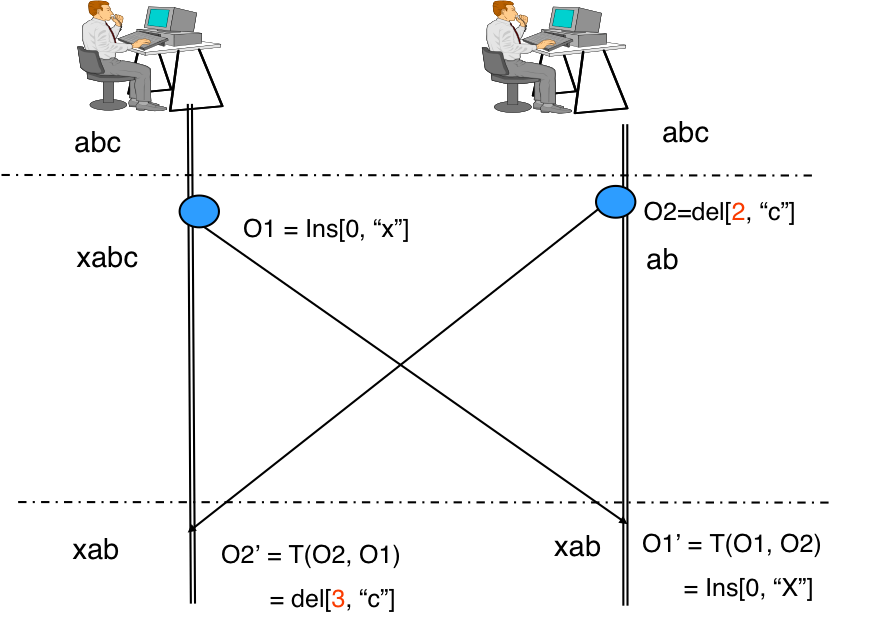
Operation O2:
- User 1 receives an O2 del [2, “c”] operation from user 2.
- O2 operation is transformed with respect to O1 operation, which user 2 did not have at the time of O2 creation.
- The result is del [3, “c”], since one character was already inserted before the position 2 and the position at c became 3.
Operation O1:
- User 2 from user 1 receives operation O1 ins [0, “x”].
- O1 is transformed relative to O2, but this time during transformation, the operation does not change and is applied in the same form as the author of the operation - user 1.
Inclusion transformation is used here (exclusion transformation is used in some algorithms). In the future, I will use the designation Inc (O1, O2) for operation O1, taking into account the effects of operation O2, that is, briefly, we have included O2 in O1.
The basic requirement that inclusion transformations (known as Transition Property 1) must satisfy is:
Inc (O2, O1) * O1 = Inc (O1, O2) * O2,
where * is a sequential application, right to left. For ease of understanding, look at the image:
The above equality applied to this picture means that, starting from one document state and moving along the right or left branch, we get the same final state. The principal point is that we must begin the “movement” from the same state. If this condition is not met, the result will be the mismatched state of the documents or the transformed operation may simply not make sense. For example, inserting a character into an invalid or non-existent document position.
As I indicated above, there are several different OT-based algorithms. Their main difference is the solution of the key question: how to perform transformations so that any operations involved in the transformation are over the same state of the document, and if this is not possible, then what other transformations can be used to change the order of operations.
The fact is that the first OT-based algorithms did not provide for the use of a central server. All clients have contacted peer-to-peer. Accordingly, the current state of the document among users was expressed by the sequence of operations (O1, O2 ... N), while at each moment of time the number, composition and order of these operations can be different for each client. In this case, it is impossible to determine a single strict order among all the generated operations, you can enter only a weak order on what happens before the criterion. Operations between which there is no such relationship are considered competing or concurrent (concurrent).
This approach also brings with it certain difficulties:
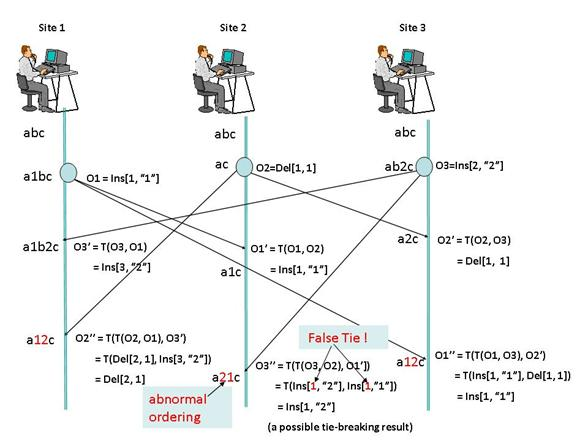
- Performance. The number of transformations can be very large, customers have to keep the whole story, because at any moment an “ancient” operation can come from another user.
- For the correct implementation of the requirement of TP-1 is not enough. It is necessary to require at least TP-2: Inc (O3, Inc (O1, O2) * O2) = Inc (O3, Inc (O2, O1) * O1). Depending on the specific algorithm, it may be necessary to fulfill other requirements for transformations and inverse operations (see the full list here ). If you have a set of operations, then these requirements must be met for any pair or triple, and this is not always the case. At the same time, in order to have confidence in the convergence of the algorithm, these requirements must be formally verified, that is, proved as a theorem.
- Complexity. Such algorithms are really difficult, and sometimes errors are found in them. For example, one of the cases that potentially leads to an error looks like this:
Those interested in classic peer-to-peer algorithms can find a detailed review and comparison of them here .
The difficulties listed above can be resolved by abandoning the equality of all clients and peer-to-peer connections. When adding a central server, the state of the documents can be described by a simple revision and require no more than TP-1 execution ... But the next article will be devoted to this topic. I promise that for lovers of algorithms there will be more interesting.
The first article from the cycle, meanwhile, reached the final. I would be glad to see in the comments your questions and suggestions regarding the content of the following articles.
The second part can be found here .
Until!
Source: https://habr.com/ru/post/264923/
All Articles