DMP Part 1. Microsegmentation of the audience using keywords
Authors of the article: Danila Perepechin Danila Perepechin, Dmitry Cheklov dcheklov .
Hello.
Data management platform (DMP) is our favorite topic in the whole story about online advertising. RTB is all about the data .
In the course of the series of stories about the technological stack Targetix ( SSP , DSP ), today I will describe one of the tools included
in DMP - Keyword Builder .
')
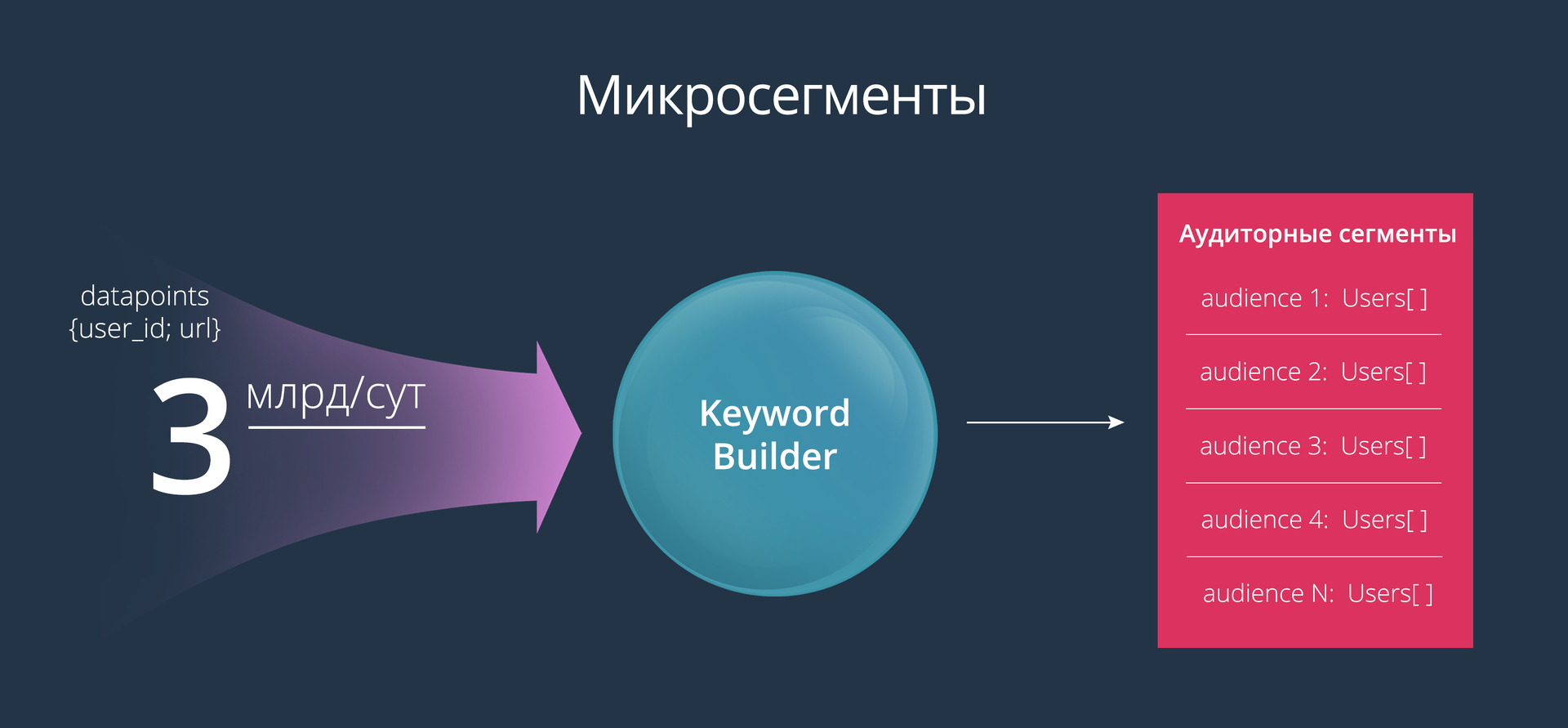
Keyword Builder helps advertisers to create very narrow audience segments (also called microsegments). To build such audiences, we decided to use the following mechanism: the advertiser sets up a list of keywords, and at the output receives an audience consisting of those users who have visited pages with specified keywords or searched for these words in a search. On the one hand, this is a very simple tool; on the other hand, it provides marketers with quite large possibilities for experiments.
The main advantage of this tool is full control over the creation of the audience. The advertiser clearly understands which users will eventually see the advertisement. For example, you can create an audience based on the following list of keywords: ford focus, opel astra, toyota corola.
How it looks from the side of the advertiser:

First of all, to solve this problem, we get clickstream from all possible data providers (Raw Data Suppliers) (user’s browsing history). The data comes to us in this form:
The main requirement that we made to the tool is the speed of creating an audience. This process should not take more than 5 minutes even for the most high-frequency words. It is also important that the advertiser in the interface, when specifying a keyword, can estimate the size of the audience. Size estimation should occur in real time when entering words (no more than 100 ms, as seen in the video above).
For a better understanding, we present a complete list of requirements for the instrument:
True, we came to these requirements after creating the first version of this tool :)
Initially, MongoDB was used and everything went pretty well.

In the Visitor History collection recorded data about the user, in the Page Index - about the pages. The URL of the page itself does not represent value - the page should be downloaded and extracted keywords. Then there was the first problem. The fact is that the Page Compiled collection was not there at first, and the keywords were recorded in the Page Index , but the simultaneous recording of keywords and data from suppliers created too much load on this collection. The Keywords field is usually large, it needs an index, and in MongoDB of that time (version 2.6) there was a lock on the entire collection during a write operation. In general, I had to put the keywords into a separate Page Compiled collection. I had to - so what, the problem is solved - we are happy. Now it is difficult to remember the number and characteristics of servers ... something about 50 shard'ov.

To create an audience by keywords, we made a request to the Page Compiled collection, received a list of URLs that met these words, went to the Visitor History collection with this list, and searched for users who visited these pages. Everything worked well (sarcasm) and we could create 5 or even 10 (!!!) audience segments per day ... unless, of course, nothing falls. The load at that time was about 800 million datapoint per day, the TTL index was 2 weeks: 800 * 14 ... there was a lot of data. Work went wrong and for 3 months the load doubled. But taking more N servers to sustain the life of this strange construction was not comme il faut.
The biggest and most obvious disadvantage of this architecture is the above-described request related to obtaining a list of URLs. The result of this query could be thousands, millions of records. And most importantly, on this list, it was necessary to make a request to another collection.
Other cons of architecture:
Pros:
In general, from the very beginning it was clear that something had gone wrong, but now it became obvious. We concluded that a table is needed, which will be updated in real time and contain records of the following form:
After analyzing possible solutions, we chose not for one database, but their combination with a small duplication of data. We did this because the cost of data duplication was not comparable with the possibilities that this architecture gave us.

The first solution is the Solr full-text search platform. Allows you to create a distributed index of documents. Solr is a popular solution that has a large amount of documentation and is supported in the Cloudera service. However, it didn’t work with him as a full-fledged database, we decided to add a distributed column database HBase to the architecture.
At the beginning, it was decided that in Solr a user will appear as a document, in which there will be an indexed keywords field with all keywords. But since we planned to delete the old data from the table, we decided to use the user + date link as the document, which became the User_id field: that is, each document should store all user keywords for the day. This approach allows you to delete old entries on the TTL-index, as well as build audiences with varying degrees of "freshness." The Real_Id field is the real user id. This field is used for aggregation in queries with a specified duration of interest.
By the way, in order not to store unnecessary data in Solr , the keywords field was made only indexable, which allowed us to significantly reduce the amount of stored information. In this case, the keywords themselves, as you already understood, can be obtained from HBase .
Solr features that we found useful in this architecture:
Data duplicated in HBase and Solr, applications are recorded only in HBase, from where the service from Cloudera automatically duplicates the records in Solr with the specified field attributes and TTL index.
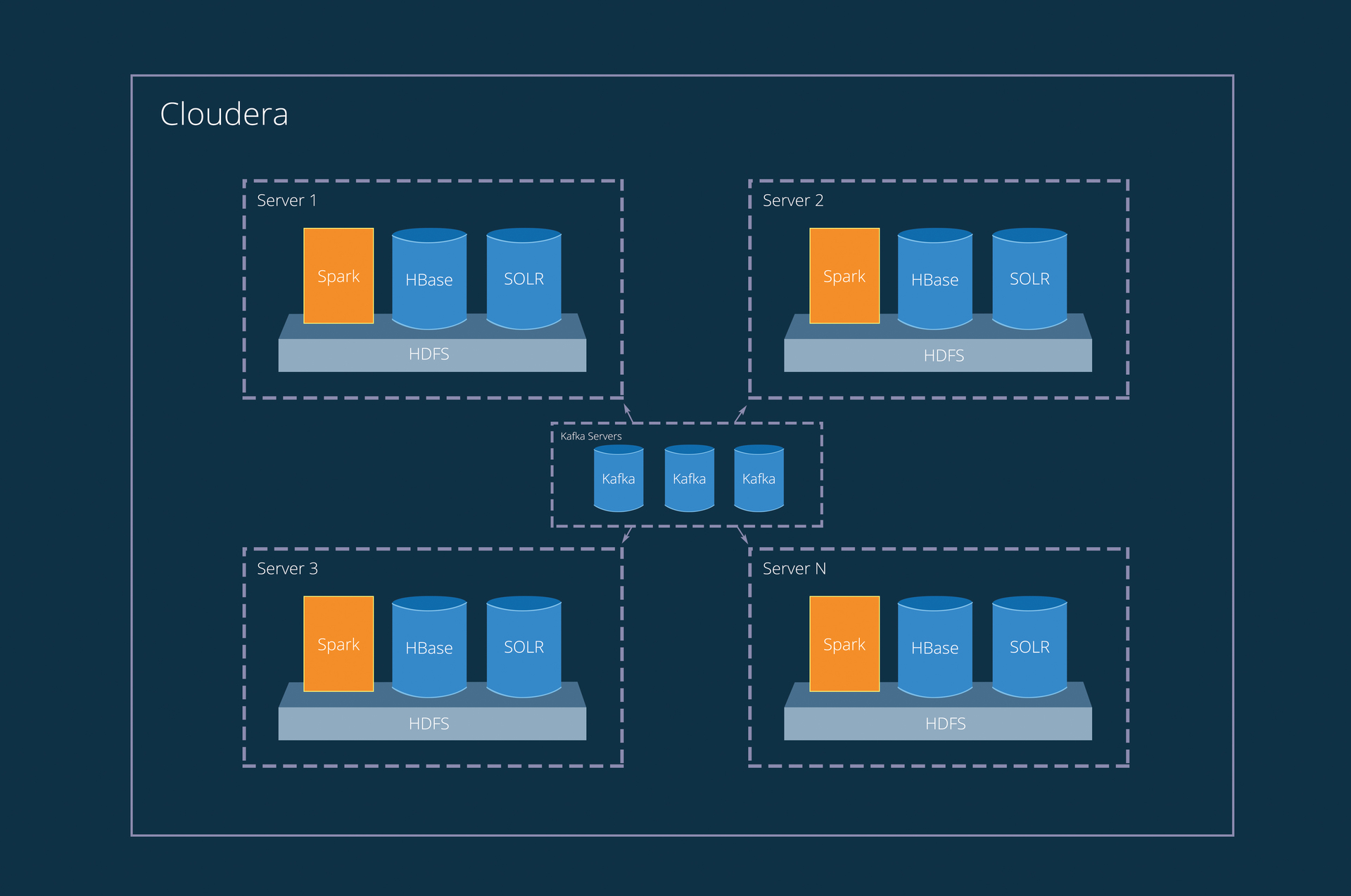
Thus, we were able to reduce the costs associated with heavy queries. But these are not all the elements that we needed and became our foundation. First of all, we needed to handle large amounts of data on the fly, and then Apache Spark with its streaming functionality came in handy. And as the data queue, we chose Apache Kafka , which is the best suited for this role.
Now the working scheme is as follows:
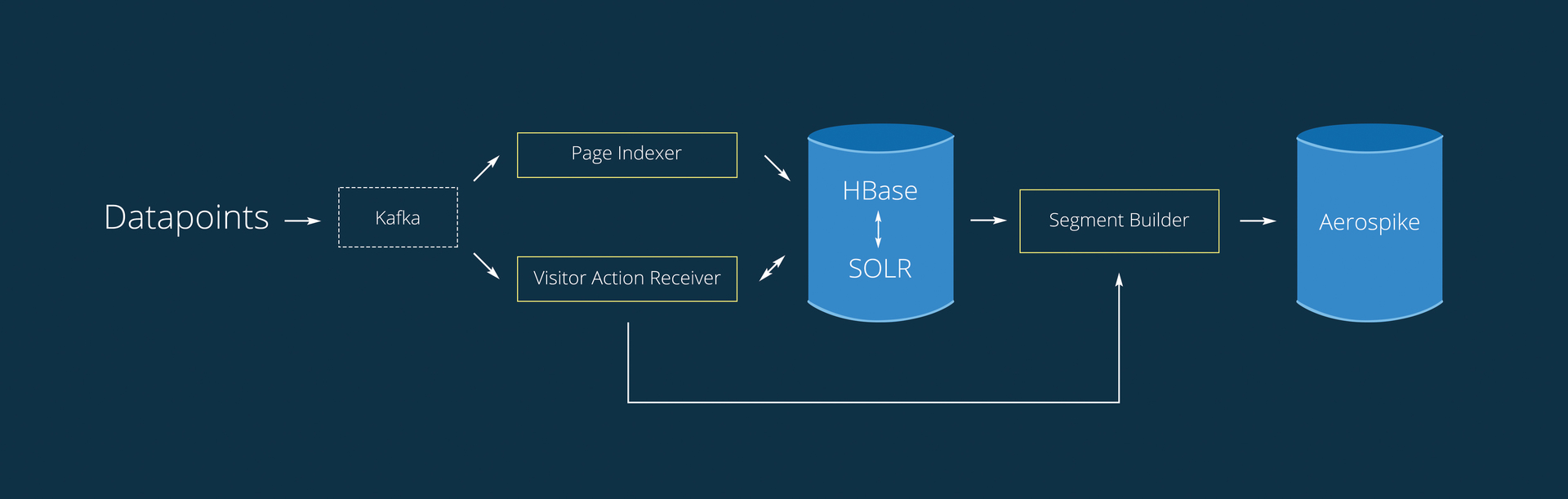
1. From the Kafka data select two processes. Queuing functionality allows you to read it to several independent processes, each of which has its own cursor.
2. PageIndexer - from the record {user_id: [urls]} uses only the URL. It works only with the Page Compiled table.
3. VisitorActionReceiver — Collects information about users actions stored in the Kafka in 30 seconds (batch interval).
4. SegmentBuilder builds audiences and adds new users to existing ones, in real time.
A feature of PageIndexer is the choice of keywords from a page, for different types of pages - different sets of words.
Works on 1-2 servers 32GB RAM Xeon E5-2620, downloads 15-30K pages per minute. At the same time choosing from the queue 200-400K records.
And the main advantage of VisitorActionReceiver is that in addition to adding entries to Solr / HBase, data is also sent to Segment Builder and new users are added to the audience in real time.
Segment Builder generates a complex query in Solr, where words from different tags are assigned different weights, and the duration of the user's interest is taken into account (short-term, medium-term, long-term). All requests for building an audience are made using the edismax query, which returns the weight of each document relative to the request. In this way, really relevant users get into the audience.
In HBase per second comes about 20K of requests for reading and 2.5K for writing. The data storage capacity is ~ 100 GB. Solr occupies ~ 250 GB, contains ~ 250 million TTL records 7 days index. (All numbers without replication).
Briefly recall the main elements of the infrastructure:
Kafka is a smart and stable queue, HBase is a fast column database, Solr is a long-established search engine, Spark is distributed computing, including streaming, and most importantly, all this is on HDFS , scales well, is monitored and is very stable. Works surrounded by Cloudera.
It may seem that we have complicated the working scheme with a wide variety of tools. In fact, we have taken the path of the greatest simplification. Yes, we changed one Mongu to the list of services, but they all work in the niche for which they were created.
Now the Keyword Builder really meets all the requirements of advertisers and common sense. Audiences of 2.5 million people are created in 1-7 minutes. Evaluation of audience size occurs in real time. Only 8 servers are involved (i7-4770, 32GB RAM). Adding servers entails a linear increase in performance.
And you can always try the resulting tool in the Hybrid retargeting platform .
I express my deep gratitude to the user dcheklov , for help in creating the article and admonishing the true path =).
The DMP theme started and remains open, wait for us in the next issues.
Hello.
Data management platform (DMP) is our favorite topic in the whole story about online advertising. RTB is all about the data .
In the course of the series of stories about the technological stack Targetix ( SSP , DSP ), today I will describe one of the tools included
in DMP - Keyword Builder .
')
Microsegmentation
Keyword Builder helps advertisers to create very narrow audience segments (also called microsegments). To build such audiences, we decided to use the following mechanism: the advertiser sets up a list of keywords, and at the output receives an audience consisting of those users who have visited pages with specified keywords or searched for these words in a search. On the one hand, this is a very simple tool; on the other hand, it provides marketers with quite large possibilities for experiments.
The main advantage of this tool is full control over the creation of the audience. The advertiser clearly understands which users will eventually see the advertisement. For example, you can create an audience based on the following list of keywords: ford focus, opel astra, toyota corola.
How it looks from the side of the advertiser:
First of all, to solve this problem, we get clickstream from all possible data providers (Raw Data Suppliers) (user’s browsing history). The data comes to us in this form:
{ user_id; url } Goals and requirements
The main requirement that we made to the tool is the speed of creating an audience. This process should not take more than 5 minutes even for the most high-frequency words. It is also important that the advertiser in the interface, when specifying a keyword, can estimate the size of the audience. Size estimation should occur in real time when entering words (no more than 100 ms, as seen in the video above).
For a better understanding, we present a complete list of requirements for the instrument:
- principle of data locality;
- high availability of a database (high availability);
- horizontal scalability;
- high write speed;
- high speed full-text search;
- high speed search by key.
True, we came to these requirements after creating the first version of this tool :)
The first architecture, which teaches, "how not to do"
Initially, MongoDB was used and everything went pretty well.
In the Visitor History collection recorded data about the user, in the Page Index - about the pages. The URL of the page itself does not represent value - the page should be downloaded and extracted keywords. Then there was the first problem. The fact is that the Page Compiled collection was not there at first, and the keywords were recorded in the Page Index , but the simultaneous recording of keywords and data from suppliers created too much load on this collection. The Keywords field is usually large, it needs an index, and in MongoDB of that time (version 2.6) there was a lock on the entire collection during a write operation. In general, I had to put the keywords into a separate Page Compiled collection. I had to - so what, the problem is solved - we are happy. Now it is difficult to remember the number and characteristics of servers ... something about 50 shard'ov.
To create an audience by keywords, we made a request to the Page Compiled collection, received a list of URLs that met these words, went to the Visitor History collection with this list, and searched for users who visited these pages. Everything worked well (sarcasm) and we could create 5 or even 10 (!!!) audience segments per day ... unless, of course, nothing falls. The load at that time was about 800 million datapoint per day, the TTL index was 2 weeks: 800 * 14 ... there was a lot of data. Work went wrong and for 3 months the load doubled. But taking more N servers to sustain the life of this strange construction was not comme il faut.
The biggest and most obvious disadvantage of this architecture is the above-described request related to obtaining a list of URLs. The result of this query could be thousands, millions of records. And most importantly, on this list, it was necessary to make a request to another collection.
Other cons of architecture:
- inconvenient recording due to global lock'a;
- the huge size of the index, which grew despite the deletion of data;
- the complexity of monitoring a large cluster;
- the need to independently create a simplified version of full-text search;
- the lack of a locality principle in data processing;
- the inability to quickly assess the size of the audience;
- the inability to add users to the audience on the fly.
Pros:
- we understood all the minuses.
What we came to
In general, from the very beginning it was clear that something had gone wrong, but now it became obvious. We concluded that a table is needed, which will be updated in real time and contain records of the following form:
user { user_id; keywords[] } After analyzing possible solutions, we chose not for one database, but their combination with a small duplication of data. We did this because the cost of data duplication was not comparable with the possibilities that this architecture gave us.
The first solution is the Solr full-text search platform. Allows you to create a distributed index of documents. Solr is a popular solution that has a large amount of documentation and is supported in the Cloudera service. However, it didn’t work with him as a full-fledged database, we decided to add a distributed column database HBase to the architecture.
At the beginning, it was decided that in Solr a user will appear as a document, in which there will be an indexed keywords field with all keywords. But since we planned to delete the old data from the table, we decided to use the user + date link as the document, which became the User_id field: that is, each document should store all user keywords for the day. This approach allows you to delete old entries on the TTL-index, as well as build audiences with varying degrees of "freshness." The Real_Id field is the real user id. This field is used for aggregation in queries with a specified duration of interest.
By the way, in order not to store unnecessary data in Solr , the keywords field was made only indexable, which allowed us to significantly reduce the amount of stored information. In this case, the keywords themselves, as you already understood, can be obtained from HBase .
Solr features that we found useful in this architecture:
- fast indexing;
- compact index;
- full text search;
- assessment of the number of documents matching the request;
- index optimization after data deletion (prevents its growth, as it often happens in other databases).
Data duplicated in HBase and Solr, applications are recorded only in HBase, from where the service from Cloudera automatically duplicates the records in Solr with the specified field attributes and TTL index.
Thus, we were able to reduce the costs associated with heavy queries. But these are not all the elements that we needed and became our foundation. First of all, we needed to handle large amounts of data on the fly, and then Apache Spark with its streaming functionality came in handy. And as the data queue, we chose Apache Kafka , which is the best suited for this role.
Now the working scheme is as follows:
1. From the Kafka data select two processes. Queuing functionality allows you to read it to several independent processes, each of which has its own cursor.
2. PageIndexer - from the record {user_id: [urls]} uses only the URL. It works only with the Page Compiled table.
- When a datapoint arrives, it makes a request to HBase to check if the page has already been downloaded or not.
- If the page was not found in the database, extracts keywords from it.
- Writes data to HBase.
3. VisitorActionReceiver — Collects information about users actions stored in the Kafka in 30 seconds (batch interval).
- Remove duplicates from the queue
- Creating a record of the form {user_id: [urls]}
- Query to HBase in the Page Compiled table and retrieving keywords, creating a record of the form {user_id: [keywords]}
- Query to HBase in the Visitor Keywords table and retrieving keywords already contained by the user
- Combining keywords for a user
- Record in Solr and HBase
4. SegmentBuilder builds audiences and adds new users to existing ones, in real time.
- Timer checks for raw audiences.
- Generates a request to Solr and receives users for the audience.
- Writes data to Aerospike
A feature of PageIndexer is the choice of keywords from a page, for different types of pages - different sets of words.
Works on 1-2 servers 32GB RAM Xeon E5-2620, downloads 15-30K pages per minute. At the same time choosing from the queue 200-400K records.
And the main advantage of VisitorActionReceiver is that in addition to adding entries to Solr / HBase, data is also sent to Segment Builder and new users are added to the audience in real time.
The order of calls VisitorActionReceiver:
public static void main(String[] args) { SparkConf conf = getSparkConf(); JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(STREAMING_BATCH_SIZE)); JavaPairInputDStream<String, byte[]> rawStream = Utils.createDirectStream(jssc, KAFKA_TOPIC_NAME, KAFKA_BROKERS); JavaPairDStream<String, String> pairUrlVid = rawStream.mapPartitionsToPair(rawMessageIterator -> convertRawMessage(rawMessageIterator)); Utils.GetCountInStreamRDD(pairUrlVid, "before_distinct"); JavaPairDStream<String,String> reducedUrlVid = pairUrlVid.reduceByKey((old_s, next_s) -> reduceByUrl(old_s, next_s), LEVEL_PARALLELISM).repartition(LEVEL_PARALLELISM).persist(StorageLevel.MEMORY_ONLY_SER()); Utils.GetCountInStreamRDD(reducedUrlVid, "after_distinct"); JavaDStream<SolrInputDocument> solrDocumentsStream = reducedUrlVid.mapPartitions(reducedMessages -> getKeywordsFromHbase(reducedMessages)).repartition(SOLR_SHARD_COUNT).persist(StorageLevel.MEMORY_ONLY_SER()); Utils.GetCountInStreamRDD(solrDocumentsStream, "hbase"); SolrSupport.indexDStreamOfDocs(SOLR_ZK_CONNECT, SOLR_COLLECTION_NAME, SOLR_BATCH_SIZE, solrDocumentsStream); jssc.start(); jssc.awaitTermination(); } Segment Builder generates a complex query in Solr, where words from different tags are assigned different weights, and the duration of the user's interest is taken into account (short-term, medium-term, long-term). All requests for building an audience are made using the edismax query, which returns the weight of each document relative to the request. In this way, really relevant users get into the audience.
In HBase per second comes about 20K of requests for reading and 2.5K for writing. The data storage capacity is ~ 100 GB. Solr occupies ~ 250 GB, contains ~ 250 million TTL records 7 days index. (All numbers without replication).
Briefly recall the main elements of the infrastructure:
Kafka is a smart and stable queue, HBase is a fast column database, Solr is a long-established search engine, Spark is distributed computing, including streaming, and most importantly, all this is on HDFS , scales well, is monitored and is very stable. Works surrounded by Cloudera.
Vivid illustration of sustainability
Conclusion
It may seem that we have complicated the working scheme with a wide variety of tools. In fact, we have taken the path of the greatest simplification. Yes, we changed one Mongu to the list of services, but they all work in the niche for which they were created.
Now the Keyword Builder really meets all the requirements of advertisers and common sense. Audiences of 2.5 million people are created in 1-7 minutes. Evaluation of audience size occurs in real time. Only 8 servers are involved (i7-4770, 32GB RAM). Adding servers entails a linear increase in performance.
And you can always try the resulting tool in the Hybrid retargeting platform .
I express my deep gratitude to the user dcheklov , for help in creating the article and admonishing the true path =).
The DMP theme started and remains open, wait for us in the next issues.
Source: https://habr.com/ru/post/264821/
All Articles