Deep Dream: how to train a neural network to dream not only about dogs
In July, everyone was pleased with the deep dream article or introspection from Google. The article described in detail and showed how neural networks draw pictures and why they were forced to do it. Here this article on Habré.
Now everyone who has a caffe environment, who is bored and who has free time can make their own photos of intrestingism. One problem - almost all the pictures are dogs. How can you get rid of the elements with dogs in deep dream images and train your neural network to use other pictures?

')
For this task, you do not need to train the network from scratch - just tune the parameters in Googlenet. Building a network from scratch requires a lot of time, hundreds of hours. Read this before you begin.
The most difficult part is to download 200-1000 images that you want to use for training. The author came to the conclusion that similar images work well. You can use faces, pornographic pictures, letters, animals, firearms, and so on.
Resize all images to 256x256. Save them as Truecolor JPG (but not in Grayscale, even if the image is black and white).
Calculate the average colors of all your images (this is optional). You need to know about the average red, green and blue in the set of pictures. For this, the author uses the convert and identify tools in ImageMagick :
So you can see the average figure for each color channel.
Create a folder
Create a folder called
For each of the images you need to create a separate folder inside the 'images' folder. The author uses numbers starting from 0. For example,
Create a text file called
Copy the contents of the
Lines 13-15 (and 34-36) determine the average values for your set of pictures for the blue, green, and red channels (in this sequence). If you do not know the values, simply set “129” everywhere.
In line 19, specify the number of simultaneously processed images. A 4-gigabyte graphics processor can handle 40 images, well, and if the processor is 2 GB, the number will need to be reduced to 20. If the number you enter is too high, the program will generate an “out of memory” error and you will need to enter a smaller value. Any number of pictures, even 1, will do.
Lines 917, 1680, and 2393.
Line 2141,
It is very important to change the following values:
Still need googlenet. Open
Go to the working folder and execute this command:
Progress will be saved every 5000 iterations. When it continues, you can interrupt training and run Deep Dream on the network. The first results should be visible in the
To resume learning, use the latest save progress with the following command:
There are several strategies for
The graphics processor of the author - NVIDIA GTX960 with 4 GB of RAM. Caffe is compiled with the CuDNN library. Every 5,000 iterations took about an hour. When using the CPU, the calculations were 40 times slower.
The author advises to stop learning after 40 thousand iterations, but once made 90 thousand. The user with the nickname DeepDickDream took 750 thousand iterations to add the portrait of Hulk Hogan from the members.
You have little chance to make a set of images visible, if you do less than 100,000 iterations, but there is a good chance to see something new ... and without dogs.
In one category may be more images than others. For example, you can use 20 categories with two hundred pictures in them. You can train the network on random images, identical or similar - in general, whatever. The author failed to isolate the rule that provides the best result. Maybe it all depends on the content.
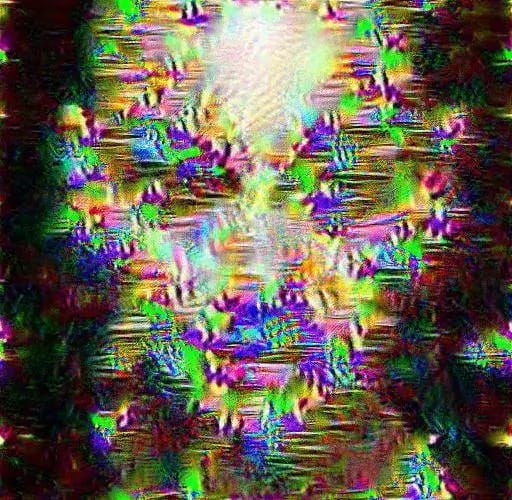
Network trained with images from the British Library. 11 categories. 100 thousand images (each image had 10 options). The inception layers 3, 4 and 5 have been cleared. The result was after 25 thousand iterations. The faces from the portrait album are clearly visible. Here is the image from layer

Subdivision of the British Library, containing only letters. 750 categories, one image each. 40 thousand iterations. Only the classification layer is cleared. I wonder why butterflies are clearly visible? Layer 5b.

The same picture, but with an hourglass. Layer 5a.

But a set of pornographic nature. 94 categories, 100 images each. 90 thousand iterations. Layer 5b.

The image is similar to the previous one, but with a modified set of images (the effects of image rotation, reflection, normalization, blur, etc.) are used. 40 thousand iterations. Layer 5b.

4 categories of distorted images, 1000 each, 65 thousand iterations. Pool5 layer.

An image similar to the previous one. 80 thousand iterations. With empty 3.4 and 5 layers. Layer 5b.
Now everyone who has a caffe environment, who is bored and who has free time can make their own photos of intrestingism. One problem - almost all the pictures are dogs. How can you get rid of the elements with dogs in deep dream images and train your neural network to use other pictures?
')
Step-by-step instruction
For this task, you do not need to train the network from scratch - just tune the parameters in Googlenet. Building a network from scratch requires a lot of time, hundreds of hours. Read this before you begin.
The most difficult part is to download 200-1000 images that you want to use for training. The author came to the conclusion that similar images work well. You can use faces, pornographic pictures, letters, animals, firearms, and so on.
Resize all images to 256x256. Save them as Truecolor JPG (but not in Grayscale, even if the image is black and white).
Calculate the average colors of all your images (this is optional). You need to know about the average red, green and blue in the set of pictures. For this, the author uses the convert and identify tools in ImageMagick :
convert *.jpg -average res.png identify -verbose res.png So you can see the average figure for each color channel.
Create a folder
<caffe_path>/models/MYNET.
<caffe_path>/models/MYNET.
This is a working folder. All created folders and files will be placed in MYNET.Create a folder called
'images'
'images'
(in the working folder in MYNET).For each of the images you need to create a separate folder inside the 'images' folder. The author uses numbers starting from 0. For example,
'images/0/firstimage.jpg',
'images/0/firstimage.jpg',
'images/1/secondimage.jpg',
and so on. Each folder is a category, so that you end up with many folders, each containing one image at a time.Create a text file called
train.txt
train.txt
(and place it in the working folder). Each line in this file must contain the path to the image with the image category number. It looks like this: images/0/firstimage.jpg 0 images/1/secondimage.jpg 1 … Copy the contents of the
train.txt
file train.txt
in the file val.txt.
val.txt.
Copy the files deploy.prototxt,
deploy.prototxt,
train_val.prototxt
and solver.prototxt
solver.prototxt
into the working folder from here .How to edit files
1. train_val.prototxt
Lines 13-15 (and 34-36) determine the average values for your set of pictures for the blue, green, and red channels (in this sequence). If you do not know the values, simply set “129” everywhere.
In line 19, specify the number of simultaneously processed images. A 4-gigabyte graphics processor can handle 40 images, well, and if the processor is 2 GB, the number will need to be reduced to 20. If the number you enter is too high, the program will generate an “out of memory” error and you will need to enter a smaller value. Any number of pictures, even 1, will do.
Lines 917, 1680, and 2393.
num_output
num_output
must match the number of your categories, i.e. number of folders in the image directory.2. deploy.prototxt
Line 2141,
num_output
num_output
should be the same as in the previous file.3. solver.prototxt
It is very important to change the following values:
- display: 20 - print statistics after every 20 iterations
- base_lr: 0.0005 - learning rate (learning rate), it can be changed. base_lr can be adapted based on the results (see strategy below)
- max_iter: 200000 - the maximum number of iterations for training. Here you can specify at least 1,000,000.
- snapshot: 5000 - how often progress will be maintained. (in this case, every 5000 iterations). This value is absolutely necessary if you need to stop learning at any point.
Almost everything is ready
Still need googlenet. Open
caffe/models/bvlc_googlenet
caffe/models/bvlc_googlenet
and save this file here .Go to the working folder and execute this command:
../../build/tools/caffe train -solver ./solver.prototxt -weights ../bvlc_googlenet/bvlc_googlenet.caffemodel Progress will be saved every 5000 iterations. When it continues, you can interrupt training and run Deep Dream on the network. The first results should be visible in the
inception_5b/output
layer inception_5b/output
.To resume learning, use the latest save progress with the following command:
../../build/tools/caffe train -solver ./solver.prototxt -snapshot ./MYNET_iter_5000.solverstate Strategies for base_lr
There are several strategies for
base_lr
base_lr
during the first 1000 iterations. Watch the percentage of losses. During training, the value should gradually decrease to 0.0, however:- If you see that the percentage of losses is higher and higher, interrupt the training and set the value to
base_lrbase_lrfive times lower than the current. - If the loss percentage is “stuck” at the same level and decreases very slowly, interrupt the training and set the value to
base_lrbase_lr5 times higher than the previous value. - If none of the above strategies worked, then there is probably a problem and the training failed. Change image set and try again.
Some insights
The graphics processor of the author - NVIDIA GTX960 with 4 GB of RAM. Caffe is compiled with the CuDNN library. Every 5,000 iterations took about an hour. When using the CPU, the calculations were 40 times slower.
The author advises to stop learning after 40 thousand iterations, but once made 90 thousand. The user with the nickname DeepDickDream took 750 thousand iterations to add the portrait of Hulk Hogan from the members.
You have little chance to make a set of images visible, if you do less than 100,000 iterations, but there is a good chance to see something new ... and without dogs.
In one category may be more images than others. For example, you can use 20 categories with two hundred pictures in them. You can train the network on random images, identical or similar - in general, whatever. The author failed to isolate the rule that provides the best result. Maybe it all depends on the content.
Examples
Network trained with images from the British Library. 11 categories. 100 thousand images (each image had 10 options). The inception layers 3, 4 and 5 have been cleared. The result was after 25 thousand iterations. The faces from the portrait album are clearly visible. Here is the image from layer
5b/output
5b/output
.Subdivision of the British Library, containing only letters. 750 categories, one image each. 40 thousand iterations. Only the classification layer is cleared. I wonder why butterflies are clearly visible? Layer 5b.
The same picture, but with an hourglass. Layer 5a.
But a set of pornographic nature. 94 categories, 100 images each. 90 thousand iterations. Layer 5b.
The image is similar to the previous one, but with a modified set of images (the effects of image rotation, reflection, normalization, blur, etc.) are used. 40 thousand iterations. Layer 5b.
4 categories of distorted images, 1000 each, 65 thousand iterations. Pool5 layer.
An image similar to the previous one. 80 thousand iterations. With empty 3.4 and 5 layers. Layer 5b.
Abstract
- For this task, you do not need to train the network from scratch - just tune the parameters in Googlenet.
- The most difficult part is to download 200-1000 images that you want to use for training.
- Good work the same type of images.
- The size of all the pictures you need to change to 256x256.
- You can train the network on random images, identical or similar.
Source: https://habr.com/ru/post/264757/
All Articles