Augmentation (augmentation, “blowing up”) of data for training a neural network using printed characters as an example

On Habré there are already many articles devoted to pattern recognition by methods of learning machines, such as neural networks, support vector machines, random trees. All of them require a significant number of examples for training and setting parameters. Creating a training and test database of images of adequate volume for them is a very non-trivial task. And this is not about the technical difficulties of collecting and storing a million images, but about the perennial situation when you have one and a half pictures in the first stage of system development. In addition, it should be understood that the composition of the training base can affect the quality of the resulting recognition system more than all other factors. Despite this, in most articles this important development stage is completely omitted.
If it is interesting to you to learn about all this - welcome under kat.
Before creating a database of examples of images and training a neural network, it is necessary to specify a technical problem. It is clear that the recognition of handwriting, the emotions of a human face, or the location of a photograph is a completely different task. It is also clear that the architecture of the used neural network will be influenced by the choice of platform: in the “cloud”, on the PC, on the mobile device — the available computing resources differ by orders of magnitude.
Further it becomes more interesting. Recognizing high-resolution images from cameras or blurry images from a webcam without autofocus will require completely different data for training, testing and validation. This is hinted at by “theorems about the absence of free data”. That is why freely distributed educational database of images (for example, [ 1 , 2 , 3 ]), are excellent for academic research, but are almost always inapplicable in real-world tasks due to their “generalization”.
')
The more accurately the training sample approximates the population of images that will be input to your system, the higher the maximum achievable quality of the result will be. It turns out that a correctly composed training sample is the most concrete specification of the technical task! For example, if we want to recognize printed characters in a photograph taken with a mobile device, the base of examples should contain photographs of documents from different sources with different lighting, taken from different models of phones and cameras. All this complicates the collection of the required number of examples for learning the recognizer.
Let us now consider several possible ways to prepare a sample of images to create a recognition system.
Creating learning examples from natural images.
Examples for learning from natural images are based on real data. Their creation consists of the following steps:
- Collection of graphic data (photographing objects of interest, removing the video stream from the camera, highlighting part of the image on the web page).
- Filtering - verification of images for a number of requirements: a sufficient level of illumination of objects on them, the presence of the necessary object, etc.
- Preparation of tools for markup (writing your own or optimizing the finished).
- Marking (selection of quadrangles, familiarity, areas of interest of the image).
- Assignment of a tag to each image (letter or name of an object in the image).
These operations require significant expenditure of working time, and, accordingly, a similar way of creating a training base is very expensive. In addition, it is necessary to collect data in different conditions - lighting, phone models, cameras from which the survey is being taken, various sources of documents (printing houses), etc.
All this complicates the collection of the required number of examples for learning the recognizer. On the other hand, according to the results of training the system on such data, one can judge its effectiveness in real conditions.
Creating learning examples from artificial images.
Another approach to creating training data is their artificial generation. You can take several templates / “ideal” examples (for example, font sets) and create the necessary number of examples for learning with the help of various distortions. The following distortions can be used:
- Geometric (affine, projective, ...).
- Brightness / color.
- Replacing the background.
- Distortions characteristic of the problem being solved: glare, noise, blur, etc.
Examples of image distortions for character recognition tasks:
Shifts:
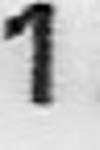
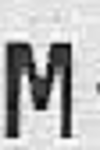
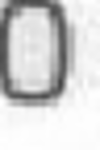

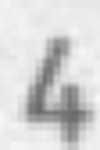
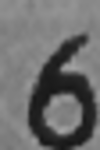

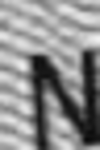
Turns:


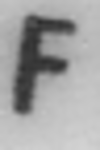
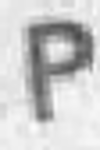

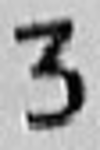


Additional lines on images:
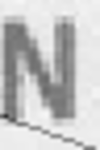

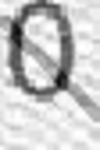





Glare:








Defocus:





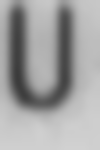

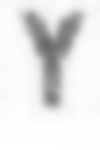
Compression and stretching along the axes:



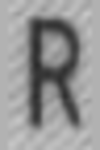
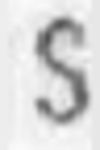
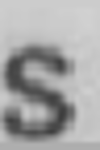
You can generate distortions using image libraries [ 1 , 2 , 3 ] or special programs that allow you to create whole artificial documents or objects.
This approach does not require a large amount of human resources and is relatively cheap because it does not require markup and data collection — the entire process of creating an image database is determined by the choice of the algorithm and parameters.
The main disadvantage of this method is the weak relationship of the quality of the system on the generated data with the quality of work in real conditions. In addition, the method requires large computing power to create the required number of examples. The choice of distortions used to create a database for a specific task also constitutes a certain complexity.
Below is an example of creating a fully artificial base.
The initial set of font character images:
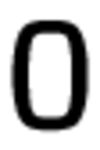

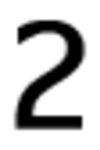
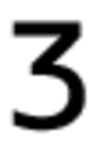
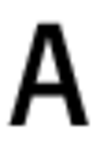
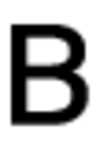

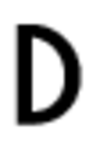
Examples of backgrounds:




Examples of images without distortion:





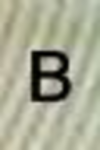

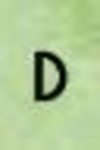
Adding small distortions:

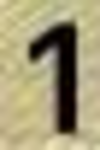

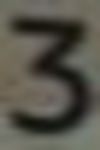


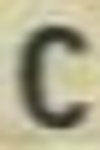

Creation of artificial teaching examples generated from natural images.
The logical continuation of the previous method is the generation of artificial examples using real data instead of templates and the original "ideal" examples. By adding distortion, you can achieve a significant improvement in the performance of the recognition system. In order to understand exactly which distortions should be applied, some of the real data should be used for validation. They can be used to evaluate the most common types of errors and add images with appropriate distortions to the training base.
This way of creating teaching examples contains the advantages of both of the above approaches: it does not require high material costs and allows you to create a large number of examples needed for the training of the recognizer.
Difficulties can be caused by careful selection of the “blow-up” parameters of the training sample from the initial examples. On the one hand, the number of examples should be sufficient for the neural network to learn to recognize even noisy examples, on the other hand, it is necessary that the quality of other types of complex images does not fall
Comparison of the quality of learning of a neural network using examples from natural images, completely artificial and generated using natural ones.
Let's try to create a neural network on images of symbols MRZ. Machine-Readable Zone (MRZ - Machine-Readable Zone) is a part of an identity document, made in accordance with international recommendations, enshrined in the document Doc 9303 - Machine Readable Travel Documents of the International Civil Aviation Organization . You can read more about MRZ recognition problems in our other article .
MRZ Example:

MRZ contains 88 characters. We will use 2 characteristics of the quality of the system:
- The percentage of characters recognized in error.
- the percentage of fully correctly recognized zones (MRZ is considered fully correctly recognized if all the characters in it are recognized correctly).
In the future, the neural network is supposed to be used on mobile devices, where computing power is limited, so the grids used will have a relatively small number of layers and weights.
For the experiments, 800'000 examples of characters were collected, which were divided into 3 groups: 200'000 examples for training, 300'000 examples for validation and 300'000 examples for testing. Such a partition is unnatural, since most of the examples are “wasted” (validation and testing), but it makes it possible to best show the advantages and disadvantages of various methods.
For a test sample, the distribution of examples of different classes is close to real and looks like this:
Class name (symbol): number of examples
0: 22416 1: 17602 2: 13746 3: 8115 4: 8587 5: 9383 6: 8697 7: 8082 8: 9734 9: 8847
<: 110438 A: 12022 B: 1834 C: 3891 D: 2952 E: 7349 F: 3282 G: 2169 H: 3309 I: 6737
J: 934 K: 2702 L: 4989 M: 6244 N: 7897 O: 4515 P: 4944 Q: 109 R: 7717 S: 5499 T: 3730
U: 4224 V: 3117 W: 744 X: 331 Y: 1834 Z: 1246
When learning only in natural examples, the average symbolic error value in 25 experiments was 0.25%, i.e. the total number of incorrectly recognized symbols was 750 images out of 300,000. For practical application, this quality is unacceptable, since the number of correctly recognized zones in this case is 80%.
Consider the most common types of errors that a neural network makes.
Examples of incorrectly recognized images:



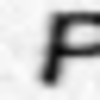
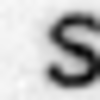


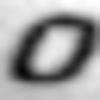
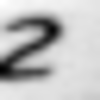
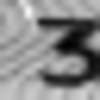




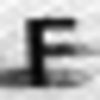

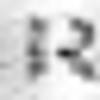
The following types of errors can be distinguished:
- Errors on non-centered images.
- Errors on rotated images.
- Errors on images with lines.
- Errors on images with highlights.
- Errors in difficult cases.
The most common errors table:
(format Original symbol, number of errors, with which symbols the network most often confuses this symbol and how many times)
Original symbol: '0', number of errors: 437
'O': 419, 'U': 5, 'J': 4, '2': 2, '1': 1
Original symbol: '<', number of errors: 71
'2': 29, 'K': 6, 'P': 6, '4': 4, '6': 4
Original symbol: '8', number of errors: 35
'B': 10, '6': 10, 'D': 4, 'E': 2, 'M': 2
Original symbol: 'O', number of errors: 20
'0': 19, 'Q': 1
Original symbol: '4', number of errors: 19
'6': 5, 'N': 3, '¡': 2, 'A': 1, 'D': 1
Original symbol: '6', number of errors: 18
'G': 4, 'S': 4, 'D': 3, 'O': 2, '4': 2
Original symbol: '1', number of errors: 17
'T': 6, 'Y': 5, '7': 2, '3': 1, '6': 1
Original symbol: 'L', number of errors: 14
'I': 9, '4': 4, 'C': 1
Original symbol: 'M', number of errors: 14
'H': 7, 'P': 5, '3': 1, 'N': 1
Original symbol: 'E', number of errors: 14
'C': 5, 'I': 3, 'B': 2, 'F': 2, 'A': 1
We will gradually add various types of distortion corresponding to the most common types of errors in the training sample. The number of added “distorted” images must be varied and selected based on the reverse response of the validation sample.
We act according to the following scheme:
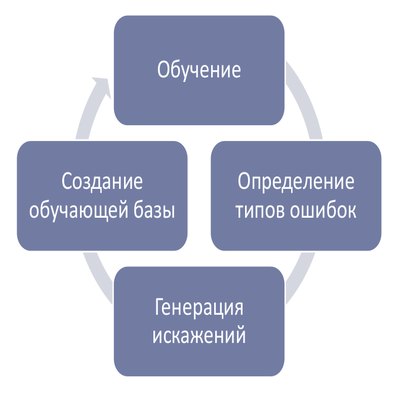
For example, the following was done for this task:
- Adding distortion type “shift” corresponding to the error on the “non-centered” image.
- Conducting a series of experiments: training of several neural networks.
- Quality assessment on the test sample. MRZ recognition quality increased by 9%.
- Analysis of the most frequent recognition errors on the validation sample.
- Adding images with additional lines to the training base.
- Again conducting a series of experiments.
- Testing. The recognition quality of the MRZ on the test sample increased by 3.5%.
Such “iterations” can be repeated many times - until the required quality is achieved or until quality ceases to grow.
In this way, the recognition quality was obtained in 94.5% of correctly recognized zones. Using post-processing (Markov models, finite automata, N-gram and vocabulary methods, etc.), one can get a further increase in quality.
When using training only on artificial data in the considered task, it was possible to achieve only the quality in 81.72% of correctly recognized zones, while the main problem is the difficulty of selecting the distortion parameters.
| Data type for training | Percentage of correctly recognized MRZ | Character error |
|---|---|---|
| Natural Images | 80.78% | 0.253% |
| Natural images + images with shifts | 89.68% | 0.13% |
| + images with additional lines | 93.19% | 0.1% |
| + rotated images | 95.50% | 0.055% |
| Artificial Images | 78.53% | 0.29% |
Conclusion
In conclusion, I would like to note that in each specific case it is necessary to choose your own algorithm for obtaining training data. If the source data is completely absent, it is necessary to generate a sample artificially. If real data is easy to get, you can use a training sample created only from them. And if the real data is not very much, or there are rare errors, the best way is to blow up a set of natural images. In our experience, this latter case occurs most frequently.
Source: https://habr.com/ru/post/264677/
All Articles