Analysis of large semantic cores, or "Robot Recognizer"
They say that meta tags are dead for SEO purposes and there is no longer any reason to prescribe the cherished meta keywords string. Indeed, in modern multi-factor algorithms, this tag has lost its weight. But this does not mean at all that it is necessary to refuse to work with the semantic core of the site - it is still invaluable for structuring the site, forming topics (which search engines are interested in) and even for contextual advertising. Assembling a core is not an easy task, assembling it wisely and not turning it into “throw me synonyms” is even more difficult. So, the article will deal with macros and MS Excel formulas, which will simplify the processing of large semantic cores. We present you a small Excel-robot from our resourceful and not greedy specialist of the RealWeb contextual advertising department Dmitry Tumaykin. Him and the word.

“Hi, Habr! From the very beginning I want to warn readers that the development is not something new on the market in terms of logic and principle of operation, but it has several advantages over other well-known tools:
The file is one of a series of files for contextual advertising specialists (more interesting and very useful “robots” are planned). By the way, the development was created from scratch, and already after the fact it became known that there are already similar macros for table editors on the market - for example, the Devaka publication (macro for OpenOffice) and the development of the MFC-team , which is an adaptation of this macro MS Excel. However, none of the files could satisfy my needs as the needs of a contextual advertising specialist. Our development has its advantages, as described below.
Suppose there is a large semantic core. How it was received, we are not interested. In essence, this is an unstructured set of queries that we would like to structure. How do we do it manually?
Being sincerely believing that laziness is the engine of progress, and having written more than one macro for this reason, I began to look for tools that would allow the entire process to be automated as much as possible. Among the options I have not found one that fully satisfies my requirements. And that's why.
KeyCollector and SlovoEB are multifunctional programs, one of the tasks of which is to collect the semantic core. The first is paid, the second is a stripped-down free version. They have a module "stop words", allowing you to mark phrases in the table containing the data stop words.
Cons of these programs:
http://py7.ru/tools/group/ - tools appeared in the public domain quite recently, but gained serious popularity. The mechanics of this tool is slightly different from KeyCollector, but the problems are the same - errors with word forms, the inability to analyze several categories at the same time.
The aforementioned Devaka and MFC macros. The main problem here is that both macros use a mask search algorithm, i.e. if the word marker is part of any of the words, the entire query falls into this category. As a result, the shorter the word marker is, the more mistakes, with the words B and CU, it is impossible to work a priori, but the upper threshold for characters of even 6 characters does not save you from having to recheck everything that has been done. For example, the word "bathroom" is found in hundreds of verb adjectives (lacquered, corrugated ...). It is clear that in many cases there is no question of relevance.
... I created my own file withblackjack formulas and macros. Without further ado, he simply analyzes whether a word occurs in exact correspondence in your query, so there are no mistakes a priori. Many formulas (Substring, Multicat) are not written from scratch, but are imported from the PLEX add-in (for which special thanks to its creator ).
Now more about the development, comments on the screenshot:
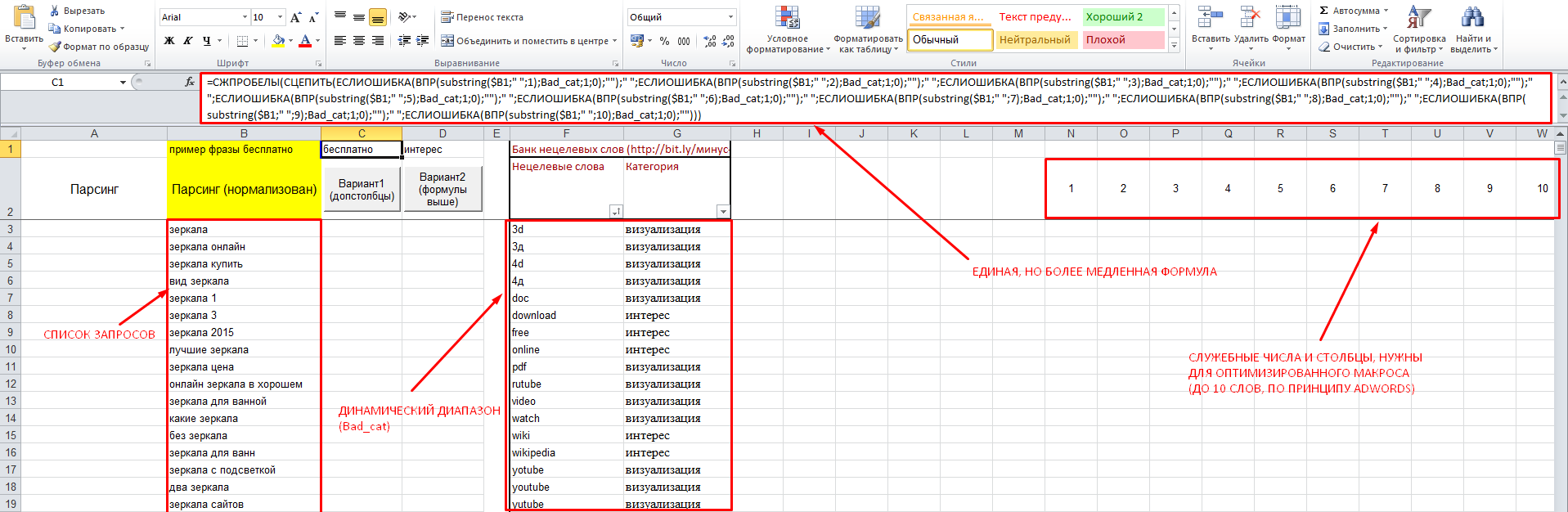
File Link: Robot Recognizer
In the file 2 macros, operating on a simple principle - they are:
An example of a formula that does all this in a single cell is stored in the top row, from where you can simply copy it manually. There is a macro that will do this for you by placing the new data in the range exactly opposite your list of keys (there should not be empty cells in it!). However, this option is more resource intensive, and will make you wait long enough if the number of keywords and the bank minus words is, say, more than 5000. Therefore, a second macro has been created that does the same thing step by step and discards unnecessary calculations along the way.
Recommendations:
Here is a story. Take a file, create semantic kernels, use them in contextual advertising and SEO, make your site better, share your experience with others.
PS: Wishes and bug reports are welcome.
To date, the file uses a linear search for CDF. Later I will lay out the version of the file with binary search, the increase in the speed of calculations on large volumes will be enormous. The list of negative words specified in the file is not a recommendation and can harm you and / or your client, therefore I urge you to check public lists (including this one) for compliance with the subject matter of your client, and supplement it with new words. Formulas and macros work only in the original file, and will not work in others. Using macros in Excel does not harm your health. "
This is the end of the story of Dmitry about creating a useful macro. And we remind that sometimes the most difficult tasks have simple solutions. MS Excel has always been and remains the chief assistant of analysts, specialists in contextual advertising and SEO-optimizers. Its functions, formulas and macros can generate interesting tools that facilitate the work of specialists. And, of course, it will be very nice if some of the developments will be laid out in open access and bring real practical benefits.
“Hi, Habr! From the very beginning I want to warn readers that the development is not something new on the market in terms of logic and principle of operation, but it has several advantages over other well-known tools:
- It is completely free for all users (unlike KeyCollector and a number of other similar services).
- It does not require an internet connection + uses local power (there is a version created for Google Docs, but on large amounts of data it works slower than your computer, even a single-core one, because the corporation good by habit limits the processor power to 1 user.
') - It is an optimized (as far as knowledge of Excel calculation algorithms allows) algorithm for processing large cores.
The file is one of a series of files for contextual advertising specialists (more interesting and very useful “robots” are planned). By the way, the development was created from scratch, and already after the fact it became known that there are already similar macros for table editors on the market - for example, the Devaka publication (macro for OpenOffice) and the development of the MFC-team , which is an adaptation of this macro MS Excel. However, none of the files could satisfy my needs as the needs of a contextual advertising specialist. Our development has its advantages, as described below.
In the meantime, why do you need it?
Suppose there is a large semantic core. How it was received, we are not interested. In essence, this is an unstructured set of queries that we would like to structure. How do we do it manually?
- Having run through the requests with our eyes, we try to understand the general semantic focus, we single out which categories of requests are present in the core.
- We define and highlight marker words that will allow us to assign requests to a particular category. The most primitive variant is “target-non-target”, but it is possible to single out the direction of words. For example, for companies working with e-commerce, wholesale (wholesale, base, warehouse, wholesale ...), information (how, where, difference, comparison, reviews ...) buying (store, buy, price, cost ...) will be popular. , rental (rental, rental, rental, rental ...), geo-markers, etc ...
- We search for each of the requests in the source list with the help of filters, mark these requests. It all depends on the imagination - if we have only two options, then it is enough just to mark the requests with different colors. If there are a lot of options to avoid confusion, we could mark opposite the queries in the adjacent column in the same column the name of the same category to which the marker word contained in the query belongs. And so that everything is even more obvious, you can indicate in the additional column the word marker itself. By the end I came to this.
- After everything is laid out “on the shelves” in this way - we use the resulting lists for our own purposes. Experts contextual advertising expose adjustments rates depending on the category of the request (for example, the “warmer” the request, the higher the rate), or “minus” completely untargeted requests.
Being sincerely believing that laziness is the engine of progress, and having written more than one macro for this reason, I began to look for tools that would allow the entire process to be automated as much as possible. Among the options I have not found one that fully satisfies my requirements. And that's why.
KeyCollector and SlovoEB are multifunctional programs, one of the tasks of which is to collect the semantic core. The first is paid, the second is a stripped-down free version. They have a module "stop words", allowing you to mark phrases in the table containing the data stop words.
Cons of these programs:
- It is impossible to use several categories at once, since phrases will be simply marked in the table. Therefore, the analysis of the kernel for the presence of requests of a certain category should be performed exactly as many times as you have categories.
- If you use a search that does not depend on word forms, then there may be collation errors, for example, “underwear” and “white” are considered morphemes of one word.
http://py7.ru/tools/group/ - tools appeared in the public domain quite recently, but gained serious popularity. The mechanics of this tool is slightly different from KeyCollector, but the problems are the same - errors with word forms, the inability to analyze several categories at the same time.
The aforementioned Devaka and MFC macros. The main problem here is that both macros use a mask search algorithm, i.e. if the word marker is part of any of the words, the entire query falls into this category. As a result, the shorter the word marker is, the more mistakes, with the words B and CU, it is impossible to work a priori, but the upper threshold for characters of even 6 characters does not save you from having to recheck everything that has been done. For example, the word "bathroom" is found in hundreds of verb adjectives (lacquered, corrugated ...). It is clear that in many cases there is no question of relevance.
And that is why ...
... I created my own file with
Now more about the development, comments on the screenshot:
File Link: Robot Recognizer
In the file 2 macros, operating on a simple principle - they are:
- Divide requests for words (space is considered a separator). According to the AdWords principle, only the first 10 words.
- Each of the words is compared with a bank of negative keywords, which is a named dynamic range, i.e. words can be added to it up to the end of the column, and the macro will adapt to each option, taking the more CPU time, the larger the “bank”, and vice versa.
- If they find a word in the bank, they return it; if they don’t find it, they return “two quotes” (empty result).
- A simple CDF formula (vertical scan) returns the category of each of the words from the adjacent column.
- Glue all the parameters together (separated by a space) and display them in the appropriate columns opposite.
An example of a formula that does all this in a single cell is stored in the top row, from where you can simply copy it manually. There is a macro that will do this for you by placing the new data in the range exactly opposite your list of keys (there should not be empty cells in it!). However, this option is more resource intensive, and will make you wait long enough if the number of keywords and the bank minus words is, say, more than 5000. Therefore, a second macro has been created that does the same thing step by step and discards unnecessary calculations along the way.
Recommendations:
- To speed up the macro, it is recommended that "bank negative words" be in a sorted “AZ” (by word).
- Using normalized lists (both keys and negative keywords) will significantly speed up calculations in the file and your work, since narrows the semantic core.
- But be careful with them (check the final list). So, “Delhi” (city) and “Divide” - conditionally for normalization programs - the same word. Similar examples are "tea" and "tea" or "covers" and "cover"
- Do not be lazy to make your own lists of negative keywords for different topics and share them with colleagues.
- The file can be used to catalog any kernels for any groups of queries, i.e. It is not necessary to use negative keywords. It all depends on the task and imagination.
Here is a story. Take a file, create semantic kernels, use them in contextual advertising and SEO, make your site better, share your experience with others.
PS: Wishes and bug reports are welcome.
To date, the file uses a linear search for CDF. Later I will lay out the version of the file with binary search, the increase in the speed of calculations on large volumes will be enormous. The list of negative words specified in the file is not a recommendation and can harm you and / or your client, therefore I urge you to check public lists (including this one) for compliance with the subject matter of your client, and supplement it with new words. Formulas and macros work only in the original file, and will not work in others. Using macros in Excel does not harm your health. "
This is the end of the story of Dmitry about creating a useful macro. And we remind that sometimes the most difficult tasks have simple solutions. MS Excel has always been and remains the chief assistant of analysts, specialists in contextual advertising and SEO-optimizers. Its functions, formulas and macros can generate interesting tools that facilitate the work of specialists. And, of course, it will be very nice if some of the developments will be laid out in open access and bring real practical benefits.
Source: https://habr.com/ru/post/264591/
All Articles