SMR: understandable in theory, difficult to practice
Today, data growth per person is growing exponentially, and companies offering storage solutions for this data strive to do their utmost to increase the available capacity of their devices. Seagate SMR (Shingled Magnetic Recording) tiled magnetic recording technology improves recording density, increasing disk capacity by 25%. This is possible by increasing the number of tracks on each plate and reducing the distance between them. The tracks are placed one above the other (like tiles on the roof), which allows you to record more data without increasing the area of the plate. When recording new data, the tracks partially overlap or are truncated. Due to the fact that the reading element on the disk head is smaller than the writing one, it can read data even from a truncated track without disturbing its integrity and reliability.
However, the following problem is associated with the SMR technology: in order to overwrite or update the information, it is necessary to rewrite not only the required fragment, but also the data on the last tracks. Due to the fact that the recording element is wider, it captures data on the adjacent tracks, so you need to overwrite it. Thus, when changing data on the lower track, you need to correct the data on the nearest superimposed track, then on the next one, and so on, until the entire plate is rewritten.
For this reason, the tracks of the SMR disk are grouped into small groups called tapes. Superimposed on each other, respectively, only the tracks within the same tape. Due to such grouping, in the case of updating some data, it will not be necessary to rewrite the entire plate, but only a limited number of tracks, which greatly simplifies and speeds up the process. For each type of discs, its own tape architecture is developed, taking into account its scope. Each Seagate product line is designed for a specific scope and specific working conditions, and SMR technology allows you to achieve the best results when used correctly.
')
Seagate SMR is a technology to meet the ever-growing demand for additional capacity. Today, it is being actively improved and, in combination with other innovative methods, can be used to increase the recording density on the next generation of hard drives.
But first of all, it is necessary to understand some of the nuances of its application.
There are three types of devices that support tiled writing:
Standalone (Drive Managed)
Working with these devices does not require any changes to the host software. All write / read logic is organized by the device itself. Does it mean we can just set them and relax? Not.
Drives that implement Drive Managed write technology usually have a large write-back cache (from 128 MB to disk). In this case, successive requests are processed in write-around mode. The main difficulties faced by developers of devices and storage systems based on this recording technology are the following:
1. The cache size is limited and as it is filled we can get unpredictable device performance.
2. Sometimes there are significant levels of delays with an intensive cache flush.
3. Determination of sequences is not always a trivial task, and in difficult cases we can expect degradation of performance.
The main advantage of this approach is the complete backward compatibility of devices with existing operating systems and applications. By understanding your task well, you can now buy Drive Managed devices and benefit from the use of technology. Further in the article you will see the results of testing such devices and be able to determine how they suit you.
Host Managed
These devices use a set of extensions to ATA and SCSI to interact with the disks. This is a different type of device (14h), which requires major changes in the entire Storage Stack and is incompatible with classical technologies, that is, without special adaptation of applications and operating systems, you will not be able to use these disks. The host must write to the devices strictly sequentially. At the same time, device performance is 100% predictable. But the correct operation of the higher-level software is necessary in order for the performance of the storage subsystem to be truly predictable.
Supported by the host (Host Aware)
These are hybrid solutions combining the advantages of Device Managed and Host Managed technologies. By purchasing such disks, we get support for backward compatibility with the possibility of using special ATA and SCSI extensions for optimal operation with SMR devices. That is, we can, as it is easy to write to devices, as we did before, and to do it in the most optimal way.
In order to work with Host Managed and Host Aware devices, a pair of new standards are being developed: ZBC and ZAC, which are included in T10 / T13. ZBC is an SCSI extension and is ratified by T10. Standards are being developed for SMR disks, but in the future they may be applied to other devices.
ZBC / ZAC define a logical model of devices, where the main element is the zone that is displayed as an LBA range.
Standards define three types of logical zones into which devices are broken down:
1. Conventional zone - a zone with which we can work in the traditional way, as with ordinary hard drives. That is, we can write consistently and randomly.
2. Two types of Write Pointer Zone:
2.1. Sequential write preferred - the main type of zones for Host Aware devices, preference is given to sequential write. Random writing to devices is handled as in Device Managed devices and can cause performance loss.
2.2. Sequential write only is the main zone type for Host Manged devices, only sequential write is possible. Random entry is not allowed, if you attempt to produce it, an error will be returned.
Each zone has its own Write Pointer and its status. For all devices that support HM write type, the first LBA of the next write command must necessarily correspond to the position of Write Pointer. For HA devices, the Write Pointer is informational and serves to optimize disk handling.
In addition to the new logical structure, new commands appear in the standards:
REPORT_ZONES is the main method by which you can get information about existing zones on the device and their status. The disk in response to this command reports the existing zones, their types (Conventional, Sequential Write Required, Sequential Write Preferred), state of the zones, size, information about finding Write Pointer.
RESET_WRITE_POINTER is the successor to the TRIM command for ZBC devices. When you call it, the zone is erased and Write Pointer is moved to the beginning of the zone.
To control the status of a zone, 3 optional commands are used:
OPEN_ZONE
CLOSE_ZONE
FINISH_ZONE
In the VPD pages, new information has appeared, including the maximum number of open zones, providing the best performance and the maximum number of zones available for random recording with the best performance.
Storage manufacturers need to take care of the support of HA / HM devices, making changes at all levels of the stack: libraries, schedulers, RAID engine, logical volumes, file systems.
In addition, you need to provide two types of interfaces for applications: the traditional interface, organizing an array as a device-managed device, and the implementation of a virtual volume as a HOST AWARE device. This is necessary because applications are expected to work directly with HM / HA devices.
In general, the algorithm for working with HA devices is as follows:
1. Determine the device configuration using the REPORT_ZONES
2. Define zones for random recording.
2.1. Quantity limited by device capabilities
2.2. In these zones, there is no need to track the position of the Write Pointer.
3. Use the remaining zones for sequential writing and using Write-Pointer position information and performing only sequential writing.
4. Control the number of open zones
5. Use garbage collection to release a pool of zones.
Some recording techniques can be applied from existing all-flash storage systems for which problems of prostate sequential recording and garbage collection were solved.
RAIDIX has tested Seagate SMR drives in their lab and gives several recommendations for using them. These disks differ in that they are Device Managed and do not require any major changes in the operation of applications.
During testing, an attempt was made to test the performance expectations of such disks and to understand why we can use them.
Two Seagate Archive HDD 8000GB drives participated in the tests.
Testing was performed on the Debian operating system version 8.1
CPU Intel i7 c 2.67 MHz
16 GB RAM
The drives have SATA 3 interface, we included the controller in AHCI mode.
To begin with, we provide information about devices by making an Inquiry inquiry.
Nothing special, we have not seen. Attempts to read information about the zones turned out to be a failure.
RAIDIX makes software for storage systems operating in various industries, and we tried not to use specialized or paid benchmarks.
We start with the fact that we check the streaming performance of disks on internal and external tracks. The test results will give the maximum expected performance of the device and correspond primarily to tasks such as data archiving.
We did not touch the block subsystem settings. We perform testing, writing data to the disks in blocks of 1 megabyte. For this we use the benchmark fio v.2.1.11.
Jobs differ from each other only by the offset from the beginning of the device and are launched one by one. Libaio is selected as the I / O library.
The results are pretty good:
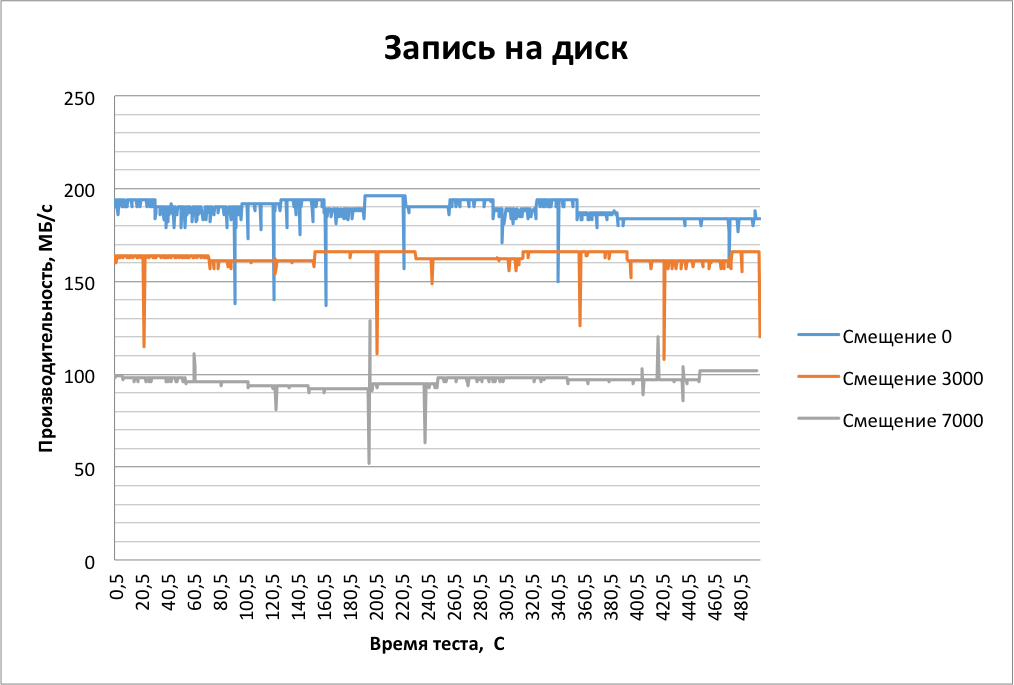
Performance on the external and internal lanes differs almost 2 times.
We see occasional dips in performance. They are not critical for archiving, but can be a problem for other tasks. When the storage cache write-back works correctly, we assume that we will not observe such a situation. We had a similar experience, creating a RAID 0 array from both disks, allocating 2GB of RAM cache to each disk, and did not see performance failures.
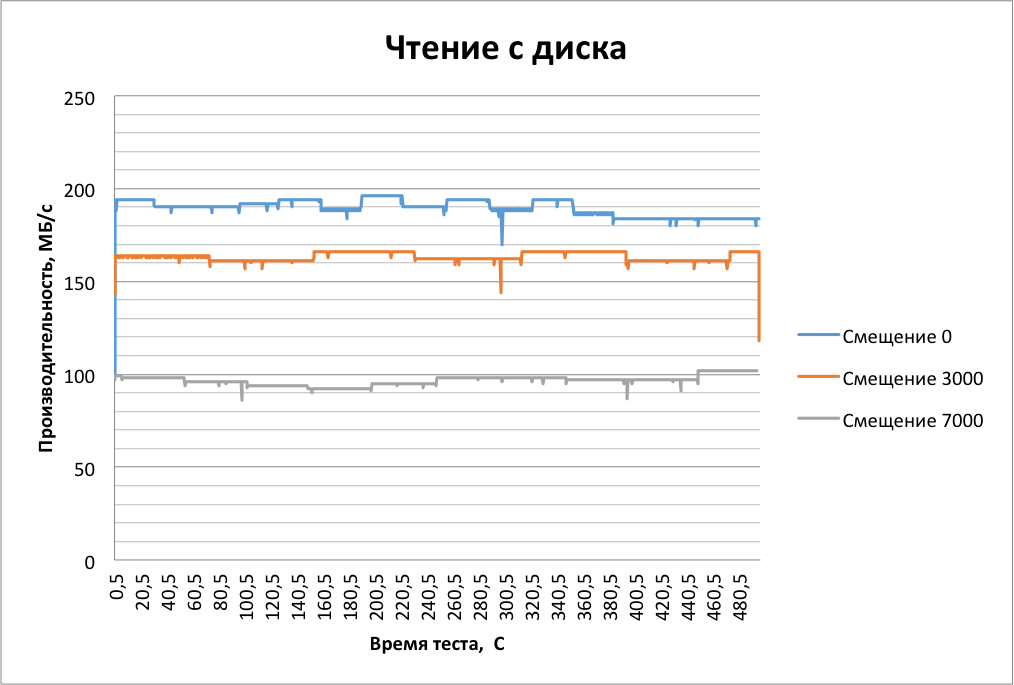
When reading the failures are not visible. And subsequent tests will show that the read performance of SMR drives in performance is no different from normal.
Now we will conduct more interesting tests. Run 10 threads with different offset at the same time. We do this in order to check the correctness of buffering and see how the discs will work on the tasks of CCTV, Video Ingest and the like.
The graphs show the total performance for all jobs:

The disk coped well with the load!
Performance is kept at 90 MB / s, evenly distributed over the streams, and there are no serious failures. The reading schedule is absolutely similar, only raised by 20 MB. For storing and distributing video content, sharing large files, the performance is suitable and practically does not differ from the performance of ordinary disks.
Predictably, the disks performed well on streaming read and write operations, and working in several streams was a pleasant surprise for us.
We proceed to the "random" reading and writing. Let's see how disks behave in classic enterprise tasks: storing DBMS files, virtualization, etc. In addition, “random” operations include frequent work with metadata and, for example, deduplication enabled on an array.
Testing is carried out in blocks of 16 kilobytes and is still true fio.
In the test, we set up several jobs with different queue depths, but we will not give full results. Only the beginning of the test is significant.

The first 70.5 seconds we see unrealistic for a hard disk 2500 IOps. When this happens frequent failures. Apparently, at this moment there is a recording in the buffer and its periodic reset. Then there is a sharp drop to 3 IOps, which are held until the end of the test.
If you wait a few minutes, then after the cache is reset, the situation will repeat.
It can be expected that in the presence of a small number of random operations, the disk will behave well. But if we expect a heavy load on the device, it is better to refrain from using SMR disks. If possible, RAIDIX recommends that all work with metadata be transferred to external devices.
And what about random reading?
In this test, we limited the response time to 50 ms. Our devices are doing well.

Reading is between 144-165 IOPs. The numbers themselves are not bad, but the scatter of 20 IOPs is a bit scary. Focus on the lower boundary. The result is not bad, at the level of classic discs.
Let's change the approach a little. Let's take another look at working with a large number of files.
The SGS frametest utility will help us with this. This benchmark is designed to test the performance of the storage system when editing uncompressed video. Each frame is a separate file.
We created the xfs file system and mounted it with the following parameters:
-o noatime, nodiratime, logbufs = 8, logbsize = 256k, largeio, inode64, swalloc, allocsize = 131072k, nobarrier
We start frametest with the following parameters:
./frametest -w hd -n 2000 / test1 /
The benchmark creates 2,000 files of 8MB size.
The beginning of the test goes well:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.028 ms 79.40 ms 79.43 ms 100.37 MB / s 12.6 fps
5s: 0.156 ms 83.37 ms 83.53 ms 95.44 MB / s 12.0 fps
But after recording 1500 frames, the situation worsens significantly:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.035 ms 121.88 ms 121.92 ms 65.39 MB / s 8.2 fps
5s: 0.036 ms 120.78 ms 120.83 ms 65.98 MB / s 8.3 fps
Then everything is worse:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.036 ms 438.90 ms 438.94 ms 18.16 MB / s 2.3 fps
5s: 0.035 ms 393.50 ms 393.55 ms 20.26 MB / s 2.5 fps
Let's carry out the test for reading:
./frametest -r hd -n 2000 / test1 /
Throughout the test, the performance is excellent:
Averaged details:
Last 1s: 0.004 ms 41.09 ms 41.10 ms 193.98 MB / s 24.3 fps
5s: 0.004 ms 41.09 ms 41.10 ms 193.98 MB / s 24.3 fps
Now work is underway on specialized file systems for SMR disks.
Seagate is developing an ext4 based SMR_FS-EXT4. You can find several log-structured file systems designed specifically for Device Managed SMR disks, but none of them can be called a mature, recommended product for implementation. Seagate is also developing a host-supported (Host Aware) version of the SMR disk, which must be completed before the end of the year.
What conclusions can we draw from the results of performance measurements?
Device Managed devices can be safely used for tasks that do not differ intensive recording. They do a very good job with single-threaded and multi-threaded recording tasks. They are great for reading data. Periodic “random” requests to disks when updating metadata are absorbed by a large cache.
For solving problems characterized by intensive “random” recording or updating a large number of files, such devices are not very suitable, at least, without the use of additional technical means.
The MTBF parameter of the tested disks is 800,000 hours, which is 1.5 times lower than that of, for example, NAS disks. A large volume of disks significantly increases recovery time and makes it almost impossible to have a regular media scan. We recommend when designing storage with such disks to rely on a RAID with a parity number greater than 2 and / or approaches that reduce recovery time (For example, Parity Declustering).
However, the following problem is associated with the SMR technology: in order to overwrite or update the information, it is necessary to rewrite not only the required fragment, but also the data on the last tracks. Due to the fact that the recording element is wider, it captures data on the adjacent tracks, so you need to overwrite it. Thus, when changing data on the lower track, you need to correct the data on the nearest superimposed track, then on the next one, and so on, until the entire plate is rewritten.
For this reason, the tracks of the SMR disk are grouped into small groups called tapes. Superimposed on each other, respectively, only the tracks within the same tape. Due to such grouping, in the case of updating some data, it will not be necessary to rewrite the entire plate, but only a limited number of tracks, which greatly simplifies and speeds up the process. For each type of discs, its own tape architecture is developed, taking into account its scope. Each Seagate product line is designed for a specific scope and specific working conditions, and SMR technology allows you to achieve the best results when used correctly.
')
Seagate SMR is a technology to meet the ever-growing demand for additional capacity. Today, it is being actively improved and, in combination with other innovative methods, can be used to increase the recording density on the next generation of hard drives.
But first of all, it is necessary to understand some of the nuances of its application.
There are three types of devices that support tiled writing:
Standalone (Drive Managed)
Working with these devices does not require any changes to the host software. All write / read logic is organized by the device itself. Does it mean we can just set them and relax? Not.
Drives that implement Drive Managed write technology usually have a large write-back cache (from 128 MB to disk). In this case, successive requests are processed in write-around mode. The main difficulties faced by developers of devices and storage systems based on this recording technology are the following:
1. The cache size is limited and as it is filled we can get unpredictable device performance.
2. Sometimes there are significant levels of delays with an intensive cache flush.
3. Determination of sequences is not always a trivial task, and in difficult cases we can expect degradation of performance.
The main advantage of this approach is the complete backward compatibility of devices with existing operating systems and applications. By understanding your task well, you can now buy Drive Managed devices and benefit from the use of technology. Further in the article you will see the results of testing such devices and be able to determine how they suit you.
Host Managed
These devices use a set of extensions to ATA and SCSI to interact with the disks. This is a different type of device (14h), which requires major changes in the entire Storage Stack and is incompatible with classical technologies, that is, without special adaptation of applications and operating systems, you will not be able to use these disks. The host must write to the devices strictly sequentially. At the same time, device performance is 100% predictable. But the correct operation of the higher-level software is necessary in order for the performance of the storage subsystem to be truly predictable.
Supported by the host (Host Aware)
These are hybrid solutions combining the advantages of Device Managed and Host Managed technologies. By purchasing such disks, we get support for backward compatibility with the possibility of using special ATA and SCSI extensions for optimal operation with SMR devices. That is, we can, as it is easy to write to devices, as we did before, and to do it in the most optimal way.
In order to work with Host Managed and Host Aware devices, a pair of new standards are being developed: ZBC and ZAC, which are included in T10 / T13. ZBC is an SCSI extension and is ratified by T10. Standards are being developed for SMR disks, but in the future they may be applied to other devices.
ZBC / ZAC define a logical model of devices, where the main element is the zone that is displayed as an LBA range.
Standards define three types of logical zones into which devices are broken down:
1. Conventional zone - a zone with which we can work in the traditional way, as with ordinary hard drives. That is, we can write consistently and randomly.
2. Two types of Write Pointer Zone:
2.1. Sequential write preferred - the main type of zones for Host Aware devices, preference is given to sequential write. Random writing to devices is handled as in Device Managed devices and can cause performance loss.
2.2. Sequential write only is the main zone type for Host Manged devices, only sequential write is possible. Random entry is not allowed, if you attempt to produce it, an error will be returned.
Each zone has its own Write Pointer and its status. For all devices that support HM write type, the first LBA of the next write command must necessarily correspond to the position of Write Pointer. For HA devices, the Write Pointer is informational and serves to optimize disk handling.
In addition to the new logical structure, new commands appear in the standards:
REPORT_ZONES is the main method by which you can get information about existing zones on the device and their status. The disk in response to this command reports the existing zones, their types (Conventional, Sequential Write Required, Sequential Write Preferred), state of the zones, size, information about finding Write Pointer.
RESET_WRITE_POINTER is the successor to the TRIM command for ZBC devices. When you call it, the zone is erased and Write Pointer is moved to the beginning of the zone.
To control the status of a zone, 3 optional commands are used:
OPEN_ZONE
CLOSE_ZONE
FINISH_ZONE
In the VPD pages, new information has appeared, including the maximum number of open zones, providing the best performance and the maximum number of zones available for random recording with the best performance.
Storage manufacturers need to take care of the support of HA / HM devices, making changes at all levels of the stack: libraries, schedulers, RAID engine, logical volumes, file systems.
In addition, you need to provide two types of interfaces for applications: the traditional interface, organizing an array as a device-managed device, and the implementation of a virtual volume as a HOST AWARE device. This is necessary because applications are expected to work directly with HM / HA devices.
In general, the algorithm for working with HA devices is as follows:
1. Determine the device configuration using the REPORT_ZONES
2. Define zones for random recording.
2.1. Quantity limited by device capabilities
2.2. In these zones, there is no need to track the position of the Write Pointer.
3. Use the remaining zones for sequential writing and using Write-Pointer position information and performing only sequential writing.
4. Control the number of open zones
5. Use garbage collection to release a pool of zones.
Some recording techniques can be applied from existing all-flash storage systems for which problems of prostate sequential recording and garbage collection were solved.
RAIDIX has tested Seagate SMR drives in their lab and gives several recommendations for using them. These disks differ in that they are Device Managed and do not require any major changes in the operation of applications.
During testing, an attempt was made to test the performance expectations of such disks and to understand why we can use them.
Two Seagate Archive HDD 8000GB drives participated in the tests.
Testing was performed on the Debian operating system version 8.1
CPU Intel i7 c 2.67 MHz
16 GB RAM
The drives have SATA 3 interface, we included the controller in AHCI mode.
To begin with, we provide information about devices by making an Inquiry inquiry.
For this, we used the sg3-utils utility set.
sg_inq / dev / sdb
standard INQUIRY:
PQual = 0 Device_type = 0 RMB = 0 version = 0x05 [SPC-3]
[AERC = 0] [TrmTsk = 0] NormACA = 0 HiSUP = 0 Resp_data_format = 2
SCCS = 0 ACC = 0 TPGS = 0 3PC = 0 Protect = 0 BQue = 0
EncServ = 0 MultiP = 0 [MChngr = 0] [ACKREQQ = 0] Addr16 = 0
[RelAdr = 0] WBus16 = 0 Sync = 0 Linked = 0 [TranDis = 0] CmdQue = 0
[SPI: Clocking = 0x0 QAS = 0 IUS = 0]
length = 96 (0x60) Peripheral device type: disk
Vendor identification: ATA
Product identification: ST8000AS0002-1NA
Product revision level: AR13
Unit serial number: Z84011LQ
standard INQUIRY:
PQual = 0 Device_type = 0 RMB = 0 version = 0x05 [SPC-3]
[AERC = 0] [TrmTsk = 0] NormACA = 0 HiSUP = 0 Resp_data_format = 2
SCCS = 0 ACC = 0 TPGS = 0 3PC = 0 Protect = 0 BQue = 0
EncServ = 0 MultiP = 0 [MChngr = 0] [ACKREQQ = 0] Addr16 = 0
[RelAdr = 0] WBus16 = 0 Sync = 0 Linked = 0 [TranDis = 0] CmdQue = 0
[SPI: Clocking = 0x0 QAS = 0 IUS = 0]
length = 96 (0x60) Peripheral device type: disk
Vendor identification: ATA
Product identification: ST8000AS0002-1NA
Product revision level: AR13
Unit serial number: Z84011LQ
On page 83 is the VPD.
sg_inq / dev / sdb -p 0x83
VPD INQUIRY: Device Identification page
Designation descriptor number 1, descriptor length: 24
designator_type: vendor specific [0x0], code_set: ASCII
associated with the preferred logical unit
vendor specific: Z84011LQ
Designation descriptor number 2, descriptor length: 72
designator_type: T10 vendor identification, code_set: ASCII
associated with the preferred logical unit
vendor id: ATA
vendor specific: ST8000AS0002-1NA17Z Z84011LQ
VPD INQUIRY: Device Identification page
Designation descriptor number 1, descriptor length: 24
designator_type: vendor specific [0x0], code_set: ASCII
associated with the preferred logical unit
vendor specific: Z84011LQ
Designation descriptor number 2, descriptor length: 72
designator_type: T10 vendor identification, code_set: ASCII
associated with the preferred logical unit
vendor id: ATA
vendor specific: ST8000AS0002-1NA17Z Z84011LQ
Nothing special, we have not seen. Attempts to read information about the zones turned out to be a failure.
RAIDIX makes software for storage systems operating in various industries, and we tried not to use specialized or paid benchmarks.
We start with the fact that we check the streaming performance of disks on internal and external tracks. The test results will give the maximum expected performance of the device and correspond primarily to tasks such as data archiving.
We did not touch the block subsystem settings. We perform testing, writing data to the disks in blocks of 1 megabyte. For this we use the benchmark fio v.2.1.11.
Jobs differ from each other only by the offset from the beginning of the device and are launched one by one. Libaio is selected as the I / O library.
The results are pretty good:
Performance on the external and internal lanes differs almost 2 times.
We see occasional dips in performance. They are not critical for archiving, but can be a problem for other tasks. When the storage cache write-back works correctly, we assume that we will not observe such a situation. We had a similar experience, creating a RAID 0 array from both disks, allocating 2GB of RAM cache to each disk, and did not see performance failures.
When reading the failures are not visible. And subsequent tests will show that the read performance of SMR drives in performance is no different from normal.
Now we will conduct more interesting tests. Run 10 threads with different offset at the same time. We do this in order to check the correctness of buffering and see how the discs will work on the tasks of CCTV, Video Ingest and the like.
The graphs show the total performance for all jobs:
The disk coped well with the load!
Performance is kept at 90 MB / s, evenly distributed over the streams, and there are no serious failures. The reading schedule is absolutely similar, only raised by 20 MB. For storing and distributing video content, sharing large files, the performance is suitable and practically does not differ from the performance of ordinary disks.
Predictably, the disks performed well on streaming read and write operations, and working in several streams was a pleasant surprise for us.
We proceed to the "random" reading and writing. Let's see how disks behave in classic enterprise tasks: storing DBMS files, virtualization, etc. In addition, “random” operations include frequent work with metadata and, for example, deduplication enabled on an array.
Testing is carried out in blocks of 16 kilobytes and is still true fio.
In the test, we set up several jobs with different queue depths, but we will not give full results. Only the beginning of the test is significant.
The first 70.5 seconds we see unrealistic for a hard disk 2500 IOps. When this happens frequent failures. Apparently, at this moment there is a recording in the buffer and its periodic reset. Then there is a sharp drop to 3 IOps, which are held until the end of the test.
If you wait a few minutes, then after the cache is reset, the situation will repeat.
It can be expected that in the presence of a small number of random operations, the disk will behave well. But if we expect a heavy load on the device, it is better to refrain from using SMR disks. If possible, RAIDIX recommends that all work with metadata be transferred to external devices.
And what about random reading?
In this test, we limited the response time to 50 ms. Our devices are doing well.
Reading is between 144-165 IOPs. The numbers themselves are not bad, but the scatter of 20 IOPs is a bit scary. Focus on the lower boundary. The result is not bad, at the level of classic discs.
Let's change the approach a little. Let's take another look at working with a large number of files.
The SGS frametest utility will help us with this. This benchmark is designed to test the performance of the storage system when editing uncompressed video. Each frame is a separate file.
We created the xfs file system and mounted it with the following parameters:
-o noatime, nodiratime, logbufs = 8, logbsize = 256k, largeio, inode64, swalloc, allocsize = 131072k, nobarrier
We start frametest with the following parameters:
./frametest -w hd -n 2000 / test1 /
The benchmark creates 2,000 files of 8MB size.
The beginning of the test goes well:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.028 ms 79.40 ms 79.43 ms 100.37 MB / s 12.6 fps
5s: 0.156 ms 83.37 ms 83.53 ms 95.44 MB / s 12.0 fps
But after recording 1500 frames, the situation worsens significantly:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.035 ms 121.88 ms 121.92 ms 65.39 MB / s 8.2 fps
5s: 0.036 ms 120.78 ms 120.83 ms 65.98 MB / s 8.3 fps
Then everything is worse:
Averaged details:
Open I / O Frame Data Rate Frame Rate
Last 1s: 0.036 ms 438.90 ms 438.94 ms 18.16 MB / s 2.3 fps
5s: 0.035 ms 393.50 ms 393.55 ms 20.26 MB / s 2.5 fps
Let's carry out the test for reading:
./frametest -r hd -n 2000 / test1 /
Throughout the test, the performance is excellent:
Averaged details:
Last 1s: 0.004 ms 41.09 ms 41.10 ms 193.98 MB / s 24.3 fps
5s: 0.004 ms 41.09 ms 41.10 ms 193.98 MB / s 24.3 fps
Now work is underway on specialized file systems for SMR disks.
Seagate is developing an ext4 based SMR_FS-EXT4. You can find several log-structured file systems designed specifically for Device Managed SMR disks, but none of them can be called a mature, recommended product for implementation. Seagate is also developing a host-supported (Host Aware) version of the SMR disk, which must be completed before the end of the year.
What conclusions can we draw from the results of performance measurements?
Device Managed devices can be safely used for tasks that do not differ intensive recording. They do a very good job with single-threaded and multi-threaded recording tasks. They are great for reading data. Periodic “random” requests to disks when updating metadata are absorbed by a large cache.
For solving problems characterized by intensive “random” recording or updating a large number of files, such devices are not very suitable, at least, without the use of additional technical means.
The MTBF parameter of the tested disks is 800,000 hours, which is 1.5 times lower than that of, for example, NAS disks. A large volume of disks significantly increases recovery time and makes it almost impossible to have a regular media scan. We recommend when designing storage with such disks to rely on a RAID with a parity number greater than 2 and / or approaches that reduce recovery time (For example, Parity Declustering).
Source: https://habr.com/ru/post/264553/
All Articles