Recognition of Cyrillic Yandex Captcha
This article continues the cycle about the features, weaknesses and directly about the recognition of popular captcha.
In the previous publication, we touched upon a ready-made KCAPTCHA solution, which, despite good security, was recognized without any serious preprocessing and segmentation, the usual multi-layer perceptron.
Now the next step is Cyrillic Yandex captcha, with which, I am sure, many of us are very familiar.
So, we have such captcha:
')

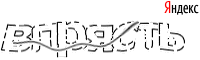
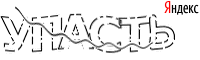
Conditionally divide the recognition into the following steps:
Remove the Yandex logo and auto-frame the image:
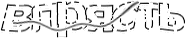
Normalize the input data:
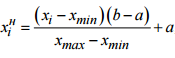
Where x is the color values of pixels, [a, b] is the interval of allowable values of input signals. In our case, from -1 to 1.
For recognition of the length of the captcha meets the network with 4 neurons of the output layer, each of which corresponds to the value of length from 4 to 7.
Now, knowing the length of the captcha, it remains only to divide the image into equal parts, for further recognition:

For recognition of letters, a network of two layers is used.
The first layer is trained and consists of 900 neurons, the output consists of 31 neurons, each of which corresponds to a letter in the picture.
The initial training sample was prepared thanks to adetachment of Russian-speaking antigate Hindus and amounted to 2,000 captchas, after a short network training, Yandex itself acted as a teacher and a previously prepared dictionary of 387,143 words from 4 to 7 characters, based on data from Yandex dictionaries.
The potentially correct answers of the network, which are present in the dictionary, were sent to Yandex for review, which resulted in training, which significantly reduced the cost of further sampling.
During the day, the recognition accuracy of each character in 70% was obtained.
After receiving the result of recognition, it is checked for its presence in the dictionary.
If the recognition result is not in the dictionary, most likely it is not true.
Often there are errors between similar characters, for example, n - and, s - e, b - s, n - l.
In this case, based on the responses of the network, select the most likely letters and look for the corresponding words in the dictionary.
If there are no words, select options with the same length and minimum Levenshtein distance.
This option gives 18% captcha recognition accuracy.
You can also use the frequency distribution of letters and their combinations in the Russian language, not to mention the ready-made solutions to check spelling, in any case, many options.
Even a simple pryuning of results that are absent in the dictionary discards a significant part of the wrong options.
As I said earlier, if desired, and due to the number of examples, any captcha understandable [and not only] to a person is recognizable. Emphasis should be placed not on the complexity of the image itself, but on technologies to detect bots, until they themselves began to identify and screen out people.
Cyrillic Yandex captcha is rather weak, but rather more friendly for Russian-speaking users than, for example, kcaptcha or recaptcha (especially the first version).
I am sure that in the near future the guys from Yandex will work on their captcha and will be able to reach a compromise between reliability and convenience for ordinary people.
If you want to test or understand the work of the network - welcome to GitHub .
PS If you have interesting problems in this area - I will be glad to help .
In the previous publication, we touched upon a ready-made KCAPTCHA solution, which, despite good security, was recognized without any serious preprocessing and segmentation, the usual multi-layer perceptron.
Now the next step is Cyrillic Yandex captcha, with which, I am sure, many of us are very familiar.
So, we have such captcha:
')
Special features
- Variable length
- Distortions
- Noise (curve)
- Cyrillic letters
- Trendy logo in the upper right corner
Weak sides
- Distortions are minor, do not hinder segmentation
- Noises only slightly complicate the recognition
- The limited dictionary allows you to weed out the wrong options and adjust the network responses
Decision
Conditionally divide the recognition into the following steps:
- Preliminary processing
- Location lookup and text segmentation
- Recognition
- Final result processing
Preliminary processing
Remove the Yandex logo and auto-frame the image:
Normalize the input data:
Where x is the color values of pixels, [a, b] is the interval of allowable values of input signals. In our case, from -1 to 1.
Location lookup and text segmentation
For recognition of the length of the captcha meets the network with 4 neurons of the output layer, each of which corresponds to the value of length from 4 to 7.
Now, knowing the length of the captcha, it remains only to divide the image into equal parts, for further recognition:
Recognition
For recognition of letters, a network of two layers is used.
The first layer is trained and consists of 900 neurons, the output consists of 31 neurons, each of which corresponds to a letter in the picture.
The initial training sample was prepared thanks to a
The potentially correct answers of the network, which are present in the dictionary, were sent to Yandex for review, which resulted in training, which significantly reduced the cost of further sampling.
During the day, the recognition accuracy of each character in 70% was obtained.
Final result processing
After receiving the result of recognition, it is checked for its presence in the dictionary.
If the recognition result is not in the dictionary, most likely it is not true.
Often there are errors between similar characters, for example, n - and, s - e, b - s, n - l.
In this case, based on the responses of the network, select the most likely letters and look for the corresponding words in the dictionary.
If there are no words, select options with the same length and minimum Levenshtein distance.
This option gives 18% captcha recognition accuracy.
You can also use the frequency distribution of letters and their combinations in the Russian language, not to mention the ready-made solutions to check spelling, in any case, many options.
Even a simple pryuning of results that are absent in the dictionary discards a significant part of the wrong options.
Conclusion
As I said earlier, if desired, and due to the number of examples, any captcha understandable [and not only] to a person is recognizable. Emphasis should be placed not on the complexity of the image itself, but on technologies to detect bots, until they themselves began to identify and screen out people.
Cyrillic Yandex captcha is rather weak, but rather more friendly for Russian-speaking users than, for example, kcaptcha or recaptcha (especially the first version).
I am sure that in the near future the guys from Yandex will work on their captcha and will be able to reach a compromise between reliability and convenience for ordinary people.
Sources
If you want to test or understand the work of the network - welcome to GitHub .
PS If you have interesting problems in this area - I will be glad to help .
Source: https://habr.com/ru/post/264489/
All Articles