Large-scale study of flash drive failures (article review)
The most interesting study “A Large-Scale Study of Flash Memory in the Field” was recently published by Qiang Wu and Sanjev Kumar from Facebook, as well as Justin Meza and Onur Mutlu from Carnegie Mellon University. Below are the main conclusions from the article with a few comments.
Now, when flash drives are very actively used as a high-performance replacement for hard drives, their reliability plays an increasingly important role. Chip failures can lead to downtime and even data loss. To develop an understanding of the processes of changing the reliability of flash memory in real conditions of a loaded project, a study was conducted, which is presented in the article under discussion.
The authors collected extensive statistics for four years of operating flash drives in Facebook data centers.
')
As many probably know, Facebook has long been the best (and main) customer of Fusuion-IO (now purchased by SANdisk), which was one of the first to launch PCI-e flash drives.

As a result of the analysis of the collected data, a number of interesting conclusions were made:
• SSD failure probability varies non-linearly with time. It can be expected that the probability of failure will grow linearly with the increase in the number of write cycles. On the contrary, there are separate peaks in which the probability of failure increases, but these peaks are determined by factors other than normal wear and tear.
• Reading errors are rare in practice and are not dominant.
• The distribution of data across the volume of SSD drive can significantly affect the probability of failure.
• An increase in temperature leads to an increase in the probability of failure, but thanks to the support of throttling, the negative temperature effect is significantly reduced.
• The amount of data that was recorded on the SSD by the operating system does not always accurately reflect the degree of wear of the drive, since the controller has internal optimization algorithms and also uses buffering in the system software.
Objects of study.
The authors managed to obtain statistical data from a variety of 3 types of drives (of different generations) in 6 different hardware configurations: 1 or 2 720GB PCI-e v1 x4 drives, 1 or 2 1.2TB PCI-e v2 x4 drives and 1 or 2 3.2TB PCI drives -e v2 x4. Since all measurements were taken from “live” systems, the operation time of the drives (as well as the recorded / read amount of data) differs significantly from each other. However, the data collected was sufficient to obtain statistically significant data after averaging the results within individual groups. The main measurable indicator of the reliability with which the authors of the article operate is the uncorrectable bit error rate, UBER = unrecorectable errors / bits accessed. These are the errors that occur when reading / writing, but can not be corrected by the ssd controller. It seems very interesting that for some systems, UBER indicators are comparable to the order of magnitude with data obtained by other researchers when measuring bit errors (BER) at the level of individual chips in synthetic tests (LM Grupp, JD Davis, and S. Swanson. The Bleak Future of NAND Flash Memory. In FAST, 2012.). However, this similarity was obtained only for first-generation drives and only in a configuration with two boards in the system. In all other cases, the difference is several orders of magnitude, which looks quite logical. Most likely, the reason was a number of both internal and external (temperature, power) factors, so no significant conclusions from this observation can be made.
The distribution of errors.
Interestingly, the number of errors observed strongly depends on the specific drive - the authors note that only 10% of the total number of SSD drives show 95% of all uncorrectable errors. In addition, the probability of errors significantly depends on the “history” of the drive: if at least one error was observed during the week, then with a probability of 99.8% next week you can also expect an error to occur on this drive. The authors also note a correlation between the probability of an error and the number of SSD cards in the system — for configurations with two drives, the probability of failure increased. Here, however, it is necessary to take into account other external factors - first of all, the nature of the load and the way the load is redistributed in the event of a drive failure. Therefore, it is impossible to talk about the direct influence of drives on each other, but when planning complex systems, it is important how the load is distributed not only in the normal state, but also in the event of individual component failures. It is necessary to plan the complex in such a way that the failure of one component does not lead to an avalanche-like increase in the probability of failure in other components of the system.
The dependence of the number of errors on the lifetime (number of write cycles).
It is well known that the lifetime of an SSD depends on the number of write cycles, which, in turn, is quite strictly limited within the framework of the technology used. It is logical to expect that the number of observed errors will increase in proportion to the amount of data recorded on the SSD. The experimental data obtained show that in reality the picture turns out to be somewhat more complex. It is known that a typical U-shaped curve describing the probability of failure is typical for conventional hard drives.
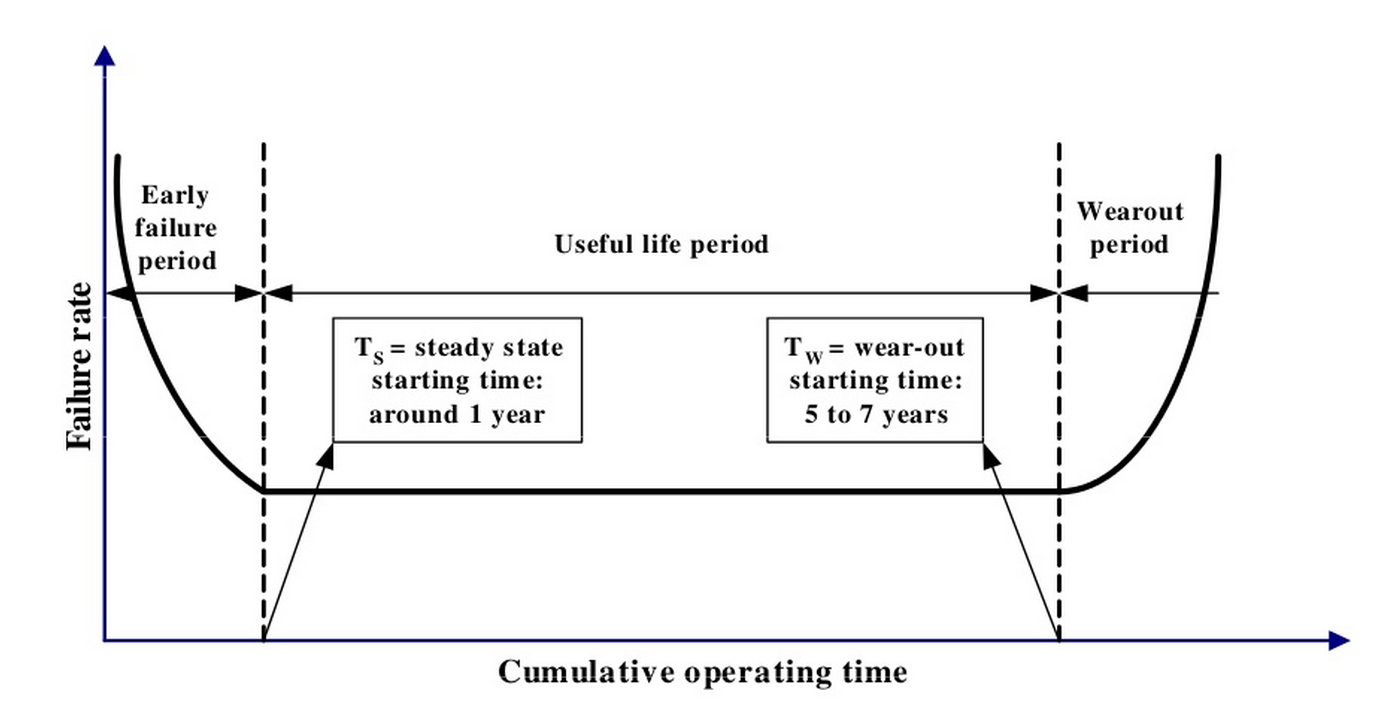
(Jimmy Yang, Feng-Bin Sun A comprehensive review of hard-disk drive reliability. Reliability and Maintainability Symposium, 1999. Proceedings. Annual)
At the initial stage of operation, there is a relatively high probability of failures, which then decreases and begins to increase again after long-term operation. For SSD, we also see an increased number of failures at the initial stage, but not immediately, but first there is a gradual increase in the number of errors.
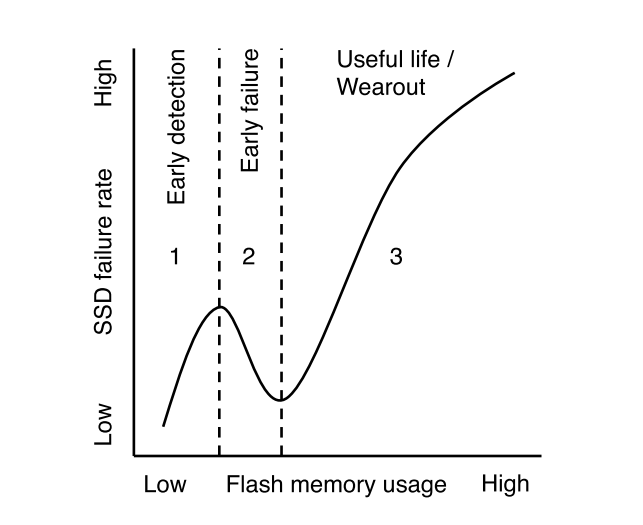
The authors hypothesize that the cause of nonlinear behavior is the presence of a “weak link” - cells that are subject to wear much faster. These cells at an early stage of operation generate uncorrectable errors, and the controller, in turn, eliminates them from work. The remaining “reliable” cells function normally during their life cycle and begin to serve as a cause of errors only after a long period of operation (as expected based on the maximum number of write cycles). This is a logical assumption - primary failures are observed for hard drives, and for SSD. The difference in the behavior of HDD and SSD is due to the fact that a physical error on the hard disk drive usually results in a drive falling out of the RAID array, and for the SSD controller it can usually correct the error and move the data to the backup capacity. To reduce the likelihood of failures at the initial stage of operation can be a preliminary control ("run-in"), which is sometimes practiced by vendors on special stands.
The dependence of the number of errors on the amount of read data.
Separately, it was investigated the assumption that the amount of read data can also affect the UBER value, however, it turned out that for SSDs for which the amount of read data is significantly different (with a similar amount of recorded data), the ratio of uncorrectable errors differs slightly. Thus, the authors argue that read operations do not have any significant effect on the reliability of drives.
The impact of data fragmentation within the SSD on failures.
Another aspect that is worth paying attention to is the relationship between the error rate and the load on the buffer. Of course, the buffer load itself (which is a normal DRAM chip) is not connected in any way. However, the more “smeared” the recorded blocks are by the volume of SSD (fragmentation), the more actively the buffer that is used to store metadata is used. As a result of research of the obtained data, a number of configurations showed a clear dependence of the error rate on the distribution of the recorded data over the SSD volume. This allows you to allow significant potential in the development of technologies that allow to optimize write operations due to the optimal distribution of data across the drive, which, in turn, will ensure higher reliability of drives.
Temperature effects.
From external factors that have a potential impact on the reliability of drives, first of all, we can distinguish temperature effects. Like any semiconductor, flash chips are subject to degradation at high temperatures, so you can expect that an increase in temperature inside the system can lead to an increase in the error rate. In reality, this behavior is observed only for a number of configurations. The effect of temperature is most pronounced for the first generation of drives, as well as for systems with two drives of the second generation. In other cases, the temperature effect was relatively small, and sometimes was even negative. This behavior is easily explained by throttling support (skipping cycles) in the SSD.
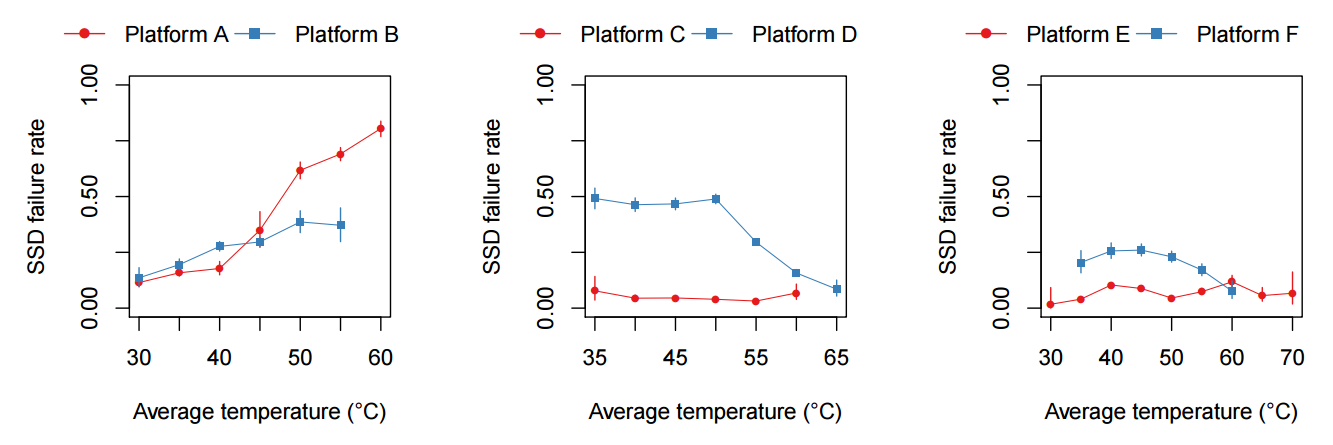
Probably, for earlier models, the technology was either not supported or was not implemented at the proper level. New drives calmly tolerate a rise in temperature, although the price for this is a decrease in performance. Therefore, if suddenly the performance of the SSD drive in the system has decreased, it is worth checking the temperature conditions. The temperature effect is very interesting especially in the light of the fact that engineering units in recent years have tried to maximize the temperature in the data center in order to reduce cooling costs. In the documents published by ASHRAE (American Society of Heating, Refrigerating and Air-Conditioning Engineers) you can find recommendations for systems with SSD drives. For example, a document that may well be useful - Data Center Storage Equipment - Thermal Guidelines, Issues, and Best Practices. When planning serious computing complexes, it is certainly worth considering the recommendations of ASHRAE and carefully study the characteristics of the drives planned for use so as not to fall into such a temperature mode when performance degradation has already begun to maintain the reliability of the drive.
Reliability of statistical data in the system software.
Another interesting observation by the authors is in some cases, although the operating system metrics showed a high amount of recorded data, the error rate was lower than for systems where the amount of recorded data was lower.
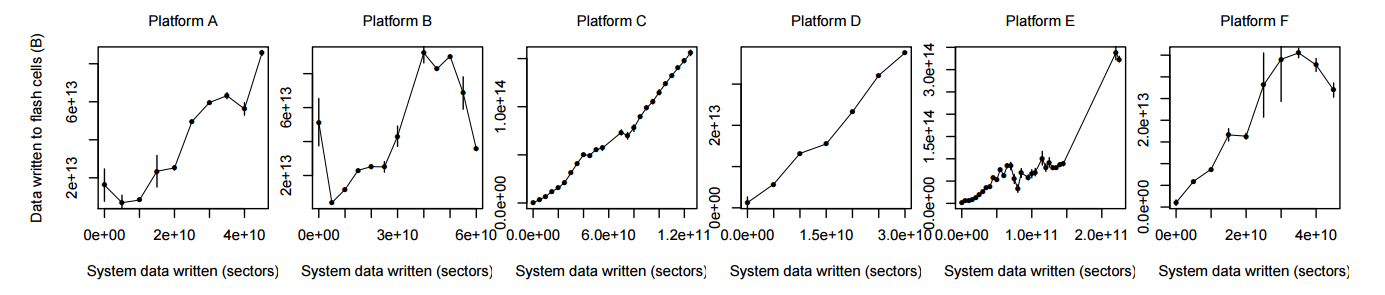
As it turned out, often the metrics of the operating system and the SSD controller itself were significantly different. This is due to optimizations inside the SSD controller, as well as to I / O buffering both in the operating system itself and in the storage device. As a result, you should not rely 100% on operating system metrics - they may not be entirely accurate, and further optimizations of the I / O subsystem can make this gap even more noticeable.
Practical conclusions.
So, what practical conclusions can be drawn from this study?
1. When designing serious solutions based on SSD, you must be very careful about the temperature conditions in the data center, otherwise you can get either performance degradation or a high probability of failure.
2. Before entering into the production, it is necessary to “warm up” the system in order to identify “weak links”. This board, however, is equally well suited to any components, be it an SSD or hard drives, or memory modules. Load testing allows you to identify many "problem" components that, otherwise, could "spoil the blood" in the combat infrastructure.
3. If the drive began to produce errors, you should take care of the availability of spare parts.
4. It is better to collect statistics from all available sources, but for a number of indicators it is better to focus on low-level data inside the drives.
5. New SSD generations are usually better than old ones :)
In all these tips, there is nothing unexpected, but often simple things elude attention.
Here I touched upon what seemed to me the most interesting moments, if you are interested in a detailed study of the issue, you should carefully study all the calculations of the authors by reading the original version . A truly titanic work was done on the collection and analysis of data. If the team continues its research, then in a couple of years we can expect even more extensive and comprehensive research.
PS The term “reliability” in the text is used exclusively as an analogue to the term “number of errors”.
Other Trinity articles can be found in the Trinity hub . Subscribe!
Now, when flash drives are very actively used as a high-performance replacement for hard drives, their reliability plays an increasingly important role. Chip failures can lead to downtime and even data loss. To develop an understanding of the processes of changing the reliability of flash memory in real conditions of a loaded project, a study was conducted, which is presented in the article under discussion.
The authors collected extensive statistics for four years of operating flash drives in Facebook data centers.
')
As many probably know, Facebook has long been the best (and main) customer of Fusuion-IO (now purchased by SANdisk), which was one of the first to launch PCI-e flash drives.
As a result of the analysis of the collected data, a number of interesting conclusions were made:
• SSD failure probability varies non-linearly with time. It can be expected that the probability of failure will grow linearly with the increase in the number of write cycles. On the contrary, there are separate peaks in which the probability of failure increases, but these peaks are determined by factors other than normal wear and tear.
• Reading errors are rare in practice and are not dominant.
• The distribution of data across the volume of SSD drive can significantly affect the probability of failure.
• An increase in temperature leads to an increase in the probability of failure, but thanks to the support of throttling, the negative temperature effect is significantly reduced.
• The amount of data that was recorded on the SSD by the operating system does not always accurately reflect the degree of wear of the drive, since the controller has internal optimization algorithms and also uses buffering in the system software.
Objects of study.
The authors managed to obtain statistical data from a variety of 3 types of drives (of different generations) in 6 different hardware configurations: 1 or 2 720GB PCI-e v1 x4 drives, 1 or 2 1.2TB PCI-e v2 x4 drives and 1 or 2 3.2TB PCI drives -e v2 x4. Since all measurements were taken from “live” systems, the operation time of the drives (as well as the recorded / read amount of data) differs significantly from each other. However, the data collected was sufficient to obtain statistically significant data after averaging the results within individual groups. The main measurable indicator of the reliability with which the authors of the article operate is the uncorrectable bit error rate, UBER = unrecorectable errors / bits accessed. These are the errors that occur when reading / writing, but can not be corrected by the ssd controller. It seems very interesting that for some systems, UBER indicators are comparable to the order of magnitude with data obtained by other researchers when measuring bit errors (BER) at the level of individual chips in synthetic tests (LM Grupp, JD Davis, and S. Swanson. The Bleak Future of NAND Flash Memory. In FAST, 2012.). However, this similarity was obtained only for first-generation drives and only in a configuration with two boards in the system. In all other cases, the difference is several orders of magnitude, which looks quite logical. Most likely, the reason was a number of both internal and external (temperature, power) factors, so no significant conclusions from this observation can be made.
The distribution of errors.
Interestingly, the number of errors observed strongly depends on the specific drive - the authors note that only 10% of the total number of SSD drives show 95% of all uncorrectable errors. In addition, the probability of errors significantly depends on the “history” of the drive: if at least one error was observed during the week, then with a probability of 99.8% next week you can also expect an error to occur on this drive. The authors also note a correlation between the probability of an error and the number of SSD cards in the system — for configurations with two drives, the probability of failure increased. Here, however, it is necessary to take into account other external factors - first of all, the nature of the load and the way the load is redistributed in the event of a drive failure. Therefore, it is impossible to talk about the direct influence of drives on each other, but when planning complex systems, it is important how the load is distributed not only in the normal state, but also in the event of individual component failures. It is necessary to plan the complex in such a way that the failure of one component does not lead to an avalanche-like increase in the probability of failure in other components of the system.
The dependence of the number of errors on the lifetime (number of write cycles).
It is well known that the lifetime of an SSD depends on the number of write cycles, which, in turn, is quite strictly limited within the framework of the technology used. It is logical to expect that the number of observed errors will increase in proportion to the amount of data recorded on the SSD. The experimental data obtained show that in reality the picture turns out to be somewhat more complex. It is known that a typical U-shaped curve describing the probability of failure is typical for conventional hard drives.
(Jimmy Yang, Feng-Bin Sun A comprehensive review of hard-disk drive reliability. Reliability and Maintainability Symposium, 1999. Proceedings. Annual)
At the initial stage of operation, there is a relatively high probability of failures, which then decreases and begins to increase again after long-term operation. For SSD, we also see an increased number of failures at the initial stage, but not immediately, but first there is a gradual increase in the number of errors.
The authors hypothesize that the cause of nonlinear behavior is the presence of a “weak link” - cells that are subject to wear much faster. These cells at an early stage of operation generate uncorrectable errors, and the controller, in turn, eliminates them from work. The remaining “reliable” cells function normally during their life cycle and begin to serve as a cause of errors only after a long period of operation (as expected based on the maximum number of write cycles). This is a logical assumption - primary failures are observed for hard drives, and for SSD. The difference in the behavior of HDD and SSD is due to the fact that a physical error on the hard disk drive usually results in a drive falling out of the RAID array, and for the SSD controller it can usually correct the error and move the data to the backup capacity. To reduce the likelihood of failures at the initial stage of operation can be a preliminary control ("run-in"), which is sometimes practiced by vendors on special stands.
The dependence of the number of errors on the amount of read data.
Separately, it was investigated the assumption that the amount of read data can also affect the UBER value, however, it turned out that for SSDs for which the amount of read data is significantly different (with a similar amount of recorded data), the ratio of uncorrectable errors differs slightly. Thus, the authors argue that read operations do not have any significant effect on the reliability of drives.
The impact of data fragmentation within the SSD on failures.
Another aspect that is worth paying attention to is the relationship between the error rate and the load on the buffer. Of course, the buffer load itself (which is a normal DRAM chip) is not connected in any way. However, the more “smeared” the recorded blocks are by the volume of SSD (fragmentation), the more actively the buffer that is used to store metadata is used. As a result of research of the obtained data, a number of configurations showed a clear dependence of the error rate on the distribution of the recorded data over the SSD volume. This allows you to allow significant potential in the development of technologies that allow to optimize write operations due to the optimal distribution of data across the drive, which, in turn, will ensure higher reliability of drives.
Temperature effects.
From external factors that have a potential impact on the reliability of drives, first of all, we can distinguish temperature effects. Like any semiconductor, flash chips are subject to degradation at high temperatures, so you can expect that an increase in temperature inside the system can lead to an increase in the error rate. In reality, this behavior is observed only for a number of configurations. The effect of temperature is most pronounced for the first generation of drives, as well as for systems with two drives of the second generation. In other cases, the temperature effect was relatively small, and sometimes was even negative. This behavior is easily explained by throttling support (skipping cycles) in the SSD.
Probably, for earlier models, the technology was either not supported or was not implemented at the proper level. New drives calmly tolerate a rise in temperature, although the price for this is a decrease in performance. Therefore, if suddenly the performance of the SSD drive in the system has decreased, it is worth checking the temperature conditions. The temperature effect is very interesting especially in the light of the fact that engineering units in recent years have tried to maximize the temperature in the data center in order to reduce cooling costs. In the documents published by ASHRAE (American Society of Heating, Refrigerating and Air-Conditioning Engineers) you can find recommendations for systems with SSD drives. For example, a document that may well be useful - Data Center Storage Equipment - Thermal Guidelines, Issues, and Best Practices. When planning serious computing complexes, it is certainly worth considering the recommendations of ASHRAE and carefully study the characteristics of the drives planned for use so as not to fall into such a temperature mode when performance degradation has already begun to maintain the reliability of the drive.
Reliability of statistical data in the system software.
Another interesting observation by the authors is in some cases, although the operating system metrics showed a high amount of recorded data, the error rate was lower than for systems where the amount of recorded data was lower.
As it turned out, often the metrics of the operating system and the SSD controller itself were significantly different. This is due to optimizations inside the SSD controller, as well as to I / O buffering both in the operating system itself and in the storage device. As a result, you should not rely 100% on operating system metrics - they may not be entirely accurate, and further optimizations of the I / O subsystem can make this gap even more noticeable.
Practical conclusions.
So, what practical conclusions can be drawn from this study?
1. When designing serious solutions based on SSD, you must be very careful about the temperature conditions in the data center, otherwise you can get either performance degradation or a high probability of failure.
2. Before entering into the production, it is necessary to “warm up” the system in order to identify “weak links”. This board, however, is equally well suited to any components, be it an SSD or hard drives, or memory modules. Load testing allows you to identify many "problem" components that, otherwise, could "spoil the blood" in the combat infrastructure.
3. If the drive began to produce errors, you should take care of the availability of spare parts.
4. It is better to collect statistics from all available sources, but for a number of indicators it is better to focus on low-level data inside the drives.
5. New SSD generations are usually better than old ones :)
In all these tips, there is nothing unexpected, but often simple things elude attention.
Here I touched upon what seemed to me the most interesting moments, if you are interested in a detailed study of the issue, you should carefully study all the calculations of the authors by reading the original version . A truly titanic work was done on the collection and analysis of data. If the team continues its research, then in a couple of years we can expect even more extensive and comprehensive research.
PS The term “reliability” in the text is used exclusively as an analogue to the term “number of errors”.
Other Trinity articles can be found in the Trinity hub . Subscribe!
Source: https://habr.com/ru/post/264463/
All Articles