Buying the best apartment with R
Many people are faced with the issue of buying or selling real estate, and an important criterion here is how not to buy more expensive or not to sell cheaper relative to other, comparable options. The simplest method is comparative, focusing on the average price of a meter in a particular place and expertly adding or reducing the percentage of the cost for the advantages and disadvantages of a particular apartment.  But this approach is laborious, inaccurate and will not allow to take into account the diversity of the differences of apartments from each other. Therefore, I decided to automate the process of choosing a property using data analysis by predicting the “fair” price. This publication describes the main stages of this analysis, selected the best predictive model from eighteen tested models based on three quality criteria, and the best (undervalued) apartments are immediately marked on the map, all using one web application created with R.
But this approach is laborious, inaccurate and will not allow to take into account the diversity of the differences of apartments from each other. Therefore, I decided to automate the process of choosing a property using data analysis by predicting the “fair” price. This publication describes the main stages of this analysis, selected the best predictive model from eighteen tested models based on three quality criteria, and the best (undervalued) apartments are immediately marked on the map, all using one web application created with R.
With the formulation of the problem it is clear, the question arises, where do you get the data, there are several main real estate search sites in the Russian Federation, and there is a WinNER database, which in a fairly user-friendly interface contains the maximum number of ads and allows you to upload in csv format. But if earlier this base allowed time-based access (minutes, hours, days), then now the minimum is only 3 months access, which is somewhat redundant for an ordinary buyer or seller (although if seriously approached, then these costs can be incurred). With this option it would be quite simple, so let's go the other way, by parsing from some real estate site. Of the several options, I chose the most convenient well-known cian.ru. At that time, the display of the data was presented in a simple tabular form, but when I tried to parse all the data on R, then I had a failure. In some cells, the data could be underfilled, but with the standard means of the R functions I could not catch hold of anchor words or symbols, and I had to either use cycles (which is wrong for this task in R) or use regular expressions with which I am not at all familiar so I had to use an alternative. This alternative was a great service import.io , which allows you to extract information from pages (or sites), has its own REST API and gives the result to JSON. And R can and request to API to carry out and JSON to sort.
Quickly accustomed to this service, I created an extractor on it, which extracts all the required information (all parameters of each apartment) from one page. And R already goes through all the pages, calling this API for each and gluing the received JSON data into a single table. Although import.io allows you to make a completely autonomous API, which would pass through all pages, I thought it was logical that I could not do (parsing one page) correctly put on a third-party API, and continue to do everything else in R. So, The data source is selected, now about the limitations of the future model:
')
As is often the case, data may contain outliers, omissions, or simply deception, when new buildings are issued as a secondary housing, or they sell land in general.
Therefore, initially it is necessary to bring all the data to a "neat" form.
Here, the main focus on the description of the announcement, if there are words clearly not related to the sample I need, these observations are excluded, this is verified by the function R grep . And since in R the computations are vector, this function immediately returns the vector of valid observation values, applying it, we filter the sample.
The missing values are quite rare (and mainly in the "left" ads, with new buildings and land, which by this time have already been excluded), but with those that remain, it is necessary to do something. There are two options, in general, to exclude such observations or to replace these missing values. Since I did not want to sacrifice observations, but on the assumption that the data is not filled on the basis of the principle “that it is filled in, and so it is clear that this is like everything around,” I decided to replace the qualitative variables with the mode of their values, and median values. Of course, this is not entirely correct, and it would be entirely correct to conduct a correlation relationship between observations, and fill in the gaps according to the results, but for this task I considered this to be redundant, moreover, there were few such observations.
Emissions are even less common, and can only be quantitative, namely by price and by area. Here, it was based on the assumption that the buyer (I) specifically knows at what price and about what footage his apartment should be, therefore, by setting the initial values of the upper and lower prices, by limiting the footage, we automatically get rid of emissions. But even if this is not the case (not to make restrictions), then upon receiving the result or by looking at the scatterplot and seeing that there is an outlier, you can make a request with updated data, thereby removing these observations, which will improve the model.
In addition to the variables (obtained directly from the site), I decided to add additional regressors, namely, a five-story house or not (since this is usually a very qualitative difference), and the distance to the nearest metro station (similarly). The Google geocoding service API is used to determine the distance (I chose it as the most accurate, loyal to restrictions, and there is a ready function in R), first the addresses of apartments and subways are geocoded, the geocode function from the ggmap package. And the distance is determined by the formula of haversinus, the finished function distHaversine from the package geosphere .
The total number of regressors was 14 pieces:
The winner is determined (random forest), this model predicts “theoretical” prices for all observations with minimal errors. Now you can calculate the absolute, relative underestimation and output the result in the form of a sorted table, but in addition to the table view, you immediately want information, so we will display some of the best results on the map immediately. And for this purpose in R there is a googleVis package intended for integration with Google mapping system (however, there is a package for Leaflet too). I continued to use Google as well, since the obtained coordinates from their geocoding are forbidden to be displayed on other maps. The display on the map is carried out by a single function gvisMap from the googleVis package.
Transferring all the required parameters via the console is slow and inconvenient, so I wanted to do everything automatically. And traditionally, for this, you can again use R with the shiny , and shinydashboard frameworks , which have sufficient I / O controls.
The result of all this becomes a convenient GUI application, with actually two (the remaining items for control) the main items on the side menu - the first and the last. In the first ( Source data ) item of the side menu (Fig. 1), all required parameters are set (similar to cian) for searching and evaluating apartments.
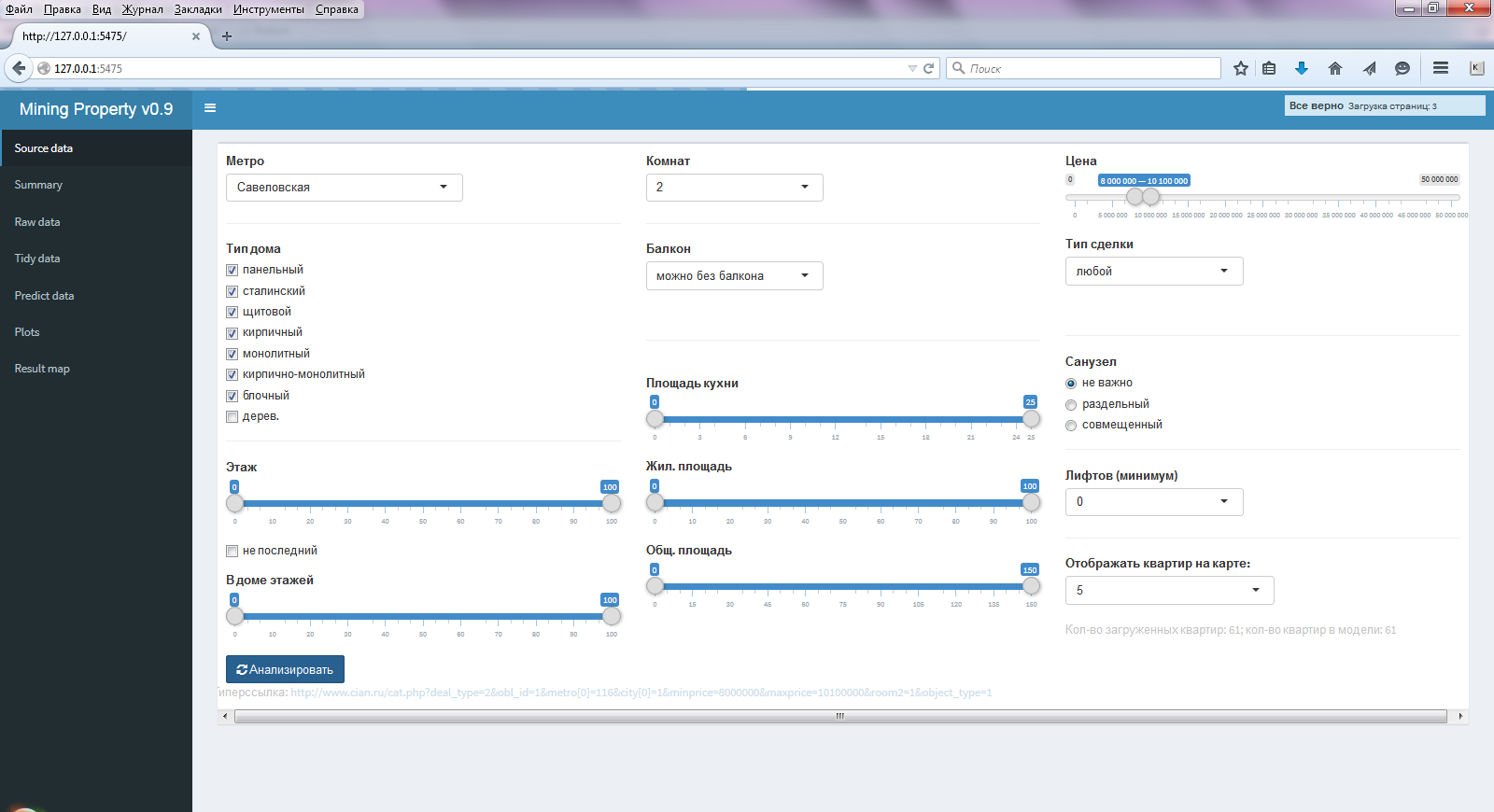
Fig.1 Window of the selected menu Source data
The remaining items on the side menu display:
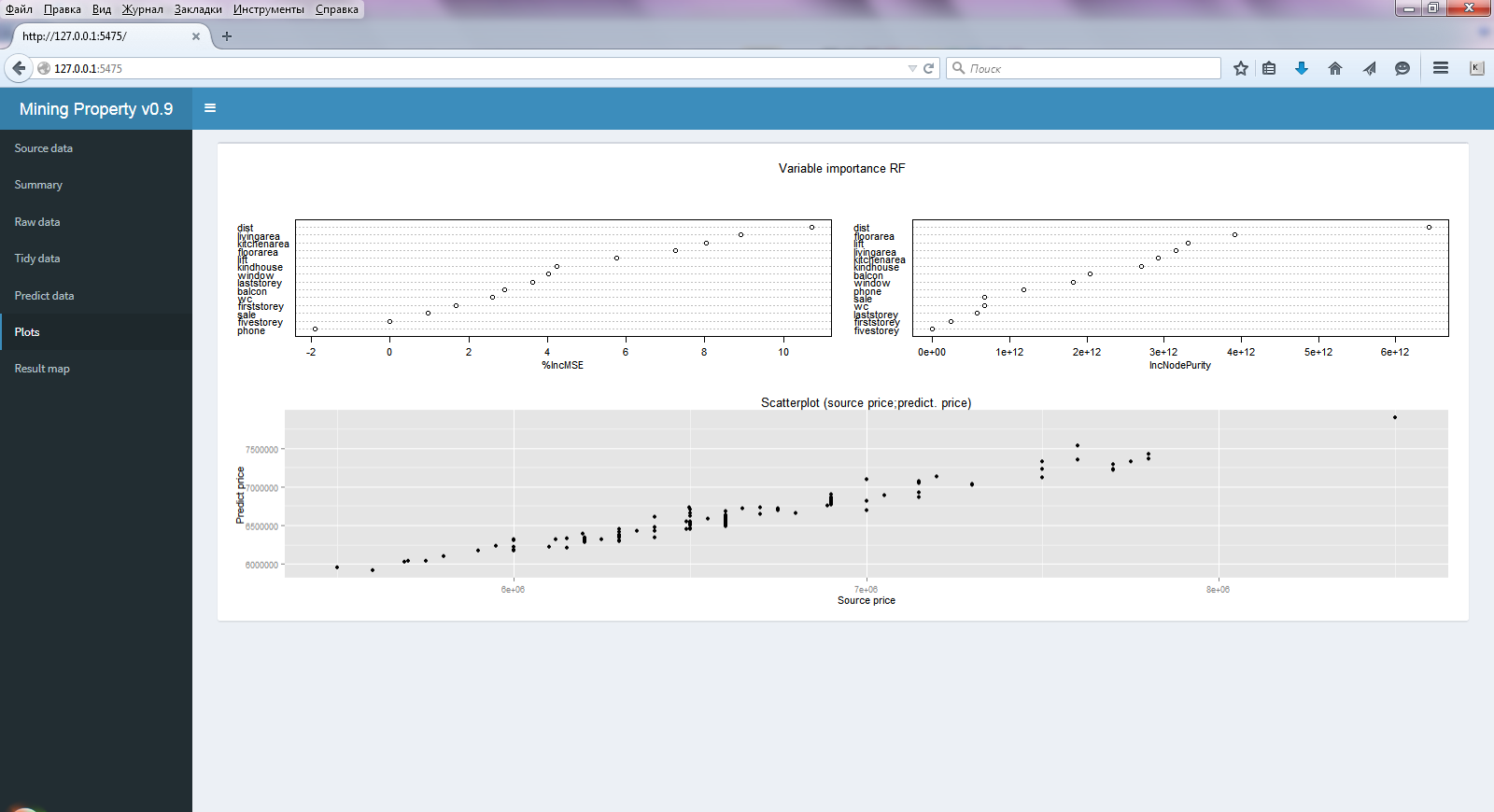
Fig.2 Window of the selected menu Plots
Well, in the last paragraph ( Result map ) (Fig. 3), this is the reason for which everything was started, a map with the best results selected and a table with the calculated predicted price and the main characteristics of the apartments.
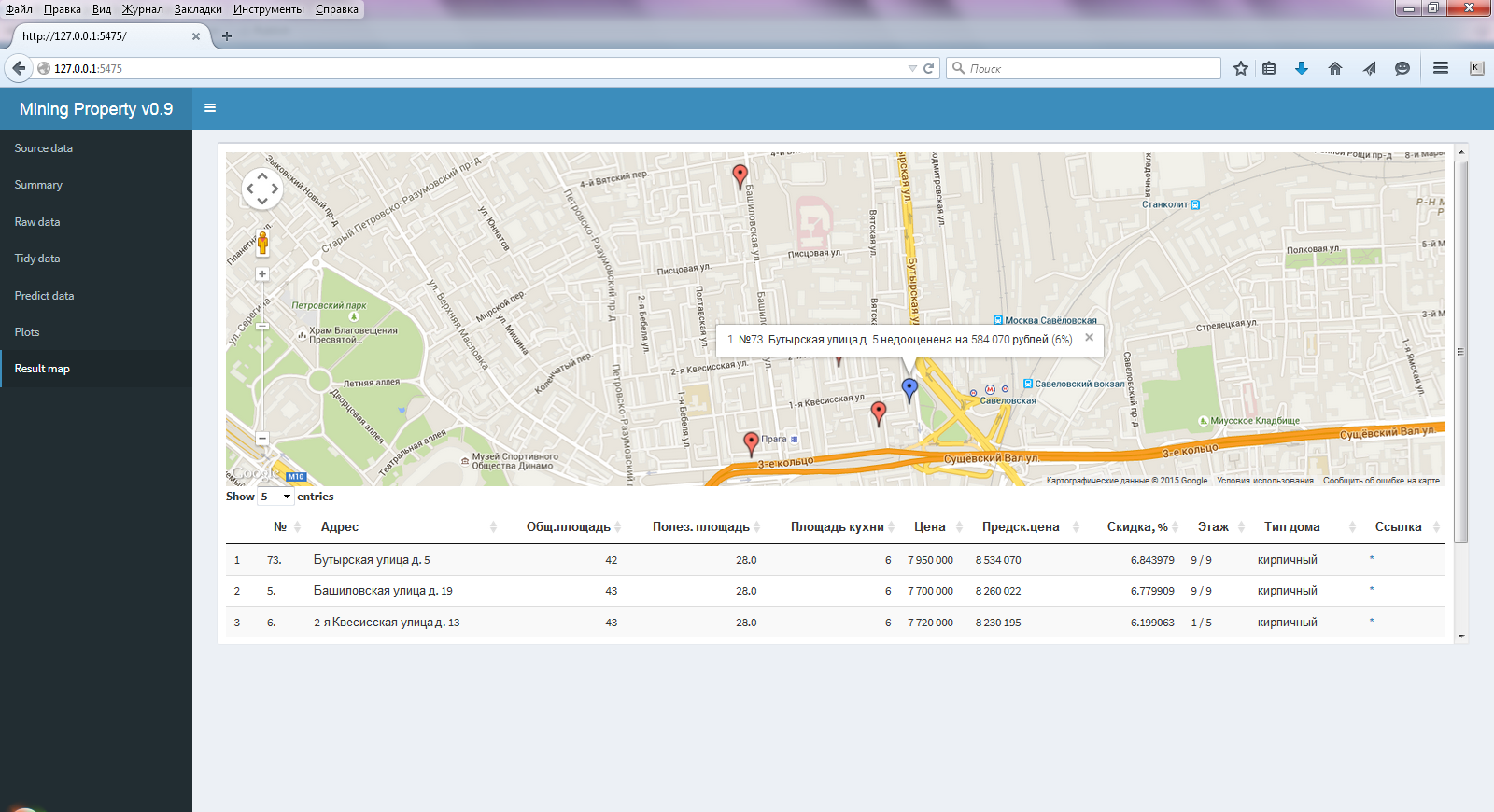
Fig.3 Window of the selected menu Result map
Also in this table immediately there is a link (*) to go to this ad. This integration (the inclusion of JS elements in the table) allows you to make a package DT .
Summarizing all the above, how does it all work:
The entire operation of the application (from the beginning of the request to display on the map) is performed in less than a minute (most of the time is spent on geolocation, the restriction of Google for residential use).
This publication wanted to show how for simple domestic needs, in the framework of one application, we managed to solve many small, but fundamentally different interesting subtasks:
Everything else is implemented in a convenient graphical application, which can be both local and hosted on the network, and all this is done on one R (not counting import.io ), with a minimum of lines of code with a simple and elegant syntax. Of course, something is not taken into account, for example, the house near the highway or the condition of the apartment (since there is no such thing in the ads), but the final, ranked list of options immediately displayed on the map and referring to the original ad itself, greatly facilitate the choice of apartments, Well, plus to everything I learned a lot of new things in R.
But this approach is laborious, inaccurate and will not allow to take into account the diversity of the differences of apartments from each other. Therefore, I decided to automate the process of choosing a property using data analysis by predicting the “fair” price. This publication describes the main stages of this analysis, selected the best predictive model from eighteen tested models based on three quality criteria, and the best (undervalued) apartments are immediately marked on the map, all using one web application created with R.Data collection
With the formulation of the problem it is clear, the question arises, where do you get the data, there are several main real estate search sites in the Russian Federation, and there is a WinNER database, which in a fairly user-friendly interface contains the maximum number of ads and allows you to upload in csv format. But if earlier this base allowed time-based access (minutes, hours, days), then now the minimum is only 3 months access, which is somewhat redundant for an ordinary buyer or seller (although if seriously approached, then these costs can be incurred). With this option it would be quite simple, so let's go the other way, by parsing from some real estate site. Of the several options, I chose the most convenient well-known cian.ru. At that time, the display of the data was presented in a simple tabular form, but when I tried to parse all the data on R, then I had a failure. In some cells, the data could be underfilled, but with the standard means of the R functions I could not catch hold of anchor words or symbols, and I had to either use cycles (which is wrong for this task in R) or use regular expressions with which I am not at all familiar so I had to use an alternative. This alternative was a great service import.io , which allows you to extract information from pages (or sites), has its own REST API and gives the result to JSON. And R can and request to API to carry out and JSON to sort.
Quickly accustomed to this service, I created an extractor on it, which extracts all the required information (all parameters of each apartment) from one page. And R already goes through all the pages, calling this API for each and gluing the received JSON data into a single table. Although import.io allows you to make a completely autonomous API, which would pass through all pages, I thought it was logical that I could not do (parsing one page) correctly put on a third-party API, and continue to do everything else in R. So, The data source is selected, now about the limitations of the future model:
- Moscow city
- One type of apartment per model (that is, one-room or two-room or three-room)
- Within one metro station (as geocoding is used, and the distance to the nearest metro)
- Secondary (since the new buildings are all fundamentally different, and qualitatively differ from each other, and in the ads it either does not say, or something is written in the comments, but neither one nor the other, does not allow creating an adequate model)
')
Data overview
As is often the case, data may contain outliers, omissions, or simply deception, when new buildings are issued as a secondary housing, or they sell land in general.
Therefore, initially it is necessary to bring all the data to a "neat" form.
Cheating
Here, the main focus on the description of the announcement, if there are words clearly not related to the sample I need, these observations are excluded, this is verified by the function R grep . And since in R the computations are vector, this function immediately returns the vector of valid observation values, applying it, we filter the sample.
Check for missing values
The missing values are quite rare (and mainly in the "left" ads, with new buildings and land, which by this time have already been excluded), but with those that remain, it is necessary to do something. There are two options, in general, to exclude such observations or to replace these missing values. Since I did not want to sacrifice observations, but on the assumption that the data is not filled on the basis of the principle “that it is filled in, and so it is clear that this is like everything around,” I decided to replace the qualitative variables with the mode of their values, and median values. Of course, this is not entirely correct, and it would be entirely correct to conduct a correlation relationship between observations, and fill in the gaps according to the results, but for this task I considered this to be redundant, moreover, there were few such observations.
Emission check
Emissions are even less common, and can only be quantitative, namely by price and by area. Here, it was based on the assumption that the buyer (I) specifically knows at what price and about what footage his apartment should be, therefore, by setting the initial values of the upper and lower prices, by limiting the footage, we automatically get rid of emissions. But even if this is not the case (not to make restrictions), then upon receiving the result or by looking at the scatterplot and seeing that there is an outlier, you can make a request with updated data, thereby removing these observations, which will improve the model.
Basic assumptions of the Gauss-Markov theorem
more
So, we have eliminated incorrect observations, further, before carrying out the analysis, we will evaluate them on the basic premises of the Gauss-Markov theorem.
Looking ahead, I will say that from the model we do not want to get an interpretation of the coefficients, or a correct assessment of their confidence intervals, we need it to predict the “theoretical” price, so some prerequisites are not critical for us.
The data is generally consistent with the assumptions, so you can build models.
Looking ahead, I will say that from the model we do not want to get an interpretation of the coefficients, or a correct assessment of their confidence intervals, we need it to predict the “theoretical” price, so some prerequisites are not critical for us.
- The data model is correctly specified. In general, yes, by eliminating outliers, incorrect declarations, replacing missing values, the model is quite adequate. Some lax multicollinearity may be present (for example, a five-story building and there is no elevator or area - common / residential), but as I wrote above, this is not critical for prediction, moreover, it does not violate the basic premises. For the purpose of building test models, all values were translated into dummy variables correctly, strict multicollinearity is excluded.
- All regressors are deterministic and not equal. Yes, that's right too.
- Errors are not systematic. True, since the OLS uses the free term, which equalizes the errors.
- The error variance is the same (homoscedasticity). Since restrictions on the size of regressors and the dependent variable are used (the scale is comparable), heteroscedasticity is minimal, and it is again not critical for prediction (standard errors are untenable, but they are not interesting for us)
- Errors are uncorrelated (endogeneity). There is no here, endogeneity is likely to exist (for example, apartments are “neighbors” from one site or porch), there is some external unaccounted factor, but again for prediction, recording with endogeneity is not critical, moreover, we do not know this unaccounted factor.
The data is generally consistent with the assumptions, so you can build models.
Set of regressors
In addition to the variables (obtained directly from the site), I decided to add additional regressors, namely, a five-story house or not (since this is usually a very qualitative difference), and the distance to the nearest metro station (similarly). The Google geocoding service API is used to determine the distance (I chose it as the most accurate, loyal to restrictions, and there is a ready function in R), first the addresses of apartments and subways are geocoded, the geocode function from the ggmap package. And the distance is determined by the formula of haversinus, the finished function distHaversine from the package geosphere .
The total number of regressors was 14 pieces:
- Distance to metro
- total area
- Living space
- Kitchen area
- House type
- Availability and types of elevators
- Availability and types of balconies
- Number and types of bathrooms
- Where the windows go
- Phone availability
- Type of sale
- Ground floor
- Top floor
- Five-story building
Tested Predictive Analysis Models
more
In addition to practical personal value, it was also interesting to test different models, then I decided to choose the best model, test different samples for all simple regression models that I know, namely, the following models were tested:
1. OLS for all regressors
2. MNC with logarithmization (different options: logarithm of price and / or area and / or distance to the metro)
3. OLS with inclusion and exclusion of regressors
a) successive step-by-step exclusions of regressors
b) direct search algorithm
4. Models with fines (to reduce the influence of heteroscedasticity)
a) Lasso-regression (with 2 ways to determine the parameter of fractionation - minimizing the Mallow Cp-criterion and cross-checking)
b) Ridge regression (with 3 ways to find the penalty parameter - using the HKB method, LW method and cross-checking)
5. The main component method
a) with all regressors
b) with step-by-step exclusion of regressors
6. Quantile (median) regression (to reduce the effect of heteroscedasticity)
7. Random Forest Algorithm
The total number of models tested was 18 pieces.
In the process of preparing the models, materials were partially used:
Mastitsky S.E., Shitikov V.K. (2014) Statistical analysis and data visualization with R.
- E-book access address: r-analytics.blogspot.com
1. OLS for all regressors
2. MNC with logarithmization (different options: logarithm of price and / or area and / or distance to the metro)
3. OLS with inclusion and exclusion of regressors
a) successive step-by-step exclusions of regressors
b) direct search algorithm
4. Models with fines (to reduce the influence of heteroscedasticity)
a) Lasso-regression (with 2 ways to determine the parameter of fractionation - minimizing the Mallow Cp-criterion and cross-checking)
b) Ridge regression (with 3 ways to find the penalty parameter - using the HKB method, LW method and cross-checking)
5. The main component method
a) with all regressors
b) with step-by-step exclusion of regressors
6. Quantile (median) regression (to reduce the effect of heteroscedasticity)
7. Random Forest Algorithm
The total number of models tested was 18 pieces.
In the process of preparing the models, materials were partially used:
Mastitsky S.E., Shitikov V.K. (2014) Statistical analysis and data visualization with R.
- E-book access address: r-analytics.blogspot.com
Model performance criteria
more
All models are fundamentally different in nature, and for many of them there is no likelihood function, therefore, internal quality criteria cannot be determined, and it is not entirely correct to rely on them to select an effective model, since they serve primarily to assess the adequacy of the model. Therefore, we will focus on assessing the quality of models on the average difference of empirical and predicted values. And in order to make it more interesting, and to determine the benefits (cost-effectiveness), the root-mean-square error will not always be indicative (as some observations may distort it), I used not only the usual RMSE — the root-mean-square error, but the MAE — and MPE - a percentage error.
Model test results
more
Since the models are evaluated by different functions and the syntax of the predicted values is also different, simply indicating that part of the regressors is factorial is not suitable for all models, so an additional data frame was created in which all qualitative variables were transformed into dummy variables and in this form built models. This allows you to uniformly evaluate all models, predict new prices, and identify errors.
On various random test samples (different metro stations, different type of apartments, other parameters), all of the above models were evaluated according to 3 performance criteria. And the absolute (92%) winner by all 3 criteria turned out to be the random forest algorithm. Also, on different samples, according to some criteria, median regression, OLS with log-price, full OLS, and sometimes Ridge with Lasso showed good results. The results are somewhat surprising, since I thought that models with fines might turn out better than full OLS, but this was not always the case. So a simple model (OLS) can is a better alternative than more complex ones. Due to the fact that on different samples, according to different criteria of a place starting from the second, different models occupied, and the random forest remained the winner, I decided to use it for further work.
Since one model is already used, there is no need to explicitly specify dummy variables, so we return to the original frame, indicating that the qualitative variables are factorial, this will simplify the subsequent interpretation in the diagram, and the algorithm will be simpler (although in fact ). For the test simulation, the randomForest function (from the package of the same name) was used with default values, trying to change the basic complexity parameters of the nodesize , maxnodes , nPerm trees , determined that a slightly better minimization of forecast errors for different samples was achieved by changing the nodesize parameter (minimum number of nodes) to 1. So, the model is selected.
On various random test samples (different metro stations, different type of apartments, other parameters), all of the above models were evaluated according to 3 performance criteria. And the absolute (92%) winner by all 3 criteria turned out to be the random forest algorithm. Also, on different samples, according to some criteria, median regression, OLS with log-price, full OLS, and sometimes Ridge with Lasso showed good results. The results are somewhat surprising, since I thought that models with fines might turn out better than full OLS, but this was not always the case. So a simple model (OLS) can is a better alternative than more complex ones. Due to the fact that on different samples, according to different criteria of a place starting from the second, different models occupied, and the random forest remained the winner, I decided to use it for further work.
Since one model is already used, there is no need to explicitly specify dummy variables, so we return to the original frame, indicating that the qualitative variables are factorial, this will simplify the subsequent interpretation in the diagram, and the algorithm will be simpler (although in fact ). For the test simulation, the randomForest function (from the package of the same name) was used with default values, trying to change the basic complexity parameters of the nodesize , maxnodes , nPerm trees , determined that a slightly better minimization of forecast errors for different samples was achieved by changing the nodesize parameter (minimum number of nodes) to 1. So, the model is selected.
Map Display
The winner is determined (random forest), this model predicts “theoretical” prices for all observations with minimal errors. Now you can calculate the absolute, relative underestimation and output the result in the form of a sorted table, but in addition to the table view, you immediately want information, so we will display some of the best results on the map immediately. And for this purpose in R there is a googleVis package intended for integration with Google mapping system (however, there is a package for Leaflet too). I continued to use Google as well, since the obtained coordinates from their geocoding are forbidden to be displayed on other maps. The display on the map is carried out by a single function gvisMap from the googleVis package.
map display code
output $ view <- renderGvis ({#view is the htmlOutput output element
if ((err ()! = "")) return (NULL)
formap3 <-formap ()
formap3 $ desc <-paste0 (row.names (formap3),
". No."
formap3 $ number,
"",
formap3 $ address,
"undervalued by",
format (-formap3 $ abs.discount, big.mark = ""),
"rubles (",
as.integer (formap3 $ otn.discount),
"%)")
gvisMap (formap3, "coord", "desc", options = list (
mapType = 'normal',
enableScrollWheel = TRUE,
showTip = TRUE))
})
if ((err ()! = "")) return (NULL)
formap3 <-formap ()
formap3 $ desc <-paste0 (row.names (formap3),
". No."
formap3 $ number,
"",
formap3 $ address,
"undervalued by",
format (-formap3 $ abs.discount, big.mark = ""),
"rubles (",
as.integer (formap3 $ otn.discount),
"%)")
gvisMap (formap3, "coord", "desc", options = list (
mapType = 'normal',
enableScrollWheel = TRUE,
showTip = TRUE))
})
Web GUI
Transferring all the required parameters via the console is slow and inconvenient, so I wanted to do everything automatically. And traditionally, for this, you can again use R with the shiny , and shinydashboard frameworks , which have sufficient I / O controls.
full client-side interface code
dashboardPage (
dashboardHeader (title = "Mining Property v0.9"),
dashboardSidebar (
sidebarMenu (
menuItem ("Source data", tabName = "Source"),
menuItem ("Summary", tabName = "Summary"),
menuItem ("Raw data", tabName = "Raw"),
menuItem ("Tidy data", tabName = "Tidy"),
menuItem ("Predict data", tabName = "Predict"),
menuItem ("Plots", tabName = "Plots"),
menuItem ("Result map", tabName = "Map")
)
),
dashboardBody (
tags $ head (tags $ style (HTML ('. box {overflow: auto;}')))
tabItems (
tabItem ("Source",
box (width = 12,
fluidRow (
column (width = 4,
selectInput ("Metro", "Metro", "", width = '60% '),
# br (),
hr ()
#checkboxInput ("Kind.home0", "all", TRUE),
checkboxGroupInput ("Kind.home", "Type of house", c (
"Panel" = 1,
"Stalin" = 7,
“Shield” = 8,
“Brick” = 2,
"Monolithic" = 3,
"Brick-monolithic" = 4,
“Block” = 5,
"Wooden" = 6), selected = c (1,2,3,4,5,6,7,8)),
hr ()
sliderInput ("Etag", "Floor", min = 0, max = 100, value = c (0, 100), step = 1),
checkboxInput ("EtagP", "not last"),
sliderInput ("Etagn", "In the house of floors", min = 0, max = 100, value = c (0, 100), step = 1)
,
submitButton (“Analyze”, icon (“refresh”))
),
column (width = 4,
selectInput ("Rooms", "Rooms", c
("",
"1" = "& room1 = 1",
"2" = "& room2 = 1",
"3" = "& room3 = 1"), width = '45% ')
# br (),
hr ()
# br (),
selectInput ("Balcon", "Balcony",
c ("can be without a balcony" = "0",
"Only with a balcony" = "& minbalkon = 1",
"Only without a balcony" = "& minbalkon = -1"),
width = '45% '),
br ()
hr ()
br ()
#br ()
sliderInput ("KitchenM", "Kitchen Area", min = 0, max = 25, value = c (0, 25), step = 1),
sliderInput ("GilM", "Living space", min = 0, max = 100, value = c (0, 100), step = 1),
sliderInput ("TotalM", "Total. area", min = 0, max = 150, value = c (0, 150), step = 1)
),
column (width = 4,
sliderInput ("Price", "Price", min = 0, max = 50000000, value = c (0, 50000000), step = 100000, sep = ""),
# hr (),
selectInput ("Deal", "type of transaction",
c ("any" = "0",
"Free." = "& Sost_type = 1",
"Alternative" = "& sost_type = 2"),
width = '45% '),
br ()
hr ()
#br ()
# br (),
# br (),
radioButtons ("wc", "Bathroom",
c ("no matter" = "",
“Split” = "& minsu_r = 1",
"Combined" = "& minsu_s = 1")),
hr ()
selectInput ("Lift", "Lifts (minimum)",
c ("0" = 0,
"1" = "& minlift = 1",
"2" = "& minlift = 2",
"3" = "& minlift = 3",
"4" = "& minlift = 4"
),
width = '45% '),
hr ()
selectInput ("obs", "Display apartments on the map:", c (1:10), selected = 5, width = 250),
textOutput ("flat")
)
),
fluidRow (htmlOutput ("hyperf1")),
fluidRow (textOutput ("testOutput"))
)
),
tabItem ("Raw", box (dataTableOutput ("Raw"), width = 12, height = 600)),
tabItem ("Summary", box (verbatimTextOutput ("Summary"), width = 12, height = 600)),
tabItem ("Tidy", box (dataTableOutput ("Tidy"), width = 12, height = 600)),
tabItem ("Predict", box (dataTableOutput ("Predict"), width = 12, height = 600)),
tabItem ("Plots", box (width = 12, plotOutput ("RFplot", height = 275), plotOutput ("r2", height = 275))),
tabItem ("Map", box (width = 12, htmlOutput ("view"), DT :: dataTableOutput ("formap2"), height = 600))
)
)
)
dashboardHeader (title = "Mining Property v0.9"),
dashboardSidebar (
sidebarMenu (
menuItem ("Source data", tabName = "Source"),
menuItem ("Summary", tabName = "Summary"),
menuItem ("Raw data", tabName = "Raw"),
menuItem ("Tidy data", tabName = "Tidy"),
menuItem ("Predict data", tabName = "Predict"),
menuItem ("Plots", tabName = "Plots"),
menuItem ("Result map", tabName = "Map")
)
),
dashboardBody (
tags $ head (tags $ style (HTML ('. box {overflow: auto;}')))
tabItems (
tabItem ("Source",
box (width = 12,
fluidRow (
column (width = 4,
selectInput ("Metro", "Metro", "", width = '60% '),
# br (),
hr ()
#checkboxInput ("Kind.home0", "all", TRUE),
checkboxGroupInput ("Kind.home", "Type of house", c (
"Panel" = 1,
"Stalin" = 7,
“Shield” = 8,
“Brick” = 2,
"Monolithic" = 3,
"Brick-monolithic" = 4,
“Block” = 5,
"Wooden" = 6), selected = c (1,2,3,4,5,6,7,8)),
hr ()
sliderInput ("Etag", "Floor", min = 0, max = 100, value = c (0, 100), step = 1),
checkboxInput ("EtagP", "not last"),
sliderInput ("Etagn", "In the house of floors", min = 0, max = 100, value = c (0, 100), step = 1)
,
submitButton (“Analyze”, icon (“refresh”))
),
column (width = 4,
selectInput ("Rooms", "Rooms", c
("",
"1" = "& room1 = 1",
"2" = "& room2 = 1",
"3" = "& room3 = 1"), width = '45% ')
# br (),
hr ()
# br (),
selectInput ("Balcon", "Balcony",
c ("can be without a balcony" = "0",
"Only with a balcony" = "& minbalkon = 1",
"Only without a balcony" = "& minbalkon = -1"),
width = '45% '),
br ()
hr ()
br ()
#br ()
sliderInput ("KitchenM", "Kitchen Area", min = 0, max = 25, value = c (0, 25), step = 1),
sliderInput ("GilM", "Living space", min = 0, max = 100, value = c (0, 100), step = 1),
sliderInput ("TotalM", "Total. area", min = 0, max = 150, value = c (0, 150), step = 1)
),
column (width = 4,
sliderInput ("Price", "Price", min = 0, max = 50000000, value = c (0, 50000000), step = 100000, sep = ""),
# hr (),
selectInput ("Deal", "type of transaction",
c ("any" = "0",
"Free." = "& Sost_type = 1",
"Alternative" = "& sost_type = 2"),
width = '45% '),
br ()
hr ()
#br ()
# br (),
# br (),
radioButtons ("wc", "Bathroom",
c ("no matter" = "",
“Split” = "& minsu_r = 1",
"Combined" = "& minsu_s = 1")),
hr ()
selectInput ("Lift", "Lifts (minimum)",
c ("0" = 0,
"1" = "& minlift = 1",
"2" = "& minlift = 2",
"3" = "& minlift = 3",
"4" = "& minlift = 4"
),
width = '45% '),
hr ()
selectInput ("obs", "Display apartments on the map:", c (1:10), selected = 5, width = 250),
textOutput ("flat")
)
),
fluidRow (htmlOutput ("hyperf1")),
fluidRow (textOutput ("testOutput"))
)
),
tabItem ("Raw", box (dataTableOutput ("Raw"), width = 12, height = 600)),
tabItem ("Summary", box (verbatimTextOutput ("Summary"), width = 12, height = 600)),
tabItem ("Tidy", box (dataTableOutput ("Tidy"), width = 12, height = 600)),
tabItem ("Predict", box (dataTableOutput ("Predict"), width = 12, height = 600)),
tabItem ("Plots", box (width = 12, plotOutput ("RFplot", height = 275), plotOutput ("r2", height = 275))),
tabItem ("Map", box (width = 12, htmlOutput ("view"), DT :: dataTableOutput ("formap2"), height = 600))
)
)
)
The result of all this becomes a convenient GUI application, with actually two (the remaining items for control) the main items on the side menu - the first and the last. In the first ( Source data ) item of the side menu (Fig. 1), all required parameters are set (similar to cian) for searching and evaluating apartments.
Fig.1 Window of the selected menu Source data
The remaining items on the side menu display:
- Summary Report on Regressors
- data tables ( Raw ( Raw data ) - original after parsing, neat ( Tidy data ) - after adjusting the parameters to a neat look and adjusting the parameters and adding geolocation, and the final ( Predict data ) table with the predicted prices)
- three diagrams ( Plots ) (Fig. 2) —the accuracy of the model and the importance of the regressors in the random forest algorithm (almost always all the regressors are important) and the scatter diagram of the original and predicted prices.
Fig.2 Window of the selected menu Plots
Well, in the last paragraph ( Result map ) (Fig. 3), this is the reason for which everything was started, a map with the best results selected and a table with the calculated predicted price and the main characteristics of the apartments.
Fig.3 Window of the selected menu Result map
Also in this table immediately there is a link (*) to go to this ad. This integration (the inclusion of JS elements in the table) allows you to make a package DT .
Conclusion
Summarizing all the above, how does it all work:
- On the first page using the controls set the original request
- Based on the selection of these input elements, a query string is formed (also indicated as a hyperlink for verification)
- This line with the page is passed to the import.io API (in the process of creating all of this, cian began to change the output interface, thanks to import.io, I retrained the extractor within literally 5 minutes)
- Processing received JSON from API
- All pages are scrolled (in the process of work, the status bar by processes is displayed)
- Tables are glued together, checked (incorrect values are eliminated, missing values are replaced), are given in a uniform form suitable for analysis
- Geocoding addresses and determining distances
- Model is built using random forest algorithm.
- Predicted prices, absolute, relative deviations are determined.
- The best results are displayed on the map and in the table below (the number of apartments to be displayed is indicated on the first page)
The entire operation of the application (from the beginning of the request to display on the map) is performed in less than a minute (most of the time is spent on geolocation, the restriction of Google for residential use).
This publication wanted to show how for simple domestic needs, in the framework of one application, we managed to solve many small, but fundamentally different interesting subtasks:
- crawling
- parsing
- integration with third-party API
- JSON processing
- geocoding
- working with different regression models
- evaluation of their effectiveness in different ways
- geolocation
- map display
Everything else is implemented in a convenient graphical application, which can be both local and hosted on the network, and all this is done on one R (not counting import.io ), with a minimum of lines of code with a simple and elegant syntax. Of course, something is not taken into account, for example, the house near the highway or the condition of the apartment (since there is no such thing in the ads), but the final, ranked list of options immediately displayed on the map and referring to the original ad itself, greatly facilitate the choice of apartments, Well, plus to everything I learned a lot of new things in R.
Source: https://habr.com/ru/post/264407/
All Articles