Clouds in the media service, or How Amazon helps process large volumes of video content
Our customer, one of the world's largest publishers, needed to increase the application's performance in order to publish news videos due to the increased traffic volume. Application users are editors of media resources. About 200 news clips pass through it every day, the average size of each of them is ~ 500 mb, totally about 100 Gb of fresh news per day.
Today we will share our experiences on how CloudFront and S3 helped us build a highly loaded and stable content processing system.

')
We hope our experience will interest developers / designers of systems for the storage and processing of media content (video, audio, images) and technicians who actively use AWS services.
Amazon Web Services offers a set of services for storing and delivering content, and their use is becoming an integral part of modern IT platforms.
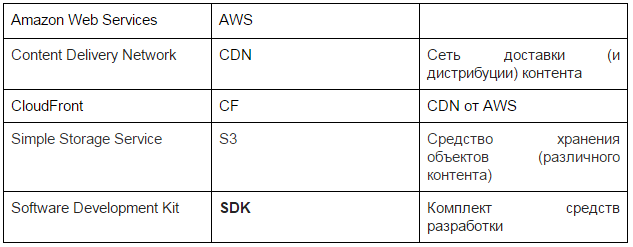
To create a video news editors, using the web interface, download the original video file and fill out the form with metadata (description, keywords, tags, categories, etc.). After that, the downloaded information is sent for processing (video conversion into different formats, generation of subtitles, etc.), including using third-party services.

# 1 The problem of downloading large amounts of data from different parts of the globe
The system is used by editors from different parts of the world, and the original video content is usually quite large (hundreds of Mb for a 10 minute video). The process of data transfer, and therefore the time of their processing and publication, depends on the editor’s distance from the application server.
# 2 Server load problem
The video uploaded by the editors in the first step goes to the server where the application is deployed. Next, we need to transcode this video into various formats, add subtitles for it. For this we use third-party video processing services. Work with each service is as follows:
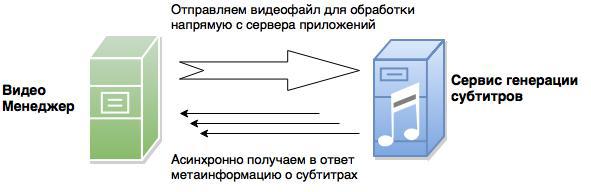
Accordingly, for the passage of the full video processing cycle (and therefore the creation of video news), several iterations of video transmission are required. In total, this translates into gigabytes of traffic and reduces the ability of the server to quickly process several such requests due to limitations on the amount of data transferred per unit time.
First of all, we went to find a solution to the server load problem. To reduce the amount of information transmitted, it was decided to transfer the storage and distribution of content on the shoulders of third-party file storages or services.
We considered services that would satisfy the following basic criteria:
the ability of third-party systems to take content for processing;
the ability to restrict access to content both by time and by reference;
The first major candidate for us was AWS S3, which allows us to use signed URLs (details -> docs.aws.amazon.com/AmazonS3/latest/API/sigv4-post-example.html ).
With S3, the processing of content by third-party services is changing. The application now sends only a link to the content, a third-party system picks it up independently from S3 via a signed link.

But in our case, this option was not suitable, since the task of accelerating the loading of data into the storage was not solved.
The next alternative was CDN CloudFront. Unlike other popular CDNs, it allows, using http-methods POST, PUT, DELETE, to manage content on S3, i.e. in fact, CDN becomes a complete wrapper for its source repository. CloudFront sends data on optimized routes, uses TCP / IP persistent connections and speeds up content delivery ( aws.amazon.com/ru/about-aws/whats-new/2013/10/15/amazon-cloudfront-now-supports-put- post-and-other-http-methods ).
As you can see, the scheme of work with content processing services remains almost the same as in the case of S3.
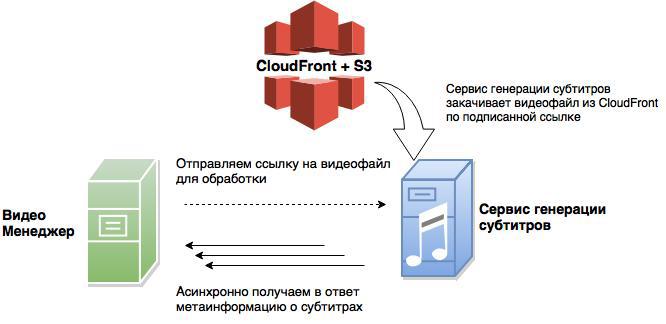
But for users of the system, everything has become much better: the content is downloaded to the nearest CloudFront server faster than directly to the S3 storage.

Thus, we kill two birds with one stone: fast data loading and saving them directly to AWS S3, bypassing the application server and the file system.
As a result of the restructuring, we obtain the following system:
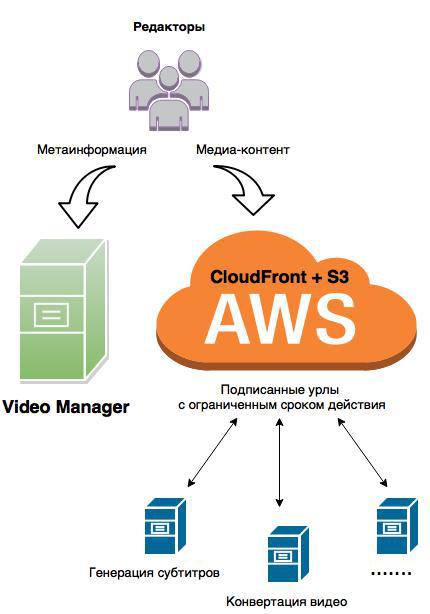
A few key points on S3 and CloudFront configuration
CORS Setup
CloudFront setup
We set up two CloudFront distribution for our target S3-bakt. The first is needed only to download content.
Key configurations:
The second is set up for feedback:
Work on the user side
In order for the new interaction scheme to work, we had to solve several integration tasks.
Popular content uploaders use multipart / form-data, which won't work with CloudFront, since it does not parse the request body, but saves it as is. I had to modify the angular-file-upload plugin a bit (AngularJS is mainly used on the project): to upload the file using the PUT method, xhr.send (Blob) was used (details here -> dvcs.w3.org/hg/xhr/raw-file/tip /Overview.html#the-send%28%29-method ).
As it turned out, the default files uploaded in this way are accessible by the AWS system only for the pseudo-user cloudfront-identity and are not accessible by signed URLs. We began to look for a way to configure permissions for downloadable files on AWS. I had to study the documentation and experiment, because In the network of such information is extremely small. As a result, it was established that the rights when downloading files via CloudFront are configured by the S3 http-headers docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html .
We used angular-file-upload to upload files.
Define a FileUploader:
Define the handler to generate the final download link to the cloudfront:
Determine the handler successful end of loading
On server
To get a signed link to download the file, use the standard class from the AWS SDK com.amazonaws.services.cloudfront.CloudFrontUrlSigner .
We give the generated links to users for uploading files to s3 or services for downloading them.
Code example
Editors of the publishing house were satisfied with the updated system: according to them, it began to work much faster, which made it possible to speed up the release of news.
According to statistics from AWS, we received:
Eventually:
Today we will share our experiences on how CloudFront and S3 helped us build a highly loaded and stable content processing system.
')
We hope our experience will interest developers / designers of systems for the storage and processing of media content (video, audio, images) and technicians who actively use AWS services.
Determine the tools and terminology
Amazon Web Services offers a set of services for storing and delivering content, and their use is becoming an integral part of modern IT platforms.
Prehistory - what did we find out?
To create a video news editors, using the web interface, download the original video file and fill out the form with metadata (description, keywords, tags, categories, etc.). After that, the downloaded information is sent for processing (video conversion into different formats, generation of subtitles, etc.), including using third-party services.
After analyzing the system architecture, we identified the following bottlenecks:
# 1 The problem of downloading large amounts of data from different parts of the globe
The system is used by editors from different parts of the world, and the original video content is usually quite large (hundreds of Mb for a 10 minute video). The process of data transfer, and therefore the time of their processing and publication, depends on the editor’s distance from the application server.
# 2 Server load problem
The video uploaded by the editors in the first step goes to the server where the application is deployed. Next, we need to transcode this video into various formats, add subtitles for it. For this we use third-party video processing services. Work with each service is as follows:
Accordingly, for the passage of the full video processing cycle (and therefore the creation of video news), several iterations of video transmission are required. In total, this translates into gigabytes of traffic and reduces the ability of the server to quickly process several such requests due to limitations on the amount of data transferred per unit time.
What have we done?
First of all, we went to find a solution to the server load problem. To reduce the amount of information transmitted, it was decided to transfer the storage and distribution of content on the shoulders of third-party file storages or services.
We considered services that would satisfy the following basic criteria:
the ability of third-party systems to take content for processing;
the ability to restrict access to content both by time and by reference;
The first major candidate for us was AWS S3, which allows us to use signed URLs (details -> docs.aws.amazon.com/AmazonS3/latest/API/sigv4-post-example.html ).
With S3, the processing of content by third-party services is changing. The application now sends only a link to the content, a third-party system picks it up independently from S3 via a signed link.
But in our case, this option was not suitable, since the task of accelerating the loading of data into the storage was not solved.
The next alternative was CDN CloudFront. Unlike other popular CDNs, it allows, using http-methods POST, PUT, DELETE, to manage content on S3, i.e. in fact, CDN becomes a complete wrapper for its source repository. CloudFront sends data on optimized routes, uses TCP / IP persistent connections and speeds up content delivery ( aws.amazon.com/ru/about-aws/whats-new/2013/10/15/amazon-cloudfront-now-supports-put- post-and-other-http-methods ).
As you can see, the scheme of work with content processing services remains almost the same as in the case of S3.
But for users of the system, everything has become much better: the content is downloaded to the nearest CloudFront server faster than directly to the S3 storage.
Thus, we kill two birds with one stone: fast data loading and saving them directly to AWS S3, bypassing the application server and the file system.
As a result of the restructuring, we obtain the following system:
- the video manager application works directly with metadata only;
- the original video files are saved directly from the S3 user interface via CloudFront;
- third-party services that need video content get it via signed links
Technical details
A few key points on S3 and CloudFront configuration
S3 configuration
CORS Setup
<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <AllowedMethod>POST</AllowedMethod> <AllowedMethod>PUT</AllowedMethod> <AllowedHeader>*</AllowedHeader> </CORSRule> </CORSConfiguration> CloudFront setup
We set up two CloudFront distribution for our target S3-bakt. The first is needed only to download content.
Key configurations:
Origin Settings Restrict Bucket Access - Yes; Allowed Http Methods - GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE; Default Cache Behavior Settings Restrict Viewer Access (Use Signed URLs) - Yes; Trusted Signer - Self The second is set up for feedback:
Origin Settings Restrict Bucket Access - Yes; Allowed Http Methods - GET, HEAD; Default Cache Behavior Settings Restrict Viewer Access (Use Signed URLs) - Yes; Trusted Signer - Self Application Integration
Work on the user side
In order for the new interaction scheme to work, we had to solve several integration tasks.
Popular content uploaders use multipart / form-data, which won't work with CloudFront, since it does not parse the request body, but saves it as is. I had to modify the angular-file-upload plugin a bit (AngularJS is mainly used on the project): to upload the file using the PUT method, xhr.send (Blob) was used (details here -> dvcs.w3.org/hg/xhr/raw-file/tip /Overview.html#the-send%28%29-method ).
As it turned out, the default files uploaded in this way are accessible by the AWS system only for the pseudo-user cloudfront-identity and are not accessible by signed URLs. We began to look for a way to configure permissions for downloadable files on AWS. I had to study the documentation and experiment, because In the network of such information is extremely small. As a result, it was established that the rights when downloading files via CloudFront are configured by the S3 http-headers docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html .
Code example
We used angular-file-upload to upload files.
Define a FileUploader:
$scope.videoUploader = new FileUploader({ autoUpload: true, method: "PUT", useDirectUpload: true, // FileUploader - html5 XmlHttpRequest FormData headers: { 'x-amz-acl': 'authenticated-read' // magic header (http://docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html) } }); Define the handler to generate the final download link to the cloudfront:
$scope.videoUploader.onBeforeUploadItem = function(item) { $.ajax({ url: "base-url.com/file/generateUploadUrl", // CloudFront type: 'GET', data: {fileName: item.file.name, fileSize:item.file.size}, async: false, success: function(data) { item.url = data.uploadUrl; // } }); }; Determine the handler successful end of loading
$scope.videoUploader.onSuccessItem = function (item, response, status, headers) { if (200 <= status && status < 300) { … // , , . }} On server
To get a signed link to download the file, use the standard class from the AWS SDK com.amazonaws.services.cloudfront.CloudFrontUrlSigner .
We give the generated links to users for uploading files to s3 or services for downloading them.
Code example
public class CloudFrontConfig { /** * for example http://get.example.cf.com/ or http://put.example.cf.com/ */ private String cloudFrontDomainNameForGet; private String cloudFrontDomainNameForPut; private String cloudFrontPrivateKey; private String cloudFrontKeyPairId; public String getDownloadUrlForUser(String s3key) throws Exception { return getSignedURL(cloudFrontDomainNameForGet, s3key); } public String getPutUrlForService(String s3key) throws Exception { return getSignedURL(cloudFrontDomainNameForPut, s3key); } private String getSignedURL(String domain, String s3Key) throws Exception { PrivateKey privateKey = loadPrivateKey(cloudFrontPrivateKey); Date dateLessThan = getDateLessThan(); String url = CloudFrontUrlSigner.getSignedURLWithCannedPolicy(domain + s3Key, cloudFrontKeyPairId, privateKey, dateLessThan); return url; } private Date getDateLessThan() { LocalDateTime dateNow = LocalDateTime.now(); ZonedDateTime zdt = dateNow.plusDays(1).atZone(ZoneId.systemDefault()); return Date.from(zdt.toInstant()); } private PrivateKey loadPrivateKey(String cloudFrontPrivateKey) { // PrivateKey } } What did we get as a result?
Editors of the publishing house were satisfied with the updated system: according to them, it began to work much faster, which made it possible to speed up the release of news.
According to statistics from AWS, we received:
- reducing incoming traffic to the server from 3Tb to 1 Gb per month;
- reduction of outgoing traffic from the server from 12Tb to 1 Gb per month;
- The size of the file system used is reduced from 500GB to 2GB.
Eventually:
- We optimized download and content access control using S3 and CloudFront;
- Reduced network and file load on the server;
- Wrote an article :)
Source: https://habr.com/ru/post/264145/
All Articles